Die wichtigsten Änderungen, die an der Kardinalitätsschätzung ab der Version SQL Server 2014 vorgenommen wurden, sind im Microsoft White Paper Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator von Joe Sack, Yi Fang und Vassilis Papadimos beschrieben.
Eine dieser Änderungen betrifft die Schätzung von einfachen Joins mit einem einzigen Gleichheits- oder Ungleichheitsprädikat unter Verwendung von Statistikhistogrammen. Im Abschnitt mit der Überschrift "Join Estimate Algorithm Changes" führte das Papier das Konzept der "groben Ausrichtung" unter Verwendung von minimalen und maximalen Histogrammgrenzen ein:
Für Joins mit einem einzelnen Gleichheits- oder Ungleichheitsprädikat verbindet das Legacy-CE die Histogramme in den Join-Spalten, indem es die beiden Histogramme Schritt für Schritt mit linearer Interpolation ausrichtet. Diese Methode könnte zu inkonsistenten Kardinalitätsschätzungen führen. Daher verwendet das neue CE jetzt einen einfacheren Join-Schätzalgorithmus, der Histogramme nur unter Verwendung von minimalen und maximalen Histogrammgrenzen ausrichtet.Obwohl möglicherweise weniger konsistent, kann das ältere CE aufgrund der schrittweisen Histogrammausrichtung etwas bessere Bedingungsschätzungen für einfache Verknüpfungen erzeugen. Das neue CE verwendet eine grobe Ausrichtung. Der Unterschied in den Schätzungen kann jedoch klein genug sein, dass es weniger wahrscheinlich ist, dass es zu Problemen mit der Planqualität kommt.
Als einer der technischen Gutachter des Papiers hatte ich das Gefühl, dass etwas mehr Details zu dieser Änderung nützlich gewesen wären, aber das hat es nicht in die endgültige Version geschafft. Dieser Artikel fügt einige dieser Details hinzu.
Beispiel für grobe Histogrammausrichtung
Die grobe Ausrichtung Beispiel im White Paper verwendet die Data Warehouse-Version der AdventureWorks-Beispieldatenbank. Trotz des Namens ist die Datenbank eher klein; Das Backup ist nur 22,3 MB groß und erweitert sich auf etwa 200 MB. Es kann über Links auf der Dokumentationsseite Installation und Konfiguration von AdventureWorks heruntergeladen werden.
Die Suchanfrage, an der wir interessiert sind, wird zu FactResellerSales hinzugefügt und FactCurrencyRate Tabellen.
SELECT
FRS.ProductKey,
FRS.OrderDateKey,
FRS.DueDateKey,
FRS.ShipDateKey,
FCR.DateKey,
FCR.AverageRate,
FCR.EndOfDayRate,
FCR.[Date]
FROM dbo.FactResellerSales AS FRS
JOIN dbo.FactCurrencyRate AS FCR
ON FCR.CurrencyKey = FRS.CurrencyKey; Dies ist ein einfacher Equijoin in einer einzelnen Spalte Daher eignet es sich für Join-Kardinalitäts- und Selektivitätsschätzungen mit Histogramm-Grobausrichtung.
