Es ist durchaus üblich, dass Datenbanken über mehrere geografische Standorte verteilt sind. Ein Szenario für diese Art der Einrichtung ist die Notfallwiederherstellung, bei der sich Ihr Standby-Rechenzentrum an einem anderen Ort als Ihr Hauptrechenzentrum befindet. Es könnte auch erforderlich sein, dass die Datenbanken näher bei den Benutzern liegen.
Die größte Herausforderung beim Erreichen dieses Setups besteht darin, die Datenbank so zu gestalten, dass die Wahrscheinlichkeit von Problemen im Zusammenhang mit der Netzwerkpartitionierung verringert wird. Eine der Lösungen könnte darin bestehen, Galera Cluster anstelle der regulären asynchronen (oder halbsynchronen) Replikation zu verwenden. In diesem Blog werden wir die Vor- und Nachteile dieses Ansatzes diskutieren. Dies ist der erste Teil einer Reihe von zwei Blogs. Im zweiten Teil werden wir den geografisch verteilten Galera-Cluster entwerfen und sehen, wie ClusterControl uns bei der Bereitstellung einer solchen Umgebung helfen kann.
Warum Galera-Cluster statt asynchroner Replikation für geografisch verteilte Cluster?
Lassen Sie uns die Hauptunterschiede zwischen der Galera und der regulären Replikation betrachten. Bei der regulären Replikation steht Ihnen nur ein Knoten zur Verfügung, auf den Sie schreiben können. Dies bedeutet, dass jeder Schreibvorgang von einem entfernten Rechenzentrum über das Wide Area Network (WAN) gesendet werden müsste, um den Master zu erreichen. Dies bedeutet auch, dass alle Proxys im entfernten Rechenzentrum in der Lage sein müssen, die gesamte Topologie zu überwachen, die sich über alle beteiligten Rechenzentren erstreckt, da sie in der Lage sein müssen, festzustellen, welcher Knoten derzeit der Master ist.
Das führt zu einer Reihe von Problemen. Erstens müssen mehrere Verbindungen über das WAN hergestellt werden, dies erhöht die Latenz und verlangsamt alle Überprüfungen, die der Proxy möglicherweise ausführt. Darüber hinaus fügt dies den Proxys und Datenbanken unnötigen Overhead hinzu. Meistens sind Sie nur daran interessiert, den Datenverkehr zu den lokalen Datenbankknoten zu leiten. Die einzige Ausnahme ist der Master und nur deshalb sind Proxys gezwungen, die gesamte Infrastruktur zu überwachen und nicht nur den Teil, der sich im lokalen Rechenzentrum befindet. Natürlich können Sie versuchen, dies zu überwinden, indem Sie Proxys verwenden, um nur SELECTs weiterzuleiten, während Sie eine andere Methode verwenden (dedizierter Hostname für den Master, der von DNS verwaltet wird), um die Anwendung auf den Master zu verweisen, aber dies fügt unnötige Komplexität und bewegliche Teile hinzu, was kann Ihre Fähigkeit, mit mehreren Knoten- und Netzwerkausfällen umzugehen, ohne die Datenkonsistenz zu verlieren, ernsthaft beeinträchtigen.
Galera Cluster kann mehrere Autoren unterstützen. Die Latenz ist ebenfalls ein Faktor, da alle Knoten im Galera-Cluster koordinieren und kommunizieren müssen, um Writesets zu zertifizieren, kann dies sogar der Grund dafür sein, dass Sie sich entscheiden, Galera nicht zu verwenden, wenn die Latenz zu hoch ist. Es ist auch ein Problem in Replikationsclustern – in Replikationsclustern wirkt sich die Latenz nur auf Schreibvorgänge von den entfernten Rechenzentren aus, während die Verbindungen vom Rechenzentrum, in dem sich der Master befindet, von Commits mit niedriger Latenz profitieren würden.
Bei der MySQL-Replikation müssen Sie auch das Worst-Case-Szenario berücksichtigen und sicherstellen, dass die Anwendung mit verzögerten Schreibvorgängen in Ordnung ist. Der Master kann sich immer ändern und Sie können nicht sicher sein, dass Sie die ganze Zeit auf einen lokalen Knoten schreiben werden.
