)
<äußere Abfrage>;
Was ein Mitglied rekursiv macht, ist ein Verweis auf den CTE-Namen. Diese Referenz stellt die Ergebnismenge der letzten Ausführung dar. Bei der ersten Ausführung des rekursiven Members stellt der Verweis auf den CTE-Namen die Ergebnismenge des Ankermembers dar. In der N-ten Ausführung, wobei N> 1, stellt der Verweis auf den CTE-Namen die Ergebnismenge der (N – 1) Ausführung des rekursiven Members dar. Wie bereits erwähnt, wird das rekursive Element, sobald es eine leere Menge zurückgibt, nicht erneut ausgeführt. Ein Verweis auf den CTE-Namen in der äußeren Abfrage stellt die einheitlichen Ergebnismengen der einzelnen Ausführung des Ankerelements und aller Ausführungen des rekursiven Elements dar.
Der folgende Code implementiert die oben erwähnte Aufgabe, den Teilbaum der Mitarbeiter für einen bestimmten Eingabemanager zurückzugeben, wobei in diesem Beispiel die Mitarbeiter-ID 3 als Stammmitarbeiter übergeben wird:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C;
Die Ankerabfrage wird nur einmal ausgeführt und gibt die Zeile für den eingegebenen Root-Mitarbeiter zurück (in unserem Fall Mitarbeiter 3).
Die rekursive Abfrage verbindet die Gruppe der Mitarbeiter der vorherigen Ebene – dargestellt durch den Verweis auf den CTE-Namen, mit dem Alias M für Manager – mit ihren direkten Untergebenen aus der Employees-Tabelle, mit dem Alias S für Untergebene. Das Join-Prädikat ist S.mgrid =M.empid, was bedeutet, dass der mgrid-Wert des Untergebenen gleich dem empid-Wert des Managers ist. Die rekursive Abfrage wird wie folgt viermal ausgeführt:
- Untergebene von Mitarbeiter 3 zurückgeben; Ausgabe:Mitarbeiter 7
- Untergebene von Mitarbeiter 7 zurückgeben; Output:Mitarbeiter 9 und 11
- Untergebene der Mitarbeiter 9 und 11 zurückgeben; Ausgang:12, 13 und 14
- Untergebene der Mitarbeiter 12, 13 und 14 zurückgeben; Ausgabe:leere Menge; Rekursion stoppt
Der Verweis auf den CTE-Namen in der äußeren Abfrage stellt die vereinheitlichten Ergebnisse der einzelnen Ausführung der Ankerabfrage (Mitarbeiter 3) mit den Ergebnissen aller Ausführungen der rekursiven Abfrage (Mitarbeiter 7, 9, 11, 12, 13 und 14). Dieser Code generiert die folgende Ausgabe:
empid mgrid empname
------ ------ --------
3 1 Ina
7 3 Aaron
9 7 Rita
11 7 Gabriel
12 9 Emilia
13 9 Michael
14 9 Didi
Ein häufiges Problem bei Programmierlösungen ist außer Kontrolle geratener Code wie Endlosschleifen, die normalerweise durch einen Fehler verursacht werden. Bei rekursiven CTEs könnte ein Fehler zu einer Runway-Ausführung des rekursiven Members führen. Angenommen, Sie hätten in unserer Lösung zur Rückgabe der Untergebenen eines Eingabemitarbeiters einen Fehler im Join-Prädikat des rekursiven Mitglieds. Anstatt ON S.mgrid =M.empid zu verwenden, haben Sie ON S.mgrid =S.mgrid verwendet, etwa so:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C;
Wenn mindestens ein Mitarbeiter mit einer nicht leeren Manager-ID in der Tabelle vorhanden ist, gibt die Ausführung des rekursiven Members weiterhin ein nicht leeres Ergebnis zurück. Denken Sie daran, dass die implizite Beendigungsbedingung für das rekursive Element darin besteht, dass seine Ausführung eine leere Ergebnismenge zurückgibt. Wenn es ein nicht leeres Resultset zurückgibt, führt SQL Server es erneut aus. Ihnen ist klar, dass SQL Server, wenn es keinen Mechanismus zum Einschränken der rekursiven Ausführungen hätte, das rekursive Element einfach für immer wiederholt ausführen würde. Als Sicherheitsmaßnahme unterstützt T-SQL eine MAXRECURSION-Abfrageoption, die die maximal zulässige Anzahl von Ausführungen des rekursiven Members begrenzt. Standardmäßig ist dieses Limit auf 100 festgelegt, aber Sie können es auf jeden nicht negativen SMALLINT-Wert ändern, wobei 0 kein Limit darstellt. Das Festlegen der maximalen Rekursionsgrenze auf einen positiven Wert N bedeutet, dass die N + 1 versuchte Ausführung des rekursiven Members mit einem Fehler abgebrochen wird. Wenn Sie beispielsweise den obigen fehlerhaften Code unverändert ausführen, verlassen Sie sich auf das standardmäßige maximale Rekursionslimit von 100, sodass die 101-Ausführung des rekursiven Members fehlschlägt:
empid mgrid empname
------ ------ --------
3 1 Ina
2 1 Eitan
3 1 Ina
...
