Wie jede Programmiersprache hat T-SQL seinen Anteil an häufigen Fehlern und Fallstricken, von denen einige zu falschen Ergebnissen und andere zu Leistungsproblemen führen. In vielen dieser Fälle gibt es Best Practices, die Ihnen helfen können, Probleme zu vermeiden. Ich habe andere MVPs von Microsoft Data Platform befragt und nach den Fehlern und Fallstricken gefragt, die sie häufig sehen oder die sie einfach besonders interessant finden, und nach den Best Practices, die sie anwenden, um diese zu vermeiden. Ich habe viele interessante Fälle.
Vielen Dank an Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser und Chan Ming Man für das Teilen Ihres Wissens und Ihrer Erfahrung!
Dieser Artikel ist der erste einer Reihe zu diesem Thema. Jeder Artikel konzentriert sich auf ein bestimmtes Thema. Diesen Monat konzentriere ich mich auf Fehler, Fallstricke und Best Practices im Zusammenhang mit Determinismus. Eine deterministische Berechnung ist eine Berechnung, die bei gleichen Eingaben garantiert wiederholbare Ergebnisse liefert. Es gibt viele Fehler und Fallstricke, die sich aus der Verwendung nichtdeterministischer Berechnungen ergeben. In diesem Artikel behandle ich die Auswirkungen der Verwendung nicht deterministischer Reihenfolge, nicht deterministischer Funktionen, mehrfacher Verweise auf Tabellenausdrücke mit nicht deterministischen Berechnungen und die Verwendung von CASE-Ausdrücken und der NULLIF-Funktion mit nicht deterministischen Berechnungen.
In vielen Beispielen dieser Serie verwende ich die Beispieldatenbank TSQLV5.
Nichtdeterministische Ordnung
Eine häufige Quelle für Fehler in T-SQL ist die Verwendung einer nicht deterministischen Reihenfolge. Das heißt, wenn Ihre Sortierliste eine Zeile nicht eindeutig identifiziert. Es könnte eine Präsentationsbestellung, eine TOP/OFFSET-FETCH-Bestellung oder eine Fensterbestellung sein.
Nehmen wir zum Beispiel ein klassisches Paging-Szenario mit dem OFFSET-FETCH-Filter. Sie müssen die Tabelle Sales.Orders abfragen und jeweils eine Seite mit 10 Zeilen zurückgeben, sortiert nach Bestelldatum, absteigend (neueste zuerst). Der Einfachheit halber verwende ich Konstanten für die offset- und fetch-Elemente, aber normalerweise handelt es sich dabei um Ausdrücke, die auf Eingabeparametern basieren.
Die folgende Abfrage (nennen Sie sie Abfrage 1) gibt die erste Seite der 10 neuesten Bestellungen zurück:
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Der Plan für Abfrage 1 ist in Abbildung 1 dargestellt.
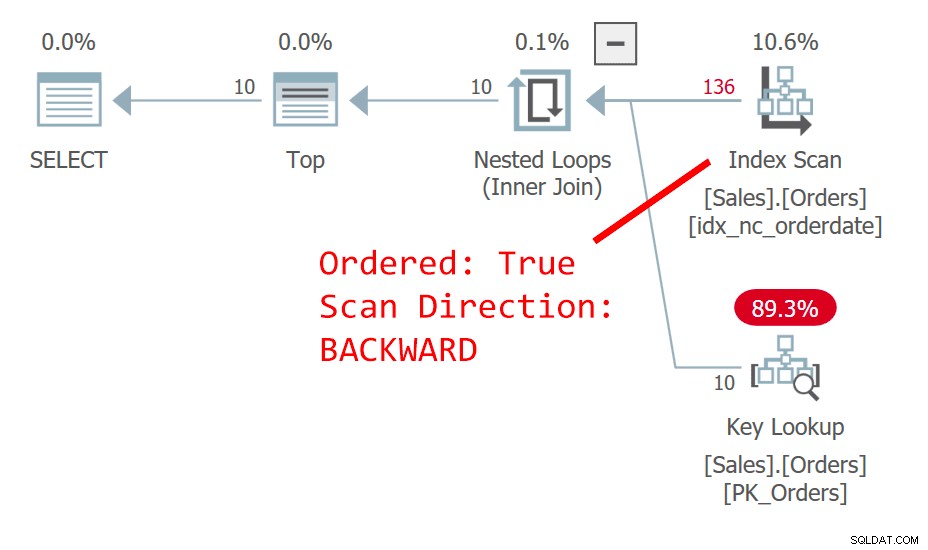 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Die Abfrage ordnet die Zeilen absteigend nach Bestelldatum. Die Orderdate-Spalte identifiziert eine Zeile nicht eindeutig. Diese nicht deterministische Reihenfolge bedeutet, dass es konzeptionell keine Präferenz zwischen den Zeilen mit demselben Datum gibt. Was im Fall von Unentschieden bestimmt, welche Zeile SQL Server bevorzugt, sind Dinge wie Planauswahl und physisches Datenlayout – nichts, auf das Sie sich als wiederholbar verlassen können. Der Plan in Abbildung 1 scannt den Index am Bestelldatum rückwärts sortiert. Es kommt vor, dass diese Tabelle einen gruppierten Index auf orderid hat, und in einer gruppierten Tabelle wird der Schlüssel des gruppierten Index als Zeilenlokator in nicht gruppierten Indizes verwendet. Es wird tatsächlich implizit als letztes Schlüsselelement in allen Nonclustered-Indizes positioniert, obwohl SQL Server es theoretisch als eingeschlossene Spalte in den Index hätte einfügen können. Implizit ist also der nicht gruppierte Index am Bestelldatum tatsächlich am (Bestelldatum, Bestell-ID) definiert. Folglich wird in unserem geordneten Rückwärtsscan des Index zwischen gebundenen Zeilen basierend auf orderdate auf eine Zeile mit einem höheren orderid-Wert vor einer Zeile mit einem niedrigeren orderid-Wert zugegriffen. Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Verwenden Sie als Nächstes die folgende Abfrage (nennen Sie sie Abfrage 2), um die zweite Seite mit 10 Zeilen zu erhalten:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Der Plan für die Abfrage ist in Abbildung 2 dargestellt.
