Sie arbeiten mit einem Entwickler zusammen, der eine geringe Leistung für den folgenden Aufruf einer gespeicherten Prozedur meldet:
EXEC [dbo].[charge_by_date] '2/28/2013';
Sie fragen, welches Problem der Entwickler sieht, aber die einzige zusätzliche Information, die Sie hören, ist, dass es „langsam läuft“. Sie springen also auf die SQL Server-Instanz und sehen sich das tatsächliche an Ausführungsplan. Sie tun dies, weil Sie nicht nur daran interessiert sind, wie der Ausführungsplan aussieht, sondern auch, wie hoch die geschätzte und die tatsächliche Anzahl von Zeilen für den Plan sind:
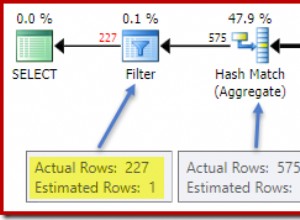
Wenn Sie sich zunächst nur die Planbetreiber ansehen, können Sie einige bemerkenswerte Details erkennen:
- Es gibt eine Warnung im Root-Operator
- Es gibt einen Tabellenscan für beide Tabellen, auf die auf Blattebene verwiesen wird (charge_jan und charge_feb), und Sie fragen sich, warum dies beide immer noch Heaps sind und keine geclusterten Indizes haben
- Sie sehen, dass nur Zeilen durch die Tabelle charge_feb fließen und nicht durch die Tabelle charge_jan
- Sie sehen parallele Zonen im Plan
Was die Warnung im Root-Iterator betrifft, fahren Sie mit der Maus darüber und sehen, dass es Warnungen zu fehlenden Indizes mit einer Empfehlung für die folgenden Indizes gibt:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Sie fragen den ursprünglichen Datenbankentwickler, warum es keinen geclusterten Index gibt, und die Antwort lautet „Ich weiß es nicht.“
Wenn Sie die Untersuchung fortsetzen, bevor Sie Änderungen vornehmen, sehen Sie sich die Registerkarte „Plan-Struktur“ im SQL Sentry-Plan-Explorer an und Sie sehen tatsächlich, dass es erhebliche Abweichungen zwischen den geschätzten und den tatsächlichen Zeilen für eine der Tabellen gibt:

Es scheint zwei Probleme zu geben:
- Eine Unterschätzung für Zeilen im charge_jan-Tabellenscan
- Eine Überschätzung für Zeilen im charge_feb-Tabellenscan
Die Kardinalitätsschätzungen sind also verzerrt, und Sie fragen sich, ob dies mit Parameter-Sniffing zusammenhängt. Sie beschließen, den kompilierten Wert des Parameters zu überprüfen und ihn mit dem Laufzeitwert des Parameters zu vergleichen, den Sie auf der Registerkarte Parameter sehen können:

Tatsächlich gibt es Unterschiede zwischen dem Laufzeitwert und dem kompilierten Wert. Sie kopieren die Datenbank in eine prod-ähnliche Testumgebung und testen dann die Ausführung der gespeicherten Prozedur zuerst mit dem Laufzeitwert 28.02.2013 und danach 31.01.2013.
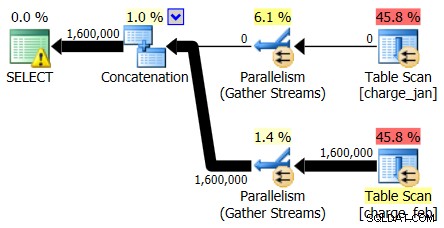
Die Pläne vom 28.02.2013 und 31.01.2013 haben identische Formen, aber unterschiedliche tatsächliche Datenflüsse. Die Plan- und Kardinalitätsschätzungen vom 28.02.2013 lauteten wie folgt:
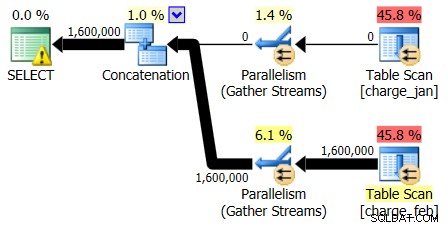

