Im Allgemeinen ist die beste Art von Sortierung eine, die vollständig vermieden wird. Durch sorgfältige Indizierung und manchmal etwas kreatives Schreiben von Abfragen können wir häufig die Notwendigkeit eines Sort-Operators aus Ausführungsplänen entfernen. Wenn die zu sortierenden Daten umfangreich sind, kann das Vermeiden dieser Art von Sortierung zu erheblichen Leistungsverbesserungen führen.
Die zweitbeste Art von Sort ist diejenige, die wir nicht vermeiden können, die jedoch eine angemessene Menge an Speicher reserviert und den gesamten oder den größten Teil davon verwendet, um etwas Sinnvolles zu tun. wertvoll sein kann viele Formen annehmen. Manchmal kann sich eine Sortierung mehr als bezahlt machen, indem sie eine spätere Operation ermöglicht, die bei sortierter Eingabe viel effizienter arbeitet. In anderen Fällen ist das Sortieren einfach notwendig und wir müssen es nur so effizient wie möglich gestalten.
Dann kommen die Sorts, die wir normalerweise vermeiden möchten:diejenigen, die viel mehr Speicher reservieren, als sie benötigen, und diejenigen, die zu wenig reservieren. Der letztere Fall ist derjenige, auf den sich die meisten Menschen konzentrieren. Wenn nicht genügend Speicher reserviert (oder verfügbar) ist, um die erforderliche Sortieroperation im Speicher abzuschließen, wird ein Sort-Operator, mit wenigen Ausnahmen, Datenzeilen an tempdb übergeben . In Wirklichkeit bedeutet dies fast immer, Sortierseiten in den physischen Speicher zu schreiben (und sie später natürlich wieder einzulesen).
In modernen Versionen von SQL Server führt eine verschüttete Sortierung zu einem Warnsymbol in Post-Execution-Plänen, das Details darüber enthalten kann, wie viele Daten verschüttet wurden, wie viele Threads beteiligt waren und wie hoch die Verschüttung war.
Hintergrund:Verschüttungsniveaus
Stellen Sie sich die Aufgabe vor, 4000 MB Daten zu sortieren, wenn wir nur 500 MB Speicher zur Verfügung haben. Natürlich können wir nicht den gesamten Satz im Speicher auf einmal sortieren, aber wir können die Aufgabe aufschlüsseln:
Wir lesen zuerst 500 MB Daten, sortieren diesen Satz im Speicher und schreiben dann das Ergebnis auf die Festplatte. Wenn Sie dies insgesamt 8 Mal durchführen, werden die gesamten 4000 MB Eingabe verbraucht, was zu 8 Sätzen sortierter Daten mit einer Größe von 500 MB führt. Der zweite Schritt besteht darin, eine 8-Wege-Zusammenführung der sortierten Datensätze durchzuführen. Beachten Sie, dass eine Zusammenführung erforderlich ist, nicht eine einfache Verkettung der Sets, da die Daten erst in der Zwischenstufe innerhalb eines bestimmten 500-MB-Sets garantiert wie erforderlich sortiert werden.
Im Prinzip könnten wir jeweils eine Zeile aus jedem der acht Sortierläufe lesen und zusammenführen, aber das wäre nicht sehr effizient. Stattdessen lesen wir den ersten Teil jeder Sorte zurück in den Speicher, sagen wir 60 MB. Dies verbraucht 8 x 60 MB =480 MB der 500 MB, die wir zur Verfügung haben. Wir können dann die 8-Wege-Zusammenführung für eine Weile effizient im Speicher durchführen und die endgültige sortierte Ausgabe mit den noch verfügbaren 20 MB Speicher puffern. Wenn jeder der Speicherpuffer des Sortierlaufs geleert wird, lesen wir einen neuen Abschnitt dieses Sortierlaufs in den Speicher ein. Sobald alle Sortierläufe verbraucht wurden, ist die Sortierung abgeschlossen.
