
T-SQL Tuesday #78 wird von Wendy Pastrick moderiert, und die Herausforderung in diesem Monat besteht einfach darin, „etwas Neues zu lernen und darüber zu bloggen“. Ihr Klappentext tendiert zu neuen Funktionen in SQL Server 2016, aber da ich viele davon gebloggt und vorgestellt habe, dachte ich, ich würde etwas anderes aus erster Hand erkunden, auf das ich schon immer wirklich neugierig war.
Ich habe mehrere Leute gesehen, die angeben, dass ein Heap für bestimmte Szenarien besser sein kann als ein gruppierter Index. Dem kann ich nicht widersprechen. Einer der interessanten Gründe, die ich gesehen habe, ist jedoch, dass eine RID-Suche schneller ist als eine Schlüsselsuche. Ich bin ein großer Fan von geclusterten Indizes und kein großer Fan von Heaps, daher dachte ich, dass dies etwas getestet werden muss.
Also testen wir es!
Ich dachte, es wäre gut, eine Datenbank mit zwei Tabellen zu erstellen, die identisch sind, außer dass eine einen geclusterten Primärschlüssel und die andere einen nicht geclusterten Primärschlüssel hat. Ich würde einige Zeilen in die Tabelle laden, eine Reihe von Zeilen in einer Schleife aktualisieren und aus einem Index auswählen (entweder eine Schlüssel- oder RID-Suche erzwingen).
Systemspezifikationen
Diese Frage kommt oft auf, also um die wichtigen Details zu diesem System zu klären, bin ich auf einer 8-Kern-VM mit 32 GB RAM, unterstützt von PCIe-Speicher. Die SQL Server-Version ist 2014 SP1 CU6, ohne spezielle Konfigurationsänderungen oder ausgeführte Ablaufverfolgungsflags:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13. April 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) unter Windows NT 6.3
Die Datenbank
Ich habe eine Datenbank mit viel freiem Speicherplatz sowohl in der Daten- als auch in der Protokolldatei erstellt, um zu verhindern, dass Autogrow-Ereignisse die Tests stören. Außerdem habe ich die Datenbank auf einfache Wiederherstellung eingestellt, um die Auswirkungen auf das Transaktionsprotokoll zu minimieren.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Die Tabellen
Wie gesagt, zwei Tabellen, mit dem einzigen Unterschied, ob der Primärschlüssel geclustert ist.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Eine Tabelle zum Erfassen der Laufzeit
Ich könnte die CPU und all das überwachen, aber eigentlich dreht sich die Neugier fast immer um die Laufzeit. Also habe ich eine Logging-Tabelle erstellt, um die Laufzeit jedes Tests zu erfassen:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Der Insert-Test
Wie lange dauert es also, 2.000 Zeilen 100 Mal einzufügen? Ich hole einige ziemlich grundlegende Daten aus sys.all_objects , und ziehen Sie die Definition für alle Prozeduren, Funktionen usw. mit:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Der Aktualisierungstest
Für den Aktualisierungstest wollte ich nur die Geschwindigkeit des Schreibens in einen gruppierten Index im Vergleich zu einem Heap sehr zeilenweise testen. Also habe ich 200 zufällige Zeilen in eine #temp-Tabelle geschrieben und dann einen Cursor darum gebaut (die #temp-Tabelle stellt lediglich sicher, dass dieselben 200 Zeilen in beiden Versionen der Tabelle aktualisiert werden, was wahrscheinlich übertrieben ist).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Der Auswahltest
Oben haben Sie also gesehen, dass ich einen Index mit Name erstellt habe als Schlüsselspalte in jeder Tabelle; Um die Kosten für die Durchführung von Suchvorgängen für eine beträchtliche Anzahl von Zeilen zu bewerten, habe ich eine Abfrage geschrieben, die die Ausgabe einer Variablen zuweist (wodurch Netzwerk-I/O und Client-Rendering-Zeit eliminiert werden), aber die Verwendung des Indexes erzwingt:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Für diesen wollte ich einige interessante Aspekte der Pläne zeigen, bevor ich die Testergebnisse zusammentrage. Wenn Sie sie einzeln gegeneinander laufen lassen, erhalten Sie diese Vergleichsmetriken:

Die Dauer ist für eine einzelne Anweisung belanglos, aber schauen Sie sich diese Lesevorgänge an. Wenn Sie langsamen Speicher verwenden, ist das ein großer Unterschied, den Sie in einem kleineren Maßstab und/oder auf Ihrer lokalen Entwicklungs-SSD nicht sehen werden.
