Letzte Woche habe ich ein paar schnelle Leistungsvergleiche durchgeführt und dabei das neue STRING_AGG() getestet Funktion gegen den traditionellen FOR XML PATH Ansatz, den ich seit Ewigkeiten verwende. Ich habe sowohl undefinierte/willkürliche Reihenfolge als auch explizite Reihenfolge und STRING_AGG() getestet hat sich in beiden Fällen durchgesetzt:
- SQL Server v.Next :STRING_AGG()-Leistung, Teil 1
Für diese Tests habe ich mehrere Dinge weggelassen (nicht alle absichtlich):
- Mikael Eriksson und Grzegorz Łyp wiesen beide darauf hin, dass ich nicht den absolut effizientesten
FOR XML PATHverwende konstruieren (und um klar zu sein, ich habe nie). - Ich habe keine Tests unter Linux durchgeführt; nur unter Windows. Ich erwarte nicht, dass diese sehr unterschiedlich sind, aber da Grzegorz sehr unterschiedliche Dauern gesehen hat, ist dies eine weitere Untersuchung wert.
- Ich habe auch nur getestet, wenn die Ausgabe eine endliche Nicht-LOB-Zeichenfolge wäre – was meiner Meinung nach der häufigste Anwendungsfall ist (ich glaube nicht, dass die Leute normalerweise jede Zeile in einer Tabelle zu einer einzigen durch Kommas getrennten verketten string, aber deshalb habe ich in meinem vorherigen Beitrag nach Ihrem/Ihren Anwendungsfall(en) gefragt.
- Für die Bestelltests habe ich keinen Index erstellt, der hilfreich sein könnte (oder irgendetwas ausprobieren, wo alle Daten aus einer einzigen Tabelle stammen).
In diesem Beitrag werde ich mich mit einigen dieser Punkte befassen, aber nicht mit allen.
FÜR XML-PFAD
Ich hatte Folgendes verwendet:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Nach diesem Kommentar von Mikael habe ich meinen Code aktualisiert, um stattdessen dieses etwas andere Konstrukt zu verwenden:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs. Windows
Anfangs hatte ich mir nur die Mühe gemacht, Tests unter Windows durchzuführen:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Aber Grzegorz machte deutlich, dass er (und vermutlich viele andere) nur Zugriff auf die Linux-Variante von CTP 1.1 hatte. Also habe ich Linux zu meiner Testmatrix hinzugefügt:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Einige interessante, aber völlig nebensächliche Beobachtungen:
@@VERSIONzeigt in diesem Build nicht die Edition, sondernSERVERPROPERTY('Edition')gibt die erwarteteDeveloper Edition (64-bit)zurück .- Basierend auf den Build-Zeiten, die in den Binärdateien kodiert sind, scheinen die Windows- und Linux-Versionen jetzt zur gleichen Zeit und aus der gleichen Quelle kompiliert worden zu sein. Oder es war ein verrückter Zufall.
Ungeordnete Tests
Ich habe damit begonnen, die willkürlich geordnete Ausgabe zu testen (wo es keine explizit definierte Reihenfolge für die verketteten Werte gibt). Nach Grzegorz habe ich WideWorldImporters (Standard) verwendet, aber eine Verknüpfung zwischen Sales.Orders durchgeführt und Sales.OrderLines . Die fiktive Anforderung hier ist, eine Liste aller Bestellungen auszugeben und zusammen mit jeder Bestellung eine kommaseparierte Liste jeder StockItemID .
