So ziemlich jedes Leistungsproblem im Zusammenhang mit berechneten Spalten, das mir im Laufe der Jahre begegnet ist, hatte eine (oder mehrere) der folgenden Ursachen:
- Einschränkungen bei der Implementierung
- Fehlende Kostenmodellunterstützung im Abfrageoptimierer
- Berechnete Erweiterung der Spaltendefinition vor Beginn der Optimierung
Ein Beispiel für eine Implementierungsbeschränkung ist nicht in der Lage, einen gefilterten Index für eine berechnete Spalte zu erstellen (selbst wenn sie beibehalten wird). Gegen diese Problemkategorie können wir nicht viel tun; Wir müssen Problemumgehungen verwenden, während wir auf Produktverbesserungen warten.
Die fehlende Kostenmodellunterstützung des Optimierers bedeutet, dass SQL Server skalaren Berechnungen unabhängig von der Komplexität oder Implementierung einen kleinen Fixpreis zuweist. Infolgedessen beschließt der Server häufig, einen gespeicherten berechneten Spaltenwert neu zu berechnen, anstatt den persistenten oder indizierten Wert direkt zu lesen. Dies ist besonders ärgerlich, wenn der berechnete Ausdruck teuer ist, beispielsweise wenn es um den Aufruf einer skalaren benutzerdefinierten Funktion geht.
Die Probleme rund um die Definitionserweiterung sind etwas komplizierter und haben weitreichende Auswirkungen.
Die Probleme der berechneten Spaltenerweiterung
SQL Server erweitert berechnete Spalten normalerweise während der Bindungsphase der Abfragenormalisierung in ihre zugrunde liegenden Definitionen. Dies ist eine sehr frühe Phase im Abfragekompilierungsprozess, lange bevor Entscheidungen zur Planauswahl getroffen werden (einschließlich trivialer Pläne).
Theoretisch könnte eine frühzeitige Erweiterung Optimierungen ermöglichen, die andernfalls übersehen würden. Beispielsweise kann der Optimierer möglicherweise Vereinfachungen anwenden, wenn andere Informationen in der Abfrage und in den Metadaten (z. B. Einschränkungen) gegeben sind. Dies ist die gleiche Art von Argumentation, die dazu führt, dass Ansichtsdefinitionen erweitert werden (es sei denn, ein NOEXPAND Hinweis wird verwendet).
Später im Kompilierungsprozess (aber noch bevor auch nur ein trivialer Plan in Betracht gezogen wurde) versucht der Optimierer, Ausdrücke mit persistenten oder indizierten berechneten Spalten abzugleichen. Das Problem ist, dass Optimierer-Aktivitäten in der Zwischenzeit die erweiterten Ausdrücke möglicherweise so geändert haben, dass ein Zurückvergleichen nicht mehr möglich ist.
Wenn dies auftritt, sieht der endgültige Ausführungsplan so aus, als hätte der Optimierer eine „offensichtliche“ Gelegenheit verpasst, eine persistente oder indizierte berechnete Spalte zu verwenden. Es gibt nur wenige Details in den Ausführungsplänen, die helfen können, die Ursache zu ermitteln, was die Fehlersuche und -behebung zu einem potenziell frustrierenden Problem macht.
Abgleich von Ausdrücken mit berechneten Spalten
Besonders hervorzuheben ist, dass es sich hier um zwei getrennte Prozesse handelt:
- Frühe Erweiterung berechneter Spalten; und
- Spätere Versuche, Ausdrücke mit berechneten Spalten abzugleichen.
Beachten Sie insbesondere, dass jeder Abfrageausdruck später mit einer geeigneten berechneten Spalte abgeglichen werden kann, nicht nur Ausdrücke, die aus der Erweiterung berechneter Spalten entstanden sind.
Der Abgleich von berechneten Spaltenausdrücken kann Planverbesserungen ermöglichen, selbst wenn der Text der ursprünglichen Abfrage nicht geändert werden kann. Wenn Sie beispielsweise eine berechnete Spalte erstellen, die mit einem bekannten Abfrageausdruck übereinstimmt, kann der Optimierer Statistiken und Indizes verwenden, die der berechneten Spalte zugeordnet sind. Diese Funktion ähnelt konzeptionell dem Abgleich indizierter Ansichten in der Enterprise Edition. Der berechnete Spaltenabgleich funktioniert in allen Editionen.