Und dann die Pläne, die die zwei verschiedenen Lookups mit SQL Sentry Plan Explorer zeigen:

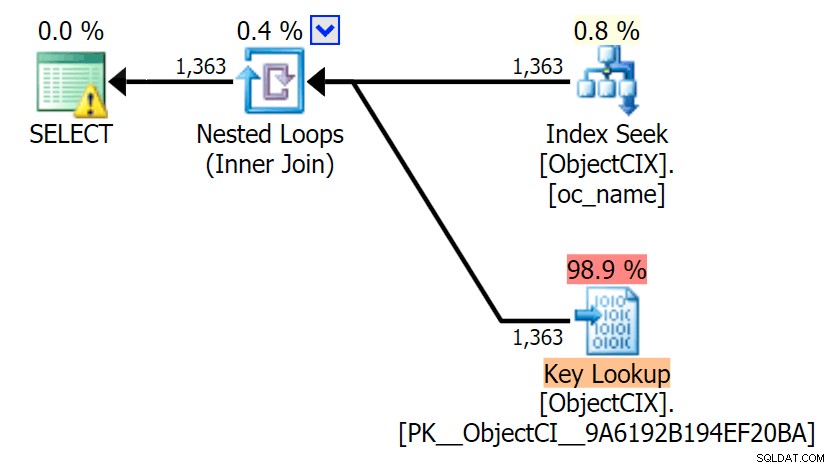
Die Pläne sehen fast identisch aus, und Sie bemerken den Unterschied bei den Lesevorgängen in SSMS möglicherweise nicht, es sei denn, Sie erfassen Statistik-E/A. Sogar die geschätzten E/A-Kosten für die beiden Suchen waren ähnlich – 1,69 für die Schlüsselsuche und 1,59 für die RID-Suche. (Das Warnsymbol in beiden Plänen weist auf einen fehlenden Deckungsindex hin.)
Es ist interessant festzustellen, dass, wenn wir keine Suche erzwingen und SQL Server entscheiden lassen, was zu tun ist, in beiden Fällen ein Standardscan ausgewählt wird – keine Warnung wegen fehlendem Index, und schauen, wie viel näher die Lesevorgänge sind:

Der Optimierer weiß, dass ein Scan in diesem Fall viel billiger ist als Suchen + Nachschlagen. Ich habe eine LOB-Spalte für die Variablenzuweisung nur aus Gründen der Wirkung ausgewählt, aber die Ergebnisse waren auch bei Verwendung einer Nicht-LOB-Spalte ähnlich.
Die Testergebnisse
Mit der vorhandenen Timings-Tabelle konnte ich die Tests problemlos mehrmals ausführen (ich habe ein Dutzend Tests durchgeführt) und dann mit der folgenden Abfrage Durchschnittswerte für die Tests erhalten:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Ein einfaches Balkendiagramm zeigt den Vergleich:
