Einführung
In diesem Artikel erläutern wir, wie sich verschiedene Arten von Indizes in speicheroptimierten SQL Server-Tabellen auf die Leistung auswirken. Wir werden Beispiele untersuchen, wie sich verschiedene Indextypen auf die Leistung von speicheroptimierten Tabellen auswirken können.
Um die Themendiskussion zu vereinfachen, verwenden wir ein ziemlich großes Beispiel. Der Einfachheit halber enthält dieses Beispiel verschiedene Replikate einer einzelnen Tabelle, für die wir verschiedene Abfragen ausführen. Diese Replikate verwenden unterschiedliche Indizes oder gar keine Indizes (außer natürlich die Primärschlüssel – PKs).
Beachten Sie, dass der eigentliche Zweck dieses Artikels nicht darin besteht, die Leistung zwischen datenträgerbasierten und speicheroptimierten Tabellen in SQL Server an sich zu vergleichen. Sein Zweck besteht darin, zu untersuchen, wie sich Indizes auf die Leistung in speicheroptimierten Tabellen auswirken. Um jedoch ein vollständiges Bild der Experimente zu erhalten, werden auch Zeitangaben für die entsprechenden datenträgerbasierten Tabellenabfragen bereitgestellt, und die Beschleunigungen werden unter Verwendung der optimalsten Konfiguration von datenträgerbasierten Tabellen als Basis berechnet.
Szenario
Beispieldaten für unser Szenario basieren auf einer einzelnen Tabelle, die wie folgt definiert ist:
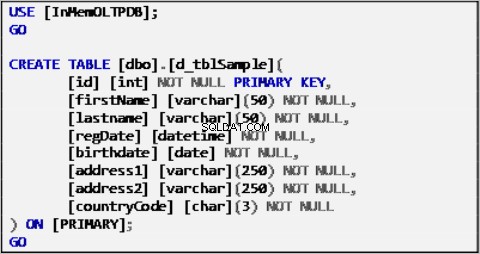
Listing 1:Beispieldatenquellentabelle.
Die obige Tabelle wurde mit Beispieldaten gefüllt und dient als Datenquelle für die restlichen Tabellen.
Basierend auf der obigen Tabelle erstellen wir also die folgenden 9 Tabellenvariationen und füllen sie mit denselben Beispieldaten:
- 3 festplattenbasierte Tabellen:
- d_tblSample1
- Clustered-Index für die Spalte „id“ – Primärschlüssel (PK)
- d_tblSample2
- Clustered-Index für die „id“-Spalte (PK)
- Nicht gruppierter Index in der Spalte „countryCode“
- d_tblSample3
- Clustered-Index für die „id“-Spalte (PK)
- Nicht gruppierte Indizes in der Spalte „regDate“
- Nicht geclusterte Indizes in der Spalte „countryCode“
- d_tblSample1
- 3 speicheroptimierte Tabellen (Satz 1:Hash-Indizes):
- m1_tblSample1
- Nicht geclusterter Hash-Index für die Spalte „id“ – Primärschlüssel (PK)
- m1_tblSample2
- Nicht geclusterter Hash-Index für die „id“-Spalte (PK)
- Hash-Index für die Spalte „countryCode“
- m1_tblSample3
- Nicht geclusterter Hash-Index für die „id“-Spalte (PK)
- Hash-Index für die Spalte „regDate“
- Hash-Index für die Spalte „countryCode“
- 3 speicheroptimierte Tabellen (Satz 2:Non-Clustered-Indizes):
- m2_tblSample1
- Nicht geclusterter Index für die Spalte „id“ – Primärschlüssel (PK)
- m2_tblSample2
- Nicht gruppierter Index für die Spalte „id“ (PK)
- Nicht gruppierter Index in der Spalte „countryCode“
- m2_tblSample3
- Nicht gruppierter Index für die Spalte „id“ (PK)
- Nicht gruppierter Index für die Spalte „regDate“
- Nicht gruppierter Index in der Spalte „countryCode“
- m2_tblSample1
- m1_tblSample1
In den folgenden Auflistungen finden Sie die Definitionen für die obigen Tabellen.
Die Szenariologik besteht darin, dass wir verschiedene Datenbankoperationen für Variationen derselben Tabelle (aber mit unterschiedlichen Indizes) ausführen und beobachten, wie die Leistung in jedem Fall beeinträchtigt wird.