Aus praktischer Sicht ist meine eigene Erfahrung, dass der Abgleich allgemeiner Abfrageausdrücke mit berechneten Spalten tatsächlich die Leistung, Effizienz und Stabilität des Ausführungsplans verbessern kann. Andererseits habe ich selten (wenn überhaupt) festgestellt, dass sich die berechnete Spaltenerweiterung lohnt. Es scheint einfach nie nützliche Optimierungen zu liefern.
Verwendung berechneter Spalten
Berechnete Spalten, die weder noch sind persistent oder indiziert haben gültige Verwendungen. Beispielsweise können sie automatische Statistiken unterstützen, wenn die Spalte deterministisch und präzise ist (keine Gleitkommaelemente). Sie können auch verwendet werden, um Speicherplatz zu sparen (auf Kosten einer etwas zusätzlichen Laufzeitprozessornutzung). Als letztes Beispiel können sie eine nette Möglichkeit bieten, sicherzustellen, dass eine einfache Berechnung immer korrekt ausgeführt wird, anstatt jedes Mal explizit in Abfragen geschrieben zu werden.
Bestanden Berechnete Spalten wurden dem Produkt speziell hinzugefügt, damit Indizes auf deterministischen, aber "ungenauen" (Gleitkomma-)Spalten erstellt werden können. Dieser Verwendungszweck ist meiner Erfahrung nach relativ selten. Vielleicht liegt das einfach daran, dass ich Gleitkommadaten nicht oft begegne.
Abgesehen von Gleitkomma-Indizes sind persistente Spalten ziemlich häufig. Dies kann bis zu einem gewissen Grad daran liegen, dass unerfahrene Benutzer davon ausgehen, dass eine berechnete Spalte immer beibehalten werden muss, bevor sie indiziert werden kann. Erfahrenere Benutzer können dauerhafte Spalten verwenden, einfach weil sie festgestellt haben, dass die Leistung auf diese Weise tendenziell besser ist.
Indiziert berechnete Spalten (persistent oder nicht) können verwendet werden, um eine Sortierung und eine effiziente Zugriffsmethode bereitzustellen. Es kann nützlich sein, einen berechneten Wert in einem Index zu speichern, ohne ihn auch in der Basistabelle zu speichern. Ebenso können geeignete berechnete Spalten auch in Indizes aufgenommen werden, anstatt Schlüsselspalten zu sein.
Schlechte Leistung
Eine Hauptursache für schlechte Leistung ist ein einfaches Versäumnis, einen indizierten oder persistenten berechneten Spaltenwert wie erwartet zu verwenden. Ich habe die Anzahl der Fragen verloren, die ich im Laufe der Jahre hatte, warum der Optimierer einen schlechten Ausführungsplan wählen würde, wenn ein offensichtlich besserer Plan mit einer indizierten oder persistenten berechneten Spalte existiert.
Die genaue Ursache ist in jedem Fall unterschiedlich, aber fast immer entweder eine fehlerhafte kostenbasierte Entscheidung (weil Skalaren niedrige Fixkosten zugewiesen werden); oder ein Fehler beim Abgleichen eines erweiterten Ausdrucks mit einer persistenten berechneten Spalte oder einem Index.
Die Match-Back-Fehler sind für mich besonders interessant, da sie oft komplexe Interaktionen mit orthogonalen Engine-Features beinhalten. Ebenso oft hinterlässt der Fehler beim „Zurückpassen“ einen Ausdruck (statt einer Spalte) an einer Position in der internen Abfragestruktur, die verhindert, dass eine wichtige Optimierungsregel abgeglichen wird. In beiden Fällen ist das Ergebnis dasselbe:ein suboptimaler Ausführungsplan.
Nun, ich denke, es ist fair zu sagen, dass Leute im Allgemeinen eine berechnete Spalte indizieren oder beibehalten, mit der starken Erwartung, dass der gespeicherte Wert tatsächlich verwendet wird. Es kann ein ziemlicher Schock sein, zu sehen, wie SQL Server den zugrunde liegenden Ausdruck jedes Mal neu berechnet, während der absichtlich bereitgestellte gespeicherte Wert ignoriert wird. Die Mitarbeiter interessieren sich nicht immer sehr für die internen Interaktionen und Mängel des Kostenmodells, die zu dem unerwünschten Ergebnis geführt haben. Selbst wenn Problemumgehungen vorhanden sind, erfordern diese Zeit, Geschick und Mühe, um sie zu entdecken und zu testen.