Msg 530, Level 16, State 1, Line 121
Die Anweisung wurde beendet. Die maximale Rekursion 100 wurde vor Abschluss der Anweisung erschöpft.
Nehmen wir an, dass in Ihrer Organisation davon ausgegangen werden kann, dass die Mitarbeiterhierarchie 6 Führungsebenen nicht überschreiten wird. Sie können das maximale Rekursionslimit von 100 auf eine viel kleinere Zahl reduzieren, z. B. 10, um auf der sicheren Seite zu sein, wie folgt:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10);
Wenn es jetzt einen Fehler gibt, der zu einer außer Kontrolle geratenen Ausführung des rekursiven Members führt, wird er bei der 11. versuchten Ausführung des rekursiven Members statt bei der 101. Ausführung entdeckt:
empid mgrid empname
------ ------ --------
3 1 Ina
2 1 Eitan
3 1 Ina
...
Msg 530, Level 16, State 1, Line 149
Die Anweisung wurde beendet. Die maximale Rekursion 10 wurde vor Abschluss der Anweisung erschöpft.
Es ist wichtig zu beachten, dass die maximale Rekursionsgrenze hauptsächlich als Sicherheitsmaßnahme verwendet werden sollte, um die Ausführung von fehlerhaftem außer Kontrolle geratenem Code abzubrechen. Denken Sie daran, dass bei Überschreitung des Limits die Ausführung des Codes mit einem Fehler abgebrochen wird. Sie sollten diese Option nicht verwenden, um die Anzahl der zu besuchenden Ebenen zu Filterzwecken zu begrenzen. Sie möchten nicht, dass ein Fehler generiert wird, wenn es kein Problem mit dem Code gibt.
Zu Filterzwecken können Sie die Anzahl der programmgesteuert zu besuchenden Ebenen begrenzen. Sie definieren eine Spalte namens lvl, die die Ebenennummer des aktuellen Mitarbeiters im Vergleich zum eingegebenen Root-Mitarbeiter nachverfolgt. In der Ankerabfrage setzen Sie die lvl-Spalte auf die Konstante 0. In der rekursiven Abfrage setzen Sie sie auf den lvl-Wert des Managers plus 1. Um so viele Ebenen unterhalb des Eingabestamms wie @maxlevel zu filtern, fügen Sie das Prädikat M.lvl <@ hinzu. maxlevel in die ON-Klausel der rekursiven Abfrage. Der folgende Code gibt beispielsweise Mitarbeiter 3 und zwei Ebenen von Untergebenen von Mitarbeiter 3 zurück:
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C;
Diese Abfrage generiert die folgende Ausgabe:
empid mgrid empname lvl
------ ------ -------- ----
3 1 Ina 0
7 3 Aaron 1
9 7 Rita 2
11 7 Gabriel 2
Standard-SEARCH- und CYCLE-Klauseln
Der ISO/IEC-SQL-Standard definiert zwei sehr leistungsfähige Optionen für rekursive CTEs. Eine ist eine Klausel namens SEARCH, die die rekursive Suchreihenfolge steuert, und eine andere ist eine Klausel namens CYCLE, die Zyklen in den durchlaufenen Pfaden identifiziert. Hier ist die Standard-Syntax für die beiden Klauseln:
7.18
Funktion
Geben Sie die Generierung von Sortier- und Zykluserkennungsinformationen im Ergebnis rekursiver Abfrageausdrücke an.