Definitionen
Festplattenbasierte Tabellen
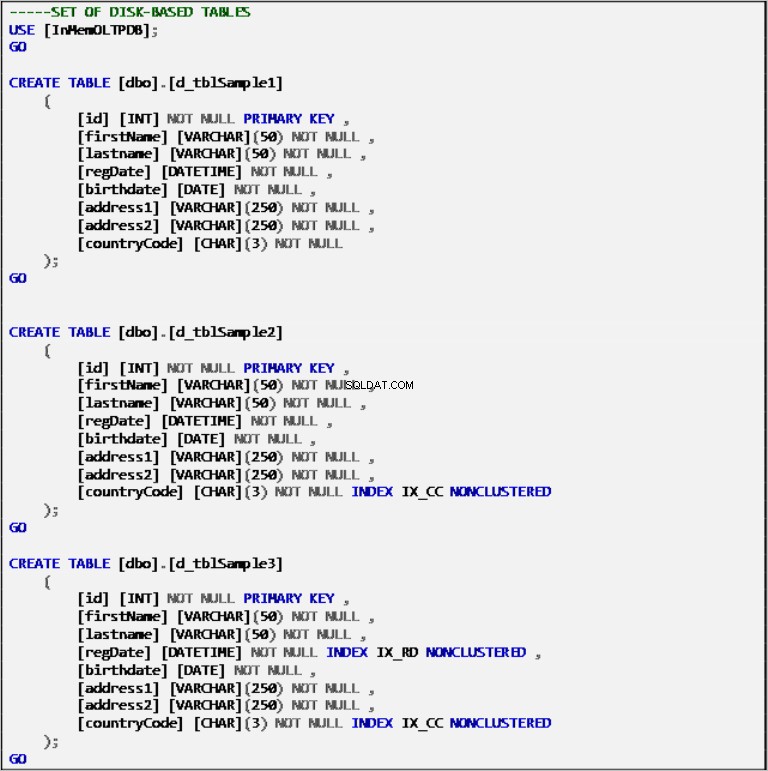
Listing 2:Disk-Based Tables Definition.
Speicheroptimierte Tabellen (Set 1:Hash-Indizes)

Listing 3:Speicheroptimierte Tabellen – Set 1 (Hash-Indizes).
Speicheroptimierte Tabellen (Set 2:Non-Clustered Indexes)

Listing 4:Speicheroptimierte Tabellen – Set 2 (Non-Clustered Indexes).
Dann füllen wir alle obigen Tabellen mit denselben Beispieldaten, was insgesamt 5 Millionen Datensätzen in jeder Tabelle entspricht.
Hier ist die Ausgabe des count-Befehls für jeden Tabellensatz:
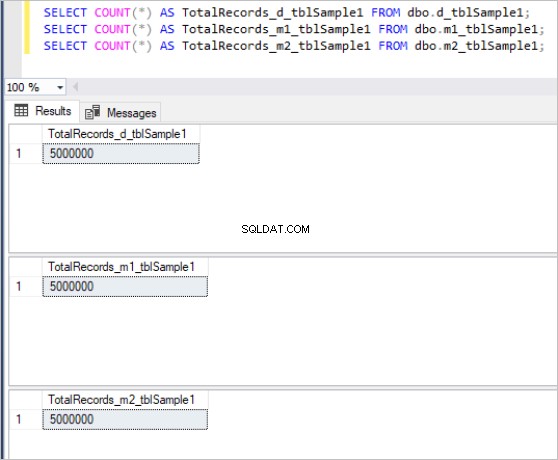
Abbildung 1:Gesamtzahl der Datensätze für den ersten Tabellensatz.
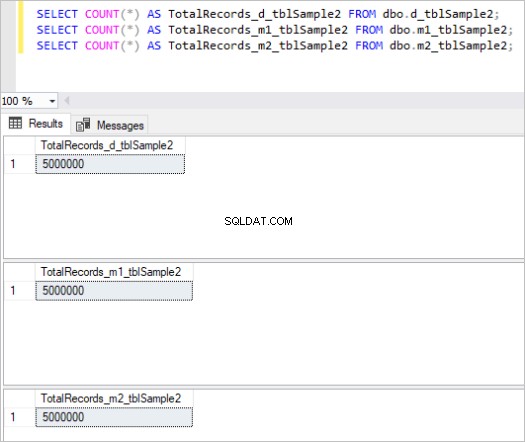
Abbildung 2:Gesamtzahl der Datensätze für den zweiten Tabellensatz.
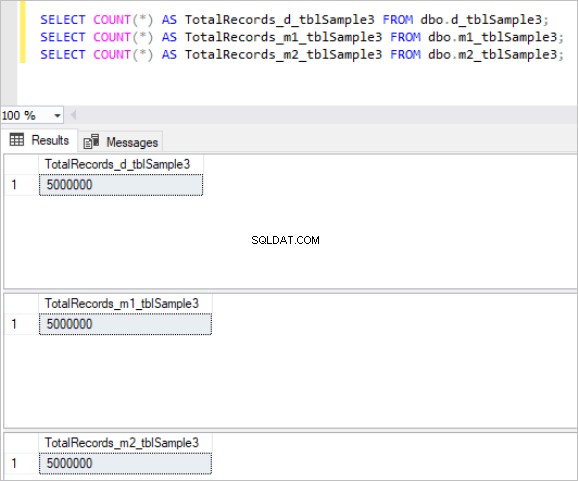
Abbildung 3:Gesamtzahl der Datensätze für den dritten Tabellensatz.
Abfragen und Szenarioausführungen
Jetzt werden wir eine Reihe von Abfragen für die obigen Tabellen ausführen und sehen, wie jede Tabelle abschneidet.