Kurz gesagt:Viele Leute würden es SQL Server einfach vorziehen, den persistenten oder indizierten Wert zu verwenden. Immer.
Eine neue Option
In der Vergangenheit gab es keine Möglichkeit, SQL Server zu zwingen, immer den gespeicherten Wert zu verwenden (kein Äquivalent zu NOEXPAND Hinweis für Aufrufe). Es gibt einige Umstände, unter denen eine Planhilfe funktioniert, aber es ist nicht immer möglich, die erforderliche Planform von vornherein zu generieren, und nicht alle Planelemente und Positionen können erzwungen werden (z. B. Filter und Berechnungsskalare).
Es gibt immer noch keine ordentliche, vollständig dokumentierte Lösung, aber ein aktuelles Update auf SQL Server 2016 hat einen interessanten neuen Ansatz geliefert. Es gilt für SQL Server 2016-Instanzen, die mindestens mit dem kumulativen Update 2 für SQL Server 2016 SP1 oder dem kumulativen Update 4 für SQL Server 2016 RTM gepatcht wurden.
Das relevante Update ist dokumentiert in:FIX:Die Partition kann für eine Tabelle, die eine berechnete Partitionierungsspalte in SQL Server 2016 enthält, nicht online neu erstellt werden
Wie so oft bei der Support-Dokumentation sagt diese nicht genau aus, was an der Engine geändert wurde, um das Problem zu beheben. Dem Titel und der Beschreibung nach zu urteilen, scheint es sicherlich nicht besonders relevant für unsere aktuellen Bedenken zu sein. Dennoch führt dieser Fix ein neues unterstütztes Ablaufverfolgungsflag 176 ein , die in einer Codemethode namens FDontExpandPersistedCC überprüft wird . Wie der Methodenname andeutet, verhindert dies, dass eine persistente berechnete Spalte erweitert wird.
Dazu gibt es drei wichtige Vorbehalte:
- Die berechnete Spalte muss beibehalten werden . Auch wenn sie indiziert ist, muss die Spalte auch beibehalten werden.
- Der Abgleich von allgemeinen Abfrageausdrücken mit persistenten berechneten Spalten ist deaktiviert .
- Die Dokumentation beschreibt nicht die Funktion des Trace-Flags und schreibt es nicht für eine andere Verwendung vor. Wenn Sie sich dafür entscheiden, das Ablaufverfolgungsflag 176 zu verwenden, um die Erweiterung von persistenten berechneten Spalten zu verhindern, geschieht dies daher auf Ihr eigenes Risiko.
Dieses Trace-Flag wirkt als Start-–T Option sowohl im globalen als auch im Sitzungsbereich mit DBCC TRACEON , und pro Abfrage mit OPTION (QUERYTRACEON) .
Beispiel
Dies ist eine vereinfachte Version einer Frage (basierend auf einem realen Problem), die ich vor einigen Jahren auf Database Administrators Stack Exchange beantwortet habe. Die Tabellendefinition enthält eine persistente berechnete Spalte:
CREATE TABLE dbo.T( ID integer IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Berechnet ALS A + '-' + B + '-' + C PERSISTED, CONSTRAINT PK_T_ID PRIMARY KEY CLUSTERED (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.number % 20, 2), C =STR(SV.number % 30, 2), D =DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P';
Die folgende Abfrage gibt alle Zeilen aus der Tabelle in einer bestimmten Reihenfolge zurück, während sie auch den nächsten Wert von Spalte D in derselben Reihenfolge zurückgibt:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1ORDER BY T1.Computed, T1.D;
Ein offensichtlicher abdeckender Index zur Unterstützung der endgültigen Reihenfolge und Suche in der Unterabfrage ist:
CREATE UNIQUE NOCLLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Berechnet, D, ID);
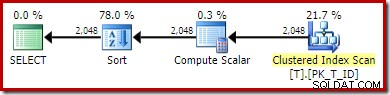
Der vom Optimierer gelieferte Ausführungsplan ist überraschend und enttäuschend:
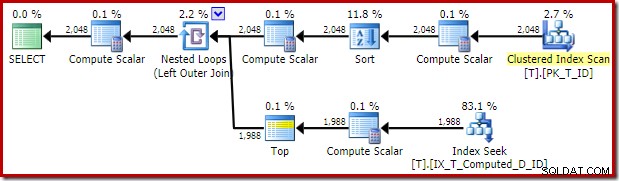
Der Index Seek auf der Innenseite des Nested Loops Join scheint alles in Ordnung zu sein. Das Clustered Index Scan and Sort an der äußeren Eingabe ist jedoch unerwartet. Wir hätten gehofft, stattdessen einen geordneten Scan unseres abdeckenden Nonclustered-Index zu sehen.