Formatieren
::=
[ ]
AS [ ]
::=
| |
::=
SEARCH SET
::=
DEPTH FIRST BY | BREADTH FIRST BY
::=
::=
CYCLE SET TO
DEFAULT USING
::= [ { }… ]
::=
::=
::=
::=
::=
Zum Zeitpunkt der Erstellung dieses Artikels unterstützt T-SQL diese Optionen nicht, aber unter den folgenden Links können Sie Anfragen zur Verbesserung von Funktionen finden, die um ihre zukünftige Aufnahme in T-SQL bitten, und für sie stimmen:
- Fügen Sie Unterstützung für die ISO/IEC SQL SEARCH-Klausel zu rekursiven CTEs in T-SQL hinzu
- Unterstützung für ISO/IEC SQL CYCLE-Klausel zu rekursiven CTEs in T-SQL hinzugefügt
In den folgenden Abschnitten beschreibe ich die beiden Standardoptionen und stelle auch logisch gleichwertige Alternativlösungen bereit, die derzeit in T-SQL verfügbar sind.
SEARCH-Klausel
Die Standard-SEARCH-Klausel definiert die rekursive Suchreihenfolge als BREADTH FIRST oder DEPTH FIRST durch einige spezifizierte Sortierspalten und erzeugt eine neue Sequenzspalte mit den Ordnungspositionen der besuchten Knoten. Sie geben BREADTH FIRST an, um zuerst über jede Ebene (Breite) und dann die Ebenen nach unten (Tiefe) zu suchen. Sie geben DEPTH FIRST an, um zuerst nach unten (Tiefe) und dann quer (Breite) zu suchen.
Sie geben die SEARCH-Klausel direkt vor der äußeren Abfrage an.
Ich beginne mit einem Beispiel für eine breite rekursive Suchreihenfolge. Denken Sie nur daran, dass diese Funktion in T-SQL nicht verfügbar ist, sodass Sie die Beispiele, die die Standardklauseln in SQL Server oder Azure SQL-Datenbank verwenden, nicht tatsächlich ausführen können. Der folgende Code gibt den Unterbaum von Mitarbeiter 1 zurück und fragt nach einer Breiten-Suchreihenfolge von empid, wodurch eine Sequenzspalte namens seqbreadth mit den Ordnungspositionen der besuchten Knoten erstellt wird:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth;
Hier ist die gewünschte Ausgabe dieses Codes:
empid mgrid empname seqbreadth
------ ------ -------- -----------
1 NULL David 1
2 1 Eitan 2
3 1 Ina 3
4 2 Seraph 4
5 2 Jiru 5
6 2 Steve 6
7 3 Aaron 7
8 5 Lilach 8
9 7 Rita 9
10 5 Sean 10
11 7 Gabriel 11
12 9 Emilia 12
13 9 Michael 13
14 9 Didi 14
Lassen Sie sich nicht von der Tatsache verwirren, dass die seqbreadth-Werte mit den empid-Werten identisch zu sein scheinen. Das ist nur ein Zufall, weil ich die Empid-Werte in den von mir erstellten Beispieldaten manuell zugewiesen habe.
Abbildung 2 zeigt eine grafische Darstellung der Mitarbeiterhierarchie, wobei eine gepunktete Linie die erste Reihenfolge der Breite zeigt, in der die Knoten durchsucht wurden. Die empid-Werte erscheinen direkt unter den Mitarbeiternamen, und die zugewiesenen seqbreadth-Werte erscheinen in der unteren linken Ecke jedes Felds.