Diese Abfragen führen die folgenden Operationen aus:
- Abfrage 1:Aggregation (GROUP BY)
- Abfrage 2:Indexsuche nach Gleichheitsprädikaten
- Abfrage 3:Indexsuche nach Gleichheits- und Ungleichheitsprädikaten
Der Plan ist, die Abfragen wie folgt auszuführen:
Abfrage 1 – Ausführung gegen die folgenden Tabellen:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (kein Index für Zielspalten)
- m2_tblSample1 (kein Index für Zielspalten)
Abfrage 2 – Ausführung gegen die folgenden Tabellen:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (kein Index für Zielspalten)
- m2_tblSample1 (kein Index für Zielspalten)
Abfrage 3 – Ausführung gegen die folgenden Tabellen:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (kein Index für Zielspalten)
- m2_tblSample1 (kein Index für Zielspalten)
Hinweis :Obwohl die Definition für d_tblSample1 Da die datenträgerbasierte Tabelle in den obigen Tabellendefinitionen enthalten ist, wird sie in den in diesem Artikel bereitgestellten Abfragen nicht verwendet. Der Grund dafür ist, dass in jedem Szenario die bestmögliche Konfiguration für die datenträgerbasierte Tabelle verwendet wird, da wir möchten, dass unsere Baseline so schnell wie möglich ist, wenn wir sie mit der Leistung von speicheroptimierten Tabellen vergleichen. Dazu die d_tblSample1 Tabelle dient nur zu Informationszwecken.
Nachfolgend finden Sie die T-SQL-Skripte für die drei Abfragen zusammen mit den Mechanismen zur Messung der Ausführungszeit.

Listing 5:Abfrage 1 – Aggregation (mit Indizes).
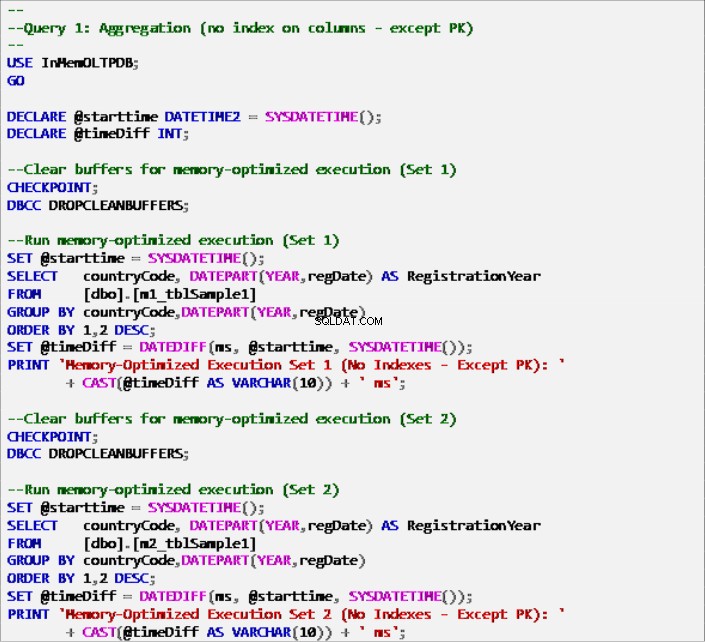
Listing 6:Abfrage 1 – Aggregation (ohne Indizes – außer Primärschlüssel).
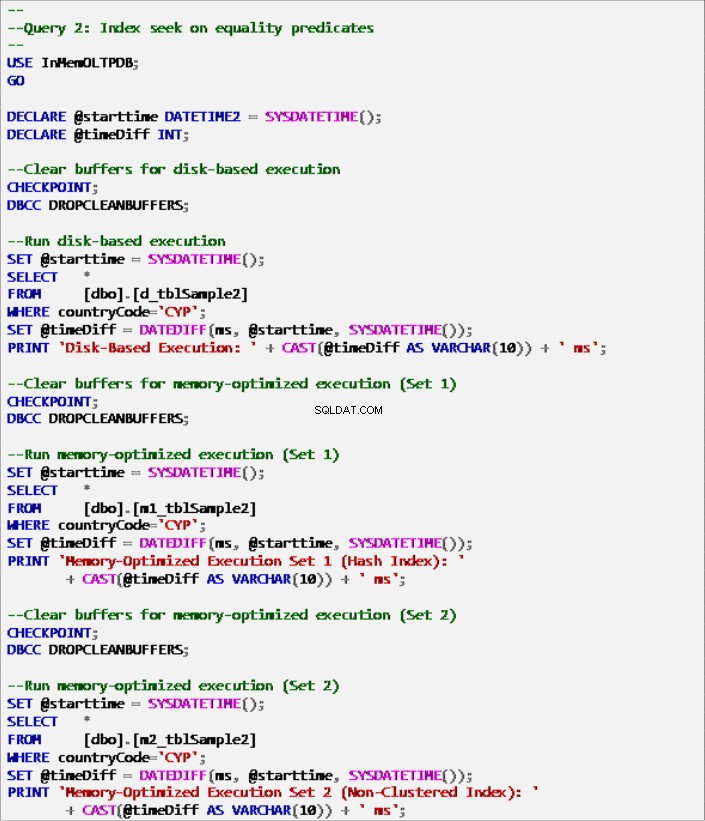
Listing 7:Abfrage 2 – Indexsuche nach Gleichheitsprädikaten (mit Indizes).

Listing 8:Abfrage 2 – Indexsuche nach Gleichheitsprädikaten (ohne Indizes – außer Primärschlüssel).