Wir können den Optimierer zwingen, den Nonclustered-Index mit einem Tabellenhinweis zu verwenden:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1 WITH (INDEX(IX_T_Computed_D_ID)) -- New!ORDER BY T1.Computed, T1.D;
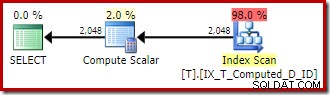
Der resultierende Ausführungsplan lautet:
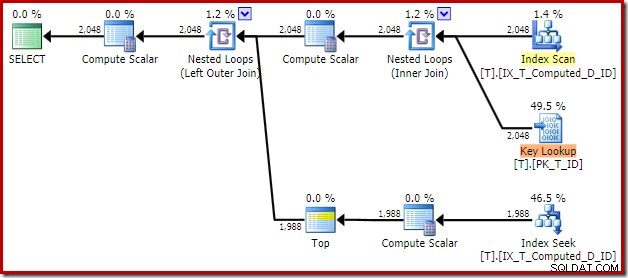
Das Scannen des Nonclustered-Index entfernt die Sortierung, fügt aber eine Schlüsselsuche hinzu! Die Suchvorgänge in diesem neuen Plan sind überraschend, da unser Index definitiv alle für die Abfrage erforderlichen Spalten abdeckt.
Betrachten Sie die Eigenschaften des Key Lookup-Operators:
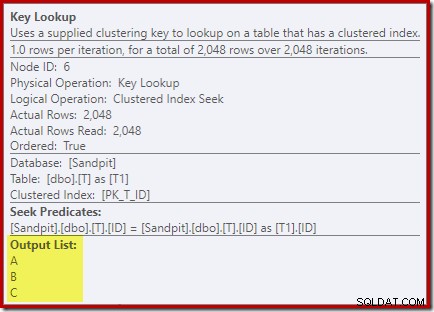
Aus irgendeinem Grund hat der Optimierer entschieden, dass drei Spalten, die nicht in der Abfrage erwähnt werden, aus der Basistabelle abgerufen werden müssen (da sie absichtlich nicht in unserem Nonclustered-Index vorhanden sind).
Wenn wir uns im Ausführungsplan umsehen, stellen wir fest, dass die nachgeschlagenen Spalten von der Innenseite Index Seek:
benötigt werden

Der erste Teil dieses Suchprädikats entspricht der Korrelation T2.Computed = T1.Computed in der ursprünglichen Abfrage. Der Optimierer hat die Definitionen beider berechneter Spalten erweitert, aber es gelang ihm nur, den Alias T1 der inneren Seite wieder mit der persistenten und indizierten berechneten Spalte abzugleichen . Verlassen Sie das T2 Verweis erweitert hat dazu geführt, dass die Außenseite des Joins die Spalten der Basistabelle bereitstellen muss (A , B , und C ) benötigt, um diesen Ausdruck für jede Zeile zu berechnen.
Wie es manchmal der Fall ist, ist es möglich, diese Abfrage so umzuschreiben, dass das Problem verschwindet (eine Option wird in meiner alten Antwort auf die Stack Exchange-Frage gezeigt). Unter Verwendung von SQL Server 2016 können wir auch das Ablaufverfolgungsflag 176 versuchen, um zu verhindern, dass die berechneten Spalten erweitert werden:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1ORDER BY T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Neu!
Der Ausführungsplan wurde jetzt stark verbessert:
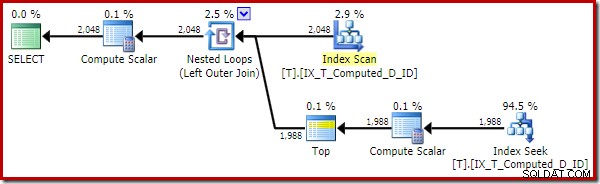
Dieser Ausführungsplan enthält nur Verweise auf die berechneten Spalten. Die Compute Scalars tun nichts Nützliches und würden aufgeräumt, wenn der Optimierer im Haus etwas aufgeräumter wäre.
Der wichtige Punkt ist, dass der optimale Index jetzt korrekt verwendet wird und Sortierung und Schlüsselsuche eliminiert wurden. Alles, indem SQL Server daran gehindert wird, etwas zu tun, was wir nie erwartet hätten (Erweitern einer persistenten und indizierten berechneten Spalte).