Histogramme
Die benötigten Histogramme sind dem CurrencyKey zugeordnet Spalte in jeder verknüpften Tabelle. Auf einer neuen Kopie der AdventureWorksDW-Datenbank werden die bereits vorhandenen Statistiken für die größeren FactResellerSales Tabelle basieren auf einem Muster. Um die Reproduzierbarkeit zu maximieren und die detaillierten Berechnungen so einfach wie möglich nachvollziehbar zu machen (Vermeidung von Skalierung), aktualisieren wir zunächst die Statistiken mit einem vollständigen Scan:
UPDATE STATISTICS dbo.FactCurrencyRate WITH FULLSCAN; UPDATE STATISTICS dbo.FactResellerSales WITH FULLSCAN;
Diese Tabellen haben den demofreundlichen Vorteil, kleine und einfache maxdiff zu erstellen Histogramme:
DBCC SHOW_STATISTICS
(FactResellerSales, CurrencyKey)
WITH HISTOGRAM;
DBCC SHOW_STATISTICS
(FactCurrencyRate, [PK_FactCurrencyRate_CurrencyKey_DateKey])
WITH HISTOGRAM;
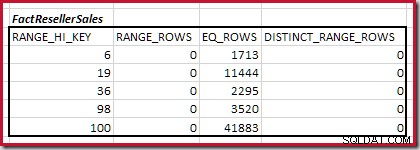
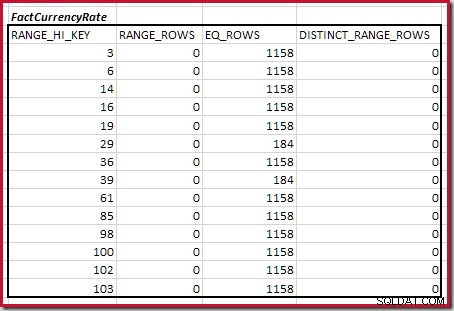
Kombinieren der minimalen übereinstimmenden Histogrammschritte
Der erste Schritt in der Grobausrichtung Die Berechnung besteht darin, den Beitrag zur Join-Kardinalität zu finden, der durch den niedrigsten übereinstimmenden Histogrammschritt bereitgestellt wird. Für unsere Beispielhistogramme liegt der kleinste passende Schrittwert bei RANGE_HI_KEY = 6 :
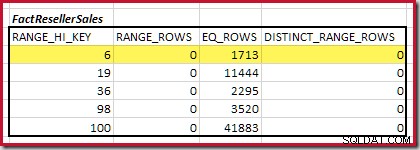
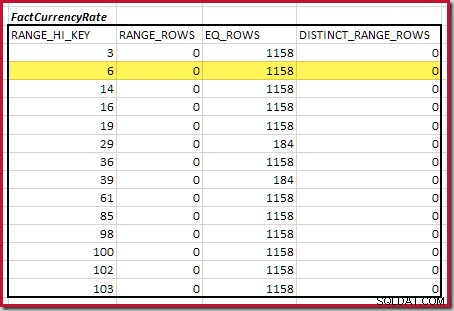
Die geschätzte Equijoin-Kardinalität für nur diesen hervorgehobenen Schritt beträgt 1.713 * 1.158 =1.983.654 Zeilen .
Verbleibende übereinstimmende Schritte
Als nächstes müssen wir den Bereich des Histogramms RANGE_HI_KEY identifizieren Schritte bis zum Maximum für mögliche Equijoin-Matches. Dies beinhaltet das Vorwärtsbewegen von dem zuvor gefundenen Minimum, bis eine der Histogrammeingaben keine Zeilen mehr hat. Die übereinstimmenden Equijoin-Bereiche für das aktuelle Beispiel sind unten hervorgehoben:
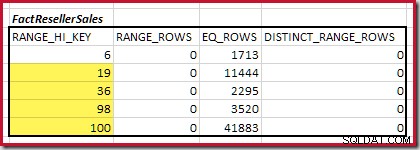
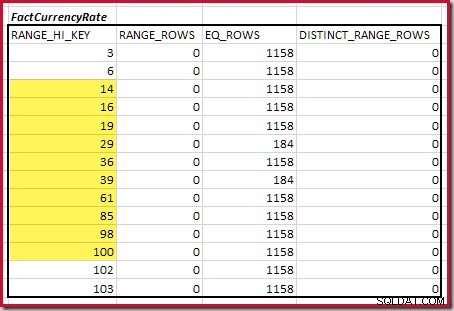
Diese beiden Bereiche stellen die verbleibenden Zeilen dar, von denen erwartet werden kann, dass sie zur Equijoin-Kardinalität beitragen.
Grobe frequenzbasierte Schätzung
Die Frage ist nun, wie man eine grobe durchführt Schätzung der Equijoin-Kardinalität der hervorgehobenen Schritte unter Verwendung der verfügbaren Informationen.