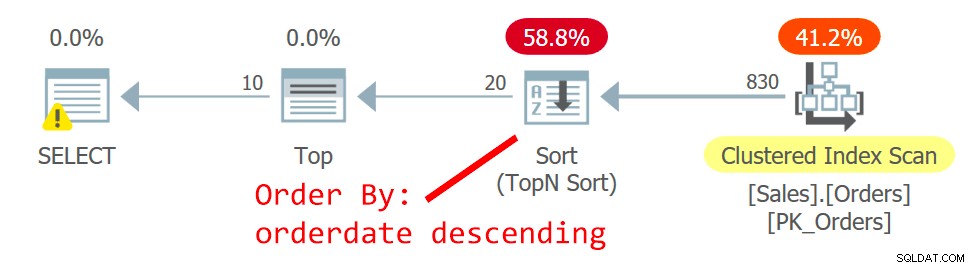
Abbildung 2:Plan für Abfrage 2
Der Optimierer wählt einen anderen Plan – einen, der den geclusterten Index in ungeordneter Weise durchsucht und eine TopN-Sortierung verwendet, um die Anforderung des Top-Operators zu unterstützen, den Offset-Fetch-Filter zu handhaben. Der Grund für die Änderung ist, dass der Plan in Abbildung 1 einen Nonclustered Noncovering-Index verwendet und je weiter die gesuchte Seite entfernt ist, desto mehr Suchen sind erforderlich. Mit der zweiten Seitenanforderung haben Sie den Wendepunkt überschritten, der die Verwendung des nicht deckenden Index rechtfertigt.
Obwohl der Scan des Clustered-Index, der mit orderid als Schlüssel definiert ist, ein unsortierter Scan ist, verwendet die Speicher-Engine intern einen Scan der Indexreihenfolge. Dies hat mit der Größe des Indexes zu tun. Bis zu 64 Seiten bevorzugt die Speicher-Engine im Allgemeinen Scans in Indexreihenfolge gegenüber Scans in Zuordnungsreihenfolge. Selbst wenn der Index größer war, verwendet die Speicher-Engine unter der Read-Committed-Isolationsstufe und Daten, die nicht als schreibgeschützt markiert sind, einen Scan der Indexreihenfolge, um doppeltes Lesen und Überspringen von Zeilen als Ergebnis von Seitenteilungen zu vermeiden, die während der Scan. Unter den gegebenen Bedingungen greift dieser Plan in der Praxis zwischen Zeilen mit demselben Datum auf eine Zeile mit einer niedrigeren Orderid vor einer mit einer höheren Orderid zu.
Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
Beachten Sie, dass Sie, obwohl sich die zugrunde liegenden Daten nicht geändert haben, sowohl auf der ersten als auch auf der zweiten Seite dieselbe Bestellung (mit der Bestell-ID 11069) erhalten haben!
Hoffentlich ist die Best Practice hier klar. Fügen Sie Ihrer Sortierliste einen Tiebreaker hinzu, um eine deterministische Reihenfolge zu erhalten. Zum Beispiel sortiere nach Bestelldatum absteigend, Bestell-ID absteigend.
Versuchen Sie erneut, nach der ersten Seite zu fragen, diesmal mit einer deterministischen Reihenfolge:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Sie erhalten garantiert folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Fragen Sie nach der zweiten Seite:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Sie erhalten garantiert folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
Solange es keine Änderungen in den zugrunde liegenden Daten gab, erhalten Sie garantiert aufeinanderfolgende Seiten ohne Wiederholungen oder Überspringen von Zeilen zwischen den Seiten.
