Dieser Beitrag ist Teil einer Serie über Zeilenziele. Die anderen Teile findest du hier:
- Teil 1:Festlegen und Identifizieren von Zeilenzielen
- Teil 2:Semi-Joins
- Teil 3:Anti-Joins
Wenden Sie Anti-Join mit einem Top-Operator an
In Apply Anti Join sehen Sie häufig einen inneren Top-Operator (1). Ausführungspläne. Verwenden Sie beispielsweise die AdventureWorks-Datenbank:
SELECT P.ProductID FROM Production.Product AS PWHERE NOT EXISTS ( SELECT 1 FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Der Plan zeigt einen Top (1)-Operator auf der Innenseite des apply (äußere Referenzen) anti join:
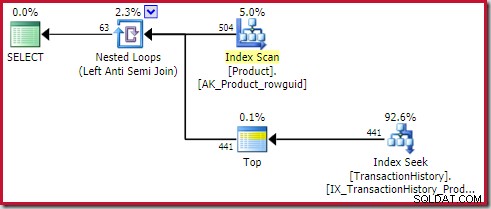
Dieser Top-Operator ist völlig redundant . Es ist nicht erforderlich für Korrektheit, Effizienz oder um sicherzustellen, dass ein Zeilenziel festgelegt wird.
Der Apply-Anti-Join-Operator beendet die Suche nach Zeilen auf der Innenseite (für die aktuelle Iteration), sobald eine Zeile am Join zu sehen ist. Es ist durchaus möglich, einen Anti-Beitrittsplan ohne das Top zu erstellen. Warum also gibt es einen Top-Operator in diesem Plan?
Quelle des Top-Operators
Um zu verstehen, woher dieser sinnlose Top-Operator kommt, müssen wir die wichtigsten Schritte verfolgen, die während der Kompilierung und Optimierung unserer Beispielabfrage unternommen wurden.
Wie üblich wird die Abfrage zuerst in einen Baum geparst. Dieser verfügt über einen logischen „nicht vorhanden“-Operator mit einer Unterabfrage, die in diesem Fall der geschriebenen Form der Abfrage sehr nahe kommt:

Die Unterabfrage nicht vorhanden wird in ein Apply Anti Join:
entrollt

Dies wird dann weiter in einen logischen Links-Anti-Semi-Join umgewandelt. Der resultierende Baum, der an die kostenbasierte Optimierung übergeben wird, sieht folgendermaßen aus:

Die erste Untersuchung, die vom kostenbasierten Optimierer durchgeführt wird, besteht darin, eine logische Unterscheidung einzuführen Operation an der unteren Anti-Join-Eingabe, um eindeutige Werte für den Anti-Join-Schlüssel zu erzeugen. Die allgemeine Idee ist, dass der Plan von der Gruppierung dieser Werte im Voraus profitieren könnte, anstatt doppelte Werte beim Join zu testen.
Die verantwortliche Explorationsregel heißt LASJNtoLASJNonDist (linker Anti-Semi-Join zu linker Anti-Semi-Join auf Distinct). Es wurde noch keine physische Implementierung oder Kostenberechnung durchgeführt, daher untersucht der Optimierer lediglich eine logische Äquivalenz, basierend auf dem Vorhandensein einer doppelten ProductID Werte. Der neue Baum mit der hinzugefügten Gruppierungsoperation ist unten dargestellt:

Die nächste in Betracht gezogene logische Transformation besteht darin, den Join als apply neu zu schreiben . Dies wird mit der Regel LASJNtoApply untersucht (Linker Anti-Semi-Join zur Anwendung bei relationaler Auswahl). Wie bereits in der Serie erwähnt, diente die frühere Transformation von „Apply“ zu „Join“ dazu, Transformationen zu ermöglichen, die speziell für Joins funktionieren. Es ist immer möglich, einen Join als Anwendung umzuschreiben, wodurch die Palette der verfügbaren Optimierungen erweitert wird.
Jetzt tut der Optimierer nicht immer Erwägen Sie eine Umschreibung als Teil der kostenbasierten Optimierung. Es muss etwas im logischen Baum sein, damit es sich lohnt, das Join-Prädikat auf der Innenseite nach unten zu schieben. Typischerweise ist dies die Existenz eines passenden Indexes, aber es gibt auch andere vielversprechende Ziele. In diesem Fall ist es der logische Schlüssel auf ProductID erstellt durch die Aggregatoperation.
