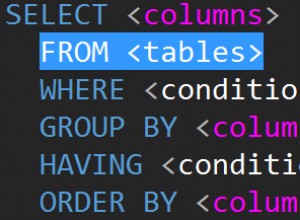
Was ist ClickHouse?

ClickHouse ist ein spaltenorientiertes Open-Source-DBMS (oder Datenbankverwaltungssystem), das hauptsächlich für OLAP (oder die analytische Online-Verarbeitung von Abfragen) verwendet wird. Es ist in der Lage, mithilfe von SQL-Abfragen blitzschnell Analysedaten in Echtzeit zu generieren und Berichte zu erstellen. Es ist fehlertolerant, skalierbar, äußerst zuverlässig und enthält ein funktionsreiches Tool-Set.
In einer normalen Datenbank werden Daten in Tabellen, Spalten und Zeilen gespeichert. In einer Tabelle werden die zugehörigen Werte physisch nebeneinander in einer Zeile gespeichert, was für die Funktionsweise von entscheidender Bedeutung ist. So funktionieren die meisten String-Datenbanken.
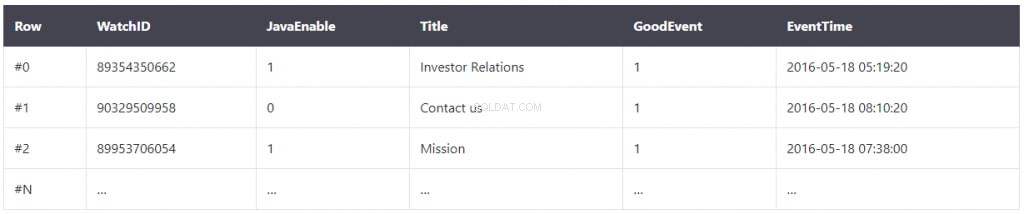
Einige Beispiele für diese Art von Datenbank sind:
- MySQL
- Postgres
- SQLite
Daten werden wie unten gezeigt in einer spaltenorientierten Datenbank gespeichert:
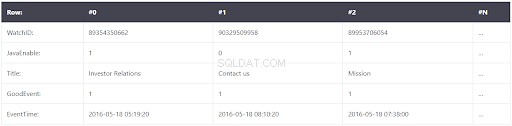
Es sieht ähnlich aus, aber die Unterschiede sind wie folgt:Werte aus verschiedenen Spalten werden separat gespeichert, während Daten aus einer Spalte zusammen gespeichert werden. Beispiele für spaltenorientierte Tabellen:
- Vertikal
- InfiniDB
- Google-Dremel
Solche DBMS speichern Datensätze in Blöcken, gruppiert nach Spalten statt nach Zeilen. Da keine Daten für die Spalten geladen werden, verbringen sie beim Ausführen von Abfragen weniger Zeit mit dem Lesen der Daten, sodass DBMS Daten viel schneller berechnen und Ergebnisse viel schneller zurückgeben können als in Blöcken gruppierte Datenbanken. Typischerweise werden spaltenorientierte Datenbanken am besten in OLAP-Szenarien eingesetzt, wo sie im Vergleich zu Zeichenfolgendatenbanken normalerweise 100-mal schneller bei der Verarbeitung der meisten Abfragen sind.
Wie wir aus den obigen Abbildungen ersehen können, ermöglicht uns OLAP, große Datenmengen zu organisieren und komplexe Abfragen um mehrere Größenordnungen schneller durchzuführen als eine typische Datenbank. Daher ist es äußerst nützlich für die Arbeit mit großen Eingabemengen, wenn Daten analysiert werden und/oder Geschäftsanalysen erforderlich sind.
SQL-Nutzung
ClickHouse verwendet einen SQL-Dialekt, der der standardmäßigen Structured Query Language ähnelt, aber zusätzliche Erweiterungen enthält:verschiedene Arrays, Funktionen höherer Ordnung, verschachtelte Strukturen, Funktionen zum Arbeiten mit URLs und die Möglichkeit, mit einem externen Wörterbuch zu arbeiten. usw.
