@rob_farley Ihre aktuelle Stackoverflow-Lösung, um zuerst nach einem Wert und dann nach einem Feld zu sortieren Genius! Wollte Ihnen persönlich danken.
– Joel Sacco (@Jsac90) 11. August 2016
Ich habe diesen Tweet gesehen…
Und es brachte mich dazu, zu sehen, worauf es sich bezog, weil ich in letzter Zeit nichts über das Bestellen von Daten auf StackOverflow geschrieben hatte. Es stellte sich heraus, dass es diese Antwort war, die ich geschrieben hatte , was zwar nicht die akzeptierte Antwort war, aber über hundert Stimmen gesammelt hat.
Die Person, die die Frage stellte, hatte ein sehr einfaches Problem – sie wollte, dass bestimmte Zeilen zuerst erscheinen. Und meine Lösung war einfach:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Es scheint eine beliebte Antwort gewesen zu sein, auch für Joel Sacco (laut obigem Tweet).
Die Idee ist, einen Ausdruck zu bilden und danach zu ordnen. ORDER BY kümmert sich nicht darum, ob es sich um eine tatsächliche Spalte handelt oder nicht. Sie hätten dasselbe mit APPLY tun können, wenn Sie es wirklich vorziehen, eine 'Spalte' in Ihrer ORDER BY-Klausel zu verwenden.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Wenn ich einige Abfragen gegen WideWorldImporters verwende, kann ich Ihnen zeigen, warum diese beiden Abfragen wirklich genau gleich sind. Ich werde die Sales.Orders-Tabelle abfragen und darum bitten, dass zuerst die Orders for Salesperson 7 angezeigt werden. Ich werde auch einen geeigneten abdeckenden Index erstellen:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Die Pläne für diese beiden Abfragen sehen identisch aus. Sie funktionieren identisch – dieselben Lesevorgänge, dieselben Ausdrücke, sie sind wirklich dieselbe Abfrage. Wenn es einen kleinen Unterschied in der tatsächlichen CPU oder Dauer gibt, dann ist das aufgrund anderer Faktoren ein Zufall.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
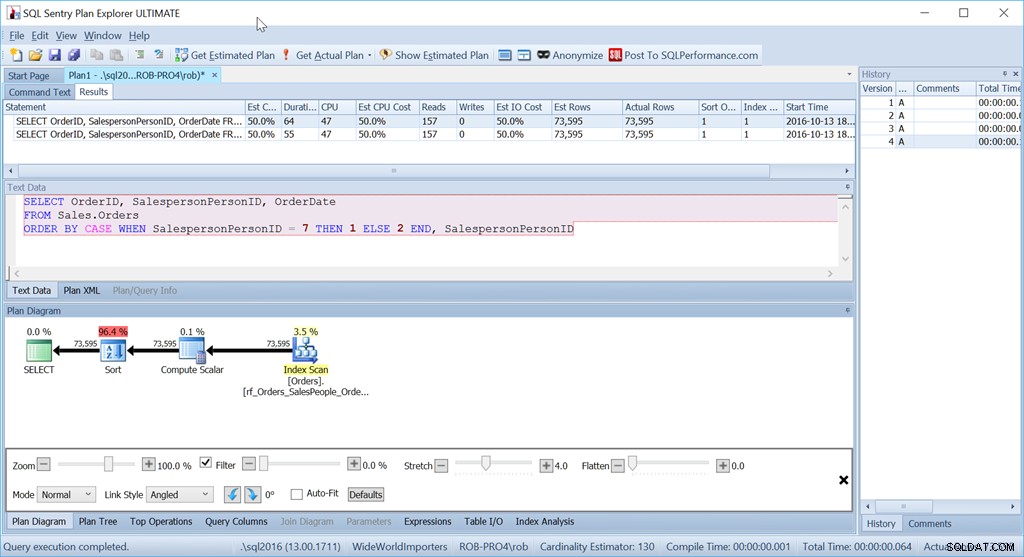
Und doch ist dies nicht die Abfrage, die ich in dieser Situation tatsächlich verwenden würde. Nicht, wenn mir Leistung wichtig wäre. (Normalerweise ist es das auch, aber es lohnt sich nicht immer, eine lange Abfrage zu schreiben, wenn die Datenmenge gering ist.)
Was mich stört, ist dieser Sort-Operator. Es sind 96,4 % der Kosten!