Ein weiterer Unterschied zwischen Replikation und Galera Cluster ist die Behandlung der Replikationsverzögerung. Geoverteilte Cluster können ernsthaft durch Verzögerungen beeinträchtigt werden:Latenz, begrenzter Durchsatz der WAN-Verbindung, all dies wirkt sich auf die Fähigkeit eines replizierten Clusters aus, mit der Replikation Schritt zu halten. Bitte beachten Sie, dass die Replikation One-to-All-Traffic generiert.
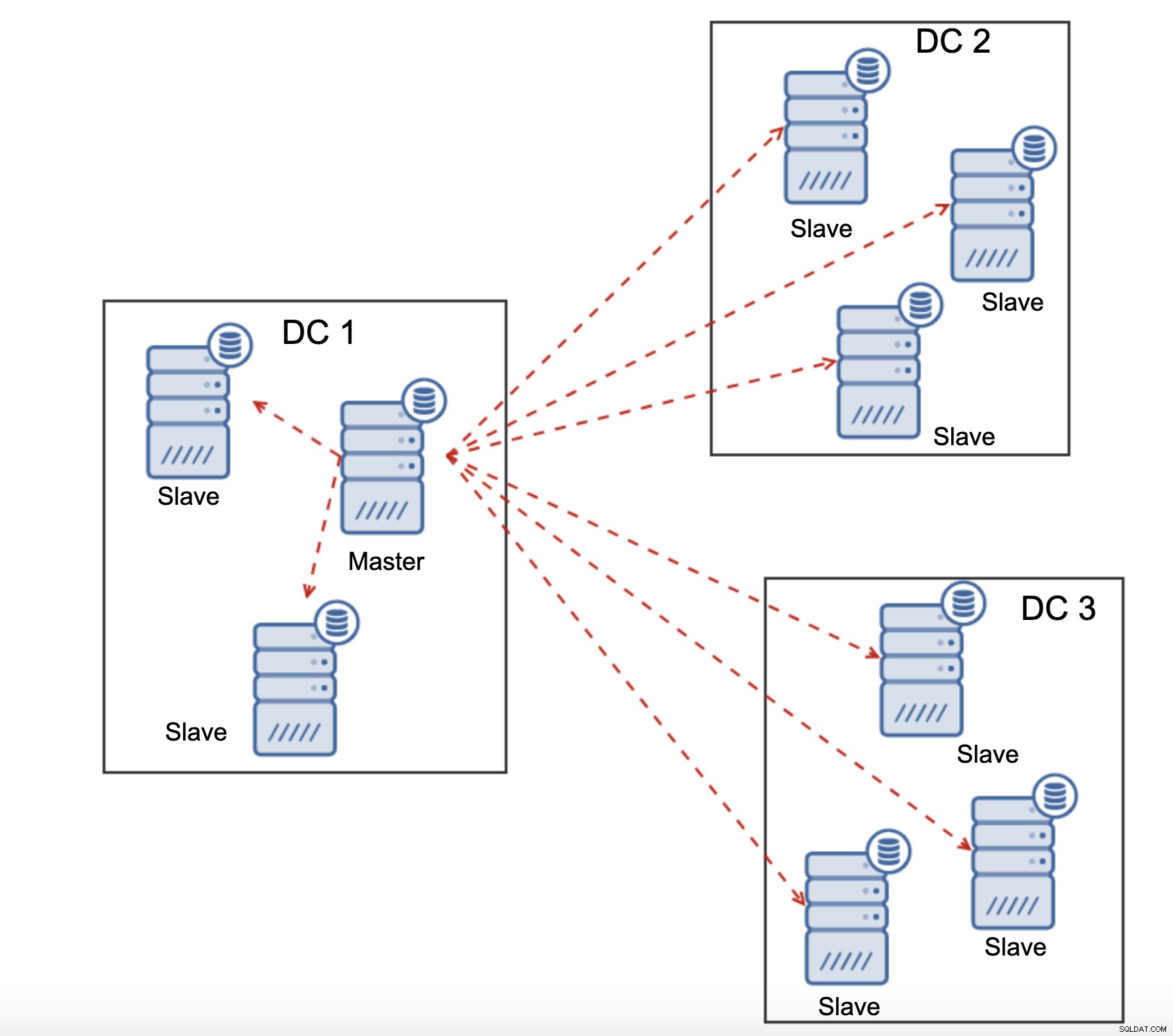
Alle Slaves müssen den gesamten Replikationsverkehr erhalten – die Datenmenge, die Sie haben an entfernte Slaves über WAN zu senden steigt mit jedem entfernten Slave, den Sie hinzufügen. Dies kann leicht zu einer Sättigung der WAN-Verbindung führen, insbesondere wenn Sie viele Änderungen vornehmen und die WAN-Verbindung keinen guten Durchsatz hat. Wie Sie im obigen Diagramm sehen können, muss der Master bei drei Rechenzentren und drei Knoten in jedem von ihnen den 6-fachen Replikationsdatenverkehr über die WAN-Verbindung senden.