Während wir an Geschwindigkeit und Big-Data-Verarbeitung gewinnen, verlieren wir auch andere Aspekte, einschließlich der folgenden Optionen:
- Mangel an Transaktionen.
- Starke Datentypen mit Bedarf an explizitem Casting.
- Muss für einige Operationen Zwischendaten im RAM speichern.
- Fehlen eines vollwertigen Abfrageoptimierers.
- Punktuelles Lesen von Daten in einer Datenbank.
Trotzdem zeigt ClickHouse eine hohe Leistung und setzt sich gegen viele Konkurrenten durch. ClickHouse wurde entwickelt, um Probleme in der Webanalyse für Yandex.Metrica, das drittbeliebteste Webanalysesystem der Welt, zu lösen. Es wird auch von Cloudflare verwendet, um Website-Statistiken für seine Benutzer zu verarbeiten.
Voraussetzungen
Zur Installation benötigen wir:
- Ein 2-Kern-Server mit mindestens 2 GB RAM
- Ein Ubuntu 20.04 LTS-Betriebssystem
- Zugriff auf das Root-Benutzerkonto (wie alle Aktionen, die als Root ausgeführt werden).
ClickHouse-Installation auf Ubuntu 20.04
Vor der Installation aktualisieren wir das System und die Pakete auf dem Server.
root@host:~# apt update && apt -y upgrade
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Hit:5 https://download.docker.com/linux/ubuntu focal InRelease
Hit:6 https://debian.neo4j.com stable InRelease
Fetched 109 kB in 0s (231 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
root@host:~# Yandex verwaltet ein Repository mit der neuesten Version von ClickHouse, daher müssen wir es hinzufügen. Fügen Sie außerdem einen GPG-Schlüssel hinzu, um das Repository zu überprüfen und ClickHouse und zukünftige Updates sicher zu installieren.
root@host:~# apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4
Executing: /tmp/apt-key-gpghome.5KK4WZQb0R/gpg.1.sh --keyserver keyserver.ubuntu.com --recv E0C56BD4
gpg: key C8F1E19FE0C56BD4: public key "ClickHouse Repository Key <milovidov@yandex-team.ru>" imported
gpg: Total number processed: 1
gpg: imported: 1
root@host:~# Fügen Sie das Repository zur Liste der APK-Repositorys hinzu.
root@host:~# echo "deb https://repo.yandex.ru/clickhouse/deb/stable/ main/" | tee /etc/apt/sources.list.d/clickhouse.list
deb https://repo.yandex.ru/clickhouse/deb/stable/ main/
root@host:~# Als nächstes aktualisieren wir unsere Serverpakete.
root@host:~# apt update
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Ign:5 https://repo.yandex.ru/clickhouse/deb/stable main/ InRelease
Get:6 https://repo.yandex.ru/clickhouse/deb/stable main/ Release [749 B]
Get:7 https://repo.yandex.ru/clickhouse/deb/stable main/ Release.gpg [836 B]
Hit:8 https://download.docker.com/linux/ubuntu focal InRelease
Get:9 https://repo.yandex.ru/clickhouse/deb/stable main/ Packages [152 kB]
Hit:10 https://debian.neo4j.com stable InRelease
Fetched 263 kB in 0s (536 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
root@host:~#Schließlich können wir ClickHouse installieren. Geben Sie ein Passwort ein, wenn Sie dazu aufgefordert werden.
root@host:~# apt install -y clickhouse-server clickhouse-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
clickhouse-common-static
Suggested packages:
clickhouse-common-static-dbg
The following NEW packages will be installed:
clickhouse-client clickhouse-common-static clickhouse-server
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 119 MB of archives.
After this operation, 401 MB of additional disk space will be used.
...
Preconfiguring packages ...
Selecting previously unselected package clickhouse-common-static.