Überlegen Sie, ob wir einfach nach SalespersonPersonID bestellen möchten:
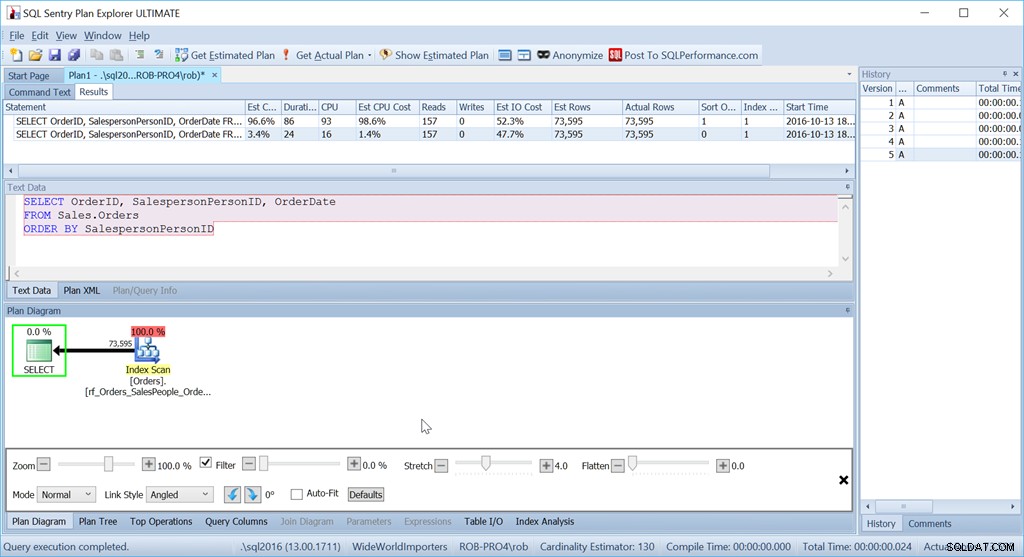
Wir sehen, dass die geschätzten CPU-Kosten dieser einfacheren Abfrage 1,4 % des Batches betragen, während die der benutzerdefinierten sortierten Version 98,6 % beträgt. Das ist SIEBZIG MAL schlimmer. Reads sind aber die gleichen – das ist gut. Die Dauer ist viel schlechter, und die CPU auch.
Ich mag Sorts nicht. Sie können böse sein.
Eine Option, die ich hier habe, besteht darin, meiner Tabelle eine berechnete Spalte hinzuzufügen und diese zu indizieren, aber das wird sich auf alles auswirken, was nach allen Spalten in der Tabelle sucht, wie z. B. ORMs, Power BI oder alles, was SELECT * . Das ist also nicht so toll (obwohl, wenn wir jemals versteckte berechnete Spalten hinzufügen könnten, wäre das hier eine wirklich nette Option).
Eine andere Option, die langatmiger ist (einige könnten meinen, das würde mir passen – und wenn Sie das dachten:Oi! Sei nicht so unhöflich!) und mehr Lesevorgänge benötigt, ist zu überlegen, was wir im wirklichen Leben tun würden, wenn wir mussten das tun.
Wenn ich einen Stapel von 73.595 Bestellungen hätte, sortiert nach Verkäuferreihenfolge, und ich sie zuerst mit einem bestimmten Verkäufer zurückgeben müsste, würde ich die Reihenfolge, in der sie sich befinden, nicht missachten und sie einfach alle sortieren, ich würde mit dem Eintauchen beginnen und die für Verkäufer 7 zu finden – sie in der Reihenfolge zu halten, in der sie waren. Dann würde ich diejenigen finden, die nicht die waren, die nicht Verkäufer 7 waren – sie als nächstes platzieren und wieder in der Reihenfolge belassen, in der sie bereits waren ein.