Bei Galera Cluster sind die Dinge etwas anders. Für den Anfang verwendet Galera die Flusskontrolle, um die Knoten synchron zu halten. Wenn einer der Knoten hinterherhinkt, kann er den Rest des Clusters bitten, langsamer zu werden und ihn aufholen zu lassen. Sicher, das reduziert die Leistung des gesamten Clusters, aber es ist immer noch besser, als wenn Sie Slaves nicht wirklich für SELECTs verwenden können, da sie von Zeit zu Zeit zu Verzögerungen neigen - in solchen Fällen können die Ergebnisse, die Sie erhalten, veraltet und falsch sein.
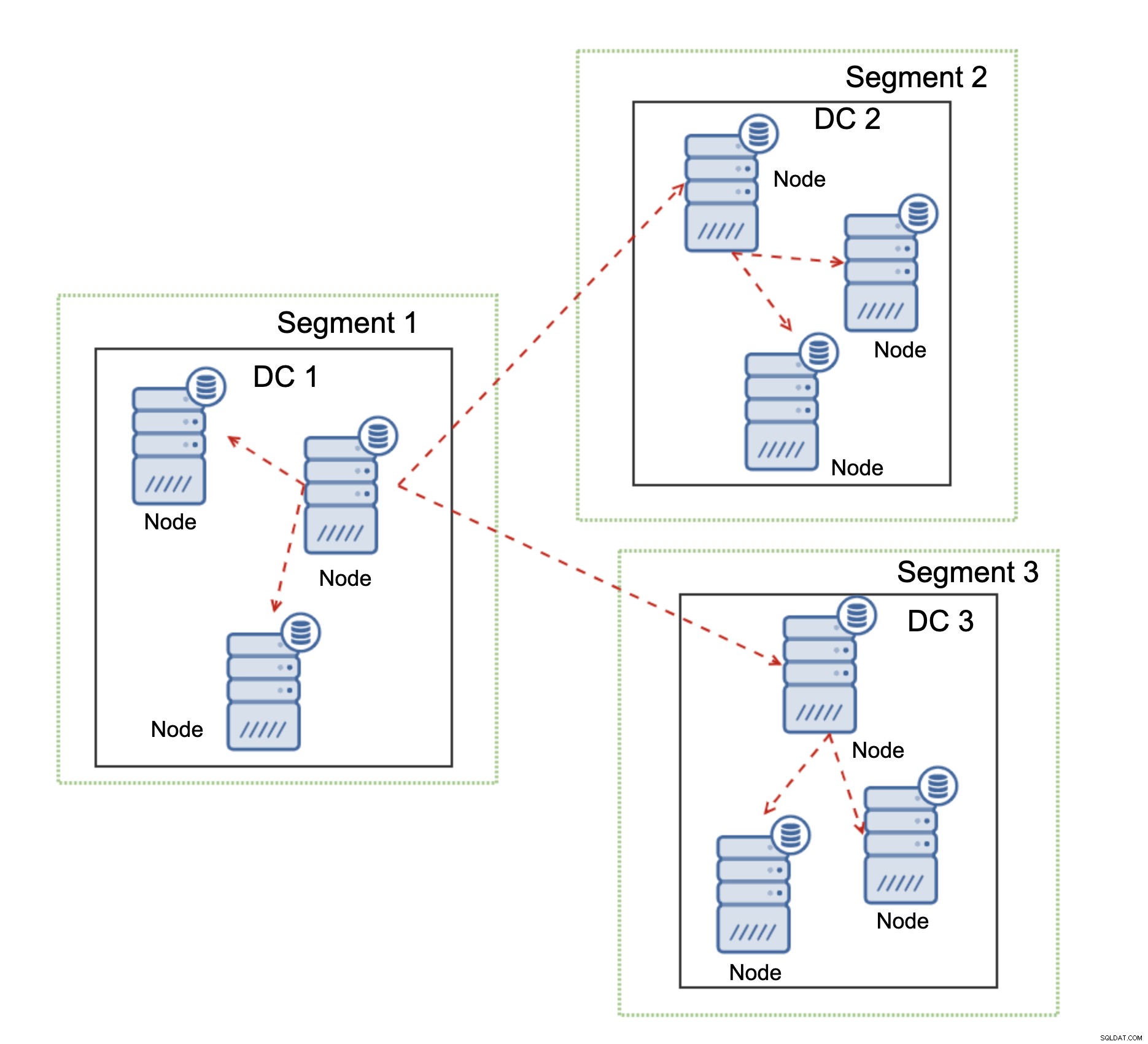
Ein weiteres Feature von Galera Cluster, das seine Leistung erheblich verbessern kann, wenn es verwendet wird WAN, sind Segmente. Standardmäßig verwendet Galera die All-to-All-Kommunikation und jedes Writeset wird vom Knoten an alle anderen Knoten im Cluster gesendet. Dieses Verhalten kann durch Segmente verändert werden. Segmente ermöglichen es Benutzern, den Galera-Cluster in mehrere Teile aufzuteilen. Jedes Segment kann mehrere Knoten enthalten und wählt einen von ihnen als Relaisknoten aus. Ein solcher Knoten empfängt Writesets von anderen Segmenten und verteilt sie über Galera-Knoten, die