(Reading database ... 164995 files and directories currently installed.)
Preparing to unpack .../clickhouse-common-static_20.12.5.14_amd64.deb ...
Unpacking clickhouse-common-static (20.12.5.14) ...
Selecting previously unselected package clickhouse-client.
Preparing to unpack .../clickhouse-client_20.12.5.14_all.deb ...
Unpacking clickhouse-client (20.12.5.14) ...
Selecting previously unselected package clickhouse-server.
Preparing to unpack .../clickhouse-server_20.12.5.14_all.deb ...
Unpacking clickhouse-server (20.12.5.14) ...
Setting up clickhouse-common-static (20.12.5.14) ...
Setting up clickhouse-server (20.12.5.14) ...
ClickHouse init script has migrated to systemd. Please manually stop old server
and restart the service: killall clickhouse-server && sleep 5 && servi
ce clickhouse-server restart
Synchronizing state of clickhouse-server.service with SysV service script with /
lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable clickhouse-server
Created symlink /etc/systemd/system/multi-user.target.wants/clickhouse-server.se
rvice → /etc/systemd/system/clickhouse-server.service.
Copying ClickHouse binary to /usr/bin/clickhouse.new
/usr/bin/clickhouse already exists, will rename existing binary to /usr/bin/clic
khouse.old and put the new binary in place
Renaming /usr/bin/clickhouse.new to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-server already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-server to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-client already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-client to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-local already exists but it points to /clickhouse. W
ill replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-local to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-benchmark already exists but it points to /clickhous
e. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-benchmark to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-copier already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-copier to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-obfuscator already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-obfuscator to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-git-import to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-compressor already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-compressor to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-format already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-format to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-extract-from-config already exists but it points to
/clickhouse. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-extract-from-config to /usr/bin/clickhouse.
Creating clickhouse group if it does not exist.
groupadd -r clickhouse
Creating clickhouse user if it does not exist.
useradd -r --shell /bin/false --home-dir /nonexistent -g clickhouse clickhouse
Will set ulimits for clickhouse user in /etc/security/limits.d/clickhouse.conf.
Creating config directory /etc/clickhouse-server/config.d that is used for tweak
s of main server configuration.
Creating config directory /etc/clickhouse-server/users.d that is used for tweaks
of users configuration.
Config file /etc/clickhouse-server/config.xml already exists, will keep it and e
xtract path info from it.
/etc/clickhouse-server/config.xml has /var/lib/clickhouse/ as data path.
/etc/clickhouse-server/config.xml has /var/log/clickhouse-server/ as log path.
Users config file /etc/clickhouse-server/users.xml already exists, will keep it
and extract users info from it.
chown --recursive clickhouse:clickhouse '/etc/clickhouse-server'
Creating log directory /var/log/clickhouse-server/.
Creating data directory /var/lib/clickhouse/.
Creating pid directory /var/run/clickhouse-server.
chown --recursive clickhouse:clickhouse '/var/log/clickhouse-server/'
chown --recursive clickhouse:clickhouse '/var/run/clickhouse-server'
chown clickhouse:clickhouse '/var/lib/clickhouse/'
Password for default user is already specified. To remind or reset, see /etc/cli
ckhouse-server/users.xml and /etc/clickhouse-server/users.d.
Setting capabilities for clickhouse binary. This is optional.
command -v setcap >/dev/null && echo > /tmp/test_setcap.sh && chmod a+x /tmp/te
st_setcap.sh && /tmp/test_setcap.sh && setcap 'cap_net_admin,cap_ipc_lock,cap_sy
s_nice+ep' /tmp/test_setcap.sh && /tmp/test_setcap.sh && rm /tmp/test_setcap.sh
&& setcap 'cap_net_admin,cap_ipc_lock,cap_sys_nice+ep' /usr/bin/clickhouse || ec
ho "Cannot set 'net_admin' or 'ipc_lock' or 'sys_nice' capability for clickhouse
binary. This is optional. Taskstats accounting will be disabled. To enable task
stats accounting you may add the required capability later manually."