Der ursprüngliche Kardinalitätsschätzer hätte eine feinkörnige schrittweise Histogrammausrichtung unter Verwendung einer linearen Interpolation durchgeführt, den Join-Beitrag jedes Schritts bewertet (ähnlich wie wir es zuvor für den minimalen Schrittwert getan haben) und jeden Schrittbeitrag summiert, um a zu erhalten vollständige Join-Schätzung. Obwohl dieses Verfahren sehr intuitiv sinnvoll ist, hat die praktische Erfahrung gezeigt, dass dieser feinkörnige Ansatz zusätzlichen Rechenaufwand verursacht und Ergebnisse von unterschiedlicher Qualität erzeugen kann.
Der ursprüngliche Schätzer hatte eine andere Möglichkeit, die Join-Kardinalität zu schätzen, wenn Histogramminformationen entweder nicht verfügbar waren oder heuristisch als minderwertig bewertet wurden. Dies wird als frequenzbasierte Schätzung bezeichnet und verwendet die folgenden Definitionen:
- C – die Kardinalität (Anzahl der Zeilen)
- D – die Anzahl unterschiedlicher Werte
- F – die Häufigkeit (Anzahl der Zeilen) für jeden einzelnen Wert
- Beachten Sie C =D * F per Definition
Die Auswirkung eines Equijoins der Relationen R1 und R2 auf jede dieser Eigenschaften ist wie folgt:
- F' =F1 * F2
- D' =MIN(D1; D2) – Eindämmung vorausgesetzt
- C' =D' * F' (wieder per Definition)
Wir sind nach C', der Kardinalität des Equijoins. Ersetzen von D' und F' in der Formel und Erweitern:
- C' =D' * F'
- C' =MIN(D1; D2) * F1 * F2
- C' =MIN(D1 * F1 * F2; D2 * F1 * F2)
- jetzt, da C1 =D1 * F1 und C2 =D2 * F2:
- C' =MIN(C1 * F2, C2 * F1)
- schließlich, da F =C/D (ebenfalls per Definition):
- C' =MIN(C1 * C2 / D2; C2 * C1 / D1)
Da C1 * C2 das Produkt der beiden Eingabekardinalitäten ist (kartesischer Join), ist klar, dass das Minimum dieser Ausdrücke derjenige mit der höheren Anzahl unterschiedlicher Werte ist:
- C' =(C1 * C2) / MAX(D1; D2)
Für den Fall, dass dies alles ein wenig abstrakt erscheint, besteht eine intuitive Möglichkeit, über die frequenzbasierte Equijoin-Schätzung nachzudenken, darin, zu berücksichtigen, dass jeder unterschiedliche Wert aus einer Relation mit einer Anzahl von Zeilen (der durchschnittlichen Häufigkeit) in der anderen Relation verknüpft wird. Wenn wir 5 unterschiedliche Werte auf der einen Seite haben und jeder unterschiedliche Wert auf der anderen Seite im Durchschnitt dreimal vorkommt, ist eine vernünftige (aber grobe) Equijoin-Schätzung 5 * 3 =15.
Das ist nicht ganz so breit gefächert, wie es scheinen mag. Denken Sie daran, dass die Zahlen für Kardinalität und unterschiedliche Werte oben nicht aus der gesamten Beziehung stammen, sondern nur aus den Übereinstimmungsschritten über dem Minimum. Daher grobe Abschätzung zwischen Minimal- und Maximalwerten.
Häufigkeitsberechnung
Wir können jeden dieser Parameter aus den hervorgehobenen Histogrammschritten erhalten.
- Die Kardinalität C ist die Summe von
EQ_ROWSundRANGE_ROWS. - Die Anzahl unterschiedlicher Werte D ist die Summe von
DISTINCT_RANGE_ROWSplus eins für jeden Schritt.
Die Kardinalität C1 des übereinstimmenden FactResellerSales Schritte ist die Summe der markierten Zellen:
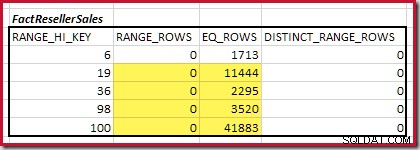
Dies ergibt C1 =59.142 Zeilen.