In T-SQL wird das so gemacht:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Dies erhält zwei Datensätze und verkettet sie. Aber der Abfrageoptimierer erkennt, dass er die SalespersonPersonID-Reihenfolge beibehalten muss, sobald die beiden Sätze verkettet sind, also führt er eine spezielle Art der Verkettung durch, die diese Reihenfolge beibehält. Es handelt sich um einen Merge Join (Concatenation) Join, und der Plan sieht folgendermaßen aus:
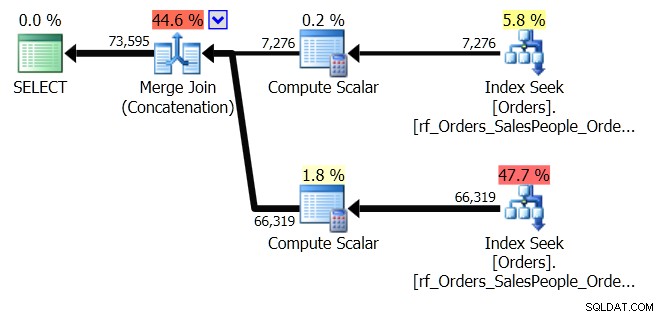
Sie sehen, es ist viel komplizierter. Aber hoffentlich fällt Ihnen auch auf, dass es keinen Sort-Operator gibt. Der Merge Join (Concatenation) zieht die Daten aus jedem Zweig und erzeugt einen Datensatz in der richtigen Reihenfolge. In diesem Fall werden zuerst alle 7.276 Zeilen für Salesperson 7 und dann die anderen 66.319 abgerufen, da dies die erforderliche Reihenfolge ist. Innerhalb jedes Satzes befinden sich die Daten in der Reihenfolge SalespersonPersonID, die beibehalten wird, während die Daten durchlaufen werden.
Ich habe bereits erwähnt, dass es mehr Lesevorgänge verwendet, und das tut es auch. Wenn ich die SET STATISTICS IO-Ausgabe zeige und die beiden Abfragen vergleiche, sehe ich Folgendes:
Tabelle 'Arbeitstisch'. Scan-Zähler 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.Tabelle 'Bestellungen'. Scan-Zähler 1, logische Lesevorgänge 157, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Lesevorgänge 0.
Tabelle 'Bestellungen '. Scan-Anzahl 3, logische Lesevorgänge 163, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Bei Verwendung der Version „Benutzerdefinierte Sortierung“ ist es nur ein Scan des Indexes mit 157 Lesevorgängen. Mit der „Union All“-Methode sind es drei Scans – einer für SalespersonPersonID =7, einer für SalespersonPersonID <7 und einer für SalespersonPersonID> 7. Wir können die letzten beiden sehen, indem wir uns die Eigenschaften des zweiten Index Seek ansehen:
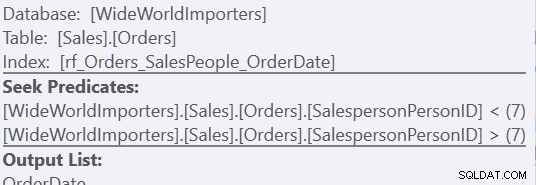
Für mich liegt der Vorteil jedoch im Fehlen einer Arbeitstabelle.
Sehen Sie sich die geschätzten CPU-Kosten an:

Es ist nicht so wenig wie unsere 1,4 %, wenn wir die Sortierung vollständig vermeiden, aber es ist immer noch eine enorme Verbesserung gegenüber unserer benutzerdefinierten Sortiermethode.
Aber ein Wort der Warnung…
Angenommen, ich hätte diesen Index anders erstellt und OrderDate als Schlüsselspalte und nicht als eingeschlossene Spalte gehabt.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Nun, meine "Union All"-Methode funktioniert überhaupt nicht wie beabsichtigt.
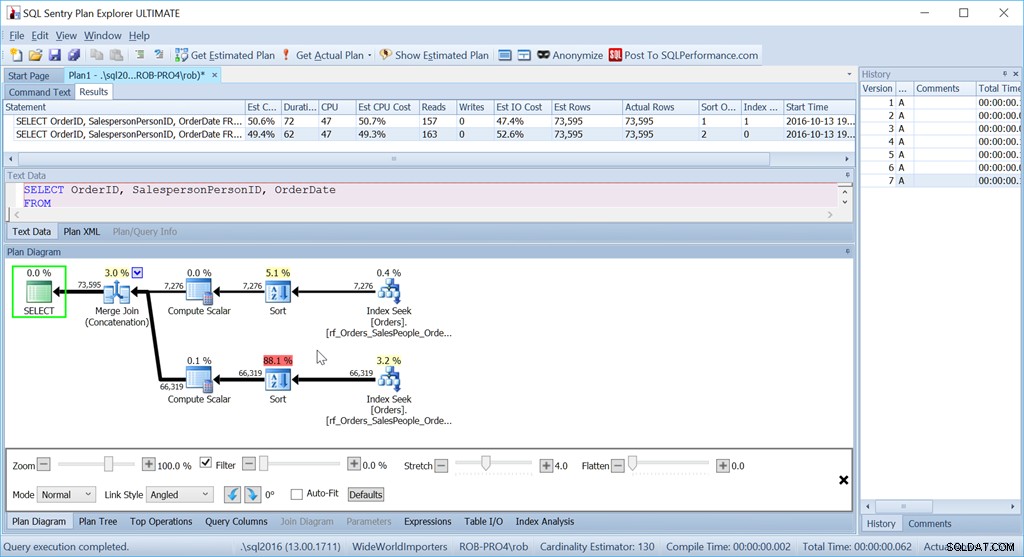
Obwohl ich genau die gleichen Abfragen wie zuvor verwende, hat mein netter Plan jetzt zwei Sort-Operatoren und ist fast so schlecht wie meine ursprüngliche Scan + Sort-Version.