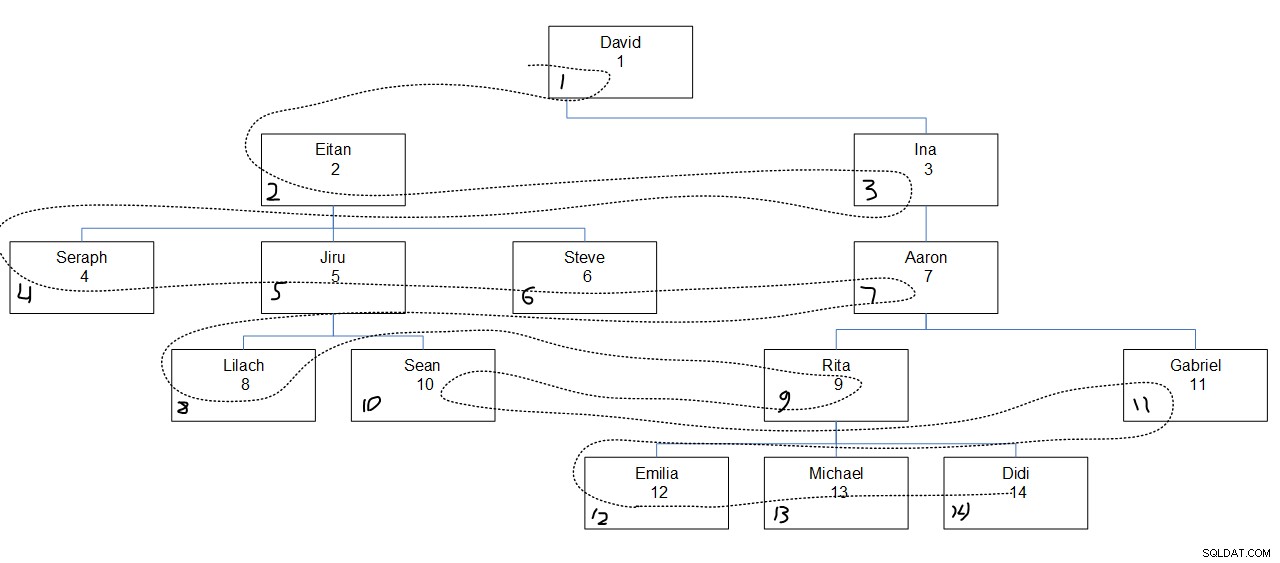 Abbildung 2:Suchbreite zuerst
Abbildung 2:Suchbreite zuerst
Interessant ist hier, dass die Knoten innerhalb jeder Ebene basierend auf der angegebenen Spaltenreihenfolge (in unserem Fall empid) unabhängig von der übergeordneten Assoziation des Knotens durchsucht werden. Beachten Sie zum Beispiel, dass auf der vierten Ebene zuerst auf Lilach zugegriffen wird, dann auf Rita, dann auf Sean und zuletzt auf Gabriel. Das liegt daran, dass unter allen Mitarbeitern in der vierten Ebene ihre Reihenfolge basierend auf ihren empirischen Werten ist. Es ist nicht so, dass Lilach und Sean nacheinander durchsucht werden sollen, weil sie direkte Untergebene desselben Managers, Jiru, sind.
Es ist ziemlich einfach, eine T-SQL-Lösung zu entwickeln, die das logische Äquivalent der Standardoption SAERCH DEPTH FIRST bietet. Sie erstellen eine Spalte mit dem Namen lvl, wie ich zuvor gezeigt habe, um die Ebene des Knotens in Bezug auf die Wurzel zu verfolgen (0 für die erste Ebene, 1 für die zweite usw.). Dann berechnen Sie die gewünschte Ergebnissequenzspalte in der äußeren Abfrage mit einer ROW_NUMBER-Funktion. Als Fensterordnung geben Sie zuerst lvl und dann die gewünschte Ordnungsspalte (in unserem Fall empid) an. Hier ist der Code der vollständigen Lösung:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth;
Als nächstes untersuchen wir die Suchreihenfolge DEPTH FIRST. Gemäß dem Standard sollte der folgende Code den Teilbaum von Mitarbeiter 1 zurückgeben und nach einer Suchreihenfolge für die Tiefe zuerst durch empid fragen, wodurch eine Sequenzspalte namens seqdepth mit den Ordinalpositionen der gesuchten Knoten erstellt wird:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth;
Es folgt die gewünschte Ausgabe dieses Codes:
empid mgrid empname seqdepth
------ ------ -------- ---------
1 NULL David 1
2 1 Eitan 2
4 2 Seraph 3
5 2 Jiru 4
8 5 Lilach 5
10 5 Sean 6
6 2 Steve 7
3 1 Ina 8
7 3 Aaron 9
9 7 Rita 10
12 9 Emilia 11
13 9 Michael 12
14 9 Didi 13
11 7 Gabriel 14
Wenn man sich die gewünschte Abfrageausgabe ansieht, ist es wahrscheinlich schwer herauszufinden, warum die Sequenzwerte so zugewiesen wurden, wie sie waren. Abbildung 3 sollte helfen. Es hat eine grafische Darstellung der Mitarbeiterhierarchie mit einer gepunkteten Linie, die die Suchreihenfolge der Tiefe zuerst widerspiegelt, mit den zugewiesenen Sequenzwerten in der unteren linken Ecke jedes Felds.
