Im Jahr 2014 habe ich einen Artikel mit dem Titel Performance Tuning the Whole Query Plan geschrieben. Es untersuchte Möglichkeiten, eine relativ kleine Anzahl unterschiedlicher Werte aus einem mäßig großen Datensatz zu finden, und kam zu dem Schluss, dass eine rekursive Lösung optimal sein könnte. Dieser Folgebeitrag greift die Frage für SQL Server 2019 erneut auf und verwendet eine größere Anzahl von Zeilen.
Testumgebung
Ich werde die 50-GB-Stack Overflow 2013-Datenbank verwenden, aber jede große Tabelle mit einer geringen Anzahl unterschiedlicher Werte würde ausreichen.
Ich werde nach unterschiedlichen Werten in BountyAmount suchen Spalte der dbo.Votes Tabelle, angezeigt in aufsteigender Reihenfolge der Prämienbeträge. Die Votes-Tabelle hat knapp 53 Millionen Zeilen (52.928.720 um genau zu sein). Es gibt nur 19 verschiedene Prämienbeträge, einschließlich NULL .
Die Stack Overflow 2013-Datenbank wird ohne Nonclustered-Indizes geliefert, um die Downloadzeit zu minimieren. Es gibt einen geclusterten Primärschlüsselindex auf der Id Spalte der dbo.Votes Tisch. Es ist auf Kompatibilität mit SQL Server 2008 (Level 100) eingestellt, aber wir beginnen mit einer moderneren Einstellung von SQL Server 2017 (Level 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Die Tests wurden auf meinem Laptop mit SQL Server 2019 CU 2 durchgeführt. Diese Maschine verfügt über vier i7-CPUs (Hyperthreading auf 8) mit einer Basisgeschwindigkeit von 2,4 GHz. Es verfügt über 32 GB RAM, wobei 24 GB für die SQL Server 2019-Instanz verfügbar sind. Der Kostenschwellenwert für Parallelität ist auf 50 festgelegt.
Jedes Testergebnis stellt das Beste aus zehn Läufen dar, mit allen erforderlichen Daten und Indexseiten im Speicher.
1. Row Store Clustered Index
Um eine Basislinie festzulegen, ist der erste Lauf eine serielle Abfrage ohne neue Indizierung (und denken Sie daran, dass dies mit der auf Kompatibilitätsgrad 140 eingestellten Datenbank erfolgt):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Dadurch wird der gruppierte Index gescannt und ein Hash-Aggregat im Zeilenmodus verwendet, um die unterschiedlichen Werte von BountyAmount zu finden :
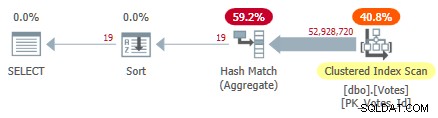 Serial Clustered Index Plan
Serial Clustered Index Plan
Dies dauert 10.500 ms zu vervollständigen, wobei die gleiche Menge an CPU-Zeit verwendet wird. Denken Sie daran, dass dies die beste Zeit über zehn Läufe mit allen Daten im Speicher ist. Automatisch erstellte Stichprobenstatistiken zum BountyAmount Spalte wurden bei der ersten Ausführung erstellt.
Etwa die Hälfte der verstrichenen Zeit wird für den Clustered Index Scan und etwa die Hälfte für das Hash Match Aggregate aufgewendet. Die Sortierung muss nur 19 Zeilen verarbeiten, sodass sie nur etwa 1 ms verbraucht. Alle Operatoren in diesem Plan verwenden die Ausführung im Zeilenmodus.
Entfernen des MAXDOP 1 Hinweis gibt einen parallelen Plan:
 Parallel Clustered Index Plan
Parallel Clustered Index Plan
Dies ist der Plan, den der Optimierer ohne Hinweise in meiner Konfiguration auswählt. Es gibt Ergebnisse in 4.200 ms zurück mit insgesamt 32.800 ms CPU (bei DOP 8).