lokal zu dem Segment sind. Wie Sie im obigen Diagramm sehen können, ist es daher möglich, den über das WAN gehenden Replikationsverkehr um das Dreifache zu reduzieren – es werden nur zwei „Repliken“ des Replikationsstroms über das WAN gesendet:eine pro Rechenzentrum im Vergleich zu einer pro Slave in der MySQL-Replikation.
Handhabung der Galera-Cluster-Netzwerkpartitionierung
Wo Galera Cluster glänzt, ist die Handhabung der Netzwerkpartitionierung. Galera Cluster überwacht ständig den Zustand der Knoten im Cluster. Jeder Knoten versucht, sich mit seinen Peers zu verbinden und den Status des Clusters auszutauschen. Wenn eine Teilmenge von Knoten nicht erreichbar ist, versucht Galera, die Kommunikation weiterzuleiten, sodass sie erreicht werden, wenn es eine Möglichkeit gibt, diese Knoten zu erreichen.

Ein Beispiel ist im obigen Diagramm zu sehen:DC 1 hat die Konnektivität verloren mit DC2, aber DC2 und DC3 können eine Verbindung herstellen. In diesem Fall wird einer der Knoten in DC3 verwendet, um Daten von DC1 an DC2 weiterzuleiten, um sicherzustellen, dass die Intra-Cluster-Kommunikation aufrechterhalten werden kann.
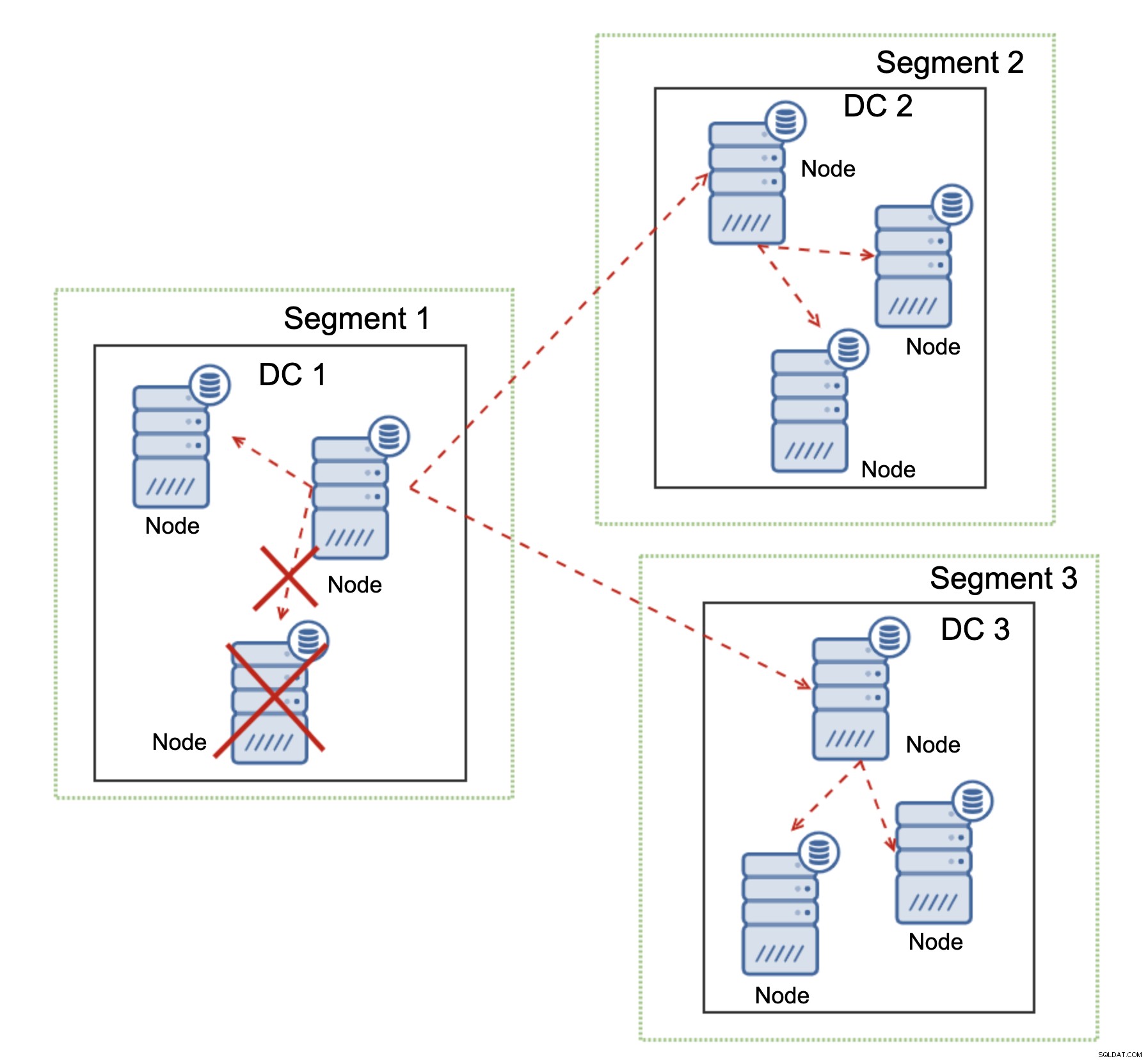