Seit StockItemID eine ganze Zahl ist, können wir einen definierten varchar verwenden , was bedeutet, dass die Zeichenfolge 8000 Zeichen lang sein kann, bevor wir uns Gedanken darüber machen müssen, ob wir MAX benötigen. Da ein int eine maximale Länge von 11 (eigentlich 10, wenn vorzeichenlos) plus ein Komma haben kann, bedeutet dies, dass eine Bestellung im schlimmsten Fall etwa 8.000/12 (666) Lagerartikel unterstützen müsste (z. B. alle StockItemID-Werte haben 11 Ziffern). In unserem Fall ist die längste ID 3-stellig, sodass wir bis zum Hinzufügen von Daten tatsächlich 8.000/4 (2.000) eindeutige Lagerartikel in jeder einzelnen Bestellung benötigen würden, um MAX zu rechtfertigen. In unserem Fall sind es insgesamt nur 227 Lagerartikel, also ist MAX nicht nötig, aber das sollte man im Auge behalten. Wenn in Ihrem Szenario eine so große Zeichenfolge möglich ist, müssen Sie varchar(max) verwenden anstelle der Vorgabe (STRING_AGG() gibt nvarchar(max) zurück , wird aber auf 8.000 Byte gekürzt, es sei denn, die Eingabe ist ein MAX-Typ).
Die anfänglichen Abfragen (um eine Beispielausgabe anzuzeigen und die Dauer für einzelne Ausführungen zu beobachten):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Ich habe die Analyse- und Kompilierzeitdaten