SQL Server führte In-Memory-OLTP-Objekte in SQL Server 2014 ein. In der ersten Version gab es viele Einschränkungen; Einige wurden in SQL Server 2016 behoben, und es wird erwartet, dass weitere in der nächsten Version behandelt werden, wenn sich das Feature weiterentwickelt. Bisher scheint die Einführung von In-Memory OLTP nicht sehr weit verbreitet zu sein, aber ich gehe davon aus, dass mit zunehmender Reife der Funktion mehr Kunden nach der Implementierung fragen werden. Wie bei jeder größeren Schema- oder Codeänderung empfehle ich gründliche Tests, um festzustellen, ob In-Memory-OLTP die erwarteten Vorteile bietet. Vor diesem Hintergrund war ich daran interessiert zu sehen, wie sich die Leistung für sehr einfache INSERT-, UPDATE- und DELETE-Anweisungen mit In-Memory-OLTP verändert. Ich hatte die Hoffnung, dass die In-Memory-Tabellen eine Lösung bieten würden, wenn ich Latching oder Locking als Problem bei festplattenbasierten Tabellen aufzeigen könnte, da sie Lock- und Latch-frei sind.
Ich habe den folgenden Test entwickelt Fälle:
- Eine festplattenbasierte Tabelle mit herkömmlichen gespeicherten Prozeduren für DML.
- Eine In-Memory-Tabelle mit traditionellen gespeicherten Prozeduren für DML.
- Eine In-Memory-Tabelle mit nativ kompilierten Prozeduren für DML.
Ich war daran interessiert, die Leistung herkömmlicher gespeicherter Prozeduren und nativ kompilierter Prozeduren zu vergleichen, da eine Einschränkung einer nativ kompilierten Prozedur darin besteht, dass alle Tabellen, auf die verwiesen wird, In-Memory sein müssen. Während einzeilige, einzelne Änderungen in einigen Systemen üblich sein können, sehe ich häufig Änderungen, die innerhalb einer größeren gespeicherten Prozedur mit mehreren Anweisungen (SELECT und DML) auftreten, die auf eine oder mehrere Tabellen zugreifen. Die In-Memory-OLTP-Dokumentation empfiehlt dringend, nativ kompilierte Prozeduren zu verwenden, um den größten Nutzen in Bezug auf die Leistung zu erzielen. Ich wollte verstehen, wie sehr es die Leistung verbessert hat.
Die Einrichtung
Ich habe eine Datenbank mit einer speicheroptimierten Dateigruppe erstellt und dann drei verschiedene Tabellen in der Datenbank erstellt (eine festplattenbasiert, zwei im Arbeitsspeicher):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
Die DDL war für alle Objekte nahezu gleich, wobei gegebenenfalls On-Disk versus In-Memory berücksichtigt wurden. DiskTable-DDL im Vergleich zu In-Memory-DDL:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Außerdem habe ich neun gespeicherte Prozeduren erstellt – eine für jede Kombination aus Tabelle und Änderung.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Löschen
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Jede gespeicherte Prozedur akzeptierte eine ganzzahlige Eingabe für die Schleife für diese Anzahl von Änderungen. Die gespeicherten Prozeduren folgten demselben Format, Variationen waren nur die Tabelle, auf die zugegriffen wurde, und ob das Objekt nativ kompiliert wurde oder nicht. Den vollständigen Code zum Erstellen der Datenbank und der Objekte finden Sie hier, mit Beispielanweisungen für INSERT und UPDATE unten:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Hinweis:Die IDs_*-Tabellen wurden nach jeder abgeschlossenen Gruppe von INSERTs neu gefüllt und waren spezifisch für die drei verschiedenen Szenarien.