In ähnlicher Weise könnten Sie bei Verwendung von Fensterfunktionen wie ROW_NUMBER mit nicht deterministischer Reihenfolge je nach Planform und tatsächlicher Zugriffsreihenfolge zwischen Bindungen unterschiedliche Ergebnisse für dieselbe Abfrage erhalten. Betrachten Sie die folgende Abfrage (nennen Sie sie Abfrage 3), die die Anforderung der ersten Seite unter Verwendung von Zeilennummern implementiert (wodurch die Verwendung des Index am Bestelldatum zu Illustrationszwecken erzwungen wird):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Der Plan für diese Abfrage ist in Abbildung 3 dargestellt:
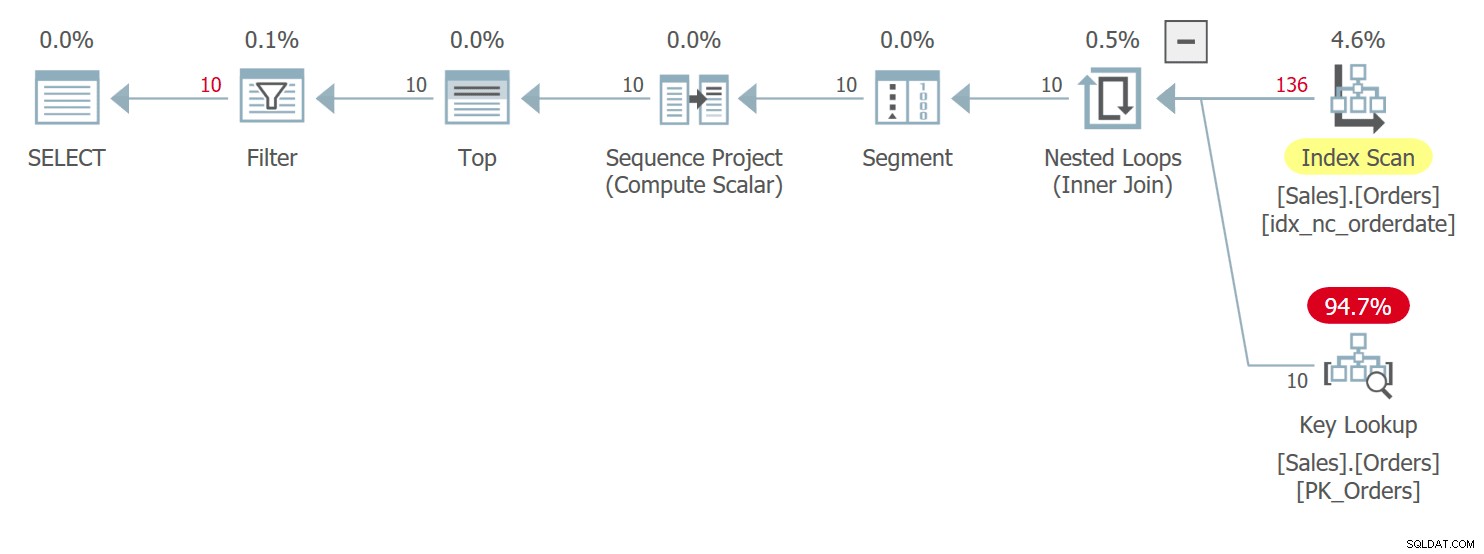
Abbildung 3:Plan für Abfrage 3
Sie haben hier sehr ähnliche Bedingungen wie die, die ich zuvor für Abfrage 1 mit ihrem Plan beschrieben habe, der zuvor in Abbildung 1 gezeigt wurde. Zwischen Zeilen mit Bindungen in den orderdate-Werten greift dieser Plan auf eine Zeile mit einem höheren orderid-Wert vor einer mit einem niedrigeren zu orderid-Wert. Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Führen Sie als Nächstes die Abfrage erneut aus (nennen Sie sie Abfrage 4), und fordern Sie die erste Seite an, nur erzwingen Sie diesmal die Verwendung des Clustered-Index PK_Orders:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Der Plan für diese Abfrage ist in Abbildung 4 dargestellt.

Abbildung 4:Plan für Abfrage 4
Dieses Mal haben Sie sehr ähnliche Bedingungen wie die, die ich zuvor für Abfrage 2 mit ihrem Plan beschrieben habe, der zuvor in Abbildung 2 gezeigt wurde. Zwischen Zeilen mit Bindungen in den orderdate-Werten greift dieser Plan auf eine Zeile mit einem niedrigeren orderid-Wert vor einer mit a zu höherer orderid-Wert. Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
Beachten Sie, dass die beiden Ausführungen zu unterschiedlichen Ergebnissen führten, obwohl sich an den zugrunde liegenden Daten nichts geändert hat.
Auch hier ist die bewährte Vorgehensweise einfach:Verwenden Sie eine deterministische Reihenfolge, indem Sie einen Tiebreaker hinzufügen, etwa so:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Der zurückgegebene Satz ist unabhängig von der Planform garantiert wiederholbar.
