Die Fensterfunktion ROW_NUMBER hat zahlreiche praktische Anwendungen, die weit über die offensichtlichen Ranking-Anforderungen hinausgehen. Wenn Sie Zeilennummern berechnen, müssen Sie sie meistens in einer bestimmten Reihenfolge berechnen, und Sie geben die gewünschte Sortierspezifikation in der Fensterreihenfolgeklausel der Funktion an. Es gibt jedoch Fälle, in denen Sie Zeilennummern in keiner bestimmten Reihenfolge berechnen müssen; mit anderen Worten, basierend auf einer nichtdeterministischen Ordnung. Dies kann über das gesamte Abfrageergebnis oder innerhalb von Partitionen erfolgen. Beispiele hierfür sind das Zuweisen eindeutiger Werte zu Ergebniszeilen, das Deduplizieren von Daten und das Zurückgeben einer beliebigen Zeile pro Gruppe.
Beachten Sie, dass das Zuweisen von Zeilennummern basierend auf einer nicht deterministischen Reihenfolge anders ist als das Zuweisen von Zeilennummern basierend auf einer zufälligen Reihenfolge. Bei Ersterem ist es Ihnen einfach egal, in welcher Reihenfolge sie zugewiesen werden und ob wiederholte Ausführungen der Abfrage immer dieselben Zeilennummern denselben Zeilen zuweisen oder nicht. Bei letzterem erwarten Sie, dass wiederholte Ausführungen ständig ändern, welche Zeilen welchen Zeilennummern zugewiesen werden. In diesem Artikel werden verschiedene Techniken zum Berechnen von Zeilennummern mit nicht deterministischer Reihenfolge untersucht. Die Hoffnung ist, eine Technik zu finden, die sowohl zuverlässig als auch optimal ist.
Besonderen Dank an Paul White für den Tipp zum konstanten Falten, für die laufzeitkonstante Technik und dafür, dass er immer eine großartige Informationsquelle ist!
Wenn Ordnung zählt
Ich beginne mit Fällen, in denen die Reihenfolge der Zeilennummern eine Rolle spielt.
In meinen Beispielen verwende ich eine Tabelle namens T1. Verwenden Sie den folgenden Code, um diese Tabelle zu erstellen und mit Beispieldaten zu füllen:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Betrachten Sie die folgende Abfrage (wir nennen sie Abfrage 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Hier möchten Sie, dass Zeilennummern innerhalb jeder Gruppe zugewiesen werden, die durch die Spalte grp identifiziert wird, geordnet nach der Spalte datacol. Als ich diese Abfrage auf meinem System ausführte, erhielt ich die folgende Ausgabe:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Zeilennummern werden hier in teilweise deterministischer und teilweise nicht deterministischer Reihenfolge vergeben. Damit meine ich, dass Sie sicher sein können, dass innerhalb derselben Partition eine Zeile mit einem größeren Datacol-Wert einen größeren Zeilennummernwert erhält. Da Datacol jedoch innerhalb der Grp-Partition nicht eindeutig ist, ist die Reihenfolge der Zuweisung von Zeilennummern zwischen Zeilen mit denselben Grp- und Datacol-Werten nicht deterministisch. Dies ist bei den Zeilen mit den ID-Werten 2 und 11 der Fall. Beide haben den Grp-Wert A und den Datacol-Wert 50. Als ich diese Abfrage zum ersten Mal auf meinem System ausgeführt habe, erhielt die Zeile mit der ID 2 die Zeilennummer 2 und die Die Zeile mit der ID 11 hat die Zeilennummer 3. Vergessen Sie die Wahrscheinlichkeit, dass dies in der Praxis in SQL Server passiert. Wenn ich die Abfrage erneut ausführe, könnte theoretisch der Zeile mit der ID 2 die Zeilennummer 3 und der Zeile mit der ID 11 die Zeilennummer 2 zugewiesen werden.