Es gibt einige zusätzliche Details und Optimierungen, die wir einbeziehen können, aber das ist der grundlegende Umriss eines Lecks der Stufe 1, auch als Single-Pass-Spill bekannt. Ein einziger zusätzlicher Durchgang über die Daten ist erforderlich, um die endgültige sortierte Ausgabe zu erzeugen.
Nun könnte eine n-Wege-Zusammenführung theoretisch eine Art beliebiger Größe in beliebiger Speichermenge aufnehmen, indem einfach die Anzahl der lokal sortierten Zwischensätze erhöht wird. Das Problem ist, dass wir mit zunehmendem 'n' kleinere Datenblöcke lesen und schreiben. Zum Beispiel würde das Sortieren von 400 GB Daten in 500 MB Speicher so etwas wie eine 800-Wege-Zusammenführung bedeuten, wobei nur etwa 0,6 MB von jedem sortierten Zwischensatz gleichzeitig im Speicher sind (800 x 0,6 MB =480 MB, was etwas Platz für eine Ausgabepuffer).
Um dies zu umgehen, können mehrere Zusammenführungsdurchgänge verwendet werden. Die allgemeine Idee besteht darin, kleine Chunks schrittweise zu größeren zusammenzuführen, bis wir den endgültigen sortierten Ausgabestrom effizient produzieren können. In dem Beispiel könnte dies bedeuten, dass 40 der 800 im ersten Durchgang sortierten Sätze gleichzeitig zusammengeführt werden, was zu 20 größeren Chunks führt, die dann erneut zusammengeführt werden können, um die Ausgabe zu bilden. Bei insgesamt zwei zusätzlichen Durchgängen über die Daten wäre dies ein Überlauf der Stufe 2 und so weiter. Glücklicherweise ermöglicht eine lineare Erhöhung des Überlaufniveaus eine exponentielle Zunahme der Sortiergröße, sodass tiefe Sortierüberlaufniveaus selten erforderlich sind.
Der "Level 15.000"-Überlauf
An diesem Punkt fragen Sie sich vielleicht, welche Kombination aus winziger Speicherzuteilung und enormer Datengröße möglicherweise zu einem Sortierverlust der Stufe 15.000 führen könnte. Versuchen Sie, das gesamte Internet in 1 MB Speicher zu sortieren? Möglich, aber das ist viel zu schwer zu demonstrieren. Um ehrlich zu sein, habe ich keine Ahnung, ob ein so wirklich hoher Spill-Level in SQL Server überhaupt möglich ist. Das Ziel hier (sicherlich ein Cheat) ist es, SQL Server dazu zu bringen, zu berichten ein Verschütten der Stufe 15.000.
Die wichtigste Zutat ist die Partitionierung. Seit SQL Server 2012 ist uns ein (bequemes) Maximum von 15.000 Partitionen pro Objekt erlaubt (Unterstützung für 15.000 Partitionen ist auch auf 2008 SP2 und 2008 R2 SP1 verfügbar, aber Sie müssen es manuell pro Datenbank aktivieren und sich dessen bewusst sein die Vorbehalte).