Es gibt keine eindeutigen Bereichszeilen, daher stammen die einzigen eindeutigen Werte aus den vier Stufengrenzen selbst, was D1 =4 ergibt .
Für die zweite Tabelle:
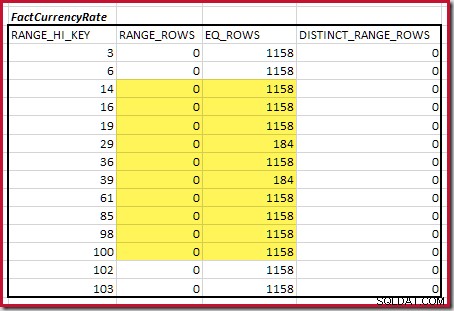
Das ergibt C2 =9.632 . Auch hier gibt es keine eindeutigen Bereichszeilen, daher stammen die eindeutigen Werte aus den zehn Stufengrenzen, D2 =10.
Ausfüllen der Equijoin-Schätzung
Wir haben jetzt alle Zahlen, die wir für die Equijoin-Formel brauchen:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(59142 * 9632) / MAX(4; 10)
- C' =569655744 / 10
- C' =56.965.574,4
Denken Sie daran, dass dies der Beitrag der Histogrammschritte über der minimalen übereinstimmenden Grenze ist. Um die Join-Kardinalitätsschätzung zu vervollständigen, müssen wir den Beitrag der minimalen Übereinstimmungsschrittwerte hinzufügen, der 1.713 * 1.158 =1.983.654 Zeilen betrug.
Die endgültige Equijoin-Schätzung beträgt daher 56.965.574,4 + 1.983.654 =58.949.228,4 Zeilen oder 58.949.200 auf sechs signifikante Stellen.
Dieses Ergebnis wird im geschätzten Ausführungsplan für die Quellabfrage bestätigt:
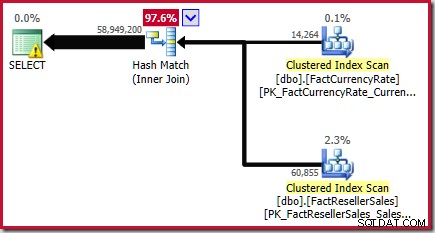
Wie im Weißbuch erwähnt, ist dies keine gute Schätzung. Die tatsächliche Anzahl der von dieser Abfrage zurückgegebenen Zeilen beträgt 70.470.090 . Die vom ursprünglichen ("alten") Kardinalitätsschätzer erstellte Schätzung – unter Verwendung einer schrittweisen Histogrammausrichtung – beträgt 70.470.100 Zeilen.
Mit der feineren Methode sind oft bessere Ergebnisse möglich, aber nur, wenn die Statistiken die zugrunde liegende Datenverteilung sehr gut darstellen. Dabei geht es nicht nur darum, die Statistiken auf dem neuesten Stand zu halten oder die vollständige Scanpopulation zu verwenden. Der Algorithmus, der verwendet wird, um Informationen in maximal 201 Histogrammschritte zu packen, ist nicht perfekt, und in jedem Fall sind viele reale Datenverteilungen einfach nicht in der Lage, eine solche Histogrammtreue zu erreichen. Im Durchschnitt sollten die Leute feststellen, dass die gröbere Methode vollkommen angemessene Schätzungen und eine größere Stabilität mit dem neuen CE liefert.
Zweites Beispiel
Dies baut ein wenig auf dem vorherigen Beispiel auf und erfordert keinen Download der Beispieldatenbank.