ClickHouse has been successfully installed.
Start clickhouse-server with:
clickhouse start
Start clickhouse-client with:
clickhouse-client --password
Setting up clickhouse-client (20.12.5.14) ...
Processing triggers for systemd (245.4-4ubuntu3.3) ...
root@host:~# ClickHouse-Dienst starten
Nachdem wir ClickHouse installiert haben, lassen Sie es uns im Hintergrund ausführen.
root@host:~# service clickhouse-server start
root@host:~# Status überprüfen
In diesem Schritt überprüfen wir einfach, ob alles wie erwartet funktioniert.
root@host:~# service clickhouse-server status
● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data)
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s ago
Main PID: 5553 (clickhouse-serv)
Tasks: 48 (limit: 9489)
Memory: 45.8M
CGroup: /system.slice/clickhouse-server.service
└─5553 /usr/bin/clickhouse-server --config=/etc/clickhouse-server/>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:26 host clickhouse-server[5553]: Logging trace to /var/log/clickho>
сне 30 22:08:26 host clickhouse-server[5553]: Logging errors to /var/log/clickh>
сне 30 22:08:26 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: networks
сне 30 22:08:26 host clickhouse-server[5553]: Saved preprocessed configuration >
сне 30 22:08:28 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_rem>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:28 host clickhouse-server[5553]: Saved preprocessed configuration >
lines 1-19/19 (END)Auf die folgenden Zeilen müssen wir besonders achten.
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s agoFirewall konfigurieren
Wenn Sie keine Firewall verwenden, überspringen Sie diesen Schritt. Wenn Sie eine Remoteverbindung planen und eine Firewall aktiviert haben, ist dieser Schritt erforderlich. Öffnen und bearbeiten Sie die Konfigurationsdatei und kommentieren Sie die folgende Zeile aus.
<!-- <listen_host>0.0.0.0</listen_host> →Sobald die Bearbeitung abgeschlossen ist, speichern Sie die Datei mit Strg+S und Strg+X und starten Sie dann den ClickHouse-Dienst neu.
root@host:~# service clickhouse-server restart
root@host:~# Ports öffnen
Öffnen Sie als nächstes Port 8123 in der Firewall, um den Zugriff für Ihre IP-Adresse zu ermöglichen.
ufw allow from YOUR_IP_SERVER/32 to any port 8123Öffnen Sie dann Port 9000 für den Clickhouse-Client IP-Adresse.
root@host:~# ufw allow from 192.168.13.1/32 to any port 8123
Rules updated
root@host:~#
root@host:~# ufw allow from 192.168.13.1/32 to any port 9000
Rules updated
root@host:~# Verbindung überprüfen
Um zu überprüfen, ob bei einer Remote-Verbindung alles funktioniert, verwenden Sie die folgende Abfrage.
clickhouse-client --host 192.168.13.1 --passwordroot@host:~# clickhouse-client --host 192.168.13.1 --password
Password for user (default):
Connecting to 192.168.13.1:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :)Lernbasisbefehle und Interaktionen
In ClickHouse können wir Datenbanken mit der modifizierten SQL-Syntax erstellen und löschen. Werfen wir einen Blick auf die folgenden Beispiele. Stellen wir zunächst eine Verbindung zu ClickHouse her.
root@host:~# clickhouse-client
ClickHouse client version 20.12.5.14 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Datenbank erstellen
Sobald wir uns in der ClickHouse-Befehlszeile befinden, erstellen wir eine Datenbank namens liquidweb mit der folgenden Syntax.
host :) CREATE DATABASE liquidweb;
CREATE DATABASE liquidweb
Query id: 9169dbaa-402e-4d37-828f-5fde43d4a91d
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) In ClickHouse ist die Tabelle fast die gleiche wie in anderen Datenbanken mit einer Reihe verwandter Daten in einem strukturierten Format. Wir können Spalten und deren Typen spezifizieren, Zeilen hinzufügen und verschiedene Arten von Abfragen gegen die Datenbank durchführen.