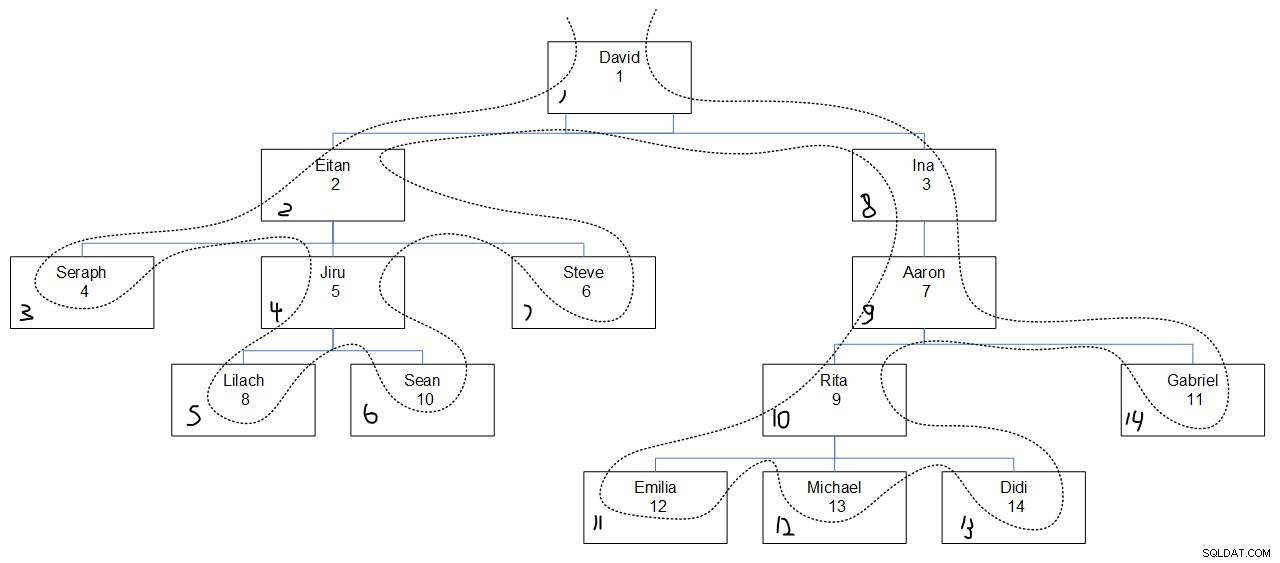 Abbildung 3:Suchtiefe zuerst
Abbildung 3:Suchtiefe zuerst
Eine T-SQL-Lösung zu entwickeln, die das logische Äquivalent zur Standardoption SEARCH DEPTH FIRST bietet, ist etwas knifflig, aber machbar. Ich beschreibe die Lösung in zwei Schritten.
In Schritt 1 berechnen Sie für jeden Knoten einen binären Sortierpfad, der aus einem Segment pro Vorfahr des Knotens besteht, wobei jedes Segment die Sortierposition des Vorfahren unter seinen Geschwistern widerspiegelt. Sie erstellen diesen Pfad ähnlich wie Sie die lvl-Spalte berechnen. Beginnen Sie also mit einer leeren Binärzeichenfolge für den Stammknoten in der Ankerabfrage. Dann verketten Sie in der rekursiven Abfrage den Pfad des übergeordneten Knotens mit der Sortierposition des Knotens unter Geschwistern, nachdem Sie ihn in ein binäres Segment konvertiert haben. Sie verwenden die ROW_NUMBER-Funktion, um die Position zu berechnen, partitioniert nach dem Elternelement (mgrid in unserem Fall) und geordnet nach der relevanten Sortierspalte (empid in unserem Fall). Sie wandeln die Zeilennummer in einen Binärwert mit ausreichender Größe um, abhängig von der maximalen Anzahl direkter Kinder, die ein Elternteil in Ihrem Diagramm haben kann. BINARY(1) unterstützt bis zu 255 Kinder pro Elternteil, BINARY(2) unterstützt 65.535, BINARY(3):16.777.215, BINARY(4):4.294.967.295. In einem rekursiven CTE müssen korrespondierende Spalten in den Anker- und rekursiven Abfragen denselben Typ und dieselbe Größe haben , stellen Sie also sicher, dass Sie den Sortierpfad in einen Binärwert gleicher Größe umwandeln.
