PostgreSQL 11 wurde planmäßig am 10. Oktober 2018 veröffentlicht, anlässlich des 23. Jahrestages der immer beliebter werdenden Open-Source-Datenbank.
Während eine vollständige Liste der Änderungen in den üblichen Versionshinweisen verfügbar ist, lohnt es sich, einen Blick auf die überarbeitete Feature-Matrix-Seite zu werfen, die genau wie die offizielle Dokumentation seit ihrer ersten Version eine Überarbeitung erfahren hat, was es einfacher macht, Änderungen zu erkennen, bevor man in die Details eintaucht .
Beispielsweise ist auf der Seite mit den Versionshinweisen die „Kanalbindung für die SCAM-Authentifizierung“ unter dem Quellcode vergraben, während die Matrix sie im Abschnitt „Sicherheit“ enthält. Für Neugierige hier ein Screenshot der Benutzeroberfläche:
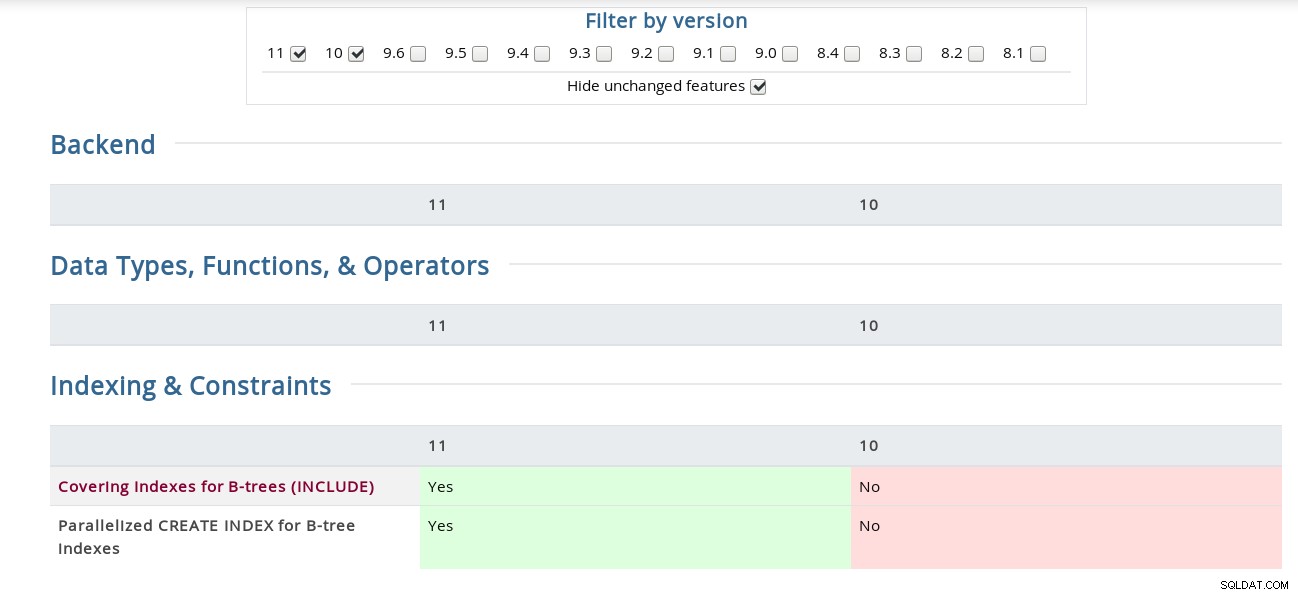 PostgreSQL-Funktionsmatrix
PostgreSQL-Funktionsmatrix Darüber hinaus ist die oben verlinkte Seite mit den Versionshinweisen von Bucardo Postgres auf ihre Art praktisch und macht es einfach, in allen Versionen nach einem Schlüsselwort zu suchen.
Was gibt's Neues? Mit buchstäblich Hunderten von Änderungen werde ich die in der Funktionsmatrix aufgeführten Unterschiede durchgehen.
Abdeckende Indizes für B-Bäume (INCLUDE)
CREATE INDEX hat die INCLUDE-Klausel erhalten, die Indizes erlaubt, Nicht-Schlüsselspalten einzuschließen . Sein Anwendungsfall für häufige identische Abfragen ist in Tom Lanes Commit vom 22. November gut beschrieben, der die Entwicklungsdokumentation aktualisiert (was bedeutet, dass die aktuelle PostgreSQL 11-Dokumentation ihn noch nicht enthält), daher finden Sie den vollständigen Text in Abschnitt 11.9. Index-Only Scans und Covering Indexes in der Entwicklungsversion.
Parallelisierter CREATE INDEX für B-Tree-Indizes
Wie der Name schon sagt, ist diese Funktion nur für die B-Tree-Indizes implementiert, und aus dem Commit-Protokoll von Robert Haas erfahren wir, dass die Implementierung in Zukunft möglicherweise verfeinert wird. Wie aus der CREATE INDEX-Dokumentation hervorgeht, nutzen sowohl parallele als auch gleichzeitige Indexerstellungsmethoden mehrere CPUs, im Fall von CONCURRENT wird jedoch nur der erste Tabellenscan parallel durchgeführt.