Wenn Sie Zeilennummern basierend auf einer vollständig deterministischen Reihenfolge zuweisen müssen, um wiederholbare Ergebnisse über die Ausführungen der Abfrage hinweg zu garantieren, solange sich die zugrunde liegenden Daten nicht ändern, muss die Kombination der Elemente in den Klauseln für die Fensterpartitionierung und -reihenfolge eindeutig sein. Dies könnte in unserem Fall erreicht werden, indem die Spalten-ID als Tiebreaker zur Fensterreihenfolgeklausel hinzugefügt wird. Die OVER-Klausel wäre dann:
OVER (PARTITION BY grp ORDER BY datacol, id)
Auf jeden Fall muss SQL Server bei der Berechnung von Zeilennummern basierend auf einer sinnvollen Sortierspezifikation wie in Abfrage 1 die Zeilen verarbeiten, die durch die Kombination von Fensterpartitionierung und Sortierelementen geordnet sind. Dies kann entweder durch Abrufen der vorgeordneten Daten aus einem Index oder durch Sortieren der Daten erreicht werden. Im Moment gibt es keinen Index auf T1, um die ROW_NUMBER-Berechnung in Abfrage 1 zu unterstützen, daher muss sich SQL Server für das Sortieren der Daten entscheiden. Dies ist im Plan für Abfrage 1 in Abbildung 1 zu sehen.
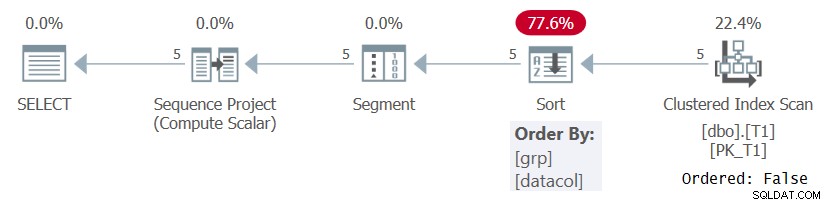 Abbildung 1:Plan für Abfrage 1 ohne unterstützenden Index
Abbildung 1:Plan für Abfrage 1 ohne unterstützenden Index
Beachten Sie, dass der Plan die Daten aus dem Clustered-Index mit einer Ordered:False-Eigenschaft scannt. Das bedeutet, dass der Scan die nach dem Indexschlüssel geordneten Zeilen nicht zurückgeben muss. Dies ist der Fall, da der Clustered Index hier nur verwendet wird, weil er die Abfrage zufällig abdeckt, und nicht wegen seiner Schlüsselreihenfolge. Der Plan wendet dann eine Sortierung an, was zu zusätzlichen Kosten, N-Log-N-Skalierung und verzögerter Antwortzeit führt. Der Segment-Operator erzeugt ein Flag, das angibt, ob die Zeile die erste in der Partition ist oder nicht. Schließlich weist der Sequence Project-Operator Zeilennummern beginnend mit 1 in jeder Partition zu.
Wenn Sie das Sortieren vermeiden möchten, können Sie einen übergeordneten Index mit einer Schlüsselliste erstellen, die auf den Partitionierungs- und Sortierelementen basiert, und einer Include-Liste, die auf den übergeordneten Elementen basiert. Ich stelle mir diesen Index gerne als POC-Index vor (zur Partitionierung , Bestellen und bedecken ). Hier ist die Definition des POC, der unsere Abfrage unterstützt:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Führen Sie Abfrage 1 erneut aus:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Der Plan für diese Ausführung ist in Abbildung 2 dargestellt.
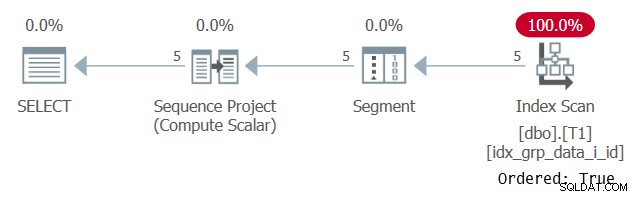 Abbildung 2:Plan für Abfrage 1 mit einem POC-Index
Abbildung 2:Plan für Abfrage 1 mit einem POC-Index
Beachten Sie, dass der Plan dieses Mal den POC-Index mit einer Ordered:True-Eigenschaft scannt. Das bedeutet, dass der Scan garantiert, dass die Zeilen in der Reihenfolge der Indexschlüssel zurückgegeben werden. Da die Daten vorgeordnet aus dem Index gezogen werden, wie es die Fensterfunktion benötigt, ist keine explizite Sortierung erforderlich. Die Skalierung dieses Plans ist linear und die Antwortzeit ist gut.