Tabelle erstellen
Bevor wir eine Tabelle erstellen, ist es wichtig, die verfügbaren Spaltentypen zu kennen und zu verstehen. Folgende Spaltentypen sind möglich:
- UInt64 — Diese Tabelle wird verwendet, um Ganzzahlen im Bereich von 0 bis 18446744073709551615 zu speichern.
- Float64 — Jede Tabelle, die Float64 verwendet, kann Gleitkommazahlen wie 10,5, 18754,067 usw. speichern.
- Zeichenfolge — Hier ersetzt die Zeichenfolgentabelle VARCHAR, BLOB, CLOB und andere Typen aus verschiedenen DBMSs
- Datum — Diese Tabelle wird verwendet, um Datumsangaben im Format JJJJ-MM-TT zu speichern.
- DatumUhrzeit — Hier wird die DateTime-Tabelle verwendet, um Datums- und Zeitangaben im genaueren Format YYYY-MM-DD HH:MM:SS zu speichern
Datenstrukturen
ClickHouse definiert die Struktur der zugrunde liegenden Daten, indem es die genauen Daten, die Fähigkeit zur Abfrage der Tabelle, die Modi des gleichzeitigen Zugriffs auf die Tabelle und die Unterstützung für Indizes beschreibt. ClickHouse verfügt über verschiedene Funktionen, die für unterschiedliche Nutzungsbedingungen geeignet sind.
MergeTree
Der am weitesten verbreitete Mechanismus ist die Tabellen-Engine-Operation namens MergeTree . Diese Funktion dient zum Einfügen großer Datenmengen in eine Tabelle. Aufgrund seiner optimierten Unterstützung für das Einfügen großer Mengen von Echtzeit-Assets sowie seiner Zuverlässigkeit und Abfrageunterstützung wird es für die Verwendung in Produktionsdatenbanken dringend empfohlen.
Datenbank auswählen
Fahren wir mit der weiteren Praxis fort. Lassen Sie uns zuerst eine Datenbank auswählen, in der wir eine Tabelle erstellen werden.
host :) USE liquidweb;
USE liquidweb
Query id: aba15bcb-224b-426d-9f74-350a88346115
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Tabelle erstellen
Als Nächstes erstellen wir eine Tabelle namens kollegen .
host :) CREATE TABLE colleagues ( id UInt64, name String, url String, created DateTime ) ENGINE = MergeTree() PRIMARY KEY id ORDER BY id;
CREATE TABLE colleagues
(
`id` UInt64,
`name` String,
`url` String,
`created` DateTime
)
ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY id
Query id: 08223a2f-d365-43cb-8627-d22674d1c47c
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) Sehen wir uns an, welche Werte wir hinzugefügt haben.
- id - Dies ist die Primärschlüsselspalte. Jede Zeile muss eine eindeutige Kennung haben.
- Name - Eine Spalte mit einem Zeichenfolgenwert.
- URL - Eine Spalte mit einem Zeichenfolgenwert, der einen Link zum Profil enthält.
- erstellt - Das Datum, an dem der Mitarbeiter im System erschienen ist.
Nachdem wir die Spalten in der Tabelle definiert haben, spezifizieren wir dann den MergeTree Mechanismus zur Aufbewahrung des Tisches. Als nächstes bestimmen wir die Spalten und definieren dann die Spalten auf Tabellenebene.
- PRIMÄRSCHLÜSSEL - Gibt die Primärschlüsselspalte an.
- BESTELLUNG VON - Die gespeicherten Tabellenwerte werden nach ID-Spalte sortiert.
Daten hinzufügen
Jetzt können wir mit der Tabelle arbeiten. Fügen wir den Kollegen einige Daten hinzu Tabelle.
host :) INSERT INTO colleagues VALUES (1, 'margaret', 'https://1.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 42dbde52-6d7e-4849-ac5e-280590f3232d
Ok.
