Im März habe ich eine Serie über allgegenwärtige Leistungsmythen in SQL Server gestartet. Eine Überzeugung, der ich von Zeit zu Zeit begegne, ist, dass Sie varchar- oder nvarchar-Spalten ohne Strafe überdimensionieren können.
Nehmen wir an, Sie speichern E-Mail-Adressen. In einem früheren Leben habe ich mich damit ziemlich beschäftigt – damals gab RFC 3696 an, dass eine E-Mail-Adresse 320 Zeichen lang sein darf (64 Zeichen @ 255 Zeichen). Ein neuerer RFC, #5321, bestätigt nun, dass 254 Zeichen die längste Länge einer E-Mail-Adresse sind. Und wenn einer von Ihnen eine so lange Adresse hat, dann sollten wir uns vielleicht unterhalten. :-)
Unabhängig davon, ob Sie sich nach dem alten oder dem neuen Standard richten, müssen Sie die Möglichkeit unterstützen, dass jemand alle zulässigen Zeichen verwendet. Das bedeutet, dass Sie 254 oder 320 Zeichen verwenden müssen. Aber was ich gesehen habe, ist, dass Leute sich überhaupt nicht die Mühe machen, den Standard zu recherchieren, und einfach davon ausgehen, dass sie 1.000 Zeichen, 4.000 Zeichen oder sogar mehr unterstützen müssen.
Schauen wir uns also an, was passiert, wenn wir Tabellen mit einer E-Mail-Adressspalte unterschiedlicher Größe haben, aber genau die gleichen Daten speichern:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Lassen Sie uns nun 10.000 fiktive E-Mail-Adressen aus Systemmetadaten generieren und alle vier Tabellen mit denselben Daten füllen:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
So überprüfen Sie, ob jede Tabelle genau die gleichen Daten enthält:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Alle vier ergeben für mich 35 und 77; Ihr Kilometerstand kann variieren. Stellen wir außerdem sicher, dass alle vier Tabellen die gleiche Anzahl von Seiten auf der Festplatte belegen:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Alle vier dieser Abfragen ergeben 89 Seiten (auch hier kann Ihr Kilometerstand variieren).
Nehmen wir nun eine typische Abfrage, die zu einem Clustered-Index-Scan führt:
SELECT id, email FROM dbo.Email_<size>;
Wenn wir Dinge wie Dauer, Lesevorgänge und geschätzte Kosten betrachten, scheinen sie alle gleich zu sein:
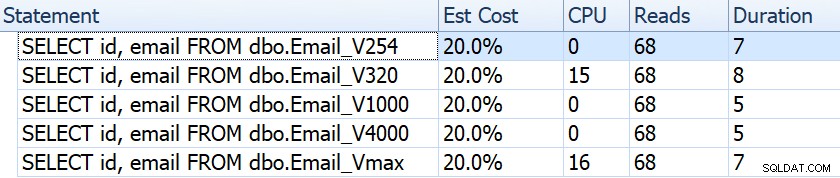
Dies kann Menschen in die falsche Annahme wiegen, dass es überhaupt keine Auswirkungen auf die Leistung gibt. Aber wenn wir etwas genauer hinschauen, sehen wir im Tooltip für den Clustered-Index-Scan in jedem Plan einen Unterschied, der bei anderen, aufwändigeren Abfragen ins Spiel kommen kann:

Von hier aus sehen wir, dass die geschätzte Zeilen- und Datengröße umso höher ist, je größer die Spaltendefinition ist. Bei dieser einfachen Abfrage sind die E/A-Kosten (0,0512731) unabhängig von der Definition für alle Abfragen gleich, da der Clustered-Index-Scan sowieso alle Daten lesen muss.
Es gibt jedoch andere Szenarien, in denen diese geschätzte Zeilen- und Gesamtdatengröße Auswirkungen haben:Vorgänge, die zusätzliche Ressourcen erfordern, z. B. Sortierungen. Nehmen wir diese lächerliche Abfrage, die keinem wirklichen Zweck dient, außer mehrere Sortieroperationen zu erfordern:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Wir führen diese vier Abfragen aus und sehen, dass die Pläne alle so aussehen:

Dieses Warnsymbol auf dem SELECT-Operator erscheint jedoch nur auf den 4000/max-Tischen. Was ist die Warnung? Es handelt sich um eine in SQL Server 2016 eingeführte Warnung zu übermäßiger Speicherzuweisung. Hier ist die Warnung für varchar(4000):

Und für varchar(max):

Schauen wir etwas genauer hin und sehen, was los ist, zumindest laut sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Ergebnisse:

In meinem Szenario wurde die Dauer nicht durch die Speicherzuweisungsunterschiede beeinflusst (mit Ausnahme des Max-Falls), aber Sie können deutlich den linearen Verlauf sehen, der mit der deklarierten Größe der Spalte übereinstimmt. Damit können Sie extrapolieren, was auf einem System mit unzureichendem Arbeitsspeicher passieren würde. Oder eine aufwändigere Abfrage für einen viel größeren Datensatz. Oder erhebliche Parallelität. Jedes dieser Szenarien könnte Überläufe erfordern, um die Sortieroperationen zu verarbeiten, und die Dauer würde dadurch mit ziemlicher Sicherheit beeinträchtigt werden.
Aber woher kommen diese größeren Speicherzuschüsse? Denken Sie daran, dass es sich um dieselbe Abfrage mit genau denselben Daten handelt. Das Problem besteht darin, dass SQL Server für bestimmte Operationen berücksichtigen muss, wie viele Daten sich in einer Spalte *möglicherweise* befinden. Es tut dies nicht basierend auf der tatsächlichen Profilerstellung der Daten, und es kann keine Annahmen basierend auf den <=201 Histogrammschrittwerten treffen. Stattdessen muss geschätzt werden, dass jede Zeile einen Wert enthält, der halb so groß ist wie die deklarierte Spaltengröße . Bei einem varchar(4000) wird also davon ausgegangen, dass jede E-Mail-Adresse 2.000 Zeichen lang ist.
Wenn es nicht möglich ist, eine E-Mail-Adresse mit mehr als 254 oder 320 Zeichen zu haben, kann man durch eine Überdimensionierung nichts gewinnen, aber möglicherweise viel verlieren. Das spätere Erhöhen der Größe einer Spalte mit variabler Breite ist viel einfacher, als sich jetzt mit allen Nachteilen auseinanderzusetzen.
Natürlich, char überdimensionieren oder nchar Spalten können viel offensichtlichere Strafen haben.