Ein Gehaltsdatenmodell ermöglicht es Ihnen, das Gehalt Ihrer Mitarbeiter einfach zu berechnen. Wie funktioniert dieses Modell?
Egal, ob Sie ein kleines oder großes Unternehmen führen, Sie benötigen eine Lösung für die Gehaltsabrechnung. Hier kommt eine Gehaltsabrechnungsanwendung ins Spiel. Und je größer das Unternehmen, desto schwieriger wird es, die Gehaltsabrechnungen der Mitarbeiter zu handhaben; hier wird eine Gehaltsabrechnungsanwendung zur Notwendigkeit. Um Ihnen zu helfen, alle für eine solche Anwendung erforderlichen Daten zu verstehen, führen wir Sie durch ein entsprechendes Datenmodell.
Sehen wir uns an, wie unser Lohndatenmodell funktioniert!
Datenmodell
Mit der Erstellung dieses Datenmodells habe ich versucht, ein Modell zu erstellen, das allgemein für jedes Unternehmen anwendbar ist. Natürlich wird es immer Unterschiede in Vorschriften, Unternehmensrichtlinien usw. geben, die eine Anpassung des Modells an die Bedürfnisse einer bestimmten Gehaltsabrechnung erfordern. Die in diesem Modell dargelegten Prinzipien sollten jedoch für die meisten Organisationen relevant sein.
Es muss beachtet werden, dass dieses Modell mit mehreren Annahmen erstellt wurde:
- Arbeitsvertraglich vereinbarte Gehälter verstehen sich pro Jahr.
- Nettogehälter (d. h. mit bestimmten abgezogenen Beträgen für Steuern usw.) werden an Mitarbeiter gezahlt.
- Gehälter werden monatlich ausgezahlt.
Das Datenmodell besteht aus vierzehn Tabellen und ist in zwei Themenbereiche unterteilt:
EmployeesSalaries
Um das Modell besser zu verstehen, ist es notwendig, jeden Themenbereich gründlich durchzugehen.
Mitarbeiter
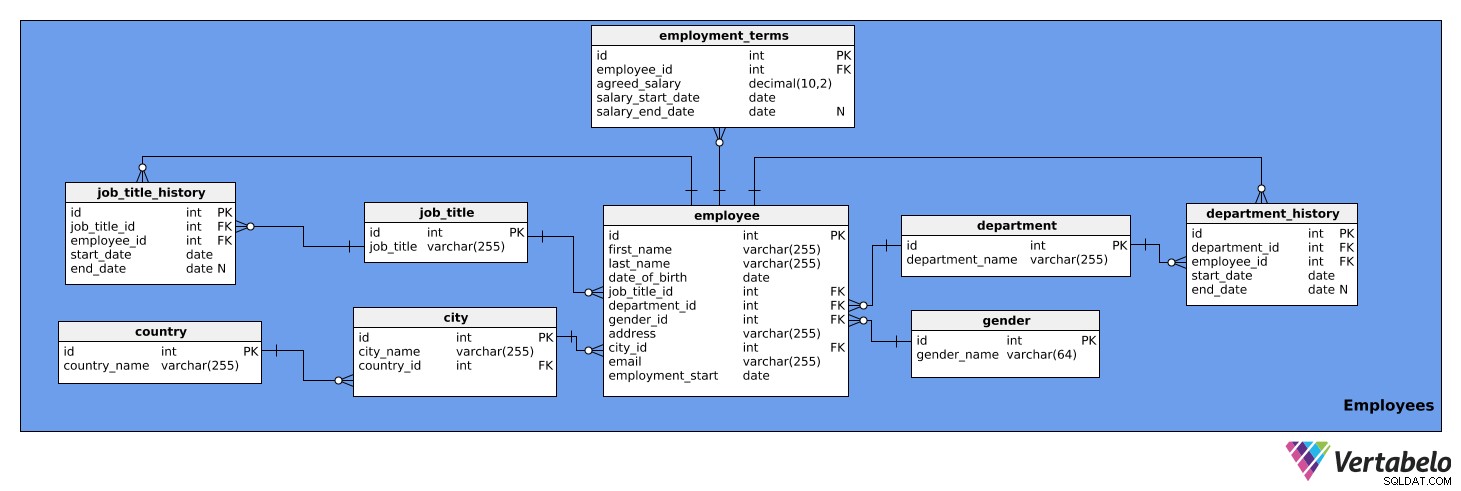
Dieser Themenbereich enthält detaillierte Informationen zu Mitarbeitern. Es besteht aus neun Tabellen:
Employeesemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
Die erste Tabelle, die wir uns ansehen, ist employee Tisch. Es enthält eine Liste aller Mitarbeiter und deren relevanten Details. Die Attribute der Tabelle sind:
id– Eine eindeutige ID für jeden Mitarbeiter.first_name– Der Vorname des Mitarbeiters.last_name– Der Nachname des Mitarbeiters.job_title_id– Referenziert denjob_titleTabelle.department_id– Verweist auf diedepartmentTabelle.gender_id– Verweist auf dasgenderTabelle.address– Die Anschrift des Mitarbeiters.city_id– Verweist aufcityTabelle.email– Die E-Mail des Mitarbeiters.employment_start– Das Datum, an dem die Beschäftigung dieser Person begonnen hat.