1 rows in set. Elapsed: 0.002 sec.
host :) Lassen Sie uns weitere Daten hinzufügen.
host :) INSERT INTO colleagues VALUES (2, 'john', 'https://2.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: a9b34f78-2caa-4b41-bd4e-91bf8049a04b
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :)host :) INSERT INTO colleagues VALUES (3, 'kingsman', 'https://3.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: df5133c1-b404-4569-8123-f0728c172c87
Ok.
1 rows in set. Elapsed: 0.003 sec.
host :) host :) INSERT INTO colleagues VALUES (4, 'tor', 'https://4.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 14f56b86-fae7-4af2-b506-18c351b92853
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :) Spalte hinzufügen
Während wir einige Werte hinzugefügt haben, haben wir festgestellt, dass wir vergessen haben, eine weitere Spalte hinzuzufügen, also müssen wir sie unten hinzufügen.
host :) ALTER TABLE colleagues ADD COLUMN location String;
ALTER TABLE colleagues
ADD COLUMN `location` String
Query id: 002900f4-9fd9-4302-a10f-6aa5b818f9ae
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :)Daten bearbeiten
Jetzt müssen wir die alten Daten irgendwie ändern. In Version 19.13 unterstützt ClickHouse das Aktualisieren und Löschen einzelner Zeilen aufgrund seiner Implementierung nicht. ClickHouse unterstützt jedoch Massenaktualisierungen und -löschungen und hat auch eine eigene Syntax für diese Vorgänge.
Jetzt aktualisieren wir unsere Zeilen.
host :) ALTER TABLE colleagues UPDATE url ='https://1.com' WHERE id < 15;
ALTER TABLE colleagues
UPDATE url = 'https://1.com' WHERE id < 15
Query id: 6fc6620e-fd90-43aa-8d7f-8a34cfb73650
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :)Nach WO , setzen wir die Filterparameter und können auch unnötige Parameter löschen.
host :) ALTER TABLE colleagues DELETE WHERE id < 2;
ALTER TABLE colleagues
DELETE WHERE id < 2
Query id: 354e27fc-70c9-480b-bb1d-067591924c6e
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :) Spalte entfernen
Gehen Sie wie folgt vor, um Spalten aus einer Tabelle zu entfernen.
host :) ALTER TABLE colleagues DROP COLUMN location;
ALTER TABLE colleagues
DROP COLUMN location
Query id: da361478-0619-4c31-8422-f59ee14a57d7
Ok.
0 rows in set. Elapsed: 0.008 sec.
host :) Datenabruf über Abfragen
Als Nächstes demonstrieren wir den Datenabruf mithilfe von Abfragen. ClickHouse verwendet hier die SQL-Syntax mit ihren Ergänzungen. Lassen Sie uns versuchen, einige grundlegende Informationen zu sammeln.
host :) SELECT url, name FROM colleagues WHERE url = 'https://1.com' LIMIT 1;
SELECT
url,
name
FROM colleagues WHERE url = 'https://1.com'
LIMIT 1
Query id: 8a5cbf9a-f187-440c-9a60-2d23029b4bd1
┌─url──────────┬─name─┐
│ https://1.com │ john │
└──────────────┴──────┘
1 rows in set. Elapsed: 0.003 sec.
host :) - AUSWÄHLEN - Mehrere Parameter auswählen.
- VON - Bestimmen Sie, welche Tabelle wir Werte erhalten.
- WO - Legen Sie die Parameter und Filter fest, welcher Wert und wie viel.
Wir können auch zusätzliche Suchparameter verwenden, wie zum Beispiel:
- Zählung - Gibt die Anzahl der Zeilen zurück, die den Bedingungen entsprechen.
- Summe - Gibt die Summe der ausgewählten Werte zurück.
- Durchschnitt - Gibt den Durchschnitt der ausgewählten Elemente zurück.
