Ich habe kürzlich einen Beitrag über DISTINCT und GROUP BY geschrieben. Es war ein Vergleich, der zeigte, dass GROUP BY im Allgemeinen eine bessere Option ist als DISTINCT. Es befindet sich auf einer anderen Website, aber kehren Sie gleich danach zu sqlperformance.com zurück.
Einer der Abfragevergleiche, die ich in diesem Beitrag gezeigt habe, war zwischen einer GROUP BY und DISTINCT für eine Unterabfrage, was zeigt, dass die DISTINCT viel langsamer ist, weil sie stattdessen den Produktnamen für jede Zeile in der Sales-Tabelle abrufen muss als nur für jede andere ProductID. Dies wird aus den Abfrageplänen deutlich, in denen Sie sehen können, dass das Aggregat in der ersten Abfrage mit Daten aus nur einer Tabelle arbeitet und nicht mit den Ergebnissen des Joins. Oh, und beide Abfragen geben die gleichen 266 Zeilen zurück.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

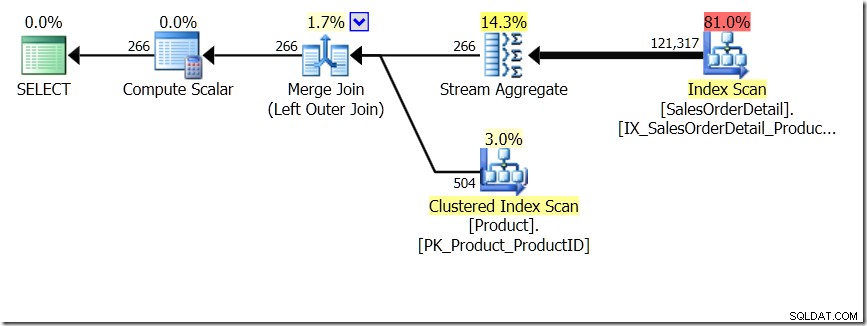
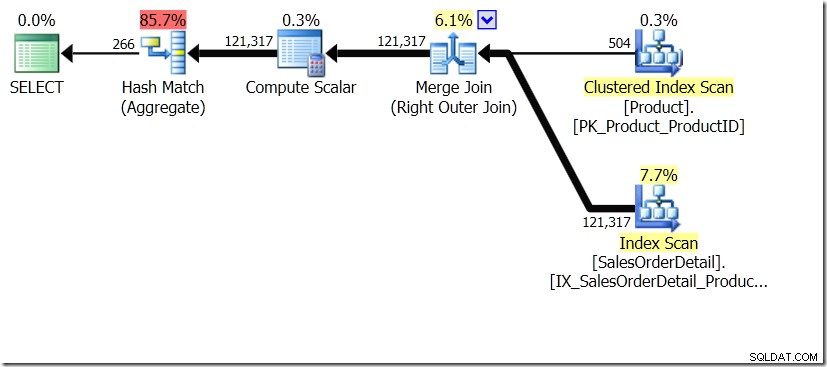
Nun wurde darauf hingewiesen, unter anderem von Adam Machanic (@adammachanic) in einem Tweet, der sich auf Aarons Post über GROUP BY v DISTINCT bezog, dass die beiden Abfragen im Wesentlichen unterschiedlich sind, dass man tatsächlich nach der Menge unterschiedlicher Kombinationen auf den Ergebnissen von fragt Unterabfrage, anstatt die Unterabfrage über die unterschiedlichen übergebenen Werte auszuführen. Das sehen wir im Plan und ist der Grund, warum die Leistung so unterschiedlich ist.
Die Sache ist die, dass wir alle davon ausgehen würden, dass die Ergebnisse identisch sein werden.
Aber das ist eine Annahme und keine gute.