Mit LEAD
Die ursprüngliche Stack Exchange-Frage zielte auf SQL Server 2008 ab, wobei LEAD ist nicht verfügbar. Lassen Sie uns versuchen, die Anforderung auf SQL Server 2016 mit der neueren Syntax auszudrücken:
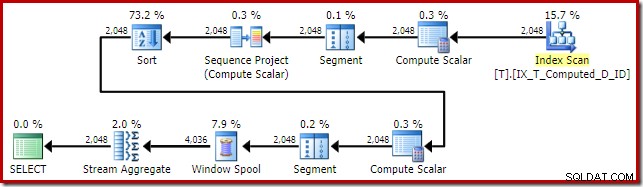
SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed;Der Ausführungsplan für SQL Server 2016 lautet:
Diese Planform ist ziemlich typisch für eine einfache Zeilenmodus-Fensterfunktion. Das einzige unerwartete Element ist der Sort-Operator in der Mitte. Wenn der Datensatz groß wäre, könnte diese Sortierung einen großen Einfluss auf die Leistung und die Speichernutzung haben.
Das Problem ist wieder einmal die berechnete Spaltenerweiterung. In diesem Fall befindet sich einer der erweiterten Ausdrücke an einer Position, die verhindert, dass die normale Optimierungslogik das Wegsortieren vereinfacht.
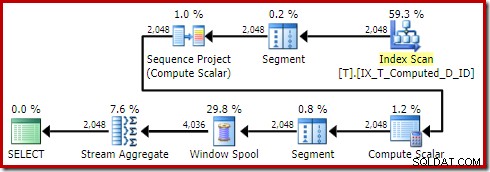
Versuchen Sie genau dieselbe Abfrage mit Ablaufverfolgungsflag 176:
SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER (PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Erzeugt den Plan:
Die Sortierung ist verschwunden, wie sie sollte. Beachten Sie auch nebenbei, dass diese Abfrage für einen trivialen Plan geeignet war, wodurch eine kostenbasierte Optimierung vollständig vermieden wurde.
Deaktivierter allgemeiner Ausdrucksabgleich
Einer der zuvor erwähnten Vorbehalte war, dass das Ablaufverfolgungsflag 176 auch den Abgleich von Ausdrücken in der Quellabfrage mit persistenten berechneten Spalten deaktiviert.
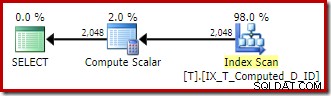
Betrachten Sie zur Veranschaulichung die folgende Version der Beispielabfrage. Der
LEADBerechnung wurde entfernt, und die Verweise auf die berechnete Spalte inSELECTundORDER BYKlauseln wurden durch die zugrunde liegenden Ausdrücke ersetzt. Führen Sie es zuerst ohne Trace-Flag 176 aus:SELECT T1.ID, Berechnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;Die Ausdrücke werden mit der persistent berechneten Spalte abgeglichen, und der Ausführungsplan ist ein einfacher geordneter Scan des Nonclustered-Index:
Der Compute Scalar dort ist mal wieder nur übriggebliebener Architekturschrott.
Versuchen Sie nun dieselbe Abfrage mit aktiviertem Trace-Flag 176:
SELECT T1.ID, Berechnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Neu!Der neue Ausführungsplan lautet:
Der Nonclustered Index Scan wurde durch einen Clustered Index Scan ersetzt. Der Berechnungsskalar wertet den Ausdruck und die Sortierreihenfolge nach dem Ergebnis aus. Da der Optimierer nicht in der Lage ist, Ausdrücke mit dauerhaft berechneten Spalten abzugleichen, kann er den dauerhaften Wert oder den nicht gruppierten Index nicht verwenden.
Beachten Sie, dass die Einschränkung des Ausdrucksabgleichs nur für persistent gilt berechnete Spalten, wenn das Trace-Flag 176 aktiv ist. Wenn wir die berechnete Spalte indexieren, aber nicht beibehalten, funktioniert der Ausdrucksabgleich korrekt.