- einzigartig - Gibt die ungefähre Anzahl der übereinstimmenden Einzelzeilen zurück.
- topK - Gibt mithilfe eines Algorithmus ein Array der häufigsten Werte einer bestimmten Spalte zurück.
Tabellen und Datenbanken löschen
Als nächstes fahren wir mit dem Löschen von Tabellen und Datenbanken fort. Lassen Sie uns zuerst eine Tabelle löschen.
host :) DROP TABLE colleagues;
DROP TABLE colleagues
Query id: 21048fe4-d379-48ac-b9a7-71f0b3fe93e1
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Löschen Sie nun die Datenbank.
host :) DROP DATABASE liquidweb;
DROP DATABASE liquidweb
Query id: 4ad9a51a-f89d-4be5-be9c-92b8cb38614b
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Um die Datenbank zu verlassen, geben Sie den Standardwert 'exit' ein.
host :) exit
Bye.
root@host:~# Erstellen Sie einen Benutzer
Nachdem wir nun alle grundlegenden Funktionen behandelt haben, werden wir mehrere Datenbankbenutzer erstellen. Die ClickHouse-Konfigurationsdatei befindet sich im folgenden Pfad /etc/clickhouse-client/config.xml. Gehen Sie zu dieser Datei, öffnen Sie sie mit vim oder nano und geben Sie die Werte in der folgenden Reihenfolge an.
<config> <user>username</user> <password>password</password> <secure>False</secure></config>Wir werden den Nano-Editor zum Bearbeiten der Datei verwenden.
root@host:~# nano /etc/clickhouse-client/config.xml
root@host:~# Geben Sie die erforderlichen Informationen ein und speichern Sie dann die Änderungen mit Strg+S undStrg+X Tasten
Verbinden Sie sich mit ClickHouse
Um schließlich eine Verbindung zu ClickHouse herzustellen, geben Sie den folgenden Befehl im Terminal ein.
root@host:~# clickhouse-client -u margaret --password
ClickHouse client version 20.12.5.14 (official build).
Password for user (margaret):
Connecting to localhost:9440 as user margaret.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Schlussfolgerung
In diesem Tutorial haben wir viele Aspekte von ClickHouse entdeckt. Wir haben herausgefunden, wie es funktioniert, wann es angewendet werden kann und unter welchen Umständen es nützlich ist. Wir haben herausgefunden, wie man einen Schlüssel und das Repository hinzufügt und dann die ClickHouse-Software installiert. Ebenso haben wir dann die Firewall eingerichtet und konfiguriert, um den Zugriff zu ermöglichen. Darüber hinaus haben wir Datenbanken und Tabellen erstellt, Spalten und Daten hinzugefügt und diese dann aktualisiert und gelöscht. Zuletzt haben wir gezeigt, wie Benutzer in der Konfigurationsdatei erstellt werden.
Wir sind stolz darauf, The Most Helpful Humans In Hosting™ zu sein! Unsere Support-Teams bestehen aus erfahrenen Linux-Technikern und talentierten Systemadministratoren, die über fundierte Kenntnisse mehrerer Webhosting-Technologien verfügen, einschließlich der in diesem Artikel besprochenen.
Sollten Sie Fragen zu diesem Artikel haben, stehen wir Ihnen jederzeit zur Verfügung 24 Stunden am Tag, 7 Tage die Woche, 365 Tage im Jahr für alle Fragen zu diesem Artikel zur Verfügung.
Wenn Sie ein vollständig verwalteter VPS-Server, dedizierter Cloud-Server, eine private VMWare-Cloud, ein privater übergeordneter Server, verwaltete Cloud-Server oder ein Eigentümer eines dedizierten Servers sind und Sie sich nicht wohl dabei fühlen, einen der beschriebenen Schritte auszuführen, Wir sind telefonisch erreichbar unter @800.580.4985, per Chat oder Support-Ticket, um Sie bei diesem Vorgang zu unterstützen.