Ich habe kurz erwähnt, dass Daten im Batch-Modus normalisiert werden in meinem letzten Artikel Batch Mode Bitmaps in SQL Server. Alle Daten in einem Stapel werden unabhängig vom zugrunde liegenden Datentyp durch einen 8-Byte-Wert in diesem speziellen normalisierten Format dargestellt.
Diese Aussage wirft zweifellos einige Fragen auf, nicht zuletzt darüber, wie Daten mit einer Länge von viel mehr als acht Bytes möglicherweise auf diese Weise gespeichert werden können. Dieser Artikel untersucht die normalisierte Darstellung von Stapeldaten, erklärt, warum nicht alle 8-Byte-Datentypen in 64 Bit passen, und zeigt ein Beispiel dafür, wie sich all dies auf die Leistung im Stapelmodus auswirkt.
Demo
Ich beginne mit einem Beispiel, das das Stapeldatenformat zeigt, das einen wichtigen Unterschied zu einem Ausführungsplan ausmacht. Sie benötigen SQL Server 2016 (oder höher) und Developer Edition (oder gleichwertig), um die hier gezeigten Ergebnisse zu reproduzieren.
Das erste, was wir brauchen, ist eine Tabelle mit bigint Zahlen von 1 bis einschließlich 102.400. Diese Zahlen werden verwendet, um in Kürze eine Columnstore-Tabelle zu füllen (die Anzahl der Zeilen ist das Minimum, das erforderlich ist, um ein einzelnes komprimiertes Segment zu erhalten).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Erfolgreicher Aggregat-Pushdown
Das folgende Skript verwendet die Zahlentabelle, um eine weitere Tabelle zu erstellen, die dieselben Zahlen enthält, die um einen bestimmten Wert versetzt sind. Diese Tabelle verwendet Columnstore als primären Speicher, um später eine Ausführung im Stapelmodus zu ermöglichen.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Führen Sie die folgenden Testabfragen für die neue Columnstore-Tabelle aus:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Die Addition innerhalb des SUM ist Überlauf zu vermeiden. Sie können das WHERE überspringen -Klauseln (um einen trivialen Plan zu vermeiden), wenn Sie SQL Server 2017 ausführen.
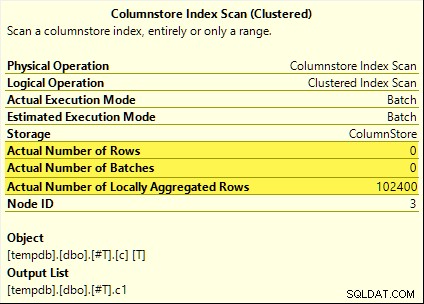
Diese Abfragen profitieren alle vom aggregierten Pushdown. Das Aggregat wird beim Columnstore Index Scan berechnet anstelle des Batch-Modus Hash Aggregate Operator. Pläne nach der Ausführung zeigen null Zeilen, die vom Scan ausgegeben wurden. Alle 102.400 Zeilen wurden „lokal aggregiert“.
Die SUM Plan ist unten als Beispiel dargestellt:

Nicht erfolgreicher Aggregat-Pushdown
Löschen Sie jetzt die Columnstore-Testtabelle und erstellen Sie sie dann neu, wobei der Offset um eins verringert wird:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Führen Sie genau die gleichen aggregierten Pushdown-Testabfragen wie zuvor aus:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Diesmal nur COUNT_BIG Aggregat erzielt Aggregat-Pushdown (nur SQL Server 2017). Der MAX und SUM Aggregate nicht. Hier ist die neue SUM Vergleichsplan mit dem aus dem ersten Test:

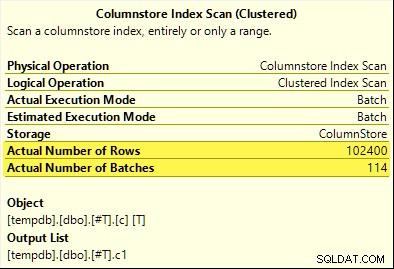
Alle 102.400 Zeilen (in 114 Batches) werden vom Columnstore Index Scan ausgegeben , verarbeitet vom Compute Scalar , und an das Hash-Aggregat gesendet .
Warum der Unterschied? Wir haben lediglich den Zahlenbereich, der in der Columnstore-Tabelle gespeichert ist, um eins versetzt!