Das Ergebnis dieser Regel ist ein korrelierter Anti-Join mit Selektion auf der Innenseite:

Als nächstes erwägt der Optimierer, die relationale Auswahl (das korrelierte Join-Prädikat) weiter nach unten auf der inneren Seite zu verschieben, vorbei an dem zuvor vom Optimierer eingeführten Distinct (Group by Aggregat). Dies geschieht durch die Regel SelOnGbAgg , das so viel wie möglich von einer Auswahl (Prädikat) an einer geeigneten Gruppe vorbei verschiebt (ein Teil der Auswahl kann zurückgelassen werden). Diese Aktivität hilft beim Push-Auswahlverfahren so nah wie möglich an den Datenzugriffsoperatoren auf Blattebene, um Zeilen früher zu eliminieren und den späteren Indexabgleich zu erleichtern.
In diesem Fall befindet sich der Filter in derselben Spalte wie die Gruppierungsoperation, sodass die Transformation gültig ist. Dies führt dazu, dass die gesamte Auswahl unter das Aggregat geschoben wird:

Die letzte interessierende Operation wird von der Regel GbAggToConstScanOrTop ausgeführt . Diese Transformation soll ersetzen eine Gruppierung nach Aggregat mit einem konstanten Scan oder Top logische Operation. Diese Regel passt zu unserem Baum, da die Gruppierungsspalte für jede Zeile, die durch die nach unten verschobene Auswahl geht, konstant ist. Alle Zeilen haben garantiert dieselbe ProductID . Die Gruppierung nach diesem einzelnen Wert erzeugt immer eine Zeile. Daher ist es gültig, das Aggregat in ein Top (1) umzuwandeln. Hier kommt also die Spitze her.
Implementierung und Kosten
Der Optimierer führt nun eine Reihe von Implementierungsregeln aus, um physikalische Operatoren für jede der vielversprechenden logischen Alternativen zu finden, die er bisher in Betracht gezogen hat (effizient in einer Memostruktur gespeichert). Die physischen Anti-Join-Optionen Hash und Merge stammen aus dem ursprünglichen Baum mit eingeführtem Aggregat (mit freundlicher Genehmigung der Regel LASJNtoLASJNonDist). erinnern). Die Anwendung erfordert etwas mehr Arbeit, um ein physisches Top zu erstellen und die Auswahl mit einer Indexsuche abzugleichen.
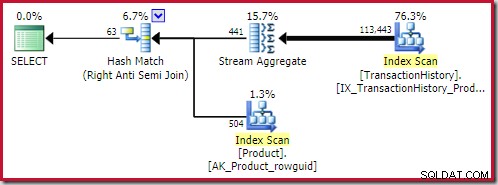
Der beste Hash-Anti-Join Die gefundene Lösung kostet 0,362143 Einheiten:
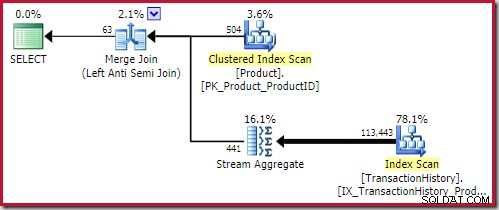
Das beste Merge-Anti-Join Lösung liegt bei 0,353479 Einheiten (etwas billiger):
Anti-Join anwenden kostet 0,091823 Einheiten (mit Abstand am billigsten):
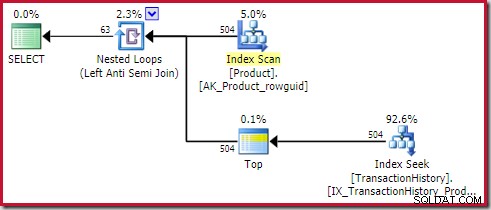
Dem aufmerksamen Leser wird vielleicht auffallen, dass sich die Zeilenanzahl auf der Innenseite von apply anti join (504) vom vorherigen Screenshot desselben Plans unterscheidet. Dies liegt daran, dass es sich um einen geschätzten Plan handelt, während der vorherige Plan nach der Ausführung erfolgte. Wenn dieser Plan ausgeführt wird, werden über alle Iterationen nur insgesamt 441 Zeilen auf der Innenseite gefunden. Dies hebt eine der Anzeigeschwierigkeiten beim Anwenden von Semi-/Anti-Join-Plänen hervor:Die minimale Schätzung des Optimierers ist eine Zeile, aber ein Semi- oder Anti-Join findet bei jeder Iteration immer eine Zeile oder keine Zeilen. Die oben gezeigten 504 Zeilen stellen 1 Zeile in jeder der 504 Iterationen dar. Damit die Zahlen übereinstimmen, müsste die Schätzung jedes Mal 441/504 =0,875 Zeilen betragen, was die Leute wahrscheinlich genauso verwirren würde.