Wenn die Reihenfolge keine Rolle spielt
Etwas knifflig wird es, wenn Sie Zeilennummern mit einer völlig nicht deterministischen Reihenfolge zuweisen müssen. In einem solchen Fall ist es naheliegend, die ROW_NUMBER-Funktion ohne Angabe einer Fensterreihenfolgeklausel zu verwenden. Prüfen wir zunächst, ob der SQL-Standard dies zulässt. Hier ist der relevante Teil des Standards, der die Syntaxregeln für Fensterfunktionen definiert:
Syntaxregeln…
5) Sei WNS der
6) Wenn
a) Wenn
…
f) ROW_NUMBER() OVER WNS entspricht der
…
Beachten Sie, dass Punkt 6 die Funktionen
Probieren wir es also aus und versuchen, Zeilennummern ohne Fensterreihenfolge in SQL Server zu berechnen:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Dieser Versuch führt zu folgendem Fehler:
Msg 4112, Level 15, State 1, Line 53Die Funktion 'ROW_NUMBER' muss eine OVER-Klausel mit ORDER BY haben.
Wenn Sie die SQL Server-Dokumentation der ROW_NUMBER-Funktion überprüfen, finden Sie in der Tat den folgenden Text:
„order_by_clause“Die ORDER BY-Klausel bestimmt die Reihenfolge, in der den Zeilen ihre eindeutige ROW_NUMBER innerhalb einer angegebenen Partition zugewiesen wird. Es ist erforderlich.“
Anscheinend ist die Fensterreihenfolgeklausel für die ROW_NUMBER-Funktion in SQL Server obligatorisch. Das ist übrigens auch bei Oracle so.
Ich muss sagen, dass ich nicht sicher bin, ob ich die Gründe für diese Anforderung verstehe. Denken Sie daran, dass Sie es zulassen, Zeilennummern basierend auf einer teilweise nicht deterministischen Reihenfolge zu definieren, wie in Abfrage 1. Warum also nicht den gesamten Nichtdeterminismus zulassen? Vielleicht gibt es einen Grund, an den ich nicht denke. Wenn Ihnen ein solcher Grund einfällt, teilen Sie ihn bitte mit.
Auf jeden Fall könnten Sie argumentieren, dass Sie, wenn Sie sich nicht um die Reihenfolge kümmern, angesichts der Tatsache, dass die Fensterreihenfolgeklausel obligatorisch ist, eine beliebige Reihenfolge angeben können. Das Problem bei diesem Ansatz besteht darin, dass eine Sortierung nach Spalten der abgefragten Tabelle(n) zu unnötigen Leistungseinbußen führen kann. Wenn kein unterstützender Index vorhanden ist, zahlen Sie für die explizite Sortierung. Wenn ein unterstützender Index vorhanden ist, beschränken Sie die Speicher-Engine auf eine Scan-Strategie in Indexreihenfolge (nach der indexverknüpften Liste). Sie erlauben ihm nicht mehr Flexibilität, wie es normalerweise der Fall ist, wenn die Reihenfolge bei der Wahl zwischen einem Scan der Indexreihenfolge und einem Scan der Zuordnungsreihenfolge (basierend auf IAM-Seiten) keine Rolle spielt.
Eine Idee, die es wert ist, ausprobiert zu werden, besteht darin, eine Konstante wie 1 in der Fensterreihenfolgeklausel anzugeben. Wenn dies unterstützt wird, hoffen Sie, dass der Optimierer intelligent genug ist, um zu erkennen, dass alle Zeilen denselben Wert haben, sodass keine wirkliche Sortierrelevanz besteht und daher keine Notwendigkeit besteht, eine Sortierung oder einen Scan der Indexreihenfolge zu erzwingen. Hier ist eine Abfrage, die diesen Ansatz versucht:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Leider unterstützt SQL Server diese Lösung nicht. Es generiert den folgenden Fehler:
Msg 5308, Level 16, State 1, Line 56Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Integer-Indizes als ORDER BY-Klauselausdrücke.
Anscheinend geht SQL Server davon aus, dass, wenn Sie eine ganzzahlige Konstante in der Window-Order-Klausel verwenden, diese eine Ordinalposition eines Elements in der SELECT-Liste darstellt, wie wenn Sie eine ganze Zahl in der ORDER BY-Klausel der Präsentation angeben. Wenn dies der Fall ist, ist eine weitere Option, die es wert ist, ausprobiert zu werden, die Angabe einer nicht ganzzahligen Konstante, etwa so:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Es stellt sich heraus, dass diese Lösung ebenfalls nicht unterstützt wird. SQL Server generiert den folgenden Fehler:
Msg 5309, Level 16, State 1, Line 65Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Konstanten als ORDER BY-Klauselausdrücke.