Es ist wahrscheinlich erwähnenswert, dass es hier keine garantierte Präsentationsreihenfolge gibt, da diese Abfrage keine Präsentations-Order-by-Klausel in der äußeren Abfrage enthält. Wenn Sie eine solche Garantie benötigen, müssen Sie eine Präsentations-Order-by-Klausel hinzufügen, etwa so:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n; Nichtdeterministische Funktionen
Eine nichtdeterministische Funktion ist eine Funktion, die bei gleichen Eingaben bei unterschiedlichen Ausführungen der Funktion unterschiedliche Ergebnisse zurückgeben kann. Klassische Beispiele sind SYSDATETIME, NEWID und RAND (bei Aufruf ohne Eingabe-Seed). Das Verhalten nichtdeterministischer Funktionen in T-SQL kann für einige überraschend sein und in einigen Fällen zu Fehlern und Fallstricken führen.
Viele Leute gehen davon aus, dass beim Aufrufen einer nicht deterministischen Funktion als Teil einer Abfrage die Funktion separat pro Zeile ausgewertet wird. In der Praxis werden die meisten nichtdeterministischen Funktionen einmal pro Referenz in der Abfrage ausgewertet. Betrachten Sie die folgende Abfrage als Beispiel:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Da es in der Abfrage nur einen Verweis auf jede der nicht deterministischen Funktionen SYSDATETIME und RAND gibt, wird jede dieser Funktionen nur einmal ausgewertet, und ihr Ergebnis wird in allen Ergebniszeilen wiederholt. Beim Ausführen dieser Abfrage habe ich die folgende Ausgabe erhalten:
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
Nehmen Sie beispielsweise an, dass Sie eine Abfrage schreiben müssen, die drei zufällige Bestellungen aus der Tabelle „Sales.Orders“ zurückgibt, wenn dieses Verhalten nicht verstanden wird und zu einem Fehler führen kann. Ein üblicher Anfangsversuch besteht darin, eine TOP-Abfrage mit einer Reihenfolge basierend auf der RAND-Funktion zu verwenden, in der Annahme, dass die Funktion separat pro Zeile ausgewertet wird, etwa so:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
In der Praxis wird die Funktion nur einmal für die gesamte Abfrage ausgewertet; Daher erhalten alle Zeilen das gleiche Ergebnis, und die Reihenfolge bleibt völlig unbeeinflusst. Wenn Sie den Plan für diese Abfrage überprüfen, sehen Sie tatsächlich keinen Sort-Operator. Als ich diese Abfrage mehrmals ausgeführt habe, habe ich immer das gleiche Ergebnis erhalten:
orderid ----------- 11008 11019 11039
Die Abfrage entspricht tatsächlich einer Abfrage ohne ORDER BY-Klausel, bei der die Reihenfolge der Präsentation nicht garantiert ist. Technisch gesehen ist die Reihenfolge also nicht deterministisch, und theoretisch könnten unterschiedliche Ausführungen zu einer anderen Reihenfolge und damit zu einer anderen Auswahl der oberen 3 Reihen führen. Die Wahrscheinlichkeit dafür ist jedoch gering, und Sie können sich diese Lösung nicht so vorstellen, dass sie bei jeder Ausführung drei zufällige Zeilen erzeugt.
Eine Ausnahme von der Regel, dass eine nicht deterministische Funktion einmal pro Verweis in der Abfrage aufgerufen wird, ist die NEWID-Funktion, die einen global eindeutigen Bezeichner (GUID) zurückgibt. Wenn sie in einer Abfrage verwendet wird, ist diese Funktion separat pro Zeile aufgerufen. Die folgende Abfrage demonstriert dies:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
Diese Abfrage generierte die folgende Ausgabe:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
Der Wert von NEWID selbst ist ziemlich zufällig. Wenn Sie die CHECKSUM-Funktion darüber anwenden, erhalten Sie ein ganzzahliges Ergebnis mit einer noch besseren Zufallsverteilung. Eine Möglichkeit, drei zufällige Reihenfolgen zu erhalten, besteht also darin, eine TOP-Abfrage mit einer Reihenfolge basierend auf CHECKSUM(NEWID()) zu verwenden, etwa so:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
Führen Sie diese Abfrage wiederholt aus und beachten Sie, dass Sie jedes Mal einen anderen Satz von drei zufälligen Bestellungen erhalten. Ich habe die folgende Ausgabe in einer Ausführung erhalten:
orderid ----------- 11031 10330 10962
Und die folgende Ausgabe in einer anderen Ausführung:
orderid ----------- 10308 10885 10444
Was ist, außer NEWID, wenn Sie eine nicht deterministische Funktion wie SYSDATETIME in einer Abfrage verwenden müssen und diese separat pro Zeile ausgewertet werden muss? Eine Möglichkeit, dies zu erreichen, besteht darin, eine benutzerdefinierte Funktion (UDF) zu verwenden, die die nicht deterministische Funktion wie folgt aufruft:
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO Anschließend rufen Sie die UDF in der Abfrage wie folgt auf (nennen Sie sie Abfrage 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
Die UDF wird diesmal pro Zeile ausgeführt. Sie müssen sich jedoch darüber im Klaren sein, dass mit der zeilenweisen Ausführung der UDF eine ziemlich starke Leistungseinbuße verbunden ist. Darüber hinaus ist das Aufrufen einer skalaren T-SQL-UDF ein Parallelitätsverhinderer.