Erklärung
Ich habe in der Einleitung erwähnt, dass nicht alle Acht-Byte-Datentypen in 64 Bit passen. Diese Tatsache ist wichtig da viele Columnstore- und Batchmodus-Leistungsoptimierungen nur mit Daten mit einer Größe von 64 Bit funktionieren. Aggregierter Pushdown ist eines dieser Dinge. Es gibt viele weitere Leistungsmerkmale (nicht alle dokumentiert), die nur dann am besten (oder überhaupt) funktionieren, wenn die Daten in 64 Bit passen.
In unserem konkreten Beispiel ist der Aggregat-Pushdown deaktiviert für ein Columnstore-Segment, wenn es gerade eins enthält Datenwert, der nicht in 64 Bit passt. SQL Server kann dies anhand der jedem Segment zugeordneten Mindest- und Höchstwert-Metadaten ermitteln, ohne alle Daten zu überprüfen. Jedes Segment wird separat ausgewertet.
Aggregierter Pushdown funktioniert immer noch für COUNT_BIG Aggregat erst im zweiten Test. Dies ist eine Optimierung, die irgendwann in SQL Server 2017 hinzugefügt wurde (meine Tests wurden auf CU16 ausgeführt). Es ist logisch, den Aggregat-Pushdown nicht zu deaktivieren, wenn wir nur Zeilen zählen und nichts mit den spezifischen Datenwerten tun. Ich konnte keine Dokumentation für diese Verbesserung finden, aber das ist heutzutage nicht mehr so ungewöhnlich.
Als Nebenbemerkung ist mir aufgefallen, dass SQL Server 2017 CU16 aggregiertes Pushdown für die zuvor nicht unterstützten Datentypen real ermöglicht , float , datetimeoffset , und numeric mit einer Genauigkeit von mehr als 18 – wenn die Daten in 64 Bit passen. Dies ist zum Zeitpunkt des Schreibens ebenfalls nicht dokumentiert.
Okay, aber warum?
Sie stellen sich vielleicht die sehr vernünftige Frage:Warum funktioniert ein Satz von bigint Testwerte passen anscheinend in 64 Bit, aber die anderen nicht?
Wenn Sie erraten haben, dass der Grund mit NULL zusammenhängt , gib dir ein Häkchen. Obwohl die Testtabellenspalte als NOT NULL definiert ist verwendet SQL Server dasselbe normalisierte Datenlayout für bigint ob die Daten Nullen zulassen oder nicht. Dafür gibt es Gründe, die ich nach und nach auspacken werde.
Lassen Sie mich mit einigen Beobachtungen beginnen:
- Jeder Spaltenwert in einem Stapel wird unabhängig vom zugrunde liegenden Datentyp in genau acht Bytes (64 Bit) gespeichert. Dieses Layout mit fester Größe macht alles einfacher und schneller. Bei der Ausführung im Batch-Modus dreht sich alles um Geschwindigkeit.
- Ein Stapel ist 64 KB groß und enthält zwischen 64 und 900 Zeilen, je nach Anzahl der projizierten Spalten. Dies ist sinnvoll, da die Spaltendatengrößen auf 64 Bit festgelegt sind. Mehr Spalten bedeuten, dass weniger Zeilen in jeden 64-KB-Batch passen.
- Nicht alle SQL Server-Datentypen passen in 64 Bit, nicht einmal im Prinzip. Eine lange Zeichenfolge (um ein Beispiel zu nennen) passt möglicherweise nicht einmal in einen ganzen 64-KB-Batch (wenn das erlaubt wäre), geschweige denn in einen einzelnen 64-Bit-Eintrag.
SQL Server löst dieses letzte Problem, indem es eine 8-Byte Referenz speichert auf Daten größer als 64 Bit. Der „große“ Datenwert wird an anderer Stelle im Speicher gespeichert. Sie könnten diese Anordnung als „Off-Row“- oder „Out-of-Batch“-Lagerung bezeichnen. Intern wird es als Deep Data bezeichnet .
Jetzt passen 8-Byte-Datentypen nicht in 64 Bit, wenn sie nullfähig sind. Nimm bigint NULL zum Beispiel . Der Nicht-Null-Datenbereich erfordert möglicherweise die vollen 64 Bits, und wir benötigen noch ein weiteres Bit, um null oder nicht anzuzeigen.