Um das dauerhafte Attribut zu löschen, müssen wir zuerst den nicht gruppierten Index löschen. Sobald die Änderung vorgenommen wurde, können wir den Index direkt zurücksetzen (weil der Ausdruck deterministisch und präzise ist):
DROP INDEX IX_T_Computed_D_ID ON dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Berechnet, D, ID);Der Optimierer hat jetzt keine Probleme, den Abfrageausdruck der berechneten Spalte zuzuordnen, wenn das Trace-Flag 176 aktiv ist:
– Berechnete Spalte nicht mehr persistent – aber immer noch indiziert. TF 176 aktiv. SELECT T1.ID, Berechnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Der Ausführungsplan kehrt ohne Sortierung zum optimalen Nonclustered-Index-Scan zurück:
Zusammenfassend:Das Ablaufverfolgungsflag 176 verhindert eine dauerhafte Erweiterung der berechneten Spalte. Als Nebeneffekt wird auch verhindert, dass der Abfrageausdruck nur mit persistenten berechneten Spalten übereinstimmt.
Schemametadaten werden nur einmal während der Bindungsphase geladen. Das Ablaufverfolgungsflag 176 verhindert die Erweiterung, sodass die berechnete Spaltendefinition zu diesem Zeitpunkt nicht geladen wird. Ein späterer Ausdruck-zu-Spalte-Abgleich kann ohne die berechnete Spaltendefinition nicht funktionieren, mit der abgeglichen werden soll.
Das anfängliche Laden der Metadaten bringt alle Spalten ein, nicht nur die, auf die in der Abfrage verwiesen wird (diese Optimierung wird später durchgeführt). Dadurch werden alle berechneten Spalten für den Abgleich verfügbar, was im Allgemeinen eine gute Sache ist. Wenn eine der geladenen berechneten Spalten eine benutzerdefinierte Skalarfunktion enthält, deaktiviert ihr Vorhandensein leider die Parallelität für die gesamte Abfrage, selbst wenn die problematische Spalte nicht verwendet wird. Auch das Ablaufverfolgungsflag 176 kann dabei helfen, wenn die betreffende Spalte beibehalten wird. Indem die Definition nicht geladen wird, ist niemals eine skalare benutzerdefinierte Funktion vorhanden, sodass die Parallelität nicht deaktiviert wird.
Abschließende Gedanken
Es scheint mir, dass die SQL Server-Welt ein besserer Ort wäre, wenn der Optimierer persistente oder indizierte berechnete Spalten eher wie normale Spalten behandeln würde. In fast allen Fällen würde dies den Erwartungen der Entwickler besser entsprechen als die derzeitige Anordnung. Das Erweitern berechneter Spalten in ihre zugrunde liegenden Ausdrücke und der spätere Versuch, sie wieder abzugleichen, ist in der Praxis nicht so erfolgreich, wie die Theorie vermuten lässt.
Bis SQL Server spezifische Unterstützung bietet, um die Erweiterung von persistenten oder indizierten berechneten Spalten zu verhindern, ist das neue Ablaufverfolgungsflag 176 eine verlockende Option für Benutzer von SQL Server 2016, wenn auch eine unvollkommene. Es ist ein wenig unglücklich, dass es als Nebeneffekt den allgemeinen Ausdrucksabgleich deaktiviert. Schade ist auch, dass die berechnete Spalte bei der Indizierung persistiert werden muss. Es besteht dann das Risiko, ein Trace-Flag für einen anderen als den dokumentierten Zweck zu verwenden.
Man kann mit Fug und Recht sagen, dass die meisten Probleme mit berechneten Spaltenabfragen letztendlich auf andere Weise gelöst werden können, wenn genügend Zeit, Mühe und Fachwissen vorhanden sind. Andererseits scheint das Ablaufverfolgungsflag 176 oft wie Zauberei zu wirken. Sie haben die Wahl, wie man so schön sagt.
Zum Abschluss noch einige interessante Probleme mit berechneten Spalten, die vom Trace-Flag 176 profitieren:
- Berechneter Spaltenindex nicht verwendet
- PERSISTED-berechnete Spalte, die bei der Partitionierung der Windowing-Funktion nicht verwendet wird
- Bestandene berechnete Spalte, die einen Scan verursacht
- Berechneter Spaltenindex wird nicht mit MAX-Datentypen verwendet
- Schwerwiegendes Leistungsproblem bei dauerhaft berechneten Spalten und Joins
- Warum „rechnet“ SQL Server „Skalar“, wenn ich eine dauerhaft berechnete Spalte auswähle?
- Basisspalten, die anstelle von persistenten berechneten Spalten von der Engine verwendet werden
- Berechnete Spalte mit UDF deaktiviert Parallelität für Abfragen auf *anderen* Spalten