Testmethodik
Die Tests wurden mit .cmd-Skripten durchgeführt, die sqlcmd zum Aufrufen eines Skripts verwendeten, das die gespeicherte Prozedur ausführte, zum Beispiel:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"beenden
Ich habe diesen Ansatz verwendet, um eine oder mehrere Verbindungen zur Datenbank zu erstellen, die gleichzeitig ausgeführt werden. Neben dem Verständnis grundlegender Leistungsänderungen wollte ich auch die Auswirkungen unterschiedlicher Workloads untersuchen. Diese Skripte wurden von einem separaten Computer initiiert, um den Overhead der Instanziierung von Verbindungen zu eliminieren. Jede gespeicherte Prozedur wurde 1000 Mal von einer Verbindung ausgeführt, und ich habe 1 Verbindung, 10 Verbindungen und 100 Verbindungen (jeweils 1000, 10000 und 100000 Änderungen) getestet. Ich habe Leistungsmetriken mit Query Store erfasst und auch Wartestatistiken erfasst. Mit Query Store konnte ich die durchschnittliche Dauer und CPU für jede gespeicherte Prozedur erfassen. Wartestatistikdaten wurden für jede Verbindung mit dm_exec_session_wait_stats erfasst und dann für den gesamten Test aggregiert.
Ich habe jeden Test viermal durchgeführt und dann die Gesamtmittelwerte für die in diesem Beitrag verwendeten Daten berechnet. Skripte, die für Workload-Tests verwendet werden, können hier heruntergeladen werden.
Ergebnisse
Wie zu erwarten war, war die Leistung mit In-Memory-Objekten besser als mit festplattenbasierten Objekten. Eine In-Memory-Tabelle mit einer regulären gespeicherten Prozedur hatte jedoch manchmal eine vergleichbare oder nur geringfügig bessere Leistung im Vergleich zu einer datenträgerbasierten Tabelle mit einer regulären gespeicherten Prozedur. Denken Sie daran:Ich war daran interessiert zu verstehen, ob ich wirklich eine kompilierte gespeicherte Prozedur benötige, um einen großen Nutzen aus einer In-Memory-Tabelle zu ziehen. Für dieses Szenario habe ich es getan. In allen Fällen hatte die In-Memory-Tabelle mit der nativ kompilierten Prozedur eine deutlich bessere Leistung. Die beiden folgenden Diagramme zeigen dieselben Daten, jedoch mit unterschiedlichen Maßstäben für die x-Achse, um zu veranschaulichen, dass die Leistung für reguläre gespeicherte Prozeduren, die Daten ändern, mit mehr gleichzeitigen Verbindungen abnimmt.
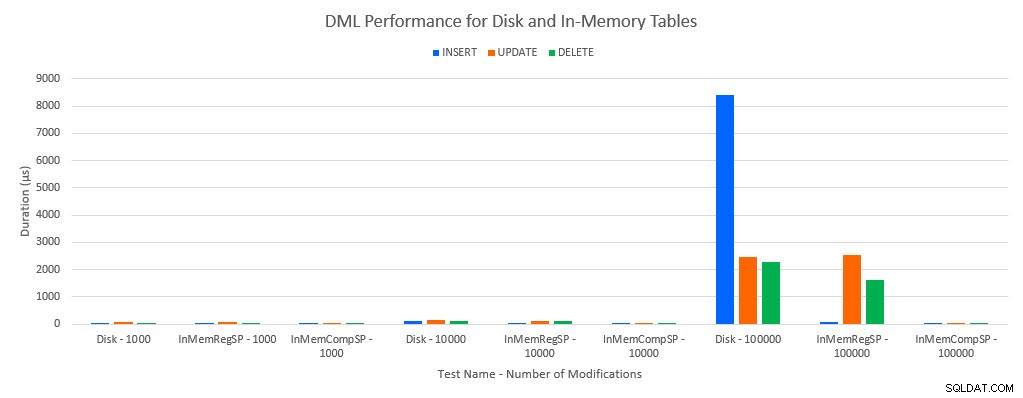
DML-Leistung nach Test und Workload
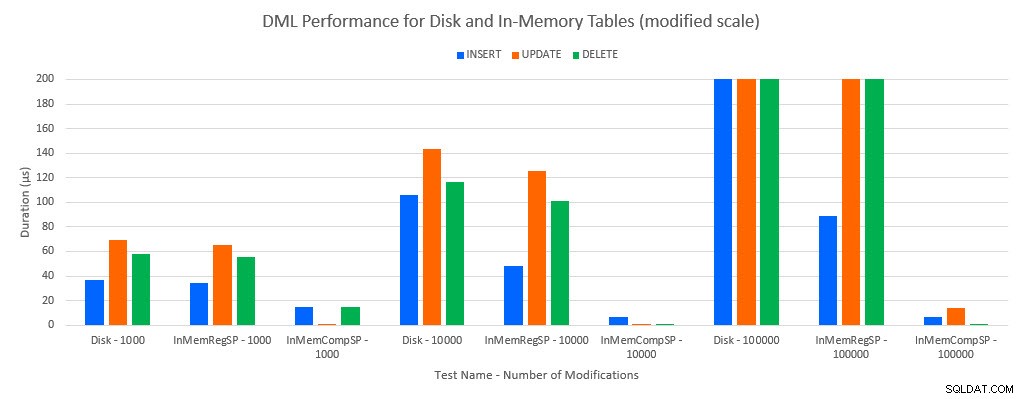
DML-Leistung nach Test und Arbeitslast [geänderte Skala]
