Die Verkettung von zwei oder mehr Datensätzen wird am häufigsten in T-SQL mit UNION ALL ausgedrückt Klausel. Angesichts der Tatsache, dass der SQL Server-Optimierer oft Dinge wie Joins und Aggregate neu anordnen kann, um die Leistung zu verbessern, ist es durchaus vernünftig zu erwarten, dass SQL Server auch eine Neuordnung von Verkettungseingaben in Betracht ziehen würde, wenn dies einen Vorteil bieten würde. Beispielsweise könnte der Optimierer die Vorteile des Umschreibens von A UNION ALL B berücksichtigen als B UNION ALL A .
Tatsächlich tut das der SQL Server-Optimierer nicht mach das. Genauer gesagt gab es in SQL Server-Versionen bis 2008 R2 eine begrenzte Unterstützung für die Neuordnung von Verkettungseingaben, die jedoch entfernt wurde in SQL Server 2012 und ist seitdem nicht mehr aufgetaucht.
SQL Server 2008 R2
Intuitiv spielt die Reihenfolge der Verkettungseingaben nur eine Rolle, wenn es ein Zeilenziel gibt . Standardmäßig optimiert SQL Server Ausführungspläne auf der Grundlage, dass alle qualifizierten Zeilen an den Client zurückgegeben werden. Wenn ein Zeilenziel in Kraft ist, versucht der Optimierer, einen Ausführungsplan zu finden, der die ersten paar Zeilen schnell produziert.
Zeilenziele können auf verschiedene Arten festgelegt werden, zum Beispiel mit TOP , ein FAST n Abfragehinweis oder durch Verwendung von EXISTS (die naturgemäß höchstens eine Zeile finden muss). Wo es kein Zeilenziel gibt (d. h. der Client benötigt alle Zeilen), spielt es im Allgemeinen keine Rolle, in welcher Reihenfolge die Verkettungseingaben gelesen werden:Jede Eingabe wird schließlich in jedem Fall vollständig verarbeitet.
Die eingeschränkte Unterstützung in Versionen bis SQL Server 2008 R2 gilt, wenn das Ziel genau eine Zeile ist . In diesem speziellen Fall ordnet SQL Server die Verkettungseingaben auf der Grundlage der erwarteten Kosten neu.
Dies geschieht nicht während der kostenbasierten Optimierung (wie man erwarten könnte), sondern eher als Umschreiben der normalen Optimiererausgabe in letzter Minute nach der Optimierung. Diese Anordnung hat den Vorteil, dass der kostenbasierte Plansuchraum nicht vergrößert wird (möglicherweise eine Alternative für jede mögliche Neuordnung), während dennoch ein Plan erstellt wird, der optimiert ist, um die erste Zeile schnell zurückzugeben.
Beispiele
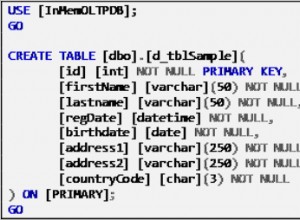
Die folgenden Beispiele verwenden zwei Tabellen mit identischem Inhalt:Eine Million Zeilen mit ganzen Zahlen von eins bis eine Million. Eine Tabelle ist ein Heap ohne Nonclustered-Indizes; der andere hat einen eindeutigen gruppierten Index:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Kein Zeilenziel
Die folgende Abfrage sucht in jeder Tabelle nach denselben Zeilen und gibt die Verkettung der beiden Sätze zurück:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Der vom Abfrageoptimierer erstellte Ausführungsplan lautet:
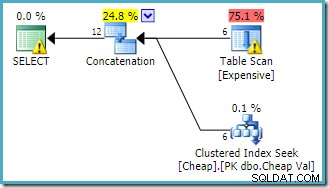
Die Warnung auf der Wurzel SELECT Operator macht uns auf den offensichtlich fehlenden Index in der Heap-Tabelle aufmerksam. Die Warnung zum Table Scan-Operator wird von Sentry One Plan Explorer hinzugefügt. Es lenkt unsere Aufmerksamkeit auf die E/A-Kosten des im Scan verborgenen Restprädikats.