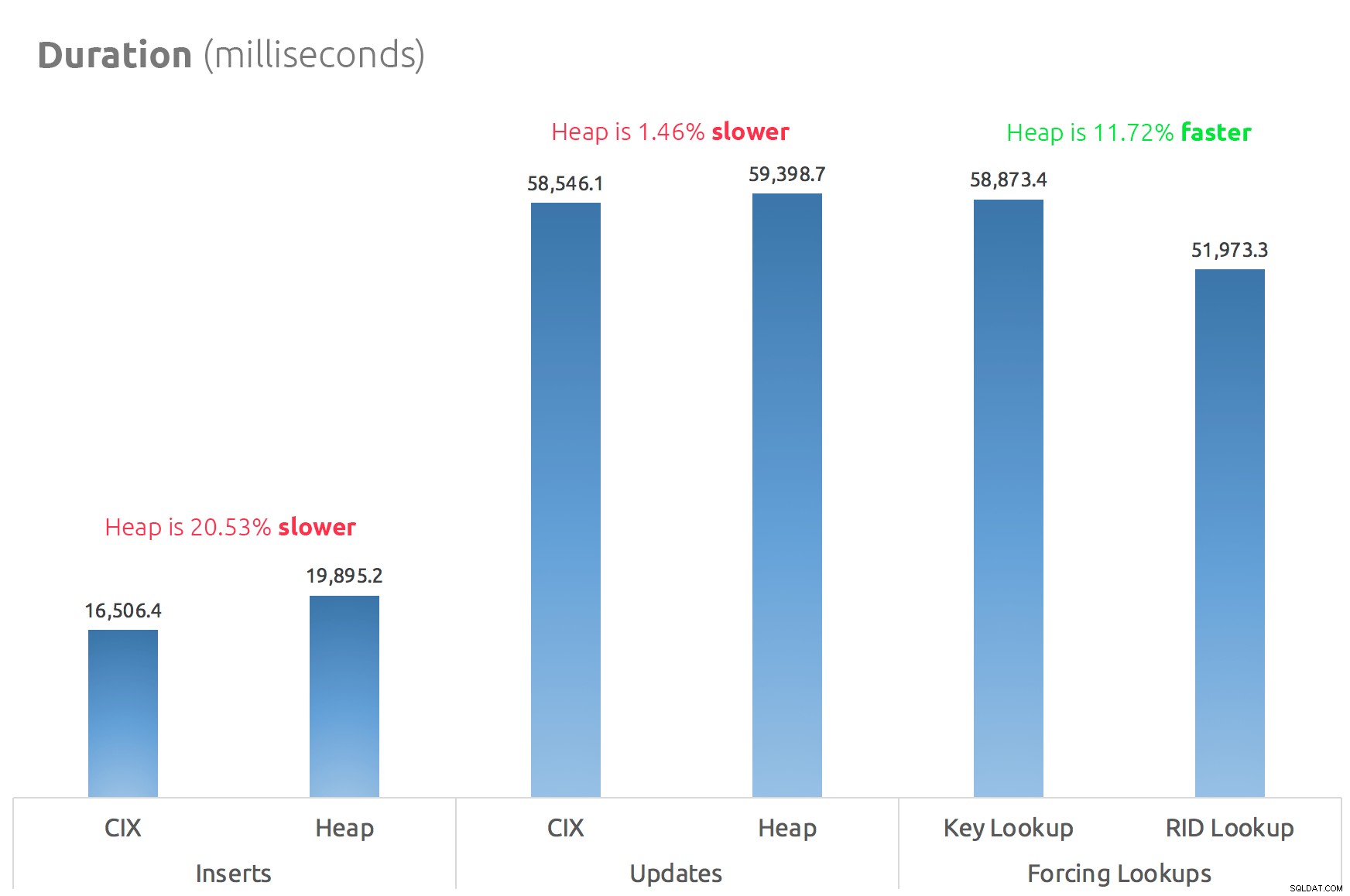
Schlussfolgerung
Die Gerüchte stimmen also:Zumindest in diesem Fall ist ein RID-Lookup deutlich schneller als ein Key-Lookup. Direkt zu file:page:slot zu gehen ist offensichtlich effizienter in Bezug auf I/O, als dem B-Tree zu folgen (und wenn Sie keinen modernen Speicher verwenden, könnte das Delta viel auffälliger sein).
Ob Sie davon profitieren und alle anderen Heap-Aspekte mitbringen möchten, hängt von Ihrer Arbeitsbelastung ab – der Heap ist für Schreibvorgänge etwas teurer. Aber das ist nicht endgültig – dies kann je nach Tabellenstruktur, Indizes und Zugriffsmustern stark variieren.
Ich habe hier sehr einfache Dinge getestet, und wenn Sie diesbezüglich unschlüssig sind, empfehle ich Ihnen dringend, Ihre tatsächliche Arbeitslast auf Ihrer eigenen Hardware zu testen und selbst zu vergleichen (und vergessen Sie nicht, dieselbe Arbeitslast zu testen, bei der abdeckende Indizes vorhanden sind; Sie werden wahrscheinlich eine viel bessere Gesamtleistung erzielen, wenn Sie Suchvorgänge einfach ganz eliminieren können). Stellen Sie sicher, dass Sie alle Metriken messen, die für Sie wichtig sind; Nur weil ich mich auf die Dauer konzentriere, heißt das nicht, dass es das ist, um das Sie sich am meisten kümmern müssen. :-)