Der Plan für diese Abfrage ist in Abbildung 5 dargestellt.
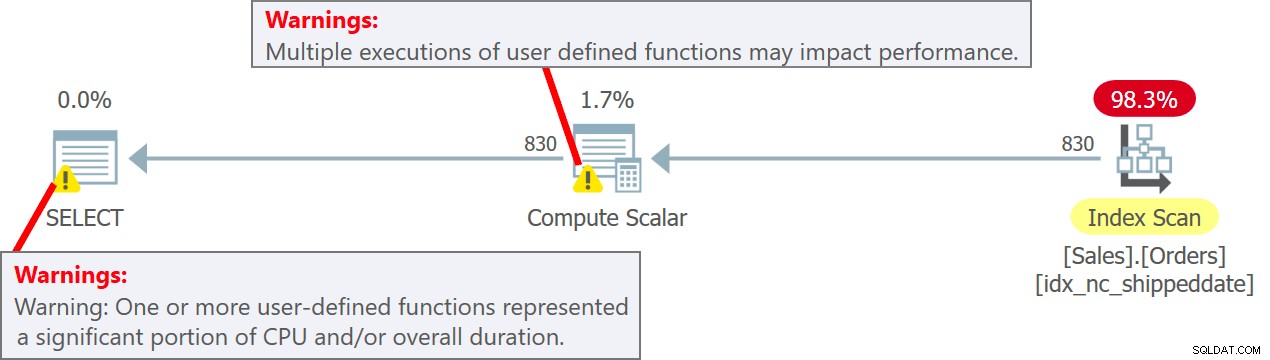
Abbildung 5:Plan für Abfrage 5
Beachten Sie im Plan, dass die UDF tatsächlich pro Quellzeile im Compute Scalar-Operator aufgerufen wird. Beachten Sie auch, dass SentryOne Plan Explorer Sie vor möglichen Leistungseinbußen warnt, die mit der Verwendung der UDF sowohl im Compute Scalar-Operator als auch im Stammknoten des Plans verbunden sind.
Ich habe die folgende Ausgabe von der Ausführung dieser Abfrage erhalten:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
Beachten Sie, dass die Ausgabezeilen mehrere unterschiedliche Datums- und Zeitwerte in der mydt-Spalte haben.
Sie haben vielleicht gehört, dass SQL Server 2019 das allgemeine Leistungsproblem behebt, das durch skalare T-SQL-UDFs verursacht wird, indem solche Funktionen eingebettet werden. Die UDF muss jedoch eine Liste von Anforderungen erfüllen, um inlinefähig zu sein. Eine der Anforderungen besteht darin, dass die UDF keine nicht deterministische intrinsische Funktion wie SYSDATETIME aufruft. Der Grund für diese Anforderung ist, dass Sie die UDF möglicherweise genau erstellt haben, um eine Ausführung pro Zeile zu erhalten. Wenn die UDF inliniert wurde, würde die zugrunde liegende nichtdeterministische Funktion nur einmal für die gesamte Abfrage ausgeführt. Tatsächlich wurde der Plan in Abbildung 5 in SQL Server 2019 generiert, und Sie können deutlich sehen, dass die UDF nicht eingebettet wurde. Das liegt an der Verwendung der nichtdeterministischen Funktion SYSDATETIME. Sie können überprüfen, ob eine UDF in SQL Server 2019 inlinefähig ist, indem Sie das is_inlineable-Attribut in der sys.sql_modules-Ansicht wie folgt abfragen:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
Dieser Code generiert die folgende Ausgabe, die Ihnen mitteilt, dass die UDF MySysDateTime nicht inlinefähig ist:
is_inlineable ------------- 0
Um eine UDF zu demonstrieren, die inlinefähig ist, ist hier die Definition einer UDF namens EndOfyear, die ein Eingabedatum akzeptiert und das entsprechende Datum des Jahresendes zurückgibt:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO Hier werden keine nichtdeterministischen Funktionen verwendet, und der Code erfüllt auch die anderen Anforderungen für Inlining. Sie können überprüfen, ob die UDF inlinefähig ist, indem Sie den folgenden Code verwenden:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
Dieser Code generiert die folgende Ausgabe:
is_inlineable ------------- 1
Die folgende Abfrage (nennen Sie sie Abfrage 6) verwendet die UDF EndOfYear, um Bestellungen zu filtern, die an einem Jahresendedatum aufgegeben wurden:
SELECT orderid FROM Sales.Orders WHERE orderdate = dbo.EndOfYear(orderdate);
Der Plan für diese Abfrage ist in Abbildung 6 dargestellt.