Die Reihenfolge der Eingaben zur Verkettung spielt hier keine Rolle, da wir kein Zeilenziel festgelegt haben. Beide Eingaben werden vollständig gelesen, um alle Ergebniszeilen zurückzugeben. Interessanterweise (obwohl dies nicht garantiert ist) beachten Sie, dass die Reihenfolge der Eingaben der Textreihenfolge der ursprünglichen Abfrage folgt. Beachten Sie auch, dass die Reihenfolge der endgültigen Ergebniszeilen ebenfalls nicht angegeben ist, da wir kein ORDER BY auf oberster Ebene verwendet haben Klausel. Wir gehen davon aus, dass dies beabsichtigt ist und die endgültige Bestellung für die anstehende Aufgabe belanglos ist.
Wenn wir die geschriebene Reihenfolge der Tabellen in der Abfrage wie folgt umkehren:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Der Ausführungsplan folgt der Änderung und greift zuerst auf die gruppierte Tabelle zu (auch dies ist nicht garantiert):
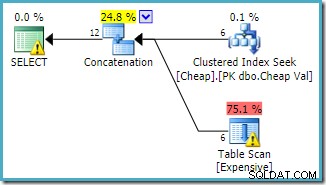
Es ist zu erwarten, dass beide Abfragen dieselben Leistungsmerkmale aufweisen, da sie dieselben Operationen ausführen, nur in einer anderen Reihenfolge.
Mit einem Reihenziel
Das Fehlen einer Indizierung in der Heap-Tabelle macht das Auffinden bestimmter Zeilen normalerweise teurer als die gleiche Operation in der Cluster-Tabelle. Wenn wir den Optimierer nach einem Plan fragen, der die erste Zeile schnell zurückgibt, würden wir erwarten, dass SQL Server die Verkettungseingaben neu ordnet, sodass die billige gruppierte Tabelle zuerst konsultiert wird.
Verwendung der Abfrage, die die Heap-Tabelle zuerst erwähnt, und Verwendung eines FAST 1-Abfragehinweises zur Angabe des Zeilenziels:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Der geschätzte Ausführungsplan, der auf einer Instanz von SQL Server 2008 R2 erstellt wurde ist:
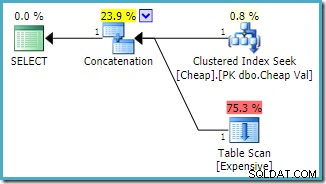
Beachten Sie, dass die Verkettungseingaben neu geordnet wurden, um die geschätzten Kosten für die Rückgabe der ersten Zeile zu reduzieren. Beachten Sie auch, dass der fehlende Index und die verbleibenden E/A-Warnungen verschwunden sind. Beide Probleme sind bei dieser Planform nicht von Bedeutung, wenn das Ziel darin besteht, eine einzelne Zeile so schnell wie möglich zurückzugeben.
Dieselbe Abfrage, die auf SQL Server 2016 ausgeführt wird (unter Verwendung eines der Kardinalitätsschätzungsmodelle) ist:
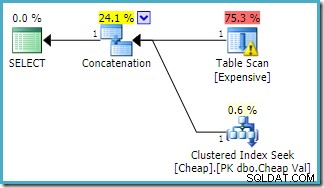
SQL Server 2016 hat die Verkettungseingaben nicht neu geordnet. Die E/A-Warnung des Plan-Explorers ist zurückgekehrt, aber leider hat der Optimierer dieses Mal keine Warnung über einen fehlenden Index ausgegeben (obwohl es relevant ist).