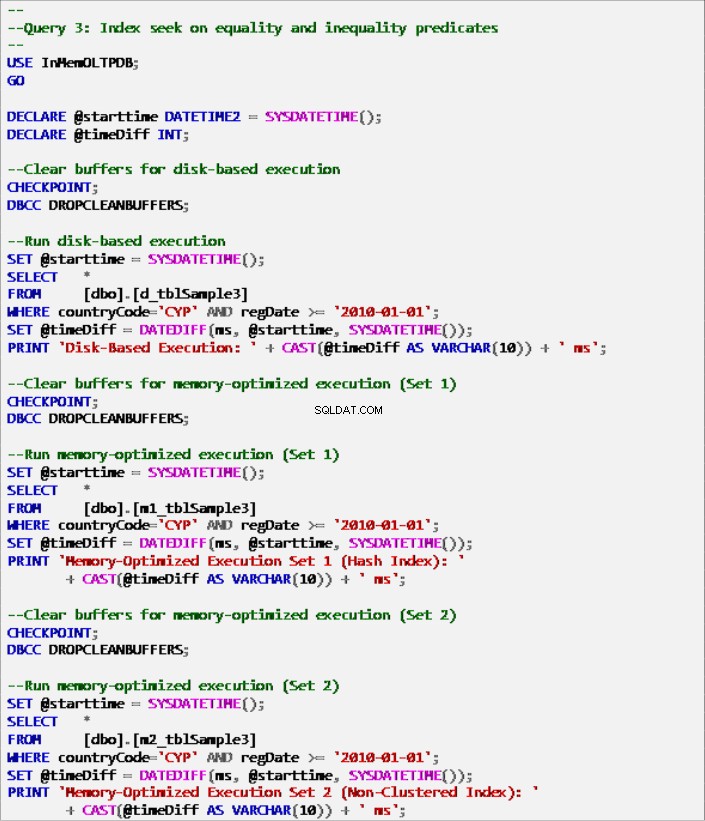
Listing 9:Abfrage 3 – Indexsuche nach Gleichheits- und Ungleichheitsprädikaten (mit Indizes).

Listing 10:Abfrage 3 – Indexsuche nach Gleichheits- und Ungleichheitsprädikaten (ohne Indizes – außer Primärschlüssel).
Die folgenden Screenshots zeigen die Ausgabe jeder Abfrageausführung:
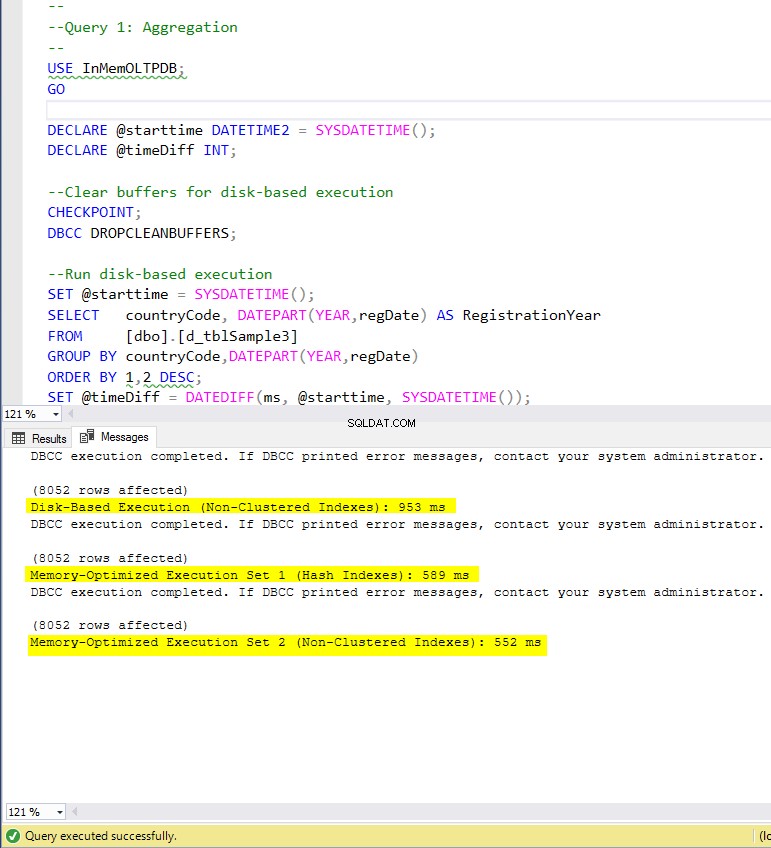
Abbildung 4:Ausführungszeit von Abfrage 1 (mit Indizes).