Anscheinend unterstützt die Window-Order-Klausel keinerlei Konstanten.
Bisher haben wir Folgendes über die Relevanz der Fensterreihenfolge der ROW_NUMBER-Funktion in SQL Server gelernt:
- ORDER BY ist erforderlich.
- Kann nicht nach einer ganzzahligen Konstante sortiert werden, da SQL Server denkt, dass Sie versuchen, eine Ordinalposition in SELECT anzugeben.
- Kann nicht nach irgendeiner Konstante sortiert werden.
Die Schlussfolgerung ist, dass Sie nach Ausdrücken ordnen sollen, die keine Konstanten sind. Natürlich können Sie die abgefragten Tabellen auch nach einer Spaltenliste sortieren. Aber wir sind auf der Suche nach einer effizienten Lösung, bei der der Optimierer erkennen kann, dass es keine Bestellrelevanz gibt.
Ständige Faltung
Die bisherige Schlussfolgerung ist, dass Sie keine Konstanten in der Fensterreihenfolgeklausel von ROW_NUMBER verwenden können, aber was ist mit Ausdrücken, die auf Konstanten basieren, wie in der folgenden Abfrage:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Dieser Versuch fällt jedoch einem Prozess zum Opfer, der als Constant Folding bezeichnet wird und sich normalerweise positiv auf die Leistung von Abfragen auswirkt. Die Idee hinter dieser Technik besteht darin, die Abfrageleistung zu verbessern, indem einige Ausdrücke, die auf Konstanten basieren, in einem frühen Stadium der Abfrageverarbeitung in ihre Ergebniskonstanten gefaltet werden. Details darüber, welche Arten von Ausdrücken konstant gefaltet werden können, finden Sie hier. Unser Ausdruck 1+0 wird zu 1 gefaltet, was zu demselben Fehler führt, den Sie erhalten haben, als Sie die Konstante 1 direkt angegeben haben:
Msg 5308, Level 16, State 1, Line 79Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Integer-Indizes als ORDER BY-Klauselausdrücke.
Sie würden sich einer ähnlichen Situation gegenübersehen, wenn Sie versuchen, zwei Zeichenfolgenliterale wie folgt zu verketten:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Sie erhalten denselben Fehler wie bei der direkten Angabe des Literals „No Order“:
Msg 5309, Level 16, State 1, Line 55Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Konstanten als ORDER BY-Klauselausdrücke.
Bizarro-Welt – Fehler, die Fehler verhindern
Das Leben steckt voller Überraschungen…
Eine Sache, die ein ständiges Falten verhindert, ist, wenn der Ausdruck normalerweise zu einem Fehler führen würde. Beispielsweise kann der Ausdruck 2147483646+1 konstant gefaltet werden, da er zu einem gültigen Wert vom Typ INT führt. Folglich schlägt ein Versuch, die folgende Abfrage auszuführen, fehl:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Integer-Indizes als ORDER BY-Klauselausdrücke.
Der Ausdruck 2147483647+1 kann jedoch nicht konstant gefaltet werden, da ein solcher Versuch zu einem INT-Überlauffehler geführt hätte. Die Auswirkungen auf die Bestellung sind recht interessant. Probieren Sie die folgende Abfrage aus (wir nennen diese Abfrage 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Seltsamerweise wird diese Abfrage erfolgreich ausgeführt! Was passiert, ist, dass SQL Server einerseits keine konstante Faltung anwendet und daher die Reihenfolge auf einem Ausdruck basiert, der keine einzelne Konstante ist. Andererseits geht der Optimierer davon aus, dass der Sortierwert für alle Zeilen gleich ist, und ignoriert daher den Sortierausdruck insgesamt. Dies wird bestätigt, wenn der Plan für diese Abfrage untersucht wird, wie in Abbildung 3 gezeigt.
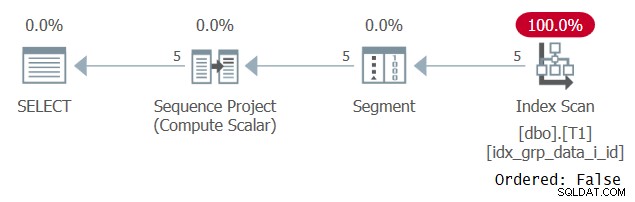 Abbildung 3:Plan für Abfrage 2
Abbildung 3:Plan für Abfrage 2
Beachten Sie, dass der Plan einen abdeckenden Index mit einer Ordered:False-Eigenschaft scannt. Genau das war unser Leistungsziel.