Allgemeine Neuordnung
Wie bereits erwähnt, ist die Umschreibung nach der Optimierung, die die Verkettungseingaben neu ordnet, nur wirksam für:
- SQL Server 2008 R2 und früher
- Ein Zeilenziel von genau einem
Wenn wir wirklich nur eine Zeile zurückgeben wollen und nicht einen Plan, der darauf optimiert ist, die erste Zeile schnell zurückzugeben (der aber letztendlich immer noch alle Zeilen zurückgibt), können wir einen TOP verwenden -Klausel mit einer abgeleiteten Tabelle oder einem allgemeinen Tabellenausdruck (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; Auf SQL Server 2008 R2 oder früher erzeugt dies den optimalen neu geordneten Eingabeplan:
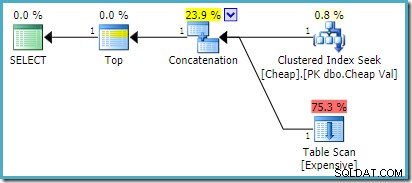
Auf SQL Server 2012, 2014 und 2016 erfolgt keine Neuordnung nach der Optimierung:
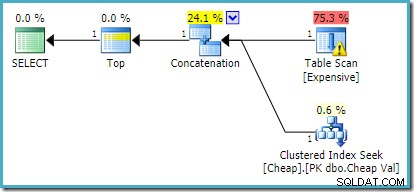
Wenn mehr als eine Zeile zurückgegeben werden soll, zum Beispiel mit TOP (2) , wird die gewünschte Umschreibung nicht angewendet auf SQL Server 2008 R2, auch wenn ein FAST 1 Hinweis wird ebenfalls verwendet. In dieser Situation müssen wir auf Tricks wie die Verwendung von TOP zurückgreifen mit einer Variablen und einem OPTIMIZE FOR Hinweis:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Der Abfragehinweis reicht aus, um ein Zeilenziel von eins festzulegen, während der Laufzeitwert der Variablen sicherstellt, dass die gewünschte Anzahl von Zeilen (2) zurückgegeben wird.
Der tatsächliche Ausführungsplan auf SQL Server 2008 R2 lautet:
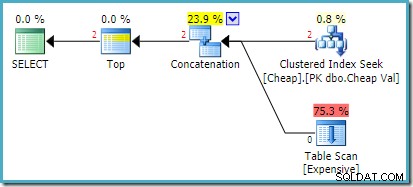
Beide zurückgegebenen Zeilen stammen aus der neu geordneten Sucheingabe, und der Tabellenscan wird überhaupt nicht ausgeführt. Der Plan-Explorer zeigt die Zeilenanzahl in Rot an, da die Schätzung (aufgrund des Hinweises) für eine Zeile galt, während zur Laufzeit zwei Zeilen gefunden wurden.
Ohne UNION ALL
Dieses Problem ist auch nicht auf explizit mit UNION ALL geschriebene Abfragen beschränkt . Andere Konstruktionen wie EXISTS und OR kann auch dazu führen, dass der Optimierer einen Verkettungsoperator einführt, der unter der fehlenden Neuordnung der Eingabe leiden kann. Es gab kürzlich eine Frage zu Database Administrators Stack Exchange mit genau diesem Problem. Transformieren der Abfrage aus dieser Frage, um unsere Beispieltabellen zu verwenden:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Der Ausführungsplan auf SQL Server 2016 hat die Heap-Tabelle in der ersten Eingabe:
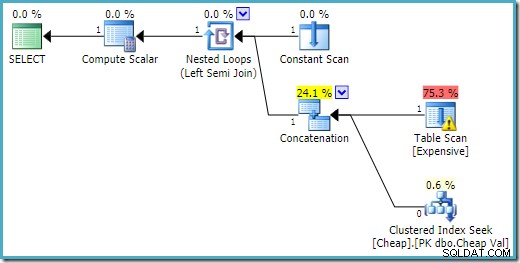
Auf SQL Server 2008 R2 ist die Reihenfolge der Eingaben optimiert, um das einzelne Zeilenziel des Semi-Joins widerzuspiegeln:
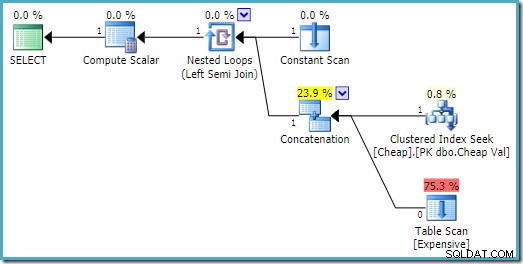
Im optimaleren Plan wird der Heap-Scan nie ausgeführt.