2. Nicht gruppierter Index
Durchsuchen der gesamten Tabelle, um nur den BountyAmount zu finden scheint ineffizient, daher ist es naheliegend zu versuchen, einen Nonclustered-Index nur für die eine Spalte hinzuzufügen, die diese Abfrage benötigt:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Die Erstellung dieses Index dauert eine Weile (1:40 Minuten). Der MAXDOP 1 -Abfrage verwendet jetzt ein Stream-Aggregat, da der Optimierer den Nonclustered-Index verwenden kann, um Zeilen in BountyAmount darzustellen Bestellung:
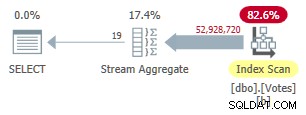 Serial Nonclustered Row Mode Plan
Serial Nonclustered Row Mode Plan
Dies dauert 9.300 ms (verbraucht die gleiche Menge an CPU-Zeit). Eine nützliche Verbesserung gegenüber den ursprünglichen 10.500 ms, aber kaum weltbewegend.
Entfernen des MAXDOP 1 hint gibt einen parallelen Plan mit lokaler (per-thread) Aggregation:
 Parallel Nonclustered Row Mode Plan
Parallel Nonclustered Row Mode Plan
Dies wird in 3.400 ms ausgeführt mit 25.800 ms CPU-Zeit. Vielleicht können wir mit Zeilen- oder Seitenkomprimierung auf dem neuen Index besser arbeiten, aber ich möchte zu interessanteren Optionen übergehen.
3. Stapelmodus im Zeilenspeicher (BMOR)
Setzen Sie nun die Datenbank in den SQL Server 2019-Kompatibilitätsmodus mit:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Dies gibt dem Optimierer die Freiheit, den Stapelmodus für den Zeilenspeicher zu wählen, wenn er dies für sinnvoll hält. Dies kann einige der Vorteile der Ausführung im Stapelmodus bereitstellen, ohne dass ein Spaltenspeicherindex erforderlich ist. Ausführliche technische Details und undokumentierte Optionen finden Sie in Dmitry Pilugins ausgezeichnetem Artikel zu diesem Thema.
Leider wählt der Optimierer immer noch die Ausführung im vollständigen Zeilenmodus unter Verwendung von Stream-Aggregaten sowohl für die seriellen als auch für die parallelen Testabfragen. Um einen Stapelmodus für den Ausführungsplan des Zeilenspeichers zu erhalten, können wir einen Hinweis hinzufügen, um die Aggregation mithilfe von Hash-Matches zu fördern (die im Stapelmodus ausgeführt werden können):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Dies gibt uns einen Plan, bei dem alle Operatoren im Stapelmodus ausgeführt werden:
 Serieller Stapelmodus auf Zeilenspeicherplan
Serieller Stapelmodus auf Zeilenspeicherplan
Ergebnisse werden in 2.600 ms zurückgegeben (alle CPU wie gewohnt). Das ist schon schneller als die parallele Zeilenmodusplan (3.400 ms verstrichen) bei deutlich geringerem CPU-Verbrauch (2.600 ms gegenüber 25.800 ms).
Entfernen des MAXDOP 1 hint (aber behält HASH GROUP ) ergibt einen parallelen Stapelmodus für den Zeilenspeicherplan:
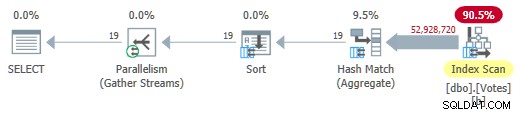 Parallel-Batch-Modus im Zeilenspeicherplan
Parallel-Batch-Modus im Zeilenspeicherplan
Dies läuft in nur 725 ms mit 5.700 ms CPU.