DROP TABLE IF EXISTS
dbo.R1,
dbo.R2;
CREATE TABLE dbo.R1 (n integer NOT NULL);
CREATE TABLE dbo.R2 (n integer NOT NULL);
INSERT dbo.R1
(n)
VALUES
(1), (2), (3), (4), (5), (6), (7), (8), (9), (10),
(6), (6), (6), (6), (6), (6), (6), (6), (6), (6),
(6), (6), (6), (6), (6), (6), (6), (6), (6);
INSERT dbo.R2
(n)
VALUES
(5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15),
(10), (10);
CREATE STATISTICS stats_n ON dbo.R1 (n) WITH FULLSCAN;
CREATE STATISTICS stats_n ON dbo.R2 (n) WITH FULLSCAN; Die Histogramme, die übereinstimmende Mindestschritte zeigen, sind:
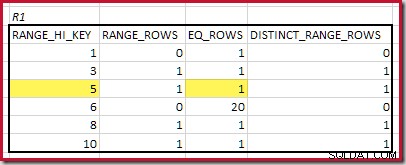
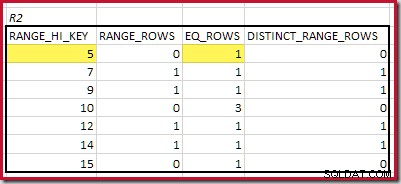
Der niedrigste RANGE_HI_KEY das passt ist 5. Der Wert von EQ_ROWS ist in beiden 1, also ist die geschätzte Equijoin-Kardinalität 1 * 1 =1 Zeile .
Der höchste übereinstimmende RANGE_HI_KEY ist 10. Hervorheben der R1-Histogrammzeilen für eine grobe frequenzbasierte Schätzung:
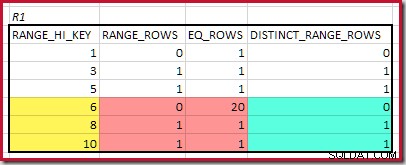
Summieren von EQ_ROWS und RANGE_ROWS ergibt C1 =24 . Die Anzahl der unterschiedlichen Zeilen beträgt 2 DISTINCT_RANGE_ROWS (unterschiedliche Werte zwischen Stufen) plus 3 für die unterschiedlichen Werte, die jeder Stufengrenze zugeordnet sind, was D1 =5 ergibt .
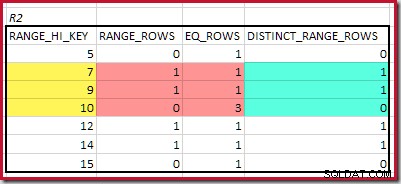
Für R2 Summieren von EQ_ROWS und RANGE_ROWS ergibt C2 =7 . Die Anzahl der unterschiedlichen Zeilen beträgt 2 DISTINCT_RANGE_ROWS (unterschiedliche Werte zwischen Stufen) plus 3 für die unterschiedlichen Werte, die jeder Stufengrenze zugeordnet sind, was D2 =5 ergibt .
Die Equijoin-Schätzung C' ist:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(24 * 7) / 5
- C' =33,6
Hinzufügen in der 1. Zeile aus der Mindestschrittübereinstimmung ergibt eine Gesamtschätzung von 34,6 Zeilen für den Equijoin:
SELECT
R1.n,
R2.n
FROM dbo.R1 AS R1
JOIN dbo.R2 AS R2
ON R2.n = R1.n; Der geschätzte Ausführungsplan zeigt eine Schätzung, die unserer Berechnung entspricht:

Das ist nicht ganz richtig, aber der "Legacy"-Kardinalitätsschätzer ist nicht besser und schätzt 15,25 Zeilen gegenüber 27 tatsächlichen:

Für eine vollständige Behandlung müssten wir auch einen abschließenden Beitrag von übereinstimmenden Histogramm-Nullschritten hinzufügen, aber dies ist ungewöhnlich für Equijoins (die normalerweise geschrieben werden, um Nullen abzulehnen) und eine relativ einfache Erweiterung für den interessierten Leser.
Abschließende Gedanken
Hoffentlich füllen die Details in dem Artikel ein paar Lücken für alle, die sich jemals über "grobe Ausrichtung" gewundert haben. Beachten Sie, dass dies nur eine kleine Komponente im Kardinalitätsschätzer ist. Es gibt mehrere andere wichtige Konzepte und Algorithmen, die für die Join-Schätzung verwendet werden, insbesondere die Art und Weise, wie Nicht-Join-Prädikate bewertet werden und wie komplexere Joins gehandhabt werden. Viele der wirklich wichtigen Punkte werden im White Paper ziemlich gut behandelt.