In ähnlicher Weise beinhaltet die folgende Abfrage einen erfolgreichen konstanten Faltungsversuch und schlägt daher fehl:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 123
Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Integer-Indizes als ORDER BY-Klauselausdrücke.
Die folgende Abfrage beinhaltet einen fehlgeschlagenen konstanten Faltungsversuch und ist daher erfolgreich, indem sie den Plan generiert, der zuvor in Abbildung 3 gezeigt wurde:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Die folgende Abfrage beinhaltet einen erfolgreichen konstanten Faltungsversuch (VARCHAR-Literal '1' wird implizit in INT 1 konvertiert, und dann wird 1 + 1 zu 2 gefaltet) und schlägt daher fehl:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 134
Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Integer-Indizes als ORDER BY-Klauselausdrücke.
Die folgende Abfrage beinhaltet einen fehlgeschlagenen konstanten Faltungsversuch (kann 'A' nicht in INT konvertieren) und ist daher erfolgreich und generiert den Plan, der zuvor in Abbildung 3 gezeigt wurde:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
Um ehrlich zu sein, obwohl diese bizarre Technik unser ursprüngliches Leistungsziel erreicht, kann ich nicht sagen, dass ich sie für sicher halte und mich daher nicht so wohl darauf verlassen kann.
Laufzeitkonstanten basierend auf Funktionen
Bei der Fortsetzung der Suche nach einer guten Lösung zum Berechnen von Zeilennummern mit nicht deterministischer Reihenfolge gibt es einige Techniken, die sicherer erscheinen als die letzte schrullige Lösung:Verwenden von Laufzeitkonstanten basierend auf Funktionen, Verwenden einer Unterabfrage basierend auf einer Konstante, Verwenden einer Alias-Spalte basierend auf eine Konstante und eine Variable verwenden.
Wie ich in T-SQL Fehler, Fallstricke und Best Practices – Determinismus – erkläre, werden die meisten Funktionen in T-SQL nur einmal pro Referenz in der Abfrage ausgewertet – nicht einmal pro Zeile. Dies ist selbst bei den meisten nichtdeterministischen Funktionen wie GETDATE und RAND der Fall. Es gibt sehr wenige Ausnahmen von dieser Regel, wie die Funktionen NEWID und CRYPT_GEN_RANDOM, die einmal pro Zeile ausgewertet werden. Die meisten Funktionen, wie GETDATE, @@SPID und viele andere, werden einmal zu Beginn der Abfrage ausgewertet, und ihre Werte werden dann als Laufzeitkonstanten betrachtet. Ein Verweis auf solche Funktionen wird nicht konstant geklappt. Diese Eigenschaften machen eine Laufzeitkonstante, die auf einer Funktion basiert, zu einer guten Wahl als Fensterordnungselement, und es scheint tatsächlich, dass T-SQL dies unterstützt. Gleichzeitig erkennt der Optimierer, dass es in der Praxis keine Sortierrelevanz gibt, wodurch unnötige Leistungseinbußen vermieden werden.
Hier ist ein Beispiel für die Verwendung der GETDATE-Funktion:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Diese Abfrage erhält denselben Plan, der zuvor in Abbildung 3 gezeigt wurde.
Hier ist ein weiteres Beispiel für die Verwendung der @@SPID-Funktion (die die aktuelle Sitzungs-ID zurückgibt):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Was ist mit der Funktion PI? Versuchen Sie die folgende Abfrage:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Dieser schlägt mit folgendem Fehler fehl:
Msg 5309, Level 16, State 1, Line 153Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Konstanten als ORDER BY-Klauselausdrücke.
Funktionen wie GETDATE und @@SPID werden einmal pro Ausführung des Plans neu ausgewertet, sodass sie nicht ständig gefaltet werden können. PI stellt immer dieselbe Konstante dar und wird daher konstant gefaltet.
Wie bereits erwähnt, gibt es nur sehr wenige Funktionen, die einmal pro Zeile ausgewertet werden, z. B. NEWID und CRYPT_GEN_RANDOM. Dies macht sie zu einer schlechten Wahl als Fensterordnungselement, wenn Sie eine nichtdeterministische Ordnung benötigen – nicht zu verwechseln mit einer zufälligen Ordnung. Warum eine unnötige Sortierstrafe zahlen?