vollständig ignoriert, da sie immer genau null oder nahe genug waren, um irrelevant zu sein. Es gab geringfügige Abweichungen in den Ausführungszeiten für jeden Lauf, aber nicht viel – die obigen Kommentare spiegeln das typische Delta in der Laufzeit wider (STRING_AGG schien dort einen kleinen Vorteil aus der Parallelität zu ziehen, aber nur unter Linux, während FOR XML PATH nicht auf beiden Plattformen). Beide Maschinen hatten einen Single-Socket, eine Quad-Core-CPU, 8 GB Arbeitsspeicher, eine sofort einsatzbereite Konfiguration und keine andere Aktivität.
Dann wollte ich in großem Maßstab testen (einfach eine einzelne Sitzung, die dieselbe Abfrage 500 Mal ausführt). Ich wollte nicht die gesamte Ausgabe wie in der obigen Abfrage 500 Mal zurückgeben, da dies SSMS überfordert hätte – und hoffentlich sowieso keine realen Abfrageszenarien darstellt. Also habe ich die Ausgabe Variablen zugewiesen und nur die Gesamtzeit für jeden Batch gemessen:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Ich habe diese Tests dreimal durchgeführt, und der Unterschied war tiefgreifend – fast eine Größenordnung. Hier ist die durchschnittliche Dauer der drei Tests:
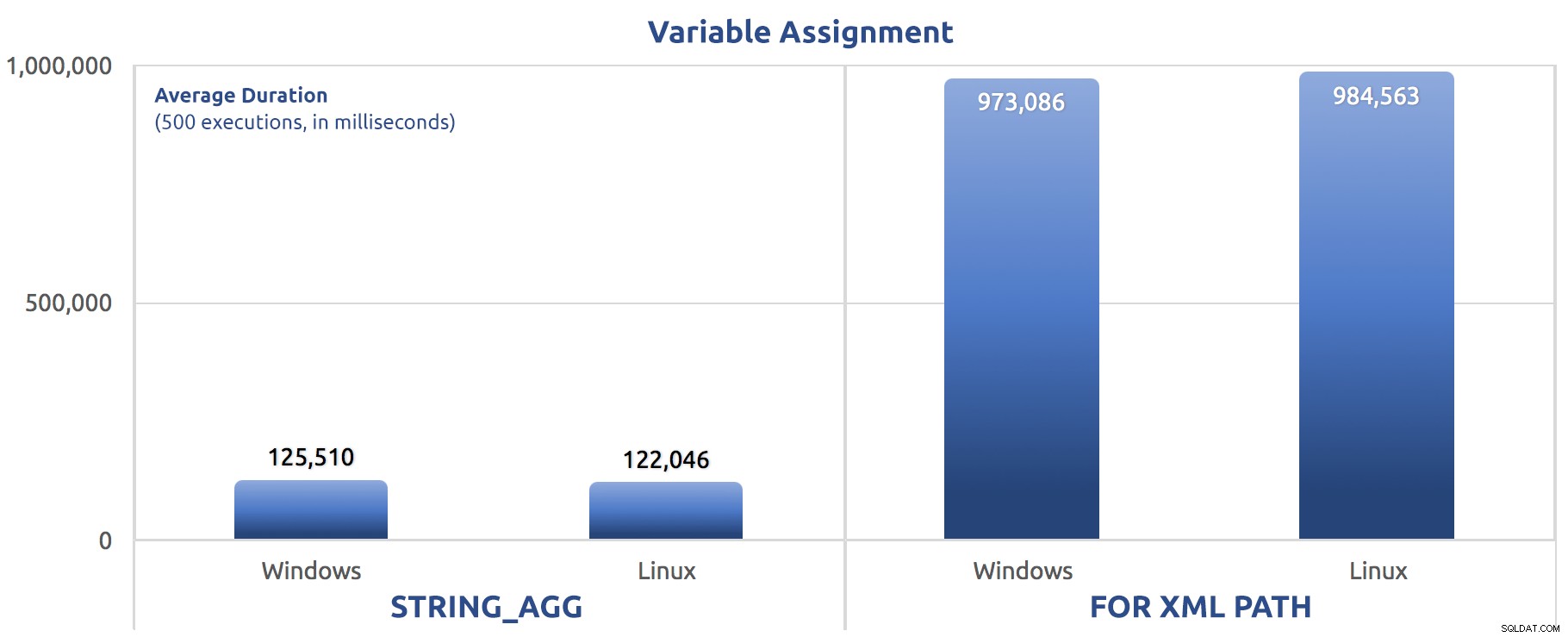 Durchschnittliche Dauer in Millisekunden für 500 Ausführungen von Variablenzuweisungen