Und während der Plan vom 28.02.2013 kein Problem mit der Kardinalitätsschätzung zeigt, tut der Plan vom 31.01.2013 Folgendes:
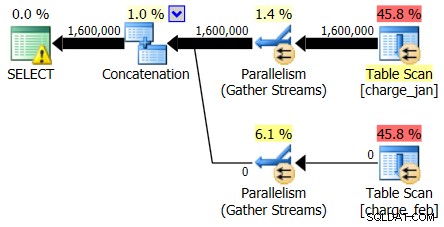

Der zweite Plan zeigt also die gleichen Über- und Unterschätzungen, nur umgekehrt zum ursprünglichen Plan, den Sie sich angesehen haben.
Sie beschließen, die vorgeschlagenen Indizes zur prod-ähnlichen Testumgebung für die Tabellen charge_jan und charge_feb hinzuzufügen und zu sehen, ob das überhaupt hilft. Wenn Sie die gespeicherten Prozeduren in der Reihenfolge Januar/Februar ausführen, sehen Sie die folgenden neuen Planformen und zugehörigen Kardinalitätsschätzungen:
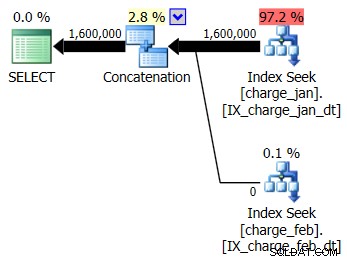

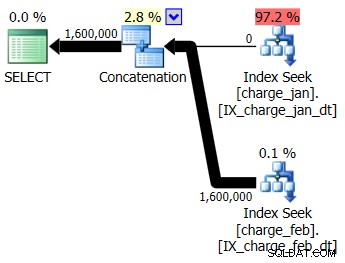

Der neue Plan verwendet eine Indexsuchoperation aus jeder Tabelle, aber Sie sehen immer noch null Zeilen, die aus einer Tabelle und nicht aus der anderen fließen, und Sie sehen immer noch Verzerrungen der Kardinalitätsschätzung basierend auf dem Parameter-Sniffing, wenn der Laufzeitwert in einem anderen Monat als der Kompilierung liegt Zeitwert.
Ihr Team hat die Richtlinie, keine Indizes hinzuzufügen, ohne dass ein ausreichender Nutzen nachgewiesen und entsprechende Regressionstests durchgeführt wurden. Sie beschließen, die soeben erstellten Nonclustered-Indizes vorerst zu entfernen. Während Sie die fehlenden clustered nicht sofort ansprechen index, entscheiden Sie, dass Sie sich später darum kümmern.
An diesem Punkt erkennen Sie, dass Sie sich die Definition der gespeicherten Prozedur genauer ansehen müssen, die wie folgt lautet:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Als nächstes sehen Sie sich die Objektdefinition charge_view an:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Die Ansicht verweist auf Gebührendaten, die nach Datum in verschiedene Tabellen unterteilt sind. Und dann fragen Sie sich, ob die Abweichung des zweiten Abfrageausführungsplans durch eine Änderung der Definition der gespeicherten Prozedur verhindert werden kann.
Wenn der Optimierer zur Laufzeit weiß, was der Wert ist, wird das Problem mit der Kardinalitätsschätzung vielleicht verschwinden und die Gesamtleistung verbessern?
Sie fahren fort und definieren den Aufruf der gespeicherten Prozedur wie folgt neu und fügen einen RECOMPILE-Hinweis hinzu (in dem Wissen, dass Sie auch gehört haben, dass dies die CPU-Auslastung erhöhen kann, aber da dies eine Testumgebung ist, können Sie es ruhig versuchen):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Anschließend führen Sie die gespeicherte Prozedur erneut aus, indem Sie den Wert vom 31.01.2013 und dann den Wert vom 28.02.2013 verwenden.
Die Form des Plans bleibt gleich, aber das Problem mit der Kardinalitätsschätzung wurde jetzt entfernt.
Die Kardinalitätsschätzungsdaten vom 31.1.2013 zeigen:

Und die Kardinalitätsschätzungsdaten vom 28.02.2013 zeigen:

Das macht Sie für einen Moment glücklich, aber dann stellen Sie fest, dass die Dauer der gesamten Abfrageausführung relativ gleich wie zuvor zu sein scheint. Sie beginnen zu zweifeln, dass der Entwickler mit Ihren Ergebnissen zufrieden sein wird. Sie haben die Verzerrung der Kardinalitätsschätzung gelöst, aber ohne die erwartete Leistungssteigerung sind Sie sich nicht sicher, ob Sie auf sinnvolle Weise geholfen haben.
An diesem Punkt erkennen Sie, dass der Abfrageausführungsplan nur eine Teilmenge der Informationen ist, die Sie möglicherweise benötigen, und Sie erweitern Ihre Untersuchung weiter, indem Sie sich die Registerkarte „Tabellen-E/A“ ansehen. Sie sehen die folgende Ausgabe für die Ausführung am 31.1.2013:

Und für die Ausführung vom 28.02.2013 sehen Sie ähnliche Daten:

An diesem Punkt fragen Sie sich, ob die Datenzugriffsvorgänge für beide Tabellen sind in jedem Plan erforderlich. Wenn der Optimierer weiß, dass Sie nur Januar-Zeilen benötigen, warum dann überhaupt auf Februar zugreifen und umgekehrt? Denken Sie auch daran, dass der Abfrageoptimierer nicht garantiert, dass es nicht gibt tatsächliche Zeilen aus den anderen Monaten in der „falschen“ Tabelle, es sei denn, solche Garantien wurden explizit über Einschränkungen für die Tabelle selbst gemacht.
Sie überprüfen die Tabellendefinitionen über sp_help für jede Tabelle und Sie sehen keine Einschränkungen, die für eine der Tabellen definiert sind.
Als Test fügen Sie also die folgenden zwei Einschränkungen hinzu:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Sie führen die gespeicherten Prozeduren erneut aus und sehen die folgenden Planformen und Kardinalitätsschätzungen.
31.01.2013 Ausführung:
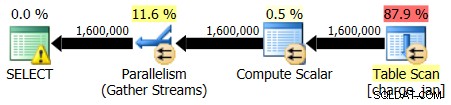

Ausführung vom 28.02.2013:


Wenn Sie sich die Tabellen-E/A erneut ansehen, sehen Sie die folgende Ausgabe für die Ausführung am 31.1.2013:

Und für die Ausführung vom 28.02.2013 sehen Sie ähnliche Daten, aber für die Tabelle charge_feb:

Denken Sie daran, dass Sie RECOMPILE noch in der Definition der gespeicherten Prozedur haben, versuchen Sie, es zu entfernen und zu sehen, ob Sie denselben Effekt sehen. Danach sehen Sie die Rückgabe des Zugriffs auf zwei Tabellen, aber ohne tatsächliche logische Lesevorgänge für die Tabelle, die keine Zeilen enthält (im Vergleich zum ursprünglichen Plan ohne die Einschränkungen). Beispielsweise zeigte die Ausführung am 31.1.2013 die folgende Tabellen-E/A-Ausgabe:

Sie beschließen, mit dem Lasttest der neuen CHECK-Einschränkungen und der RECOMPILE-Lösung fortzufahren und den Tabellenzugriff vollständig aus dem Plan (und den zugehörigen Planoperatoren) zu entfernen. Sie bereiten sich auch auf eine Debatte über den Clustered-Index-Schlüssel und einen geeigneten unterstützenden Nonclustered-Index vor, der eine breitere Gruppe von Workloads bewältigen kann, die derzeit auf die zugehörigen Tabellen zugreifen.