Ich werde mir für einen Moment vorstellen, dass der Abfrageoptimierer einen anderen Plan entwickelt hat. Ich habe dafür Hinweise verwendet, aber wie Sie wissen, kann der Abfrageoptimierer aus allen möglichen Gründen Pläne in allen möglichen Formen erstellen.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
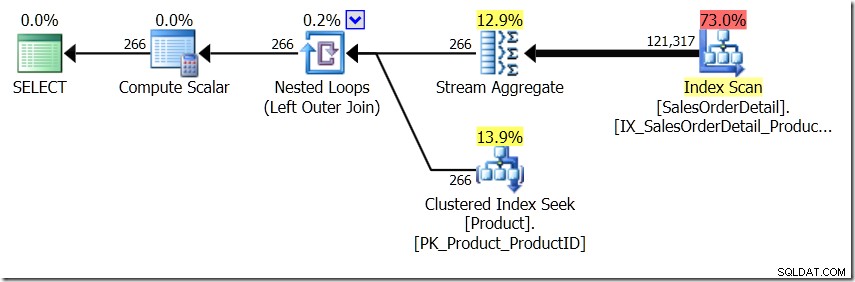
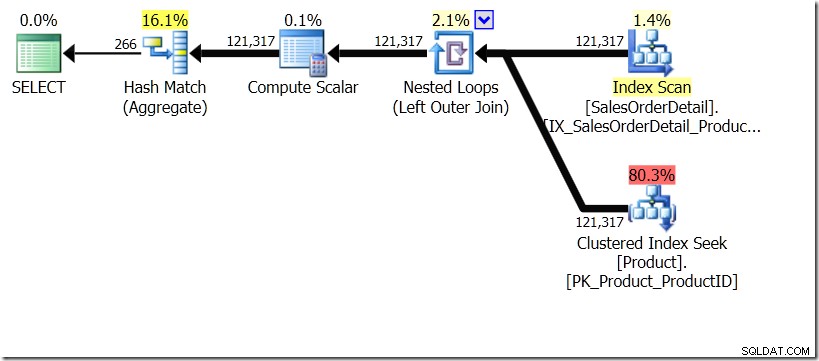
In dieser Situation führen wir entweder 266 Suchvorgänge in der Produkttabelle durch, einen für jede unterschiedliche Produkt-ID, an der wir interessiert sind, oder 121.317 Suchvorgänge. Wenn wir also an eine bestimmte ProductID denken, wissen wir, dass wir von der ersten einen einzigen Namen zurückbekommen werden. Und wir gehen davon aus, dass wir für diese ProductID einen einzigen Namen zurückbekommen, auch wenn wir hundertmal danach fragen müssen. Wir gehen einfach davon aus, dass wir dieselben Ergebnisse zurückerhalten werden.
Aber was, wenn wir es nicht tun?
Das hört sich nach einer Isolationsstufe an, also verwenden wir NOLOCK, wenn wir auf die Product-Tabelle stoßen. Und lassen Sie uns (in einem anderen Fenster) ein Skript ausführen, das den Text in den Namensspalten ändert. Ich werde es immer wieder tun, um zu versuchen, einige der Änderungen zwischen meinen Abfragen zu erhalten.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Jetzt sind meine Ergebnisse anders. Die Pläne sind die gleichen (mit Ausnahme der Anzahl der Zeilen, die aus dem Hash-Aggregat in der zweiten Abfrage kommen), aber meine Ergebnisse sind unterschiedlich.
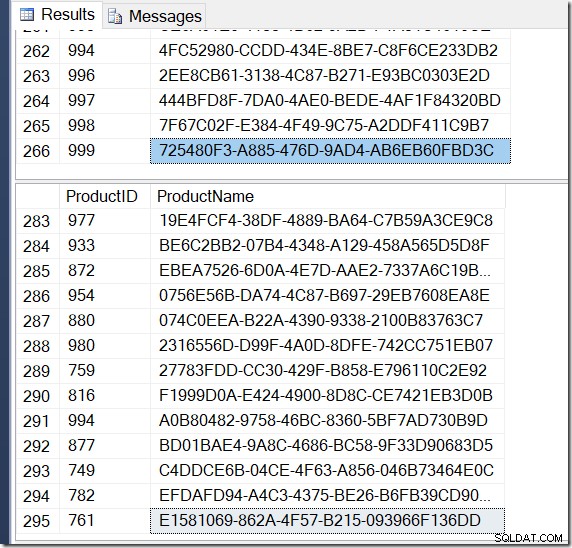
Sicher genug, ich habe mehr Zeilen mit DISTINCT, weil es unterschiedliche Name-Werte für dieselbe ProductID findet. Und ich habe nicht unbedingt 295 Zeilen. Wenn ich es noch einmal ausführe, bekomme ich vielleicht 273 oder 300 oder möglicherweise 121.317.