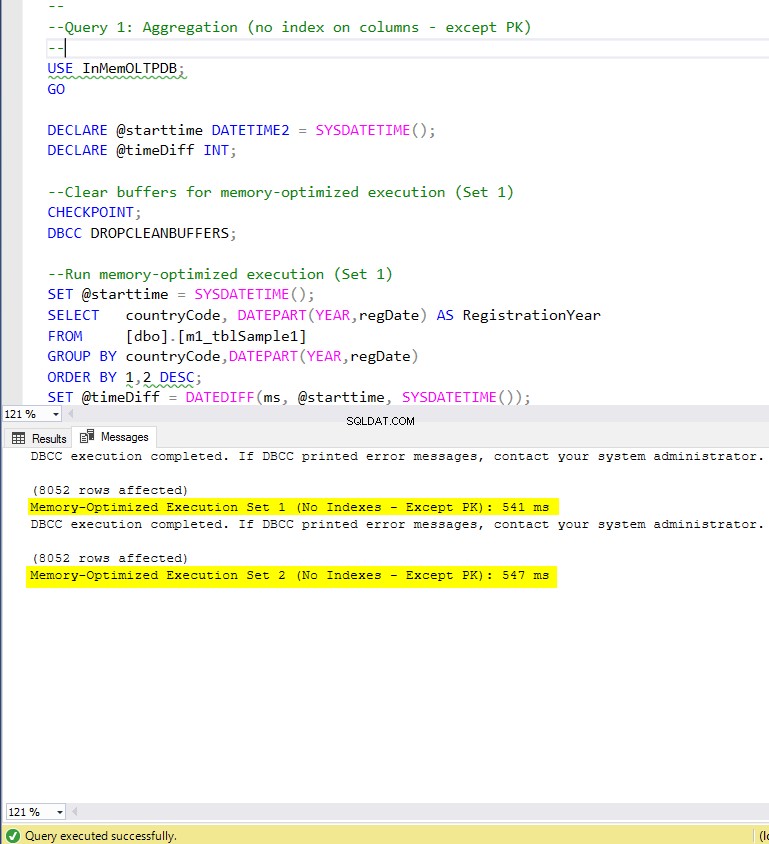
Abbildung 5:Ausführungszeit von Abfrage 1 (ohne Indizes – außer PK).
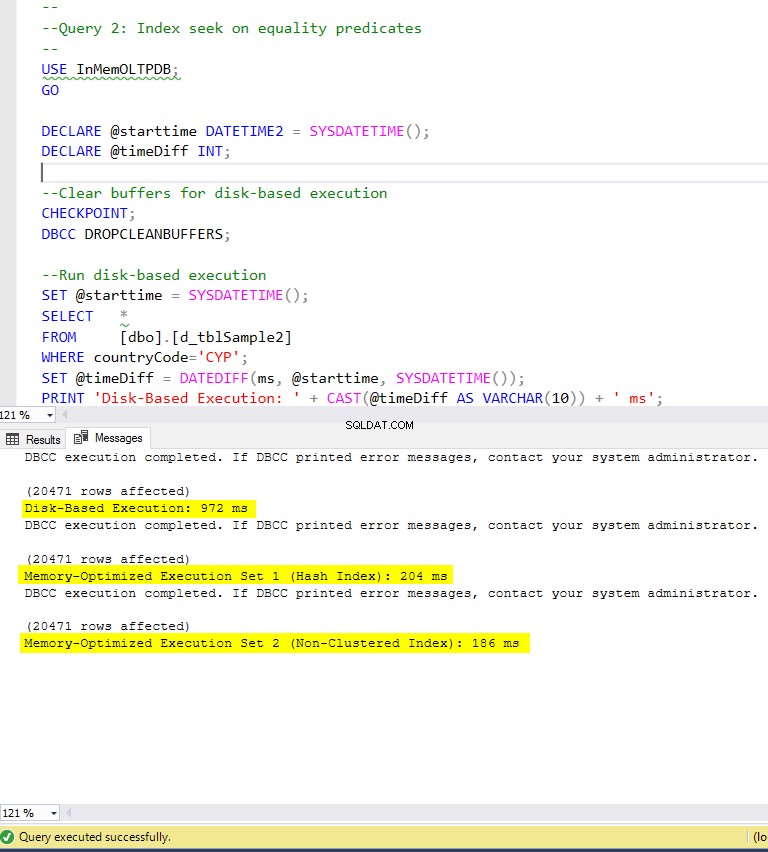
Abbildung 6:Ausführungszeit von Abfrage 2 (mit Indizes).
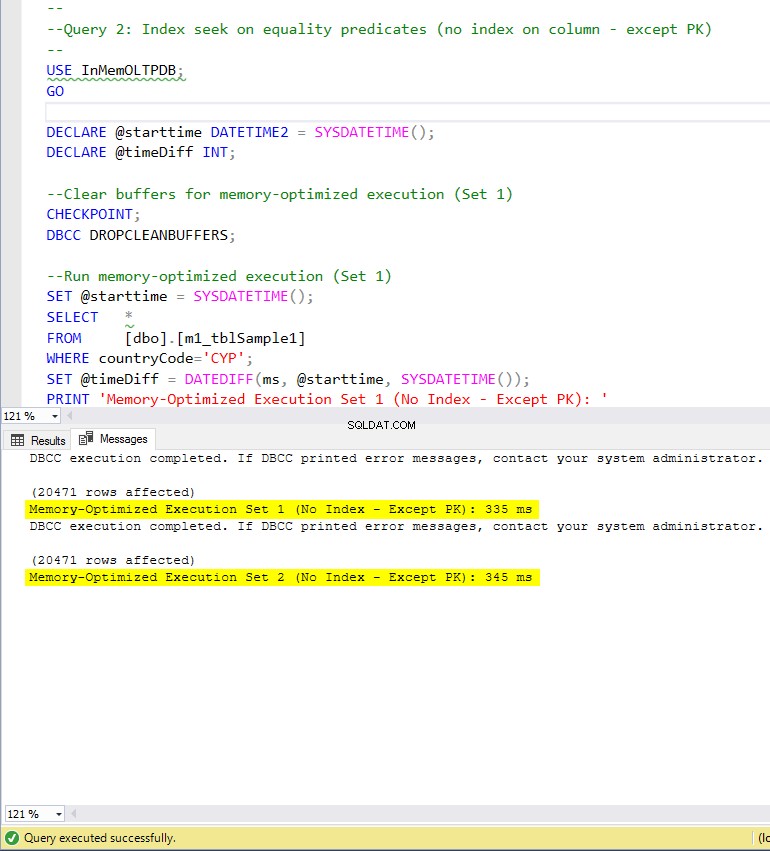
Abbildung 7:Ausführungszeit von Abfrage 2 (ohne Indizes – außer PK).