Hier ist ein Beispiel für die Verwendung der NEWID-Funktion:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Der Plan für diese Abfrage ist in Abbildung 4 dargestellt und bestätigt, dass SQL Server eine explizite Sortierung basierend auf dem Ergebnis der Funktion hinzugefügt hat.
 Abbildung 4:Plan für Abfrage 3
Abbildung 4:Plan für Abfrage 3
Wenn Sie möchten, dass die Zeilennummern in zufälliger Reihenfolge zugewiesen werden, ist dies auf jeden Fall die Technik, die Sie verwenden möchten. Sie müssen sich nur darüber im Klaren sein, dass die Sortierkosten anfallen.
Eine Unterabfrage verwenden
Sie können auch eine auf einer Konstante basierende Unterabfrage als Fensterordnungsausdruck verwenden (z. B. ORDER BY (SELECT 'No Order')). Auch bei dieser Lösung erkennt der Optimierer von SQL Server, dass es keine Sortierrelevanz gibt, und erzwingt daher keine unnötige Sortierung oder beschränkt die Auswahlmöglichkeiten der Speicher-Engine auf solche, die die Reihenfolge garantieren müssen. Versuchen Sie, die folgende Abfrage als Beispiel auszuführen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Sie erhalten denselben Plan, der zuvor in Abbildung 3 gezeigt wurde.
Einer der großen Vorteile dieser Technik ist, dass Sie Ihre eigene persönliche Note hinzufügen können. Vielleicht magst du NULLen wirklich:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Vielleicht gefällt Ihnen eine bestimmte Nummer wirklich:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Vielleicht möchten Sie jemandem eine Nachricht senden:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Du verstehst es.
Machbar, aber umständlich
Es gibt ein paar Techniken, die funktionieren, aber etwas umständlich sind. Eine besteht darin, einen Spaltenalias für einen Ausdruck zu definieren, der auf einer Konstante basiert, und diesen Spaltenalias dann als Fensterordnungselement zu verwenden. Dies kann entweder mit einem Tabellenausdruck oder mit dem CROSS APPLY-Operator und einem Tabellenwertkonstruktor erfolgen. Hier ist ein Beispiel für Letzteres:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Sie erhalten denselben Plan, der zuvor in Abbildung 3 gezeigt wurde.
Eine andere Möglichkeit besteht darin, eine Variable als Fensterordnungselement zu verwenden:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Diese Abfrage ruft auch den Plan ab, der zuvor in Abbildung 3 gezeigt wurde.
Was ist, wenn ich meine eigene UDF verwende?
Sie könnten denken, dass die Verwendung Ihrer eigenen UDF, die eine Konstante zurückgibt, eine gute Wahl als Fensterordnungselement sein könnte, wenn Sie eine nichtdeterministische Ordnung wünschen, aber das ist nicht der Fall. Betrachten Sie die folgende UDF-Definition als Beispiel:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Versuchen Sie, die UDF wie folgt als Fensterordnungsklausel zu verwenden (wir nennen diese eine Abfrage 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Vor SQL Server 2019 (oder parallelem Kompatibilitätsgrad <150) werden benutzerdefinierte Funktionen pro Zeile ausgewertet. Selbst wenn sie eine Konstante zurückgeben, werden sie nicht inliniert. Folglich können Sie einerseits ein solches UDF als Fensterordnungselement verwenden, andererseits führt dies jedoch zu einer Sortierstrafe. Dies wird bestätigt, indem der Plan für diese Abfrage untersucht wird, wie in Abbildung 5 gezeigt.
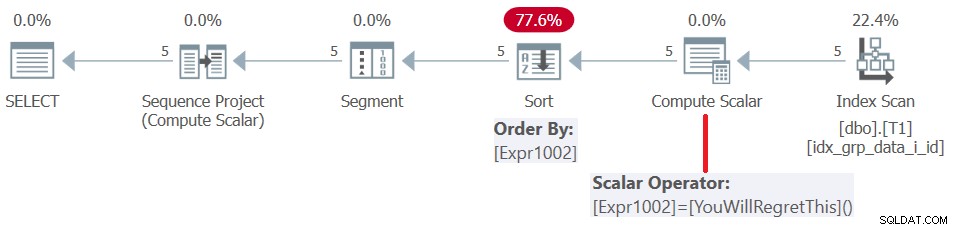 Abbildung 5:Plan für Abfrage 4
Abbildung 5:Plan für Abfrage 4
Beginnend mit SQL Server 2019, unter Kompatibilitätsstufe>=150, werden solche benutzerdefinierten Funktionen eingebettet, was meistens eine tolle Sache ist, aber in unserem Fall zu einem Fehler führt:
Msg 5309, Level 16, State 1, Line 217Fensterfunktionen, Aggregate und NEXT VALUE FOR-Funktionen unterstützen keine Konstanten als ORDER BY-Klauselausdrücke.