Probleme lösen
Die kreative und effiziente Lösung für diese Herausforderungen besteht darin, das niedrigstwertige Bit zu reservieren (LSB) des 64-Bit-Werts als Flag. Das Flag zeigt in-batch an Datenspeicherung, wenn das LSB frei ist (auf Null gesetzt). Wenn das LSB eingestellt ist (zu einem) kann es eines von zwei Dingen bedeuten:
- Der Wert ist null; oder
- Der Wert wird außerhalb des Stapels gespeichert (es handelt sich um Deep Data).
Diese beiden Fälle werden durch den Zustand der verbleibenden 63 Bit unterschieden. Wenn sie alle Null sind , der Wert ist NULL . Andernfalls ist der „Wert“ ein Zeiger auf Deep Data, die an anderer Stelle gespeichert sind.
Als Ganzzahl betrachtet bedeutet das Festlegen des LSB, dass Zeiger auf tiefe Daten immer ungerade sind Zahlen. Nullen werden durch die (ungerade) Zahl 1 dargestellt (alle anderen Bits sind Null). In-Batch-Daten werden durch gerade dargestellt Zahlen, weil das LSB null ist.
Dies gilt nicht bedeutet, dass SQL Server nur gerade Zahlen innerhalb eines Stapels speichern kann! Es bedeutet nur, dass die normalisierte Darstellung der zugrunde liegenden Spaltenwerte haben immer ein Null-LSB, wenn sie „in Batch“ gespeichert werden. Das wird gleich mehr Sinn ergeben.
Stapeldatennormalisierung
Die Normalisierung wird abhängig vom zugrunde liegenden Datentyp auf unterschiedliche Weise durchgeführt. Für bigint Der Prozess ist:
- Wenn die Daten Null sind , den Wert 1 speichern (nur LSB gesetzt).
- Wenn der Wert in 63 Bit dargestellt werden kann , verschiebt alle Bits um eine Stelle nach links und nullt das LSB. Betrachtet man den Wert als ganze Zahl, bedeutet dies Verdopplung der Wert. Zum Beispiel
bigintWert 1 wird auf den Wert 2 normalisiert. Im Binärformat sind das sieben reine Null-Bytes, gefolgt von00000010. Das LSB, das Null ist, zeigt an, dass dies Daten sind, die inline gespeichert sind. Wenn SQL Server den ursprünglichen Wert benötigt, verschiebt es den 64-Bit-Wert um eine Position nach rechts (wobei das LSB-Flag verworfen wird). - Wenn der Wert nicht kann in 63 Bit dargestellt werden, wird der Wert off-batch als deep data gespeichert . Der In-Batch-Zeiger hat das LSB-Set (was es zu einer ungeraden Zahl macht).
Der Prozess des Testens, ob ein bigint Wert in 63 Bit passen ist:
- Speichern Sie die rohe*
bigintWert im 64-Bit-Prozessorregisterr8. - Speichern Sie den doppelten Wert von
r8im Registerrax. - Verschiebe die Bits von
raxeine Stelle rechts. - Testen Sie, ob die Werte in
raxundr8sind gleich.
* Beachten Sie, dass der Rohwert nicht für alle Datentypen zuverlässig durch eine T-SQL-Konvertierung in einen binären Typ bestimmt werden kann. Das T-SQL-Ergebnis kann eine andere Byte-Reihenfolge haben und auch Metadaten enthalten, z. time Sekundenbruchteilgenauigkeit.
Wenn der Test in Schritt 4 bestanden wird, wissen wir, dass der Wert innerhalb von 64 Bit verdoppelt und dann halbiert werden kann – wobei der ursprüngliche Wert erhalten bleibt.
Eine reduzierte Reichweite
Das Ergebnis von all dem ist, dass der Bereich von bigint Werte, die im Batch gespeichert werden können, reduziert um ein Bit (weil das LSB nicht verfügbar ist). Die folgenden inklusiven Bereiche von bigint Werte werden außerhalb des Stapels als tiefe Daten gespeichert :
- -4.611.686.018.427.387.905 bis -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 bis +9.223.372.036.854.775.807
Als Gegenleistung dafür, dass Sie akzeptieren, dass diese bigint Bereichsbeschränkungen erlaubt die Normalisierung SQL Server, (die meisten) bigint zu speichern Werte, Nullen und tiefe Datenreferenzen in Batch . Dies ist viel einfacher und platzsparender als separate Strukturen für Nullzulässigkeit und tiefe Datenreferenzen. Es macht auch die Verarbeitung von Stapeldaten mit SIMD-Prozessoranweisungen viel einfacher.