Galera Cluster kann Aktionen basierend auf dem Zustand des Clusters durchführen. Es implementiert das Quorum – die Mehrheit der Knoten muss verfügbar sein, damit der Cluster arbeiten kann. Wenn der Knoten vom Cluster getrennt wird und keinen anderen Knoten erreichen kann, wird er seinen Betrieb einstellen.
Wie im obigen Diagramm zu sehen ist, gibt es einen teilweisen Verlust der Netzwerkkommunikation in DC1 und der betroffene Knoten wird aus dem Cluster entfernt, wodurch sichergestellt wird, dass die Anwendung nicht auf veraltete Daten zugreift.
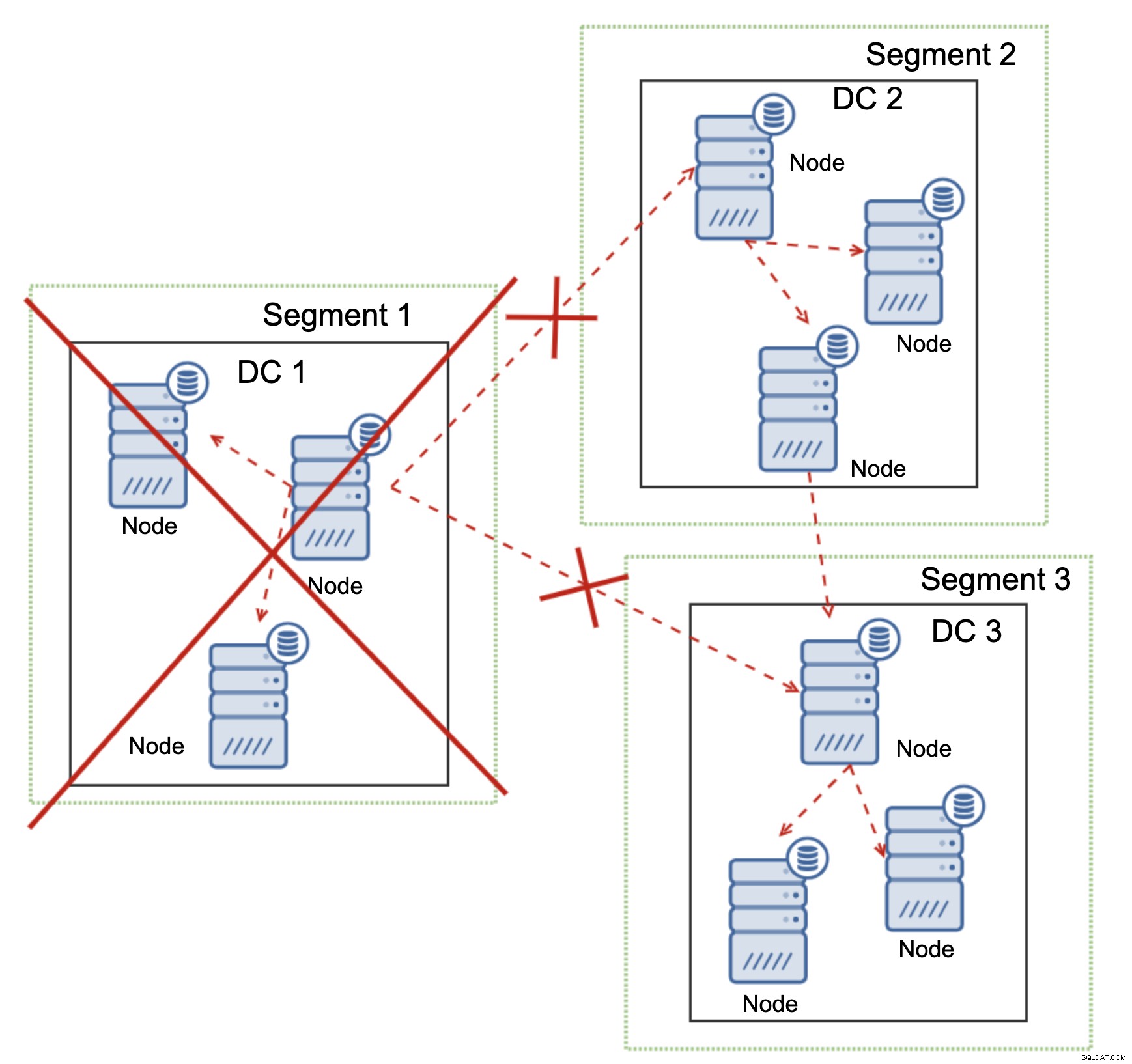
Dies gilt auch im größeren Maßstab. Der DC1 wurde die gesamte Kommunikation abgeschnitten. Infolgedessen wurde das gesamte Rechenzentrum aus dem Cluster entfernt und keiner seiner Knoten wird den Datenverkehr bedienen. Der Rest des Clusters behielt die Mehrheit (6 von 9 Knoten sind verfügbar) und konfigurierte sich selbst neu, um die Verbindung zwischen DC 2 und DC3 aufrechtzuerhalten. Im obigen Diagramm haben wir angenommen, dass der Schreibvorgang den Knoten in DC2 trifft, aber denken Sie bitte daran, dass Galera mit mehreren Schreibern ausgeführt werden kann.