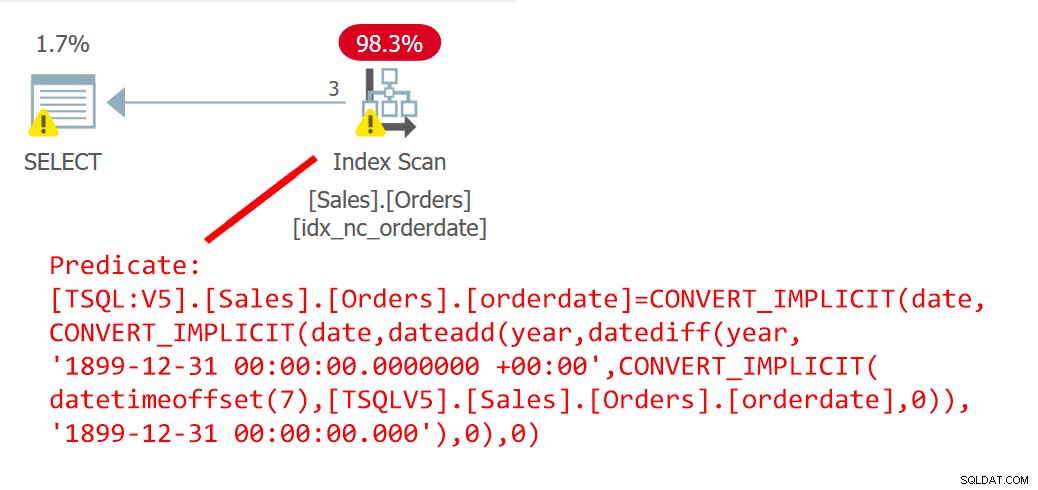
Abbildung 6:Plan für Abfrage 6
Der Plan zeigt deutlich, dass die UDF inliniert wurde.
Tabellenausdrücke, Nichtdeterminismus und Mehrfachreferenzen
Wie bereits erwähnt, werden nicht deterministische Funktionen wie SYSDATETIME einmal pro Referenz in einer Abfrage aufgerufen. Was aber, wenn Sie einmal in einer Abfrage in einem Tabellenausdruck wie einem CTE auf eine solche Funktion verweisen und dann eine äußere Abfrage mit mehreren Verweisen auf den CTE haben? Viele Leute wissen nicht, dass jeder Verweis auf den Tabellenausdruck separat erweitert wird und der eingebettete Code zu mehreren Verweisen auf die zugrunde liegende nichtdeterministische Funktion führt. Mit einer Funktion wie SYSDATETIME könnten Sie abhängig vom genauen Zeitpunkt jeder Ausführung für jede Ausführung ein anderes Ergebnis erhalten. Manche Leute finden dieses Verhalten überraschend.
Dies kann mit folgendem Code veranschaulicht werden:
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations; Wenn beide Verweise auf C1 in der Abfrage in C2 dasselbe darstellten, hätte dieser Code zu einer Endlosschleife geführt. Da die beiden Referenzen jedoch separat erweitert werden, führt die Vereinigung zu zwei Zeilen, wenn das Timing so ist, dass jeder Aufruf in einem anderen 100-Nanosekunden-Intervall (der Genauigkeit des Ergebniswerts) stattfindet, und der Code sollte von der Schleife. Führen Sie diesen Code aus und überzeugen Sie sich selbst. In der Tat bricht es nach einigen Iterationen. Ich habe bei einer der Ausführungen folgendes Ergebnis erhalten:
distinctvalues iterations -------------- ----------- 2 448
Die bewährte Methode besteht darin, die Verwendung von Tabellenausdrücken wie CTEs und Ansichten zu vermeiden, wenn die innere Abfrage nicht deterministische Berechnungen verwendet und die äußere Abfrage mehrmals auf den Tabellenausdruck verweist. Das gilt natürlich nur, wenn Sie die Auswirkungen verstehen und damit einverstanden sind. Alternative Optionen könnten darin bestehen, das innere Abfrageergebnis zu speichern, beispielsweise in einer temporären Tabelle, und dann die temporäre Tabelle beliebig oft abzufragen.
Angenommen, Sie müssen eine Abfrage schreiben, die zufällig Mitarbeiter aus der HR.Employees-Tabelle paart, um Beispiele zu demonstrieren, bei denen die Nichtbeachtung der Best Practices zu Problemen führen kann. Sie kommen mit der folgenden Abfrage (nennen Sie sie Abfrage 7), um die Aufgabe zu erledigen:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1; Der Plan für diese Abfrage ist in Abbildung 7 dargestellt.