Durchschnittliche Dauer in Millisekunden für 500 Ausführungen von Variablenzuweisungen
Ich habe auch eine Vielzahl anderer Dinge auf diese Weise getestet, hauptsächlich um sicherzustellen, dass ich die Arten von Tests abdecke, die Grzegorz durchführte (ohne den LOB-Teil).
- Nur die Länge der Ausgabe auswählen
- Abrufen der maximalen Länge der Ausgabe (einer beliebigen Zeile)
- Auswählen der gesamten Ausgabe in einer neuen Tabelle
Nur die Länge der Ausgabe auswählen
Dieser Code durchläuft lediglich jede Bestellung, verkettet alle StockItemID-Werte und gibt dann nur die Länge zurück.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Auch für die Batch-Version habe ich die Variablenzuweisung verwendet, anstatt zu versuchen, viele Resultsets an SSMS zurückzugeben. Die Variablenzuweisung würde in einer beliebigen Zeile landen, aber dies erfordert immer noch vollständige Scans, da die beliebige Zeile nicht zuerst ausgewählt wird.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Leistungsmetriken von 500 Ausführungen:
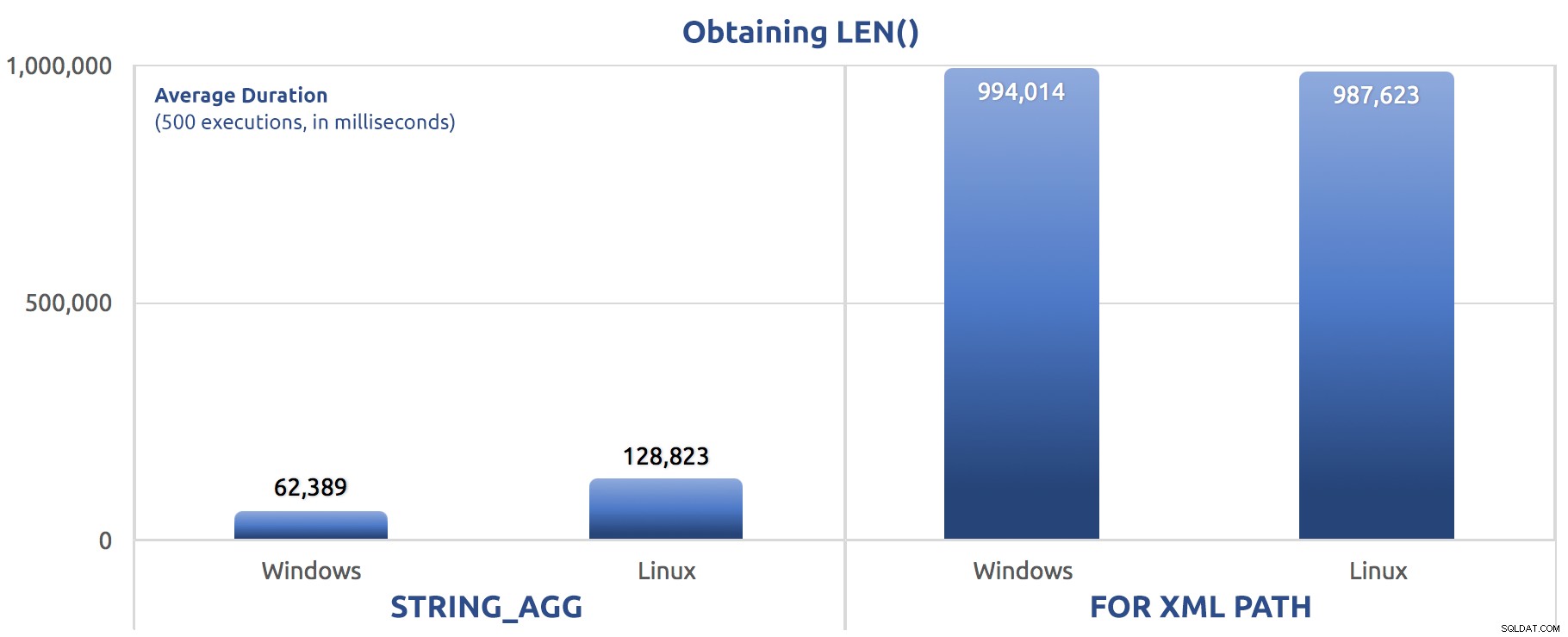 500 Ausführungen zum Zuweisen von LEN() zu einer Variablen
500 Ausführungen zum Zuweisen von LEN() zu einer Variablen