Das erste, was wir brauchen, ist eine Partitionsfunktion mit 15.000 Elementen und ein zugehöriges Partitionsschema. Um einen wirklich riesigen Inline-Codeblock zu vermeiden, verwendet das folgende Skript dynamisches SQL, um die erforderlichen Anweisungen zu generieren:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Das Skript kann leicht auf eine niedrigere Zahl geändert werden, falls Ihr Setup mit 15.000 Partitionen zu kämpfen hat (insbesondere aus Speichersicht, wie wir gleich sehen werden). Die nächsten Schritte bestehen darin, eine normale (nicht partitionierte) Heap-Tabelle mit einer einzigen Ganzzahlspalte zu erstellen und sie dann mit den Ganzzahlen von 1 bis einschließlich 15.000 zu füllen:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Das sollte in etwa 100 ms abgeschlossen sein. Wenn Sie eine Zahlentabelle zur Verfügung haben, können Sie diese stattdessen für eine eher satzbasierte Erfahrung verwenden. Die Art und Weise, wie die Basistabelle gefüllt wird, ist nicht wichtig. Um unseren 15.000-Level-Spill zu erhalten, müssen wir jetzt nur noch einen partitionierten Clustered-Index für die Tabelle erstellen:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Die Ausführungszeit hängt stark vom verwendeten Speichersystem ab. Auf meinem Laptop dauert es mit einer ziemlich typischen Consumer-SSD von vor ein paar Jahren etwa 20 Sekunden, was ziemlich beachtlich ist, wenn man bedenkt, dass wir es insgesamt nur mit 15.000 Zeilen zu tun haben. Auf einer Azure-VM mit relativ niedrigen Spezifikationen und einer ziemlich schrecklichen E/A-Leistung dauerte derselbe Test fast 20 Minuten.
Analyse
Der Ausführungsplan für den Indexaufbau lautet:
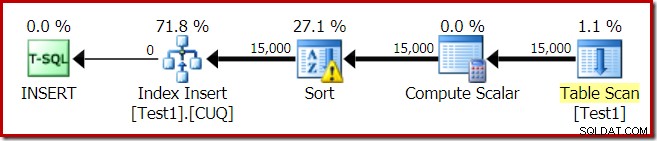
Der Table Scan liest die 15.000 Zeilen aus unserer Heap-Tabelle. Der Berechnungsskalar berechnet die Nummer der Zielindexpartition für jede Zeile mithilfe der internen Funktion RangePartitionNew() . Das Sortieren ist der interessanteste Teil des Plans, also werden wir uns das genauer ansehen.
Zuerst die Sortierwarnung, wie sie im Plan Explorer angezeigt wird:

Eine ähnliche Warnung von SSMS (aus einer anderen Ausführung des Skripts):
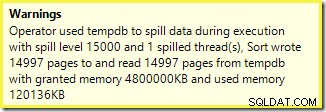
Das erste, was zu beachten ist, ist der Bericht über ein 15.000-Sorten-Spill-Level, wie versprochen. Das ist nicht ganz korrekt, aber die Details sind sehr interessant. Die Sortierung in diesem Plan hat eine Partition ID Eigenschaft, die normalerweise nicht vorhanden ist:
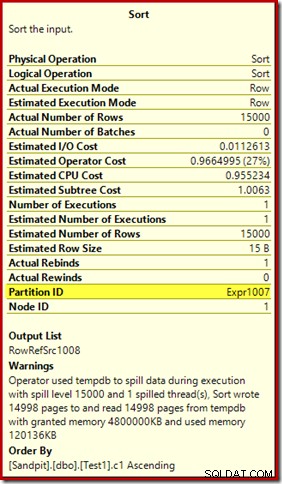
Diese Eigenschaft wird gleich der Definition der internen Partitionierungsfunktion im Compute Scalar gesetzt.
Dies ist ein nicht ausgerichteter Indexaufbau , da Quelle und Ziel unterschiedliche Partitionierungsanordnungen haben. In diesem Fall entsteht dieser Unterschied, weil die Quell-Heap-Tabelle nicht partitioniert ist, der Zielindex jedoch. Infolgedessen werden zur Laufzeit 15.000 separate Sortierungen erstellt:eine pro nicht leerer Zielpartition. Jede dieser Sortierungen wird auf Stufe 1 verschoben, und SQL Server summiert alle diese Spills auf, um die endgültige Spill-Stufe von 15.000 zu erhalten.