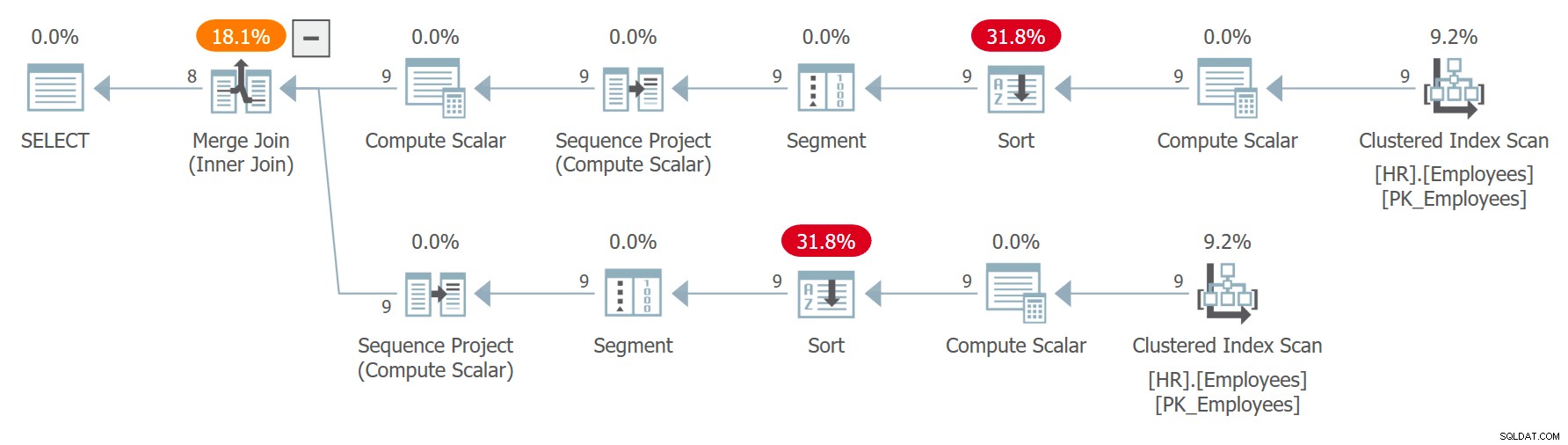
Abbildung 7:Plan für Abfrage 7
Beachten Sie, dass die beiden Verweise auf C separat erweitert werden und die Zeilennummern unabhängig für jeden Verweis berechnet werden, der durch unabhängige Aufrufe des Ausdrucks CHECKSUM(NEWID()) geordnet ist. Dies bedeutet, dass derselbe Mitarbeiter nicht garantiert dieselbe Zeilennummer in den beiden erweiterten Referenzen erhält. Wenn ein Mitarbeiter Zeilennummer x in C1 und Zeilennummer x – 1 in C2 erhält, wird die Abfrage den Mitarbeiter mit sich selbst verknüpfen. Zum Beispiel habe ich bei einer der Ausführungen folgendes Ergebnis erhalten:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
Beachten Sie, dass es hier drei Fälle von Selbstpaaren gibt. Dies lässt sich leichter erkennen, indem der äußeren Abfrage ein Filter hinzugefügt wird, der speziell nach Selbstpaaren sucht, etwa so:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid; Möglicherweise müssen Sie diese Abfrage mehrmals ausführen, um das Problem zu sehen. Hier ist ein Beispiel für das Ergebnis, das ich bei einer der Hinrichtungen erhalten habe:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
Gemäß der bewährten Methode besteht eine Möglichkeit zur Lösung dieses Problems darin, das innere Abfrageergebnis in einer temporären Tabelle zu speichern und dann nach Bedarf mehrere Instanzen der temporären Tabelle abzufragen.
Ein weiteres Beispiel veranschaulicht Fehler, die sich aus der Verwendung einer nicht deterministischen Reihenfolge und mehrfachen Verweisen auf einen Tabellenausdruck ergeben können. Angenommen, Sie müssen die Tabelle „Sales.Orders“ abfragen und möchten, um eine Trendanalyse durchzuführen, jede Bestellung basierend auf der Bestellung nach Bestelldatum mit der nächsten koppeln. Ihre Lösung muss mit Systemen vor SQL Server 2012 kompatibel sein, was bedeutet, dass Sie die offensichtlichen LAG/LEAD-Funktionen nicht verwenden können. Sie beschließen, einen CTE zu verwenden, der Zeilennummern berechnet, um Zeilen basierend auf der Reihenfolge des Bestelldatums zu positionieren, und verbinden dann zwei Instanzen des CTE, indem Sie Bestellungen basierend auf einem Offset von 1 zwischen den Zeilennummern wie folgt paaren (nennen Sie diese Abfrage 8):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1; Der Plan für diese Abfrage ist in Abbildung 8 dargestellt.