Wieder sehen wir FOR XML PATH ist viel langsamer, sowohl unter Windows als auch unter Linux.
Auswahl der maximalen Länge der Ausgabe
Eine leichte Variation des vorherigen Tests, dieser ruft nur das Maximum ab Länge der verketteten Ausgabe:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Und bei der Skalierung weisen wir diese Ausgabe einfach wieder einer Variablen zu:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Leistungsergebnisse für 500 Ausführungen, gemittelt über drei Läufe:
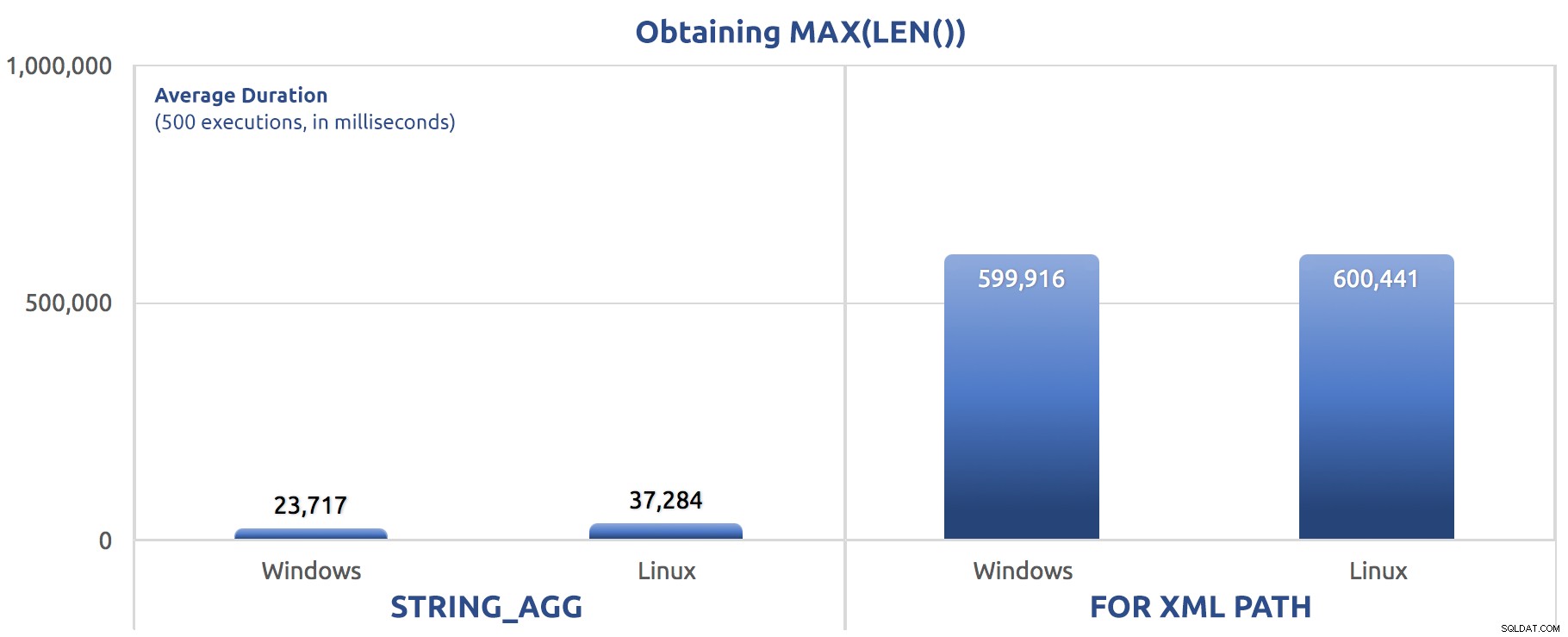 500 Ausführungen zum Zuweisen von MAX(LEN()) zu einer Variablen
500 Ausführungen zum Zuweisen von MAX(LEN()) zu einer Variablen
Möglicherweise bemerken Sie bei diesen Tests ein Muster – FOR XML PATH ist immer ein Hund, auch mit den in meinem vorherigen Post vorgeschlagenen Leistungsverbesserungen.
AUSWÄHLEN IN
Ich wollte sehen, ob die Methode der Verkettung einen Einfluss auf das Schreiben hat die Daten zurück auf die Festplatte, wie es in einigen anderen Szenarien der Fall ist:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
In diesem Fall sehen wir vielleicht SELECT INTO konnte etwas Parallelität ausnutzen, aber wir sehen immer noch FOR XML PATH kämpfen, mit Laufzeiten, die um eine Größenordnung länger sind als STRING_AGG .