Hier ist der Code, der Schritt 1 in unserer Lösung implementiert (unter der Annahme, dass BINARY(1) pro Segment ausreicht, was bedeutet, dass Sie nicht mehr als 255 direkte Untergebene pro Manager haben):
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C;
Dieser Code generiert die folgende Ausgabe:
empid mgrid empname sortpath
------ ------ -------- -----------
1 NULL David 0x
2 1 Eitan 0x01
3 1 Ina 0x02
7 3 Aaron 0x0201
9 7 Rita 0x020101
11 7 Gabriel 0x020102
12 9 Emilia 0x02010101
13 9 Michael 0x02010102
14 9 Didi 0x02010103
4 2 Seraph 0x0101
5 2 Jiru 0x0102
6 2 Steve 0x0103
8 5 Lilach 0x010201
10 5 Sean 0x010202
Beachten Sie, dass ich eine leere binäre Zeichenfolge als Sortierpfad für den Wurzelknoten des einzelnen Teilbaums verwendet habe, den wir hier abfragen. Falls das Ankerelement möglicherweise mehrere Unterbaumwurzeln zurückgeben kann, beginnen Sie einfach mit einem Segment, das auf einer ROW_NUMBER-Berechnung in der Ankerabfrage basiert, ähnlich wie Sie es in der rekursiven Abfrage berechnen. In einem solchen Fall wird Ihr Sortierpfad um ein Segment länger.
Was in Schritt 2 noch zu tun ist, ist, die gewünschte Ergebnisspalte seqdepth zu erstellen, indem Zeilennummern berechnet werden, die in der äußeren Abfrage nach sortpath geordnet sind, so
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth;
Diese Lösung ist das logische Äquivalent zur Verwendung der zuvor gezeigten Standardoption SEARCH DEPTH FIRST zusammen mit der gewünschten Ausgabe.
Sobald Sie eine Sequenzspalte haben, die die Suchreihenfolge der Tiefe zuerst widerspiegelt (in unserem Fall seqdepth), können Sie mit etwas mehr Aufwand eine sehr schöne visuelle Darstellung der Hierarchie erstellen. Sie benötigen auch die oben erwähnte lvl-Spalte. Sie ordnen die äußere Abfrage nach der Sequenzspalte. Sie geben ein Attribut zurück, das Sie verwenden möchten, um den Knoten darzustellen (z. B. empname in unserem Fall), dem eine Zeichenfolge vorangestellt ist (z. B. ' | '), die lvl-mal repliziert wird. Hier ist der vollständige Code, um eine solche visuelle Darstellung zu erreichen:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth;
Dieser Code generiert die folgende Ausgabe:
empid seqdepth emp
------ --------- --------------------
1 1 David
2 2 | Eitan
4 3 | | Seraph
5 4 | | Jiru
8 5 | | | Lilach
10 6 | | | Sean
6 7 | | Steve
3 8 | Ina
7 9 | | Aaron
9 10 | | | Rita
12 11 | | | | Emilia
13 12 | | | | Michael
14 13 | | | | Didi
11 14 | | | Gabriel
Das ist ziemlich cool!
CYCLE-Klausel
Graphstrukturen können Zyklen haben. Diese Zyklen können gültig oder ungültig sein. Ein Beispiel für gültige Zyklen ist ein Diagramm, das Autobahnen und Straßen darstellt, die Städte und Gemeinden verbinden. Das wird als zyklischer Graph bezeichnet . Umgekehrt sollte ein Diagramm, das eine Mitarbeiterhierarchie darstellt, wie in unserem Fall, keine Zyklen haben. Das wird als azyklisch bezeichnet Graph. Nehmen Sie jedoch an, dass Sie aufgrund einer fehlerhaften Aktualisierung unbeabsichtigt mit einem Zyklus enden. Angenommen, Sie aktualisieren versehentlich die Manager-ID des CEO (Mitarbeiter 1) auf Mitarbeiter 14, indem Sie den folgenden Code ausführen:
UPDATE Employees
SET mgrid = 14
WHERE empid = 1;
Sie haben jetzt einen ungültigen Zyklus in der Mitarbeiterhierarchie.
Unabhängig davon, ob Zyklen gültig oder ungültig sind, wenn Sie die Graphstruktur durchlaufen, möchten Sie sicherlich nicht wiederholt einen zyklischen Pfad verfolgen. In beiden Fällen möchten Sie die Verfolgung eines Pfads beenden, sobald ein nicht erstes Vorkommen desselben Knotens gefunden wird, und einen solchen Pfad als zyklisch markieren.