Wie auch immer, der obige Plan ist aus zwei Gründen 'glücklich' genug, um sich für ein Zeilenziel auf der Innenseite des Apply Anti Join zu qualifizieren:
- Der Anti-Join wird im kostenbasierten Optimierer von einem Join in einen Apply umgewandelt. Dies setzt ein Zeilenziel (wie in Teil drei festgelegt).
- Der Top(1)-Operator legt auch ein Zeilenziel für seinen Teilbaum fest.
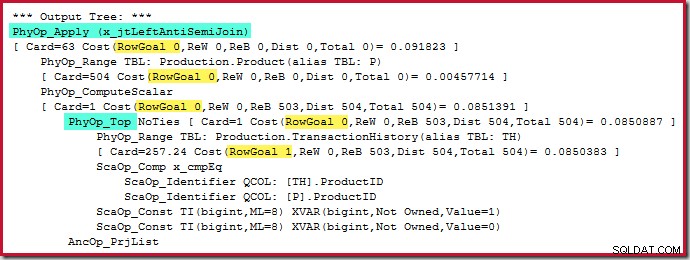
Der Top-Operator selbst hat kein Zeilenziel (von apply), da das Zeilenziel von 1 nicht kleiner sein würde als die reguläre Schätzung, die ebenfalls 1 Zeile ist (Card=1 für die PhyOp_Top unten):
Das Anti-Join-Anti-Pattern
Die folgende allgemeine Planform betrachte ich als Anti-Muster:
Nicht jeder Ausführungsplan, der einen Apply-Anti-Join mit einem Top(1)-Operator auf seiner Innenseite enthält, ist problematisch. Dennoch ist es ein zu erkennendes Muster, das fast immer weiter untersucht werden muss.
Die vier Hauptelemente, auf die Sie achten sollten, sind:
- Eine korrelierte verschachtelte Schleife (apply ) Anti-Beitritt
- Ein Oberteil (1) Bediener sofort auf der Innenseite
- Eine beträchtliche Anzahl von Zeilen auf der äußeren Eingabe (so dass die innere Seite viele Male ausgeführt wird)
- Ein möglicherweise teurer Unterbaum unterhalb von Top
Der Teilbaum "$$$" ist einer, der zur Laufzeit möglicherweise teuer ist . Dies kann schwer zu erkennen sein. Wenn wir Glück haben, gibt es etwas Offensichtliches wie einen vollständigen Tabellen- oder Index-Scan. In schwierigeren Fällen sieht der Teilbaum auf den ersten Blick völlig harmlos aus, enthält aber bei genauerer Betrachtung etwas Kostspieliges. Um ein ziemlich häufiges Beispiel zu nennen:Sie sehen möglicherweise eine Indexsuche, von der erwartet wird, dass sie eine kleine Anzahl von Zeilen zurückgibt, die jedoch ein teures Restprädikat enthält, das eine sehr große Anzahl von Zeilen testet, um die wenigen geeigneten zu finden.
Das vorhergehende AdventureWorks-Codebeispiel hatte keine „potenziell teure“ Unterstruktur. Die Indexsuche (ohne Restprädikat) wäre eine optimale Zugriffsmethode, unabhängig von Zeilenzielüberlegungen. Dies ist ein wichtiger Punkt:Dem Optimierer eine immer-effiziente Funktion zu bieten Datenzugriffspfad auf der Innenseite eines korrelierten Joins ist immer eine gute Idee. Dies gilt umso mehr, wenn die Anwendung im Anti-Join-Modus mit einem Top-Operator (1) auf der Innenseite ausgeführt wird.