Problemumgehungen
In einigen Fällen wird es für den Abfrageschreiber offensichtlich sein, dass eine der Verkettungseingaben immer billiger auszuführen ist als die anderen. Wenn dies zutrifft, ist es durchaus zulässig, die Abfrage so umzuschreiben, dass die billigeren Verkettungseingaben zuerst in schriftlicher Reihenfolge erscheinen. Dies bedeutet natürlich, dass der Abfrageautor sich dieser Einschränkung des Optimierers bewusst sein und darauf vorbereitet sein muss, sich auf undokumentiertes Verhalten zu verlassen.
Ein schwierigeres Problem entsteht, wenn die Kosten der Verkettungseingaben mit den Umständen variieren, vielleicht in Abhängigkeit von Parameterwerten. Mit OPTION (RECOMPILE) wird auf SQL Server 2012 oder höher nicht helfen. Diese Option kann auf SQL Server 2008 R2 oder früher hilfreich sein, aber nur, wenn die Zielanforderung für eine einzelne Zeile ebenfalls erfüllt ist.
Wenn es Bedenken gibt, sich auf das beobachtete Verhalten zu verlassen (Abfrageplanverkettungseingaben, die mit der Textreihenfolge der Abfrage übereinstimmen), kann eine Planleitlinie verwendet werden, um die Planform zu erzwingen. Wenn unterschiedliche Eingabereihenfolgen für unterschiedliche Umstände optimal sind, können mehrere Planleitlinien verwendet werden, bei denen die Bedingungen im Voraus genau codiert werden können. Dies ist jedoch kaum ideal.
Abschließende Gedanken
Der Abfrageoptimierer von SQL Server enthält tatsächlich eine kostenbasierte Erkundungsregel, UNIAReorderInputs , das in der Lage ist, Variationen der Verkettungseingabereihenfolge zu generieren und Alternativen während der kostenbasierten Optimierung zu untersuchen (nicht als Single-Shot-Umschreibung nach der Optimierung).
Diese Regel ist derzeit nicht für die allgemeine Verwendung aktiviert. Soweit ich das beurteilen kann, wird es nur aktiviert, wenn eine Plananleitung oder USE PLAN Hinweis ist vorhanden. Dadurch kann die Engine erfolgreich einen Plan erzwingen, der für eine Abfrage generiert wurde, die sich für das Umschreiben der Eingabeumordnung qualifiziert hat, selbst wenn die aktuelle Abfrage nicht geeignet ist.
Meiner Meinung nach ist diese Explorationsregel bewusst auf diese Verwendung beschränkt, weil Abfragen, die von einer Neuordnung der Verkettungseingabe im Rahmen der kostenbasierten Optimierung profitieren würden, als nicht ausreichend häufig angesehen werden, oder weil vielleicht Bedenken bestehen, dass sich der zusätzliche Aufwand nicht auszahlen würde aus. Meine eigene Ansicht ist, dass die Neuordnung von Eingaben durch Verkettungsoperatoren immer untersucht werden sollte, wenn ein Zeilenziel in Kraft ist.
Schade ist auch, dass das (beschränktere) Umschreiben nach der Optimierung in SQL Server 2012 oder höher nicht wirksam ist. Dies könnte an einem subtilen Fehler liegen, aber ich konnte nichts darüber in der Dokumentation, der Wissensdatenbank oder auf Connect finden. Ich habe hier ein neues Connect-Element hinzugefügt.
Aktualisierung vom 9. August 2017 :Dies ist jetzt behoben unter Ablaufverfolgungsflag 4199 für SQL Server 2014 und 2016, siehe KB 4023419:
FIX:Abfragen mit UNION ALL und einem Zeilenziel können in SQL Server 2014 oder späteren Versionen im Vergleich zu SQL Server 2008 R2 langsamer ausgeführt werden