Was passiert also, wenn Sie einen Graphen mit Zyklen mit einer rekursiven Abfrage abfragen, ohne dass ein Mechanismus vorhanden ist, um diese zu erkennen? Dies hängt von der Implementierung ab. In SQL Server erreichen Sie irgendwann das maximale Rekursionslimit, und Ihre Abfrage wird abgebrochen. Angenommen, Sie haben beispielsweise das obige Update ausgeführt, mit dem der Zyklus eingeführt wurde, versuchen Sie, die folgende rekursive Abfrage auszuführen, um den Teilbaum von Mitarbeiter 1 zu identifizieren:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C;
Da dieser Code kein explizites maximales Rekursionslimit festlegt, wird das Standardlimit von 100 angenommen. SQL Server bricht die Ausführung dieses Codes vor dem Abschluss ab und generiert einen Fehler:
empid mgrid empname
------ ------ --------
1 14 David
2 1 Eitan
3 1 Ina
7 3 Aaron
9 7 Rita
11 7 Gabriel
12 9 Emilia
13 9 Michael
14 9 Didi
1 14 David
2 1 Eitan
3 1 Ina
7 3 Aaron
...
Msg 530, Level 16, State 1, Line 432
Die Anweisung wurde beendet. Die maximale Rekursion 100 wurde vor Abschluss der Anweisung erschöpft.
Der SQL-Standard definiert eine Klausel namens CYCLE für rekursive CTEs, die es Ihnen ermöglicht, mit Zyklen in Ihrem Diagramm umzugehen. Sie geben diese Klausel direkt vor der äußeren Abfrage an. Wenn auch eine SEARCH-Klausel vorhanden ist, geben Sie sie zuerst an und dann die CYCLE-Klausel. Hier ist die Syntax der CYCLE-Klausel:
CYCLE
SET TO DEFAULT
USING
Die Erkennung eines Zyklus basiert auf der angegebenen Zyklusspaltenliste . In unserer Mitarbeiterhierarchie möchten Sie beispielsweise wahrscheinlich die Empid-Spalte für diesen Zweck verwenden. Beim zweiten Auftreten des gleichen empid-Wertes wird ein Zyklus erkannt und die Abfrage verfolgt einen solchen Weg nicht weiter. Sie geben eine neue Zyklusmarkierungsspalte an die anzeigt, ob ein Zyklus gefunden wurde oder nicht, und Ihre eigenen Werte als Zyklusmarkierung und Nicht-Zyklus-Markierung Werte. Dies könnten beispielsweise 1 und 0 oder „Ja“ und „Nein“ oder andere Werte Ihrer Wahl sein. In der USING-Klausel geben Sie einen neuen Array-Spaltennamen an, der den Pfad der bisher gefundenen Knoten enthält.
So würden Sie eine Anfrage nach Untergebenen eines Input-Root-Mitarbeiters behandeln, mit der Möglichkeit, Zyklen basierend auf der Empid-Spalte zu erkennen, wobei 1 in der Zyklusmarkierungsspalte angezeigt wird, wenn ein Zyklus erkannt wird, und andernfalls 0:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C;
Hier ist die gewünschte Ausgabe dieses Codes:
empid mgrid empname cycle
------ ------ -------- ------
1 14 David 0
2 1 Eitan 0
3 1 Ina 0
7 3 Aaron 0
9 7 Rita 0
11 7 Gabriel 0
12 9 Emilia 0
13 9 Michael 0
14 9 Didi 0
1 14 David 1
4 2 Seraph 0
5 2 Jiru 0
6 2 Steve 0
8 5 Lilach 0
10 5 Sean 0
T-SQL unterstützt derzeit die CYCLE-Klausel nicht, aber es gibt eine Problemumgehung, die ein logisches Äquivalent bietet. Es beinhaltet drei Schritte. Denken Sie daran, dass Sie zuvor einen binären Sortierpfad erstellt haben, um die rekursive Suchreihenfolge zu handhaben. Auf ähnliche Weise bauen Sie als ersten Schritt in der Lösung einen zeichenfolgenbasierten Vorfahrenpfad auf, der aus den Knoten-IDs (in unserem Fall Mitarbeiter-IDs) der Vorfahren besteht, die zum aktuellen Knoten führen, einschließlich des aktuellen Knotens. Sie möchten Trennzeichen zwischen den Knoten-IDs, einschließlich eines am Anfang und eines am Ende.
Hier ist der Code, um einen solchen Vorfahrenpfad zu erstellen:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C;
Dieser Code generiert die folgende Ausgabe, verfolgt weiterhin zyklische Pfade und bricht daher vor dem Abschluss ab, sobald die maximale Rekursionsgrenze überschritten wird:
empid mgrid empname ancpath
------ ------ -------- -------------------
1 14 David .1.
2 1 Eitan .1.2.
3 1 Ina .1.3.
7 3 Aaron .1.3.7.