4. Stapelmodus im Column Store
Der parallele Stapelmodus für das Ergebnis der Zeilenspeicherung ist eine beeindruckende Verbesserung. Wir können sogar noch besser werden, indem wir eine Column Store-Darstellung der Daten bereitstellen. Damit alles andere gleich bleibt, füge ich ein nonclustered hinzu Column Store Index nur für die Spalte, die wir brauchen:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Dieser wird aus dem bestehenden b-tree Nonclustered-Index gefüllt und benötigt nur 15 s zur Erstellung.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Der Optimierer wählt einen Plan im vollständigen Stapelmodus, der einen Spaltenspeicher-Indexscan enthält:
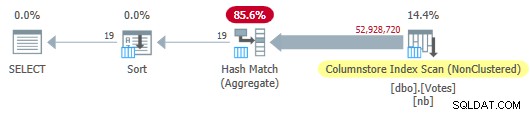 Serial Column Store Plan
Serial Column Store Plan
Dies dauert 115 ms mit der gleichen Menge an CPU-Zeit. Der Optimierer wählt diesen Plan ohne Hinweise auf meine Systemkonfiguration, da die geschätzten Kosten des Plans unter dem Kostenschwellenwert für Parallelität liegen .
Um einen parallelen Plan zu erhalten, können wir entweder die Kostenschwelle senken oder einen undokumentierten Hinweis verwenden:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); In jedem Fall lautet der parallele Plan:
 Parallel Column Store Plan
Parallel Column Store Plan
Die verstrichene Abfragezeit beträgt jetzt 30 ms , während 210 ms CPU verbraucht werden.
5. Batch-Modus im Column Store mit Push-Down
Die derzeit beste Ausführungszeit von 30 ms ist beeindruckend, insbesondere im Vergleich zu den ursprünglichen 10.500 ms. Trotzdem ist es ein bisschen schade, dass wir fast 53 Millionen Zeilen (in 58.868 Batches) vom Scan an das Hash-Match-Aggregat übergeben müssen.
Es wäre schön, wenn SQL Server die Aggregation nach unten in den Scan verschieben und einfach eindeutige Werte direkt aus dem Spaltenspeicher zurückgeben könnte. Sie denken vielleicht, dass wir DISTINCT ausdrücken müssen als GROUP BY um Grouped Aggregate Pushdown zu erhalten, aber das ist logischerweise überflüssig und nicht die ganze Geschichte.
Bei der aktuellen SQL Server-Implementierung müssen wir tatsächlich ein Aggregat berechnen Aggregat-Pushdown zu aktivieren. Darüber hinaus müssen wir benutzen das aggregierte Ergebnis irgendwie, oder der Optimierer wird es einfach als unnötig entfernen.
Eine Möglichkeit, die Abfrage zu schreiben, um einen aggregierten Pushdown zu erreichen, besteht darin, eine logisch redundante sekundäre Sortieranforderung hinzuzufügen:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Der Serienplan lautet jetzt:
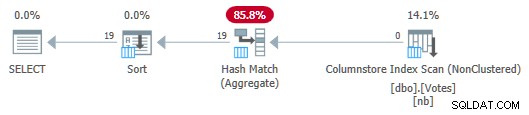 Serial Column Store Plan with Aggregate Pushdown
Serial Column Store Plan with Aggregate Pushdown
Beachten Sie, dass keine Zeilen vom Scan an das Aggregat übergeben werden! Unter der Decke Teilaggregate des BountyAmount -Werte und ihre zugehörigen Zeilenzahlen werden an das Hash-Match-Aggregat übergeben, das die Teilaggregate summiert, um das erforderliche endgültige (globale) Aggregat zu bilden. Dies ist sehr effizient, wie die verstrichene Zeit von 13 ms bestätigt (alles davon ist CPU-Zeit). Zur Erinnerung:Der vorherige Serienplan dauerte 115 ms.
Um das Set zu vervollständigen, können wir auf die gleiche Weise wie zuvor eine parallele Version erhalten:
 Parallel Column Store Plan with Aggregate Pushdown
Parallel Column Store Plan with Aggregate Pushdown
Dies dauert 7ms insgesamt 40 ms CPU verwenden.
Es ist eine Schande, dass wir ein Aggregat berechnen und verwenden müssen, das wir nicht brauchen, nur um heruntergedrückt zu werden. Vielleicht wird dies in Zukunft so verbessert, dass DISTINCT und GROUP BY ohne Aggregate können zum Scannen nach unten geschoben werden.