Die Ausnahme sind INSERTs in die In-Memory-Tabelle mit der regulären gespeicherten Prozedur. Bei 100 Verbindungen beträgt die durchschnittliche Dauer über 8 ms für eine festplattenbasierte Tabelle, aber weniger als 100 Mikrosekunden für die In-Memory-Tabelle. Der wahrscheinliche Grund ist das Fehlen von Sperren und Latchen mit der In-Memory-Tabelle, und dies wird durch Wartestatistikdaten unterstützt:
| Test | EINFÜGEN | AKTUALISIEREN | LÖSCHEN |
|---|---|---|---|
| Festplattentabelle – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Plattentabelle – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10.000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Plattentabelle – 100.000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
Statistiken nach Test abwarten
Wartestatistikdaten werden hier basierend auf der gesamten Ressourcenwartezeit aufgelistet (was im Allgemeinen auch die höchste durchschnittliche Ressourcenzeit bedeutet, aber es gab Ausnahmen). Der WRITELOG-Wartetyp ist in diesem System die meiste Zeit der begrenzende Faktor. Allerdings wartet PAGELATCH_EX auf 100 gleichzeitige Verbindungen, bei denen INSERT-Anweisungen ausgeführt werden, was darauf hindeutet, dass bei zusätzlicher Last das Sperr- und Verriegelungsverhalten, das bei plattenbasierten Tabellen vorhanden ist, ein einschränkender Faktor sein könnte. In den UPDATE- und DELETE-Szenarien mit 10 und 100 Verbindungen für die plattenbasierten Tabellentests war die durchschnittliche Ressourcenwartezeit für Sperren (LCK_M_X) am höchsten.
Schlussfolgerung
In-Memory-OLTP kann für die richtige Workload absolut eine Leistungssteigerung bieten. Die hier getesteten Beispiele sind jedoch äußerst einfach und sollten nicht als alleiniger Grund gewertet werden, auf eine In-Memory-Lösung zu migrieren. Es gibt immer noch mehrere Einschränkungen, die berücksichtigt werden müssen, und vor einer Migration müssen gründliche Tests durchgeführt werden (insbesondere, weil die Migration zu einer In-Memory-Tabelle ein Offline-Prozess ist). Aber für das richtige Szenario kann diese neue Funktion eine Leistungssteigerung bieten. Solange Sie verstehen, dass einige zugrunde liegende Einschränkungen bestehen bleiben, wie z. B. die Geschwindigkeit des Transaktionsprotokolls für dauerhafte Tabellen, wenn auch höchstwahrscheinlich in reduzierter Weise – unabhängig davon, ob die Tabelle auf der Festplatte oder im Arbeitsspeicher vorhanden ist.