Schauen wir uns nun ein Beispiel an, das aufgrund dieses Anti-Patterns eine ziemlich düstere Laufzeitleistung hat.
Beispiel
Das folgende Skript erstellt zwei temporäre Heap-Tabellen. Die erste hat 500 Zeilen, die die ganzen Zahlen von 1 bis einschließlich 500 enthalten. Die zweite Tabelle hat 500 Kopien jeder Zeile in der ersten Tabelle, also insgesamt 250.000 Zeilen. Beide Tabellen verwenden die sql_variant Datentyp.
DOP TABLE WENN VORHANDEN #T1, #T2; CREATE TABLE #T1 (c1 sql_variant NOT NULL);CREATE TABLE #T2 (c1 sql_variant NOT NULL); -- Zahlen 1 bis einschließlich 500 -- Gespeichert als sql_variantINSERT #T1 (c1)SELECT CONVERT(sql_variant, SV.number)FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 UND SV.Nummer <=500; -- 500 Kopien jeder Zeile in Tabelle #T1INSERT #T2 (c1)SELECT T1.c1FROM #T1 AS T1CROSS JOIN #T1 AS T2; -- Stellen Sie sicher, dass wir die bestmöglichen statistischen Informationen habenLeistung
Wir führen jetzt eine Abfrage durch, die nach Zeilen in der kleineren Tabelle sucht, die in der größeren Tabelle nicht vorhanden sind (natürlich gibt es keine):
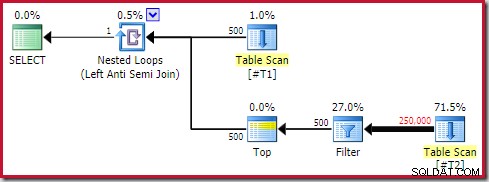
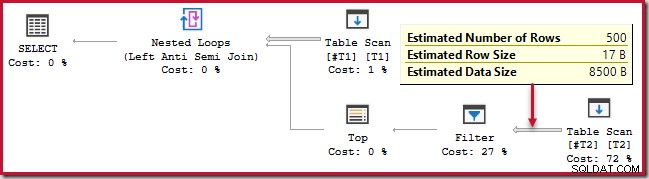
SELECT T1.c1 FROM #T1 AS T1WHERE NOT EXISTS ( SELECT 1 FROM #T2 AS T2 WHERE T2.c1 =T1.c1 );Diese Abfrage wird etwa 20 Sekunden ausgeführt , was eine schrecklich lange Zeit ist, um 500 Zeilen mit 250.000 zu vergleichen. Der geschätzte SSMS-Plan macht es schwer zu erkennen, warum die Leistung so schlecht sein könnte:
Der Beobachter muss sich darüber im Klaren sein, dass geschätzte SSMS-Pläne innere Schätzungen pro Iteration zeigen des Nested-Loop-Joins. Verwirrenderweise zeigen tatsächliche SSMS-Pläne die Anzahl der Zeilen über alle Iterationen . Der Plan-Explorer führt automatisch die einfachen Berechnungen durch, die für geschätzte Pläne erforderlich sind, um auch die erwartete Gesamtzahl der Zeilen anzuzeigen:
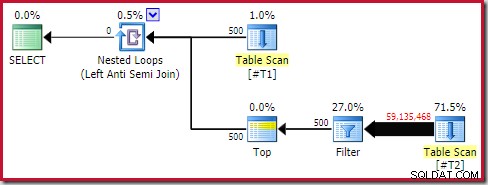
Trotzdem ist die Laufzeitleistung deutlich schlechter als geschätzt. Der (tatsächliche) Ausführungsplan nach der Ausführung lautet:
Beachten Sie den separaten Filter, der normalerweise als Restprädikat in den Scan geschoben würde. Aus diesem Grund wird
sql_variantverwendet Datentyp; Es verhindert das Pushen des Prädikats, wodurch die große Anzahl von Zeilen aus dem Scan leichter zu erkennen ist.Analyse
Der Grund für die Diskrepanz hängt davon ab, wie der Optimierer die Anzahl der Zeilen schätzt, die er aus dem Tabellenscan lesen muss, um das beim Filter festgelegte Ziel von einer Zeile zu erreichen. Die einfache Annahme ist, dass die Werte gleichmäßig in der Tabelle verteilt sind. Um also einen der 500 vorhandenen eindeutigen Werte zu finden, muss SQL Server 250.000 / 500 =500 Zeilen lesen. Über 500 Iterationen, das ergibt 250.000 Zeilen.