6. Rekursiver gemeinsamer Tabellenausdruck im Zeilenmodus
Am Anfang habe ich versprochen, die rekursive CTE-Lösung zu überdenken, die verwendet wird, um eine kleine Anzahl von Duplikaten in einem großen Datensatz zu finden. Die Implementierung der aktuellen Anforderung mit dieser Technik ist ziemlich einfach, obwohl der Code notwendigerweise länger ist als alles, was wir bisher gesehen haben:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Die Idee hat ihre Wurzeln in einem sogenannten Index-Skip-Scan:Wir finden den niedrigsten interessierenden Wert am Anfang des aufsteigend geordneten B-Tree-Index, suchen dann den nächsten Wert in Indexreihenfolge und so weiter. Die Struktur eines B-Tree-Index macht das Auffinden des nächsthöheren Werts sehr effizient – es ist nicht erforderlich, die Duplikate zu durchsuchen.
Der einzige wirkliche Trick besteht darin, den Optimierer davon zu überzeugen, uns die Verwendung von TOP zu gestatten im „rekursiven“ Teil des CTE, um eine Kopie jedes eindeutigen Werts zurückzugeben. Bitte lesen Sie meinen vorherigen Artikel, wenn Sie eine Auffrischung der Details benötigen.
Der Ausführungsplan (allgemein erklärt von Craig Freedman hier) ist:
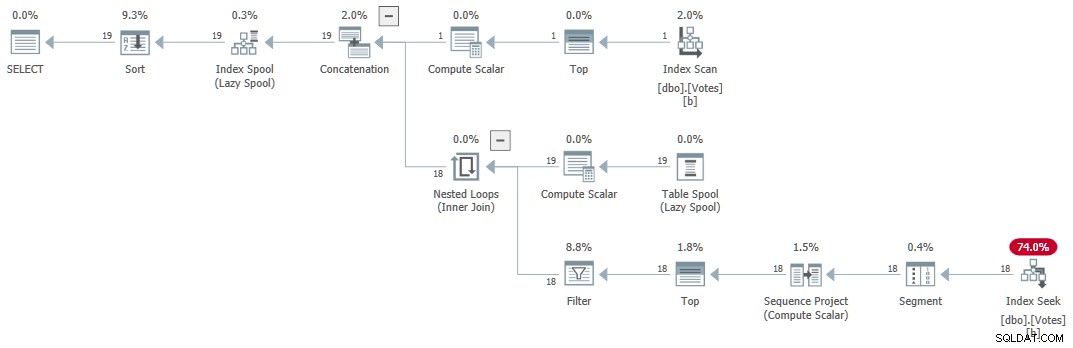 Serieller rekursiver CTE
Serieller rekursiver CTE
Die Abfrage gibt innerhalb von 1 ms korrekte Ergebnisse zurück mit 1 ms CPU, laut Sentry One Plan Explorer.
7. Iteratives T-SQL
Eine ähnliche Logik kann mit einem WHILE ausgedrückt werden Schleife. Der Code kann einfacher zu lesen und zu verstehen sein als der rekursive CTE. Es vermeidet auch, Tricks anwenden zu müssen, um die vielen Einschränkungen des rekursiven Teils eines CTE zu umgehen. Die Leistung ist bei etwa 15 ms konkurrenzfähig. Dieser Code wird aus Interesse bereitgestellt und ist nicht in der Leistungsübersichtstabelle enthalten.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Leistungsübersichtstabelle
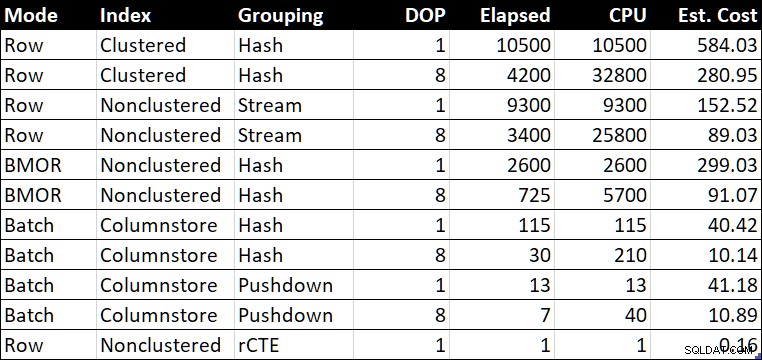 Leistungszusammenfassungstabelle (Dauer/CPU in Millisekunden)
Leistungszusammenfassungstabelle (Dauer/CPU in Millisekunden)
Die „est. Die Spalte „Kosten“ zeigt die Kostenschätzung des Optimierers für jede Abfrage, wie sie auf dem Testsystem gemeldet wird.