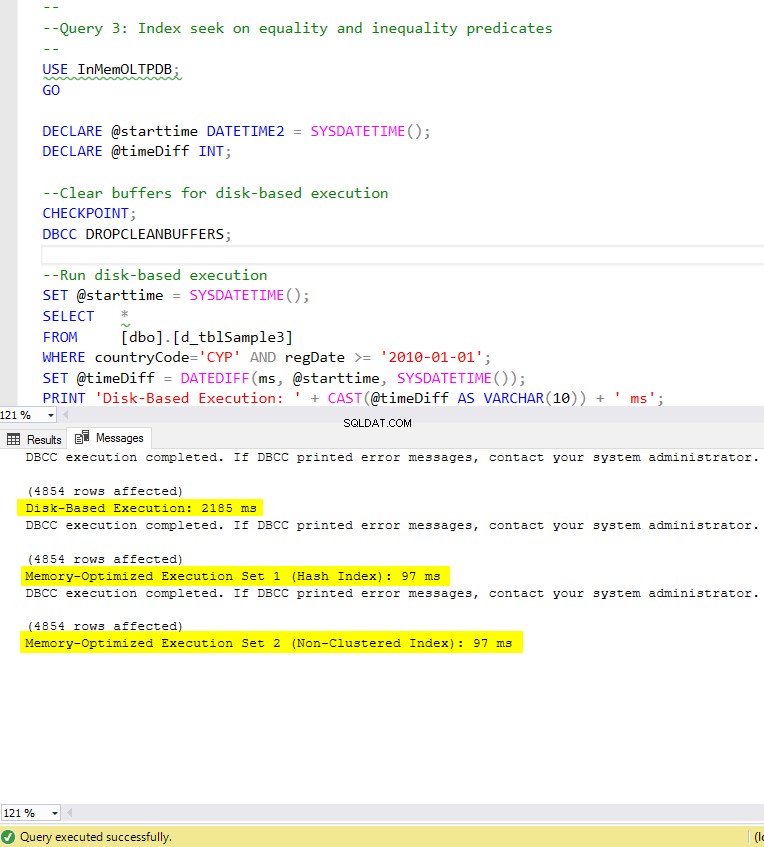
Abbildung 8:Ausführungszeit von Abfrage 3 (mit Indizes).
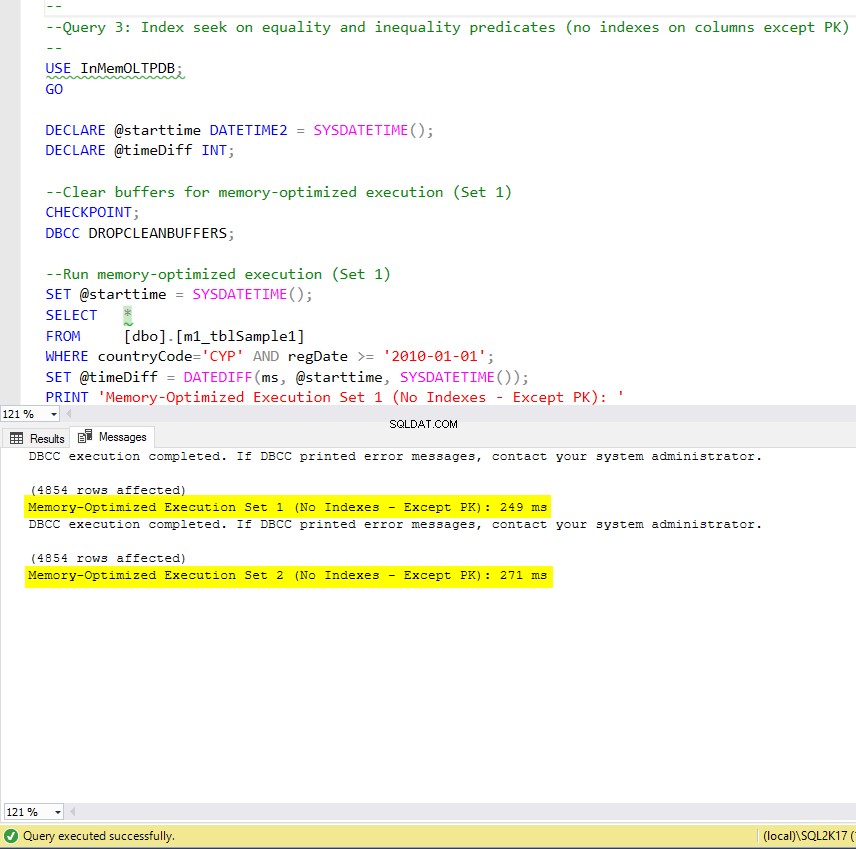
Abbildung 9:Ausführungszeit von Abfrage 3 (ohne Indizes – außer PK).