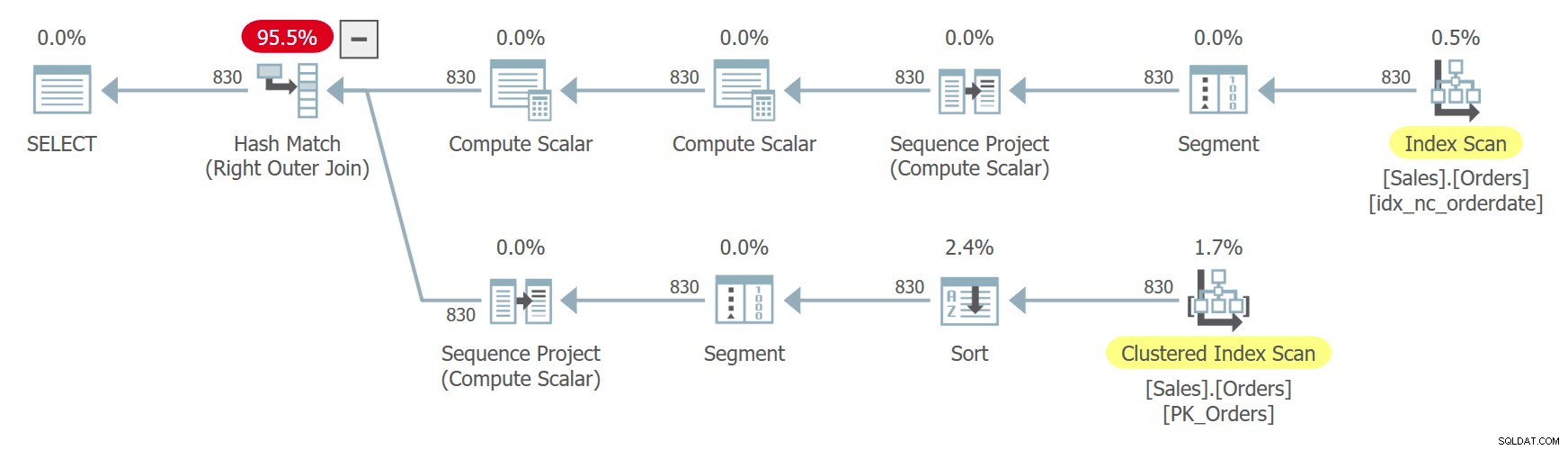 Abbildung 8:Plan für Abfrage 8
Abbildung 8:Plan für Abfrage 8
Die Reihenfolge der Zeilennummern ist nicht deterministisch, da das Bestelldatum nicht eindeutig ist. Beachten Sie, dass die beiden Verweise auf den CTE separat erweitert werden. Merkwürdigerweise entscheidet sich der Optimierer, in jedem Fall einen anderen Index zu verwenden, da die Abfrage nach einer anderen Teilmenge von Spalten aus jeder der Instanzen sucht. In einem Fall verwendet es einen geordneten Rückwärtsscan des Index am Bestelldatum, wodurch effektiv Zeilen mit demselben Datum basierend auf der Bestell-ID in absteigender Reihenfolge gescannt werden. Im anderen Fall scannt es den gruppierten Index, sortiert falsch und sortiert dann, aber effektiv unter Zeilen mit demselben Datum greift es auf die Zeilen in aufsteigender Reihenfolge zu. Das liegt an einer ähnlichen Argumentation, die ich zuvor im Abschnitt über nichtdeterministische Ordnung angeführt habe. Dies kann dazu führen, dass dieselbe Zeile in einem Fall die Zeilennummer x und in dem anderen Fall die Zeilennummer x – 1 erhält. In einem solchen Fall wird der Join am Ende eine Bestellung mit sich selbst abgleichen, anstatt mit der nächsten, wie es sollte.
Beim Ausführen dieser Abfrage habe ich folgendes Ergebnis erhalten:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
Beachten Sie die Selbstübereinstimmungen im Ergebnis. Auch hier kann das Problem leichter identifiziert werden, indem ein Filter hinzugefügt wird, der nach Selbstübereinstimmungen sucht, etwa so:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid; Ich habe die folgende Ausgabe von dieser Abfrage:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
Die beste Vorgehensweise hier ist sicherzustellen, dass Sie eine eindeutige Reihenfolge verwenden, um den Determinismus zu gewährleisten, indem Sie der Fensterreihenfolgeklausel einen Tiebreaker wie orderid hinzufügen. Obwohl Sie also mehrere Verweise auf denselben CTE haben, werden die Zeilennummern in beiden gleich sein. Wenn Sie die Wiederholung der Berechnungen vermeiden möchten, können Sie auch in Betracht ziehen, das Ergebnis der inneren Abfrage beizubehalten, aber dann müssen Sie die zusätzlichen Kosten einer solchen Arbeit berücksichtigen.
CASE/NULLIF und nichtdeterministische Funktionen
Wenn Sie in einer Abfrage mehrere Verweise auf eine nicht deterministische Funktion haben, wird jeder Verweis separat ausgewertet. Was überraschend sein und sogar zu Fehlern führen kann, ist, dass Sie manchmal eine Referenz schreiben, die jedoch implizit in mehrere Referenzen umgewandelt wird. Dies ist bei einigen Verwendungen des CASE-Ausdrucks und der IIF-Funktion der Fall.
Betrachten Sie das folgende Beispiel:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
Hier ist das Ergebnis des getesteten Ausdrucks ein nicht negativer ganzzahliger Wert, also muss es eindeutig entweder gerade oder ungerade sein. Es kann weder gerade noch ungerade sein. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END; In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END; A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Schlussfolgerung
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!