9 7 Rita .1.3.7.9.
11 7 Gabriel .1.3.7.11.
12 9 Emilia .1.3.7.9.12.
13 9 Michael .1.3.7.9.13.
14 9 Didi .1.3.7.9.14.
1 14 David .1.3.7.9.14.1.
2 1 Eitan .1.3.7.9.14.1.2.
3 1 Ina .1.3.7.9.14.1.3.
7 3 Aaron .1.3.7.9.14.1.3.7.
...
Msg 530, Level 16, State 1, Line 492
Die Anweisung wurde beendet. Die maximale Rekursion 100 wurde vor Abschluss der Anweisung erschöpft.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C;
This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle
------ ------ -------- ------------------- ------
1 14 David .1. 0
2 1 Eitan .1.2. 0
3 1 Ina .1.3. 0
7 3 Aaron .1.3.7. 0
9 7 Rita .1.3.7.9. 0
11 7 Gabriel .1.3.7.11. 0
12 9 Emilia .1.3.7.9.12. 0
13 9 Michael .1.3.7.9.13. 0
14 9 Didi .1.3.7.9.14. 0
1 14 David .1.3.7.9.14.1. 1
2 1 Eitan .1.3.7.9.14.1.2. 0
3 1 Ina .1.3.7.9.14.1.3. 1
7 3 Aaron .1.3.7.9.14.1.3.7. 1
...
Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C;
This code runs to completion, and generates the following output:
empid mgrid empname cycle
------ ------ -------- -----------
1 14 David 0
2 1 Eitan 0
3 1 Ina 0
7 3 Aaron 0
9 7 Rita 0
11 7 Gabriel 0
12 9 Emilia 0
13 9 Michael 0
14 9 Didi 0
1 14 David 1
4 2 Seraph 0
5 2 Jiru 0
6 2 Steve 0
8 5 Lilach 0
10 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees
SET mgrid = NULL
WHERE empid = 1;
Run the recursive query and you will find that there are no cycles present.
Schlussfolgerung
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.
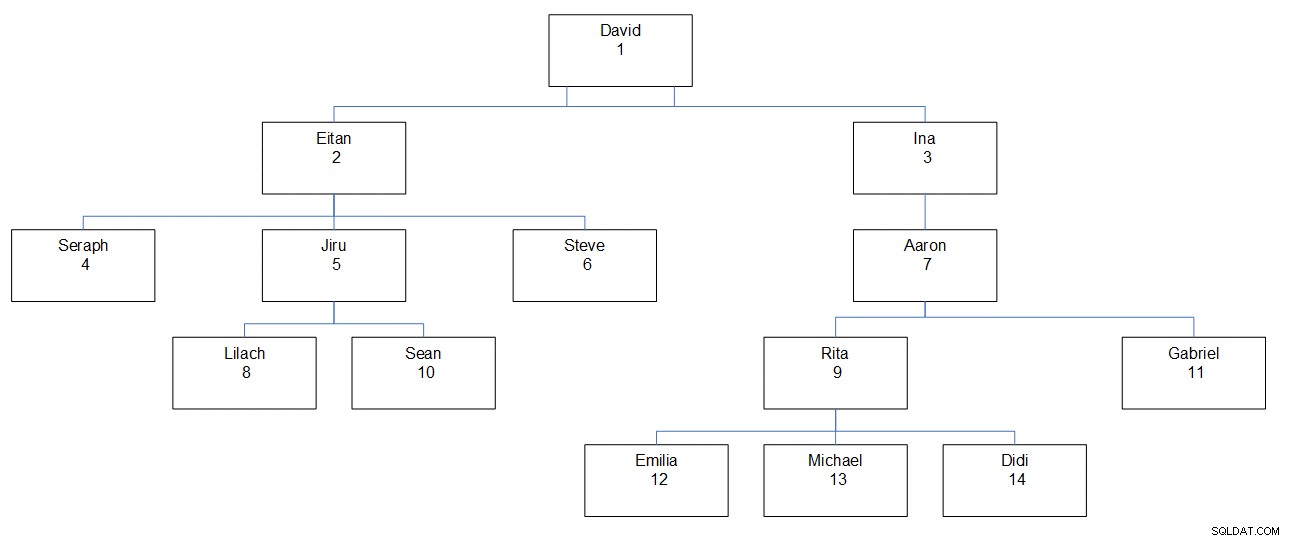 Abbildung 1:Mitarbeiterhierarchie
Abbildung 1:Mitarbeiterhierarchie