Es ist nicht schwer, ein Beispiel für eine ProductID zu finden, die mehrere Name-Werte zeigt und bestätigt, was vor sich geht.

Um sicherzustellen, dass wir diese Zeilen nicht in den Ergebnissen sehen, müssten wir natürlich entweder NICHT DISTINCT verwenden oder eine strengere Isolationsstufe verwenden.
Die Sache ist die, obwohl ich die Verwendung von NOLOCK für dieses Beispiel erwähnt habe, musste ich das nicht. Diese Situation tritt auch bei READ COMMITTED auf, was auf vielen SQL Server-Systemen die Standardisolationsstufe ist.
Sie sehen, wir brauchen die Isolationsstufe REPEATABLE READ, um diese Situation zu vermeiden, um die Sperren für jede Zeile zu halten, sobald sie gelesen wurde. Andernfalls könnte ein separater Thread die Daten ändern, wie wir gesehen haben.
Aber… ich kann Ihnen nicht zeigen, dass die Ergebnisse fest sind, weil ich es nicht geschafft habe, einen Deadlock bei der Abfrage zu vermeiden.
Ändern wir also die Bedingungen, indem wir sicherstellen, dass unsere andere Abfrage weniger problematisch ist. Anstatt die gesamte Tabelle auf einmal zu aktualisieren (was in der realen Welt ohnehin viel unwahrscheinlicher ist), aktualisieren wir einfach jeweils eine einzelne Zeile.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Jetzt können wir das Problem immer noch unter einer geringeren Isolationsstufe wie READ COMMITTED oder READ UNCOMMITTED demonstrieren (obwohl Sie die Abfrage möglicherweise mehrmals ausführen müssen, wenn Sie beim ersten Mal 266 erhalten, da die Wahrscheinlichkeit, dass eine Zeile während der Abfrage aktualisiert wird ist weniger), und jetzt können wir zeigen, dass REPEATABLE READ es behebt (egal wie oft wir die Abfrage ausführen).
REPEATABLE READ hält, was es verspricht. Sobald Sie eine Zeile innerhalb einer Transaktion gelesen haben, wird sie gesperrt, um sicherzustellen, dass Sie den Lesevorgang wiederholen und dieselben Ergebnisse erhalten. Die niedrigeren Isolationsstufen entfernen diese Sperren erst, wenn Sie versuchen, die Daten zu ändern. Wenn Ihr Abfrageplan niemals einen Lesevorgang wiederholen muss (wie es bei der Form unserer GROUP BY-Pläne der Fall ist), benötigen Sie REPEATABLE READ nicht.
Wir sollten wohl immer die höheren Isolationsstufen wie REPEATABLE READ oder SERIALIZABLE verwenden, aber es kommt darauf an, herauszufinden, was unsere Systeme brauchen. Diese Ebenen können zu unerwünschten Sperren führen, und SNAPSHOT-Isolationsebenen erfordern eine Versionierung, die ebenfalls mit einem Preis verbunden ist. Für mich ist es ein Kompromiss, denke ich. Wenn ich nach einer Abfrage frage, die von sich ändernden Daten betroffen sein könnte, muss ich möglicherweise die Isolationsstufe für eine Weile erhöhen.
Idealerweise aktualisieren Sie Daten, die gerade gelesen wurden und möglicherweise während der Abfrage erneut gelesen werden müssen, einfach nicht, sodass Sie REPEATABLE READ nicht benötigen. Aber es lohnt sich auf jeden Fall zu verstehen, was passieren kann, und zu erkennen, dass dies die Art von Szenario ist, in der DISTINCT und GROUP BY möglicherweise nicht identisch sind.
@rob_farley