Normalisierung anderer Datentypen
SQL Server enthält Normalisierung Code für jeden der Datentypen, die von der Stapelmodusausführung unterstützt werden. Jede Routine ist optimiert, um das eingehende Binärlayout effizient zu handhaben und nur bei Bedarf tiefe Daten zu erstellen. Die Normalisierung führt immer dazu, dass das LSB reserviert wird, um Nullen oder tiefe Daten anzuzeigen, aber das Layout der verbleibenden 63 Bits variiert je nach Datentyp.
Immer im Batch
Normalisierte Daten für die folgenden Datentypen werden immer im Batch gespeichert da sie nie mehr als 63 Bit brauchen:
datetime(n)– intern auftime(7)umskaliertdatetime2(n)– intern aufdatetime2(7)umskaliertintegersmallinttinyintbit– verwendet dentinyintUmsetzung.smalldatetimedatetimerealfloatsmallmoney
Es kommt darauf an
Die folgenden Datentypen können In-Batch oder Deep Data gespeichert werden je nach Datenwert:
bigint– wie zuvor beschrieben.money– gleicher Bereich im Batch wiebigintaber geteilt durch 10.000.numeric/decimal– 18 Dezimalstellen oder weniger im Batch ungeachtet deklarierter Präzision. Zum Beispieldecimal(38,9)Der Wert -999999999.999999999 kann als 8-Byte-Ganzzahl -999999999999999999 (f21f494c589c0001) dargestellt werden hex), die auf -1999999999999999998 verdoppelt werden kann (e43e9298b1380002). hex) reversibel innerhalb von 64 Bit. SQL Server weiß, wo der Dezimalpunkt von der Datentypskalierung steht.datetimeoffset(n)– In-Batch wenn der Laufzeitwert passt indatetimeoffset(2)egal der deklarierten Genauigkeit von Sekundenbruchteilen.timestamp– Internes Format weicht vom Display ab. Zum Beispiel eintimestampangezeigt von T-SQL als0x000000000099449Awird intern als9a449900 00000000dargestellt (in Hex). Dieser Wert wird als tiefe Daten gespeichert, da er verdoppelt (um ein Bit nach links verschoben) nicht in 64 Bit passt.
Immer tiefe Daten
Die folgenden Daten werden immer als tiefe Daten (außer Nullen) gespeichert :
uniqueidentifiervarbinary(n)– einschließlich(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameeinschließlich(max)– diese Typen können auch ein Wörterbuch verwenden (wenn verfügbar).text/ntext/image/xml– verwendet dievarbinary(n)Umsetzung.
Um es klar zu sagen:Nullen für alle Batch-Modus-kompatible Datentypen werden im Batch als Sonderwert „Eins“ gespeichert.
Abschließende Gedanken
Sie können davon ausgehen, das Beste aus den verfügbaren Columnstore- und Stapelmodusoptimierungen herauszuholen, wenn Sie Datentypen und Werte verwenden, die in 64 Bit passen. Sie haben auch die besten Chancen, im Laufe der Zeit von inkrementellen Produktverbesserungen zu profitieren, z. B. den neuesten Verbesserungen von Aggregat Pushdown, die im Haupttext erwähnt werden. Nicht alle Leistungsvorteile sind in Ausführungsplänen so sichtbar oder sogar dokumentiert. Dennoch können die Unterschiede extrem groß sein.
Ich sollte auch erwähnen, dass Daten normalisiert werden, wenn ein Ausführungsplanoperator im Zeilenmodus Daten an einen übergeordneten Batchmodus bereitstellt oder wenn ein Nicht-Columstore-Scan Batches erzeugt (Batchmodus auf Rowstore). Es gibt einen unsichtbaren Row-to-Batch-Adapter, der die entsprechende Normalisierungsroutine für jeden Spaltenwert aufruft, bevor er dem Batch hinzugefügt wird. Das Vermeiden von Datentypen mit komplizierter Normalisierung und tiefer Datenspeicherung kann auch hier zu Leistungsvorteilen führen.