Lassen Sie uns nun die oben erhaltenen Ergebnisse zusammenfassen. Die folgende Tabelle zeigt die gemessenen Ausführungszeiten für alle oben genannten Abfragen und Tabellen/Index-Kombinationen.
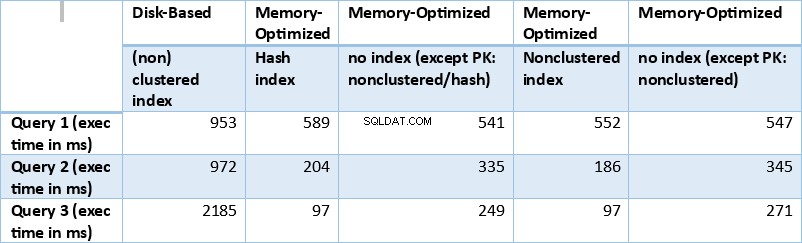
Tabelle 1:Zusammenfassung der Ausführungszeiten (ms) für alle Abfragen.
Diskussion
Wenn wir die in der obigen Tabelle zusammengefassten Ausführungsergebnisse untersuchen, können wir bestimmte Schlussfolgerungen ziehen. Lassen Sie uns jedes Abfrageergebnis in einem Diagramm darstellen. Die folgenden Diagramme veranschaulichen die Ausführungszeiten sowie die Beschleunigung der speicheroptimierten Tabellen gegenüber den festplattenbasierten Tabellen.
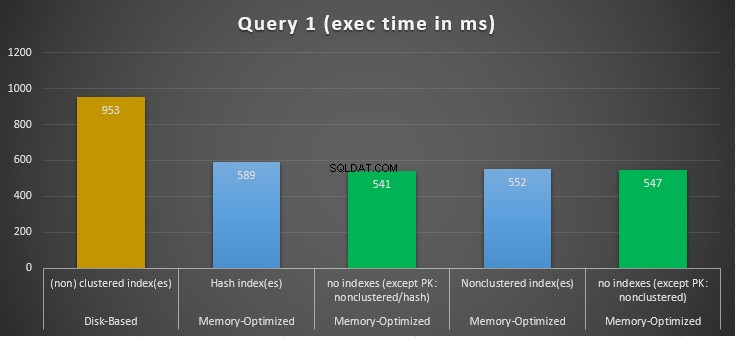
Abbildung 10:Vergleich der Ausführungszeiten von Abfrage 1.
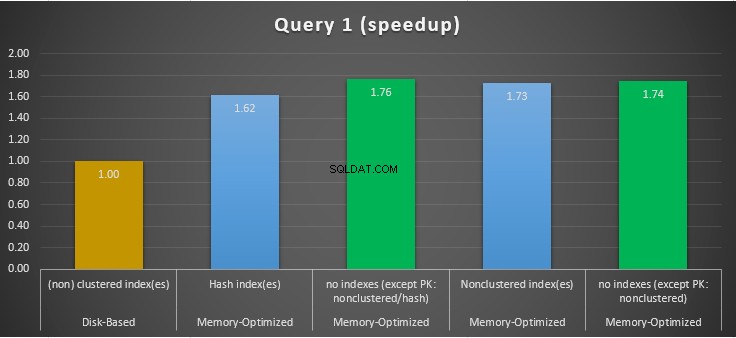
Abbildung 11:Beschleunigungsvergleich in Abfrage 1.
In Bezug auf Abfrage 1, bei der es sich um eine GROUP BY-Aggregation handelte, können wir sehen, dass beide Versionen (Indizes im Vergleich zu keinen Indizes) von speicheroptimierten Tabellen fast die gleiche Leistung erbringen, mit einer Beschleunigung gegenüber der datenträgerbasierten Tabelle (mit aktivierten Indizes) zwischen 1,62- und 1,76-mal schneller.
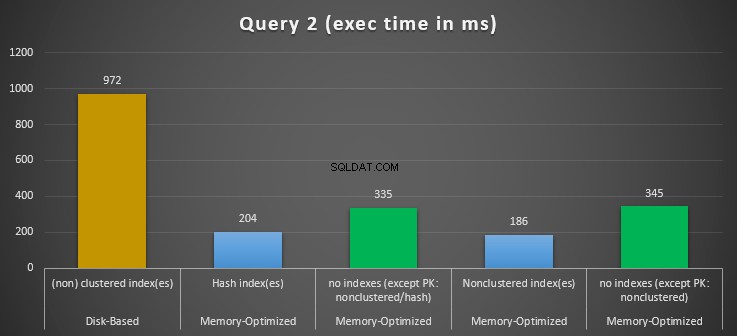
Abbildung 12:Vergleich der Ausführungszeiten von Abfrage 2.