Die 15.000 getrennten Sortierungen erklären die große Speicherbewilligung. Jede Sortierinstanz hat eine Mindestgröße von 40 Seiten, was 40 x 8 KB =320 KB entspricht. Die 15.000 Sortierungen benötigen also mindestens 15.000 x 320 KB =4.800.000 KB Speicher. Das sind knapp 4,6 GB RAM, die ausschließlich für eine Abfrage reserviert sind, die 15.000 Zeilen sortiert, die eine einzige Ganzzahlspalte enthalten. Und jede Sortierung wird auf die Festplatte übertragen, obwohl sie nur eine Zeile erhält! Wenn für die Indexerstellung Parallelität verwendet würde, könnte die Speicherzuteilung durch die Anzahl der Threads weiter aufgebläht werden. Beachten Sie auch, dass die einzelne Zeile in eine Seite geschrieben wird, was die Anzahl der Seiten erklärt, die in tempdb geschrieben und von ihr gelesen werden. Es scheint eine Race-Condition zu geben, was bedeutet, dass die gemeldete Seitenzahl oft etwas weniger als 15.000 beträgt.
Dieses Beispiel spiegelt natürlich einen Grenzfall wider, aber es ist immer noch schwer zu verstehen, warum jede Sortierung ihre einzelne Zeile verschüttet, anstatt in dem Speicher zu sortieren, der ihr gegeben wurde. Vielleicht ist dies aus irgendeinem Grund beabsichtigt, oder vielleicht ist es einfach ein Fehler. Wie dem auch sei, es ist immer noch ziemlich unterhaltsam zu sehen, dass eine Art von ein paar hundert KB an Daten mit einer Speicherzuteilung von 4,6 GB und einem Überlauf von 15.000 Leveln so lange dauert. Es sei denn, Sie begegnen ihm vielleicht in einer Produktionsumgebung. Wie auch immer, es ist etwas, dessen man sich bewusst sein sollte.
Der irreführende 15.000-Level-Spill-Bericht läuft ziemlich genau auf Darstellungsbeschränkungen in der Ausgabe des Showplans hinaus. Das grundlegende Problem tritt an vielen Stellen auf, an denen wiederholte Aktionen auftreten, beispielsweise auf der Innenseite der verschachtelten Schleifenverbindung. Es wäre sicherlich sinnvoll, in diesen Fällen eine genauere Aufschlüsselung anstelle einer Gesamtsumme sehen zu können. Im Laufe der Zeit hat sich dieser Bereich etwas verbessert, sodass wir jetzt mehr Planinformationen pro Thread oder pro Partition für einige Operationen haben. Es ist aber noch ein langer Weg.
Es ist immer noch wenig hilfreich, dass 15.000 einzelne Verschüttungen der Stufe 1 hier als eine einzige Verschüttung der Stufe 15.000 gemeldet werden.
Testvariationen
In diesem Artikel geht es mehr darum, die Einschränkungen der Planinformationen und das Potenzial für schlechte Leistung bei Verwendung einer extremen Anzahl von Partitionen hervorzuheben, als darum, den bestimmten Beispielvorgang effizienter zu gestalten, aber es gibt ein paar interessante Variationen, die ich mir auch ansehen möchte .
Online, in tempdb sortieren
Ausführen der gleichen partitionierten Indexerstellungsoperation mit ONLINE = ON, SORT_IN_TEMPDB = ON leidet nicht unter dem gleichen enormen Speicherzuschuss und -überlauf:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Beachten Sie, dass Sie ONLINE verwenden allein reicht nicht aus. Tatsächlich ergibt sich daraus derselbe Plan wie zuvor mit denselben Problemen, plus ein zusätzlicher Overhead für das Online-Erstellen jeder Indexpartition. Bei mir ergibt das eine Ausführungszeit von weit über einer Minute. Gott weiß, wie lange es auf einer niedrig spezifizierten Azure-Instanz mit schrecklicher E/A-Leistung dauern würde.