MySQL Replication hat keinerlei Cluster-Bewusstsein, was es problematisch macht, Netzwerkprobleme zu handhaben. Es kann sich nicht selbst herunterfahren, wenn die Verbindung zu anderen Knoten unterbrochen wird. Es gibt keine einfache Möglichkeit, zu verhindern, dass der alte Master nach der Trennung des Netzwerks auftaucht.
Die einzigen Möglichkeiten beschränken sich auf die Proxy-Schicht oder noch höher. Sie müssen ein System entwerfen, das versucht, den Status des Clusters zu verstehen und die erforderlichen Maßnahmen zu ergreifen. Eine Möglichkeit besteht darin, clusterfähige Tools wie Orchestrator zu verwenden und dann Skripts auszuführen, die den Status des Orchestrator-RAFT-Clusters überprüfen und basierend auf diesem Status die erforderlichen Aktionen auf der Datenbankebene ausführen. Dies ist alles andere als ideal, da jede Aktion, die auf einer höheren Ebene als der Datenbank ausgeführt wird, zusätzliche Latenz hinzufügt:Dadurch wird das Problem möglicherweise angezeigt und die Datenkonsistenz wird beeinträchtigt, bevor die richtigen Maßnahmen ergriffen werden können. Galera hingegen ergreift Maßnahmen auf Datenbankebene, um eine schnellstmögliche Reaktion zu gewährleisten.