Der Grund dafür ist eine Eigenart des Merge Join (Concatenation)-Operators, und der Hinweis liegt im Sort-Operator.

Es wird nach SalespersonPersonID bestellt, gefolgt von OrderID – dem Clustered-Index-Schlüssel der Tabelle. Es wählt dies aus, weil dies bekanntermaßen eindeutig ist und es sich um eine kleinere Gruppe von Spalten handelt, nach denen sortiert werden muss, als nach SalespersonPersonID, gefolgt von OrderDate, gefolgt von OrderID, was die Dataset-Reihenfolge ist, die von drei Indexbereichsscans erzeugt wird. Einer dieser Fälle, in denen der Abfrageoptimierer keine bessere Option erkennt, die genau da ist.
Mit diesem Index benötigen wir unseren Datensatz auch nach OrderDate, um unseren bevorzugten Plan zu erstellen.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
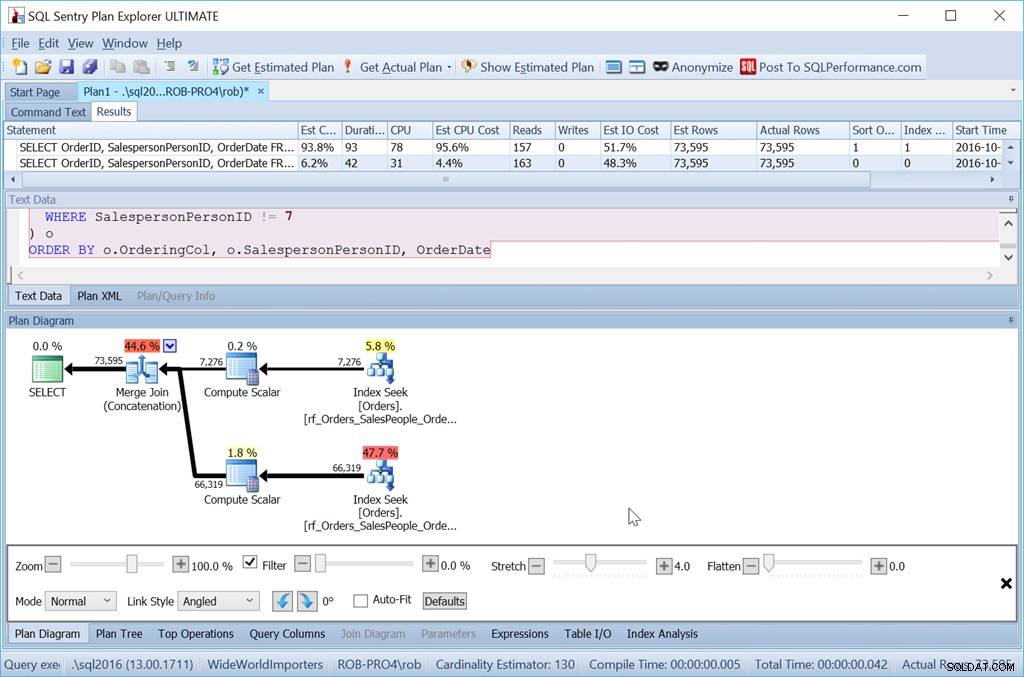
Es ist also definitiv mehr Aufwand. Die Abfrage ist für mich länger zum Schreiben, es sind mehr Lesevorgänge und ich muss einen Index ohne zusätzliche Schlüsselspalten haben. Aber es geht sicher schneller. Mit noch mehr Zeilen ist die Wirkung noch größer, und ich muss auch nicht riskieren, dass Sort auf tempdb überläuft.
Für kleine Sets ist meine StackOverflow-Antwort immer noch gut. Aber wenn mich dieser Sort-Operator an Leistung kostet, dann verwende ich die Methode Union All / Merge Join (Concatenation).