Die Einheitlichkeitsannahme des Optimierers ist allgemein, funktioniert hier aber nicht gut. Sie können mehr darüber in A Row Goal Request von Joe Obbish lesen und für seinen Vorschlag im Connect Replacement Feedback Forum unter Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop with TOP stimmen.
Meiner Meinung nach sollte der Optimierer schnell von einer einfachen Einheitlichkeitsannahme zurücktreten, wenn sich der Operator auf der inneren Seite eines Joins mit verschachtelten Schleifen befindet (d. H. Geschätzte Rückläufe plus Neubindungen sind größer als eins). Es ist eine Sache anzunehmen, dass wir 500 Zeilen lesen müssen, um eine Übereinstimmung bei der ersten Iteration der Schleife zu finden. Dies bei jeder Iteration anzunehmen, scheint furchtbar unwahrscheinlich zu sein; Dies bedeutet, dass die ersten 500 gefundenen Zeilen einen von jedem unterschiedlichen Wert enthalten sollten. Dies ist in der Praxis höchst unwahrscheinlich.
Eine Reihe unglücklicher Ereignisse
Unabhängig davon, wie die Kosten für wiederholte Top-Operatoren berechnet werden, scheint mir, dass die ganze Situation von vornherein vermieden werden sollte . Erinnern Sie sich, wie das Top in diesem Plan erstellt wurde:
- Der Optimierer hat ein charakteristisches Aggregat auf der Innenseite als Leistungsoptimierung eingeführt .
- Dieses Aggregat stellt per Definition einen Schlüssel für die Join-Spalte bereit (es erzeugt Eindeutigkeit).
- Dieser konstruierte Schlüssel stellt ein Ziel für die Konvertierung von einem Join zu einem Apply bereit.
- Das Prädikat (Auswahl), das der Anwendung zugeordnet ist, wird nach unten über das Aggregat hinaus verschoben.
- Das Aggregat arbeitet jetzt garantiert mit einem einzigen eindeutigen Wert pro Iteration (da es sich um einen Korrelationswert handelt).
- Das Aggregat wird durch ein Top (1) ersetzt.
Alle diese Transformationen sind einzeln gültig. Sie sind Teil der normalen Optimierungsoperationen, da sie nach einem vernünftigen Ausführungsplan suchen. Leider ist das Ergebnis hier, dass das vom Optimierer eingeführte spekulative Aggregat am Ende in ein Top (1) mit einem zugehörigen Zeilenziel umgewandelt wird . Das Zeilenziel führt zu einer ungenauen Kostenberechnung basierend auf der Einheitlichkeitsannahme und dann zur Auswahl eines Plans, der höchstwahrscheinlich keine gute Leistung erbringen wird.
Nun könnte man einwenden, dass der apply anti join sowieso ein Zeilenziel hätte – ohne die obige Transformationssequenz. Das Gegenargument ist, dass der Optimierer nicht berücksichtigen würde Transformation von Anti-Join zu Anwenden Anti-Join (Festlegen des Zeilenziels), ohne dass das vom Optimierer eingeführte Aggregat LASJNtoApply angibt Regel etwas, an das man sich binden kann. Darüber hinaus haben wir (in Teil drei) gesehen, dass es wieder kein Zeilenziel geben würde, wenn der Anti-Join eine kostenbasierte Optimierung als Anwendung (anstelle eines Joins) eingegeben hätte .
Kurz gesagt, das Zeilenziel im endgültigen Plan ist völlig künstlich und hat keine Grundlage in der ursprünglichen Abfragespezifikation. Das Problem mit dem Top-and-Row-Ziel ist ein Nebeneffekt dieses grundlegenderen Aspekts.
Problemumgehungen
Es gibt viele mögliche Lösungen für dieses Problem. Durch das Entfernen eines der Schritte in der obigen Optimierungssequenz wird sichergestellt, dass der Optimierer keine Anti-Join-Implementierung mit dramatisch (und künstlich) reduzierten Kosten erzeugt. Hoffentlich wird dieses Problem in SQL Server eher früher als später behoben.