Wie auch immer, der Ausführungsplan mit ONLINE = ON, SORT_IN_TEMPDB = ON ist:

Die Sortierung wird durchgeführt, bevor die Zielpartitionsnummer berechnet wird. Es hat keine Partitions-ID-Eigenschaft, also ist es nur eine normale Sortierung. Der gesamte Vorgang dauert ungefähr zehn Sekunden (es müssen noch viele Partitionen erstellt werden). Es reserviert weniger als 3 MB Speicher und verwendet maximal 816 KB. Eine ziemliche Verbesserung gegenüber 4,6 GB und 15.000 Überläufen.
Zuerst Index, dann Daten
Ähnliche Ergebnisse können erzielt werden, indem die Daten zuerst in eine Heap-Tabelle geschrieben werden:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Erstellen Sie als Nächstes eine leere partitionierte Clustertabelle und fügen Sie die Daten aus dem Heap ein:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Dies dauert ungefähr zehn Sekunden, mit einer Speicherzuteilung von 2 MB und ohne Überlaufen:
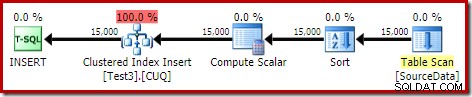
Natürlich könnte die Sortierung auch vollständig vermieden werden, indem die (unpartitionierte) Quelltabelle indiziert und die Daten in Indexreihenfolge eingefügt werden (die beste Sortierung ist überhaupt keine Sortierung, denken Sie daran).
Partitionierter Heap, dann Daten, dann Index
Für diese letzte Variante erstellen wir zuerst einen partitionierten Heap und laden die 15.000 Testzeilen:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Dieses Skript läuft ein oder zwei Sekunden lang, was ziemlich gut ist. Der letzte Schritt besteht darin, den partitionierten Clustered-Index zu erstellen:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Das ist eine komplette Katastrophe, sowohl aus Sicht der Leistung als auch aus Sicht der Showplan-Informationen. Die Operation selbst wird mit folgendem Ausführungsplan knapp eine Minute lang ausgeführt:

Dies ist ein Colocated-Insert-Plan. Der Constant Scan enthält eine Zeile für jede Partitions-ID. Die Innenseite der Schleife sucht nach der aktuellen Partition des Heaps (ja, eine Suche auf einem Heap). Die Sortierung hat eine Partitions-ID-Eigenschaft (obwohl dies eine Konstante pro Schleifeniteration ist), sodass es eine Sortierung pro Partition und das unerwünschte Überlaufverhalten gibt. Die Statistikwarnung in der Heap-Tabelle ist falsch.
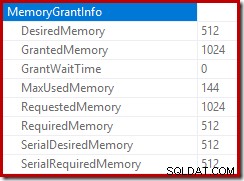
Der Stamm des Einfügeplans gibt an, dass eine Speicherzuteilung von 1 MB reserviert wurde, wobei maximal 144 KB verwendet wurden:
Der Sort-Operator meldet keinen Level-15.000-Spill, macht aber ansonsten die beteiligte Per-Loop-Iterationsmathematik komplett durcheinander:

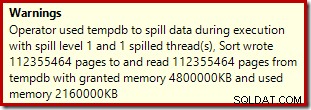
Die Überwachung der Speicherzuweisungen DMV während der Ausführung zeigt, dass diese Abfrage tatsächlich nur 1 MB reserviert, wobei bei jeder Iteration der Schleife maximal 144 KB verwendet werden. (Dagegen sind die 4,6 GB Speicherreservierung im ersten Test absolut echt.) Das ist natürlich verwirrend.
Das Problem (wie bereits erwähnt) besteht darin, dass SQL Server verwirrt darüber ist, wie man am besten darüber berichtet, was über viele Iterationen hinweg passiert ist. Es ist wahrscheinlich nicht praktikabel, Planleistungsinformationen pro Partition und Iteration einzubeziehen, aber es führt kein Weg daran vorbei, dass die derzeitige Anordnung manchmal verwirrende Ergebnisse liefert. Wir können nur hoffen, dass eines Tages ein besserer Weg gefunden wird, um diese Art von Informationen in einem konsistenteren Format zu melden.