Im Zusammenhang mit dieser neuen Funktion stehen die Konfigurationsparameter maintenance_work_mem und maintenance_parallel_maintenance_workers .
Schließlich kann die Anzahl der parallelen Worker pro Tabelle mit dem ALTER TABLE-Befehl und der Angabe eines Werts für parallel_workers festgelegt werden .
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterJust-In-Time (JIT)-Kompilierung für Ausdrucksauswertung und Tupelverformung
Mit einem eigenen JIT-Kapitel in der Dokumentation stützt sich diese neue Funktion darauf, dass PostgreSQL mit LLVM-Unterstützung kompiliert wird (verwenden Sie pg_config zur Überprüfung).
Das Thema JIT in PostgreSQL ist komplex genug (siehe die JIT-README-Referenz in der Dokumentation), um einen eigenen Blog zu erfordern, in der Zwischenzeit ist der CitusData-Blog zu JIT eine sehr gute Lektüre für diejenigen, die tiefer in das Thema eintauchen möchten.
Parallelisierte Hash-Joins
Diese Leistungsverbesserung bei parallelen Abfragen ist das Ergebnis des Hinzufügens einer gemeinsam genutzten Hash-Tabelle, die, wie Thomas Munro in seinem Blog „Parallel Hash for PostgreSQL“ erklärt, eine Partitionierung der Hash-Tabelle vermeidet, vorausgesetzt, sie passt in work_mem , was bisher für PostgreSQL eine bessere Lösung zu sein scheint als der Partition-First-Algorithmus. Derselbe Blog beschreibt die Hindernisse der PostgreSQL-Architektur, die der Autor bei seinem Streben nach einer Parallelisierung von Hash-Joins überwinden musste, was für die Komplexität der Arbeit spricht, die erforderlich war, um diese Funktion zu implementieren.
Standardpartition
Dies ist eine Catch-All-Partition zum Speichern von Zeilen, die mit keiner anderen definierten Partition übereinstimmen. In Fällen, in denen eine neue Partition hinzugefügt wird, wird eine CHECK-Einschränkung empfohlen, um einen Scan der Standardpartition zu vermeiden, der langsam sein kann, wenn die Standardpartition eine große Anzahl von Zeilen enthält.
Das standardmäßige Partitionsverhalten wird in der Dokumentation von ALTER TABLE und CREATE TABLE erklärt.
Partitionierung durch einen Hash-Schlüssel
Auch als Hash-Partitionierung bezeichnet und wie in der Commit-Nachricht ausgeführt, ermöglicht die Funktion die Partitionierung von Tabellen auf eine Weise, dass Partitionen eine ähnliche Anzahl von Zeilen enthalten. Dies wird erreicht, indem ein Modul bereitgestellt wird, der in einem einfacheren Szenario gleich der Anzahl der Partitionen sein sollte und der Rest für jede Partition unterschiedlich sein sollte.
Weitere Einzelheiten und ein Beispiel finden Sie auf der CREATE TABLE-Dokumentationsseite.
Unterstützung für PRIMARY KEY, FOREIGN KEY, Indizes und Trigger auf partitionierten Tabellen
Die Tabellenpartitionierung ist bereits ein großer Schritt zur Verbesserung der Leistung großer Tabellen, und das Hinzufügen dieser Funktionen beseitigt die Einschränkungen, die partitionierte Tabellen seit PostgreSQL 10 hatten, als die moderne „deklarative Partitionierung“ eingeführt wurde.
Arbeiten von Alvaro Herrera sind im Gange, um Fremdschlüsseln das Referenzieren von Primärschlüsseln zu ermöglichen, und sind für die nächste PostgreSQL-Hauptversion 12 geplant.
UPDATE auf einem Partitionsschlüssel
Wie im Patch-Commit-Log erklärt, verhindert dieses Update, dass PostgreSQL einen Fehler ausgibt, wenn eine Aktualisierung des Partitionsschlüssels eine Zeile ungültig macht, und stattdessen wird die Zeile in eine geeignete Partition verschoben.
Kanalbindung für SCRAM-Authentifizierung
Dies ist eine Sicherheitsmaßnahme, die darauf abzielt, Man-in-the-Middle-Angriffe bei der SASL-Authentifizierung zu verhindern, und wird im Blog des Autors ausführlich beschrieben. Die Funktion erfordert mindestens OpenSSL 1.0.2.
CREATE PROCEDURE und CALL Syntax für gespeicherte SQL-Prozeduren
PostgreSQL hat CREATE FUNCTION seit 1996 mit Version 1.0.1 , Funktionen können jedoch keine Transaktionen verarbeiten. Wie in der Dokumentation erwähnt, ist der Befehl CREATE PROCEDURE nicht vollständig kompatibel mit dem SQL-Standard.
Hinweis:Bleiben Sie dran für einen kommenden Blog, der diese Funktion ausführlich behandelt
Schlussfolgerung
Die Hauptaktualisierungen von PostgreSQL 11 konzentrieren sich auf Leistungsverbesserungen durch parallele Ausführung, Partitionierung und Just-in-Time-Kompilierung. Gespeicherte Prozeduren ermöglichen eine vollständige Transaktionskontrolle und können in einer Vielzahl von PL-Sprachen geschrieben werden.