In der Zwischenzeit ist mein Rat, auf das Anti-Join-Anti-Muster zu achten. Stellen Sie sicher, dass die Innenseite eines Apply-Anti-Joins immer einen effizienten Zugriffspfad für alle Laufzeitbedingungen hat. Wenn dies nicht möglich ist, müssen Sie möglicherweise Hinweise verwenden, Zeilenziele deaktivieren, eine Planrichtlinie verwenden oder einen Abfragespeicherplan erzwingen, um eine stabile Leistung von Anti-Join-Abfragen zu erhalten.
Serienzusammenfassung
Wir haben in den vier Raten viel Boden abgedeckt, daher hier eine Zusammenfassung auf hohem Niveau:
- Teil 1 – Festlegen und Identifizieren von Zeilenzielen
- Die Abfragesyntax bestimmt nicht das Vorhandensein oder Fehlen eines Zeilenziels.
- Ein Zeilenziel wird nur festgelegt, wenn das Ziel unter der regulären Schätzung liegt.
- Physische Top-Operatoren (einschließlich der vom Optimierer eingeführten) fügen ihrem Unterbaum ein Zeilenziel hinzu.
- Ein
FASToderSET ROWCOUNT-Anweisung legt ein Zeilenziel am Stamm des Plans fest. - Semi-Join und Anti-Join können Zeilenziel hinzufügen.
- SQL Server 2017 CU3 fügt das Showplan-Attribut EstimateRowsWithoutRowGoal hinzu für Operatoren, die von einem Zeilenziel betroffen sind
- Informationen zum Zeilenziel können durch die undokumentierten Trace-Flags 8607 und 8612 offengelegt werden.
- Teil 2 – Semi-Joins
- Es ist nicht möglich, einen Semi-Join direkt in T-SQL auszudrücken, daher verwenden wir indirekte Syntax, z.
IN,EXISTS, oderINTERSECT. - Diese Syntaxen werden in einen Baum geparst, der eine Anwendung (korrelierter Join) enthält.
- Der Optimierer versucht, die Anwendung in einen regulären Join umzuwandeln (nicht immer möglich).
- Hash, Merge und reguläre Halbverknüpfungen mit verschachtelten Schleifen setzen kein Zeilenziel.
- Semi Join anwenden legt immer ein Zeilenziel fest.
- Semi-Join anwenden kann erkannt werden, indem äußere Referenzen auf dem Join-Operator für verschachtelte Schleifen vorhanden sind.
- Semi-Join anwenden verwendet keinen Top-Operator (1) auf der Innenseite.
- Teil 3 – Anti-Joins
- Auch in eine Anwendung geparst, mit einem Versuch, dies als Join umzuschreiben (nicht immer möglich).
- Hash, Merge und Anti-Join für reguläre verschachtelte Schleifen setzen kein Zeilenziel.
- Apply Anti Join legt nicht immer ein Zeilenziel fest.
- Nur Regeln der kostenbasierten Optimierung (CBO), die Anti-Join-Regeln transformieren, um ein Zeilenziel festzulegen.
- Der Anti-Join muss CBO als Join eingeben (nicht zutreffend). Andernfalls kann die Join-to-Apply-Transformation nicht stattfinden.
- Um CBO als Beitritt einzugeben, muss die Vor-CBO-Umschreibung von Bewerbung auf Beitritt erfolgreich gewesen sein.
- CBO erkundet nur in vielversprechenden Fällen das Umschreiben eines Anti-Joins in eine Bewerbung.
- Vor-CBO-Vereinfachungen können mit dem undokumentierten Trace-Flag 8621 angezeigt werden.
- Teil 4 – Anti-Join-Anti-Muster
- Der Optimierer legt nur dann ein Zeilenziel für das Anwenden von Anti-Join fest, wenn es einen vielversprechenden Grund dafür gibt.
- Leider fügen mehrere interagierende Optimierer-Transformationen einen Top-Operator (1) zur Innenseite eines Apply-Anti-Joins hinzu.
- Der Top-Operator ist redundant; es ist für die Korrektheit oder Effizienz nicht erforderlich.
- Der Top setzt immer ein Zeilenziel (anders als der Bewerben, der einen guten Grund braucht).
- Das ungerechtfertigte Zeilenziel kann zu einer extrem schlechten Leistung führen.
- Achten Sie auf einen potenziell teuren Teilbaum unter dem künstlichen Top (1).