Die Verwendung einer UDF, die auf einer Konstante als Fensteranordnungselement basiert, erzwingt also entweder eine Sortierung oder einen Fehler, je nach verwendeter SQL Server-Version und Kompatibilitätsgrad Ihrer Datenbank. Kurz gesagt, tun Sie dies nicht.
Partitionierte Zeilennummern mit nicht deterministischer Reihenfolge
Ein häufiger Anwendungsfall für partitionierte Zeilennummern basierend auf einer nicht deterministischen Reihenfolge ist die Rückgabe einer beliebigen Zeile pro Gruppe. Da in diesem Szenario definitionsgemäß ein Partitionierungselement vorhanden ist, würden Sie denken, dass es in einem solchen Fall eine sichere Technik wäre, das Fensterpartitionierungselement auch als Fensterordnungselement zu verwenden. Als ersten Schritt berechnen Sie Zeilennummern wie folgt:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Der Plan für diese Abfrage ist in Abbildung 6 dargestellt.
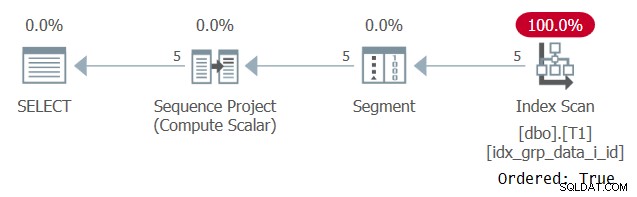 Abbildung 6:Plan für Abfrage 5
Abbildung 6:Plan für Abfrage 5
Der Grund, warum unser unterstützender Index mit einer Ordered:True-Eigenschaft gescannt wird, liegt darin, dass SQL Server die Zeilen jeder Partition als eine einzelne Einheit verarbeiten muss. Das ist vor dem Filtern der Fall. Wenn Sie nur eine Zeile pro Partition filtern, stehen Ihnen sowohl reihenfolgebasierte als auch hashbasierte Algorithmen als Optionen zur Verfügung.
Der zweite Schritt besteht darin, die Abfrage mit der Berechnung der Zeilennummer in einen Tabellenausdruck zu platzieren und in der äußeren Abfrage die Zeile mit der Zeilennummer 1 in jeder Partition zu filtern, etwa so:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Theoretisch sollte diese Technik sicher sein, aber Paul White hat einen Fehler gefunden, der zeigt, dass Sie mit dieser Methode Attribute aus verschiedenen Quellzeilen in der zurückgegebenen Ergebniszeile pro Partition erhalten können. Die Verwendung einer auf einer Funktion basierenden Laufzeitkonstante oder einer auf einer Konstanten basierenden Unterabfrage als Ordnungselement scheint selbst bei diesem Szenario sicher zu sein, stellen Sie also sicher, dass Sie stattdessen eine Lösung wie die folgende verwenden:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Niemand darf diesen Weg ohne meine Erlaubnis passieren
Der Versuch, Zeilennummern basierend auf einer nicht deterministischen Reihenfolge zu berechnen, ist ein häufiger Bedarf. Es wäre schön gewesen, wenn T-SQL die Window-Order-Klausel einfach für die ROW_NUMBER-Funktion optional gemacht hätte, aber das ist nicht der Fall. Wenn nicht, wäre es schön gewesen, wenn es zumindest erlaubt hätte, eine Konstante als Ordnungselement zu verwenden, aber das ist auch keine unterstützte Option. Aber wenn Sie nett fragen, in Form einer Unterabfrage, die auf einer Konstante basiert, oder einer Laufzeitkonstante, die auf einer Funktion basiert, wird SQL Server dies zulassen. Das sind die beiden Optionen, mit denen ich mich am wohlsten fühle. Ich fühle mich mit den skurrilen fehlerhaften Ausdrücken, die zu funktionieren scheinen, nicht wirklich wohl, daher kann ich diese Option nicht empfehlen.