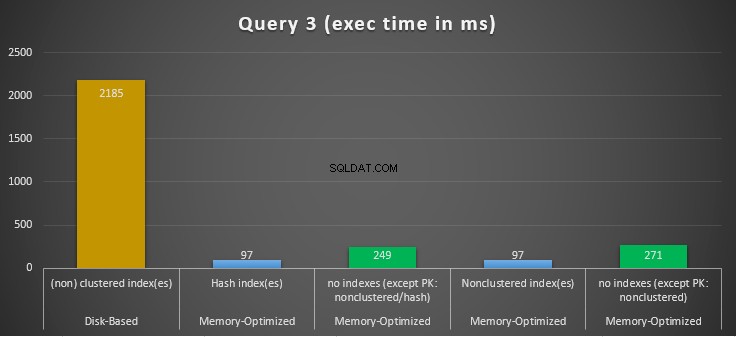
Abbildung 13:Beschleunigungsvergleich in Abfrage 2.
In Bezug auf Abfrage 2, die eine Indexsuche nach Gleichheitsprädikaten beinhaltete, können wir sehen, dass die speicheroptimierten Tabellen mit Indizes eine viel bessere Leistung erbrachten als die speicheroptimierten Tabellen ohne Indizes. Darüber hinaus beobachten wir, dass die speicheroptimierte Tabelle mit Non-Clustered-Index in der Spalte, die als Prädikat verwendet wird, besser abschneidet als die mit dem Hash-Index.
Bei Abfrage 2 gewinnt also die speicheroptimierte Tabelle mit dem nicht geclusterten Index mit einer Gesamtgeschwindigkeit von 5,23 Mal schneller als die festplattenbasierte Ausführung.
Abbildung 14:Vergleich der Ausführungszeiten von Abfrage 3.
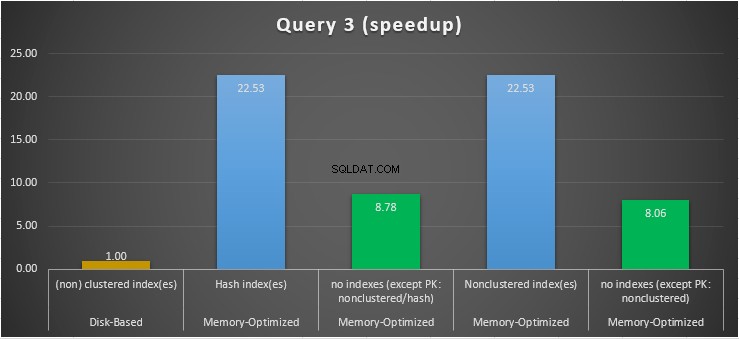
Abbildung 15:Beschleunigungsvergleich in Abfrage 3.
In Bezug auf Abfrage 3, die eine Indexsuche für Gleichheits- und Ungleichheitsprädikate kombiniert beinhaltete, können wir sehen, dass die speicheroptimierten Tabellen mit Indizes eine viel bessere Leistung erbrachten als die speicheroptimierten Tabellen ohne Indizes. Darüber hinaus beobachten wir, dass die speicheroptimierte Tabelle mit dem nicht gruppierten Index in der als Prädikat verwendeten Spalte die gleiche Leistung wie die mit dem Hash-Index erbringt.
Zu diesem Zweck können wir sehen, dass beide speicheroptimierten Tabellen, die Indizes in den als Prädikate verwendeten Spalten verwenden, eine schnellere Leistung erbringen als die ohne Indizes und eine 22,53-mal schnellere Beschleunigung erreichten über festplattenbasierte Ausführung.
Schlussfolgerung
In diesem Artikel haben wir die Verwendung von Indizes in speicheroptimierten Tabellen in SQL Server untersucht. Wir haben als Grundlage für jede Abfrage die bestmögliche datenträgerbasierte Tabellenkonfiguration verwendet und dann die Leistung von drei Abfragen mit den datenträgerbasierten Tabellen und 4 Variationen von speicheroptimierten Tabellen verglichen. Zwei von vier speicheroptimierten Tabellen verwendeten Indizes (Hash/non-clustered) und die anderen zwei verwendeten keine Indizes, außer denen, die für die Primärschlüssel verwendet wurden.
Die allgemeine Schlussfolgerung lautet, dass Sie immer untersuchen müssen, wie sich Indizes auf die Leistung auswirken, nicht nur für speicheroptimierte Tabellen, sondern auch für datenträgerbasierte Tabellen, und wann immer Sie feststellen, dass sie die Leistung verbessern, sollten Sie sie verwenden. Die Ergebnisse der Beispiele dieses Artikels zeigen, dass Sie, wenn Sie die richtigen Indizes in speicheroptimierten Tabellen verwenden, eine viel bessere Leistung für Abfragen erzielen können, die den in diesem Artikel verwendeten ähneln, als wenn Sie nur speicheroptimierte Tabellen ohne Indizes verwenden .
Referenzen und weiterführende Literatur:
- Microsoft Docs:Speicheroptimierte Tabellen
- Microsoft Docs:Richtlinien für die Verwendung von Indizes für speicheroptimierte Tabellen
- Microsoft Docs:Indizes für speicheroptimierte Tabellen
Nützliches Tool:
dbForge Index Manager – praktisches SSMS-Add-in zum Analysieren des Status von SQL-Indizes und Beheben von Problemen mit der Indexfragmentierung.