Abschließende Gedanken
Das Finden einer kleinen Anzahl unterschiedlicher Werte mag wie eine ziemlich spezifische Anforderung erscheinen, aber ich bin im Laufe der Jahre ziemlich häufig darauf gestoßen, normalerweise als Teil der Optimierung einer größeren Abfrage.
Die letzten Beispiele waren in der Leistung ziemlich nah dran. Viele Menschen wären mit jedem der Ergebnisse unter einer Sekunde zufrieden, je nach Priorität. Sogar das Ergebnis von 2.600 ms im seriellen Stapelmodus beim Zeilenspeichern lässt sich gut mit dem besten parallelen vergleichen Row-Mode-Pläne, was auf deutliche Beschleunigungen nur durch ein Upgrade auf SQL Server 2019 und die Aktivierung des Datenbank-Kompatibilitätsgrads 150 ankündigt. Nicht jeder wird in der Lage sein, schnell auf Column Store-Speicher umzusteigen, und es wird sowieso nicht immer die richtige Lösung sein . Der Stapelmodus für Zeilenspeicher bietet eine gute Möglichkeit, einige der Vorteile zu erzielen, die mit Spaltenspeichern möglich sind, vorausgesetzt, Sie können den Optimierer davon überzeugen, ihn zu verwenden.
Die parallele Spalte speichert das aggregierte Pushdown-Ergebnis von 57 Millionen Zeilen in 7 ms verarbeitet (unter Verwendung von 40 ms CPU) ist bemerkenswert, insbesondere in Anbetracht der Hardware. Das serielle aggregierte Pushdown-Ergebnis von 13 ms ist ebenso beeindruckend. Es wäre großartig, wenn ich kein bedeutungsloses Gesamtergebnis hinzufügen müsste, um diese Pläne zu erhalten.
Für diejenigen, die noch nicht zu SQL Server 2019 oder Column Store wechseln können, ist der rekursive CTE immer noch eine praktikable und effiziente Lösung, wenn ein geeigneter B-Tree-Index vorhanden ist und die Anzahl der benötigten unterschiedlichen Werte garantiert recht gering ist. Es wäre schön, wenn SQL Server auf einen solchen B-Tree zugreifen könnte, ohne einen rekursiven CTE schreiben zu müssen (oder einen gleichwertigen T-SQL-Code mit iterativer Schleife unter Verwendung von WHILE ).
Eine weitere mögliche Lösung für das Problem besteht darin, eine indizierte Ansicht zu erstellen. Dies wird deutliche Werte mit großer Effizienz liefern. Der Nachteil besteht wie üblich darin, dass jede Änderung an der zugrunde liegenden Tabelle die in der materialisierten Ansicht gespeicherte Zeilenanzahl aktualisieren muss.
Jede der hier vorgestellten Lösungen hat je nach Anforderung ihren Platz. Eine große Auswahl an Tools zur Verfügung zu haben, ist im Allgemeinen eine gute Sache beim Optimieren von Abfragen. Meistens würde ich mich für eine der Batch-Modus-Lösungen entscheiden, da ihre Leistung ziemlich vorhersehbar ist, egal wie viele Duplikate vorhanden sind.