Die Batch-Version hat lediglich die SET STATISTICS-Befehle für SELECT sysdatetime(); ausgetauscht und denselben GO 500 hinzugefügt nach den beiden Hauptchargen wie bei den vorherigen Tests. So hat sich das entwickelt (sagen Sie mir noch einmal, ob Sie das schon einmal gehört haben):
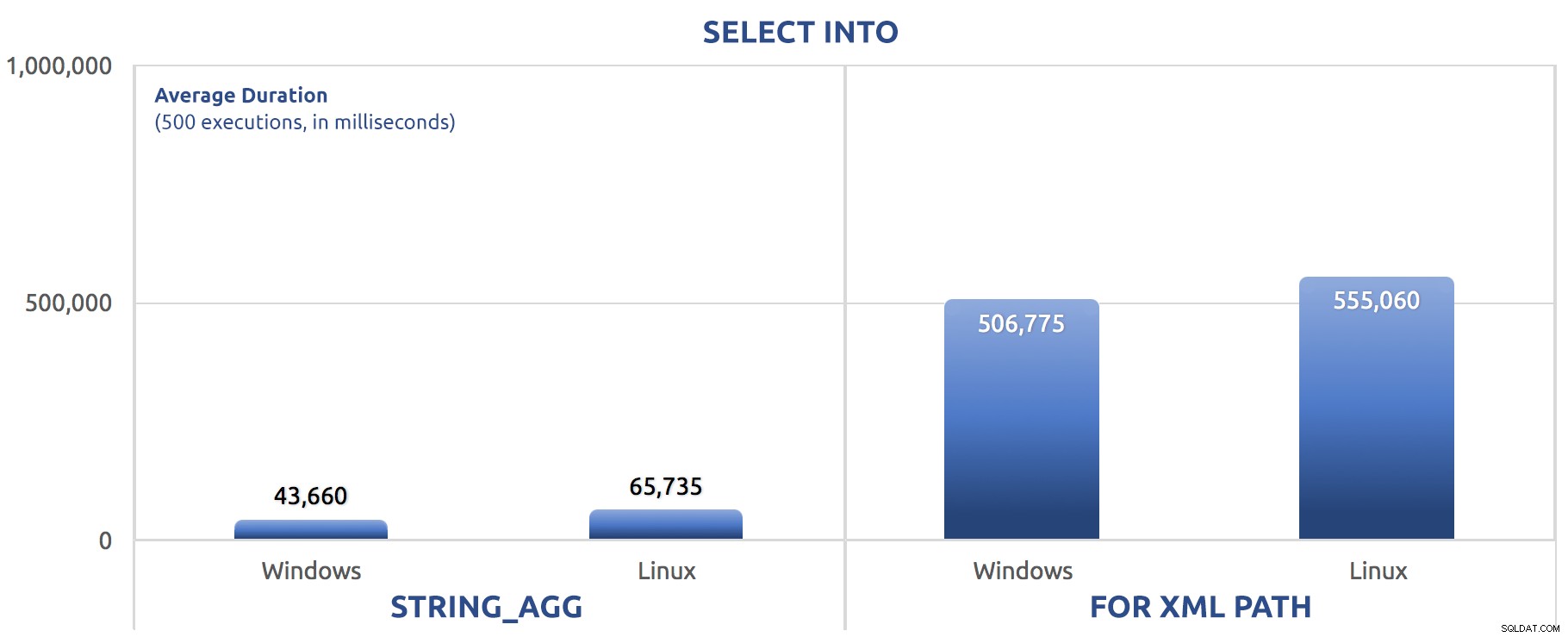 500 Ausführungen von SELECT INTO
500 Ausführungen von SELECT INTO
Bestellte Tests
Ich habe die gleichen Tests mit der geordneten Syntax durchgeführt, z. B.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Dies hatte nur sehr geringe Auswirkungen auf irgendetwas – derselbe Satz von vier Prüfständen zeigte durchweg nahezu identische Metriken und Muster.
Ich bin gespannt, ob dies anders ist, wenn die verkettete Ausgabe in Nicht-LOB ist oder wo die Verkettung Zeichenfolgen (mit oder ohne unterstützenden Index) ordnen muss.
Schlussfolgerung
Für Nicht-LOB-Strings , ist mir klar, dass STRING_AGG hat einen deutlichen Leistungsvorteil gegenüber FOR XML PATH , sowohl unter Windows als auch unter Linux. Beachten Sie dies, um die Anforderung von varchar(max) zu vermeiden oder nvarchar(max) , habe ich nichts Ähnliches wie die von Grzegorz durchgeführten Tests verwendet, was bedeutet hätte, einfach alle Werte einer Spalte über eine ganze Tabelle hinweg zu einer einzigen Zeichenfolge zu verketten. In meinem nächsten Beitrag schaue ich mir den Anwendungsfall an, bei dem die Ausgabe der verketteten Zeichenfolge möglicherweise größer als 8.000 Bytes sein könnte und daher LOB-Typen und Konvertierungen verwendet werden müssten.