Beachten Sie, dass die Spalten job_title_id und department_id sind redundant, da die Informationen über aktuelle Berufsbezeichnungen und Abteilungen aus der job_title_history und department_history Tische. Wir werden diese beiden Spalten jedoch in dieser Tabelle beibehalten, um einen schnelleren Zugriff auf die Informationen zu ermöglichen.
Das Folgende sind die employment_terms Tisch. Es speichert Daten über das im Arbeitsvertrag vereinbarte Gehalt jedes Mitarbeiters und wie es sich im Laufe der Zeit verändert hat. Die Attribute der Tabelle sind:
id– Eine eindeutige ID für jeden Satz von Beschäftigungsbedingungen.employee_id– Verweist auf denEmployeesTabelle.agreed_salary– Das im Arbeitsvertrag genannte Gehalt.salary_start_date– Das Startdatum des vereinbarten Gehalts.salary_end_date– Das Enddatum des vereinbarten Gehalts. Dies kann NULL sein, da ein Gehalt möglicherweise keine geplante Änderung aufweist.
Der job_title Tabelle ist eine Liste der Berufsbezeichnungen, die verschiedenen Mitarbeitern des Unternehmens zugeordnet werden können, z. Analytiker, Fahrer, Sekretärin, Direktor usw. Die Tabelle hat die folgenden Attribute:
id– Eine eindeutige ID für jede Berufsbezeichnung.job_title– Der Name der Berufsbezeichnung. Dies ist der alternative Schlüssel.
Wir brauchen auch eine Tabelle, um den Verlauf der Berufsbezeichnung jedes Mitarbeiters zu speichern. Wir brauchen dies, weil Mitarbeiter innerhalb des Unternehmens befördert, herabgestuft oder neu zugewiesen werden können. Die job_title_history Die Tabelle verwaltet diese Informationen und besteht aus den folgenden Attributen:
id– Eine eindeutige ID für den historischen Eintrag der Berufsbezeichnung.job_title_id– Referenziert denjob_titleTabelle.employee_id– Verweist auf denEmployeesTabelle.start_date– Das Datum, an dem der Mitarbeiter diese Berufsbezeichnung zum ersten Mal innehatte.end_date– Wenn der Mitarbeiter diese Berufsbezeichnung nicht mehr hat. Dies kann NULL sein, da der Mitarbeiter derzeit möglicherweise diese Berufsbezeichnung innehat.
Die Kombination aus job_title_id , employee_id und start_date ist der alternative Schlüssel für die obige Tabelle. Einem Mitarbeiter kann zu einem bestimmten Zeitpunkt nur eine Berufsbezeichnung zugewiesen werden.
Die nächste Tabelle ist die department Tisch. Diese listet einfach alle Abteilungen des Unternehmens auf, wie IT, Buchhaltung, Recht usw. Sie enthält zwei Attribute:
id– Eine eindeutige ID für jede Abteilung.department_name– Der Name jeder Abteilung. Dies ist der alternative Schlüssel.
Mitarbeiter können auch die Abteilung innerhalb des Unternehmens wechseln. Daher brauchen wir eine department_history Tisch. Diese Tabelle speichert Folgendes:
id– Eine eindeutige ID für diesen historischen Eintrag der Abteilung.department_id– Verweist auf diedepartmentTabelle.employee_id– Verweist auf denEmployeesTabelle.start_date– Das Datum, an dem ein Mitarbeiter in einer Abteilung zu arbeiten begann.end_date- Das Datum, an dem ein Mitarbeiter in dieser Abteilung aufgehört hat zu arbeiten. Dies kann NULL sein, da der Mitarbeiter möglicherweise noch dort arbeitet.
Die Kombination aus department_id , employee_id und start_date ist der alternative Schlüssel. Ein Mitarbeiter kann jeweils nur in einer Abteilung arbeiten.
Die nächste Tabelle, über die wir sprechen werden, ist city Tisch. Dies ist eine Liste aller relevanten Städte. Es hat die folgenden Attribute:
id– Eine eindeutige ID für jede Stadt.city_name– Der Name der Stadt.country_id– Verweist auf dascountryTabelle.
Das country Tabelle ist die nächste in unserem Modell. Es ist einfach eine Liste von Ländern und enthält die folgenden Informationen:
id– Eine eindeutige ID für jedes Land.country_name– Der Name des Landes. Dies ist der alternative Schlüssel.
Die letzte Tabelle in diesem Themenbereich ist der gender Tisch. Diese Tabelle listet alle Geschlechter auf. Es enthält die folgenden Attribute:
id– Eine eindeutige ID für jedes Geschlecht.gender_name– Der Name des Geschlechts.
Analysieren wir nun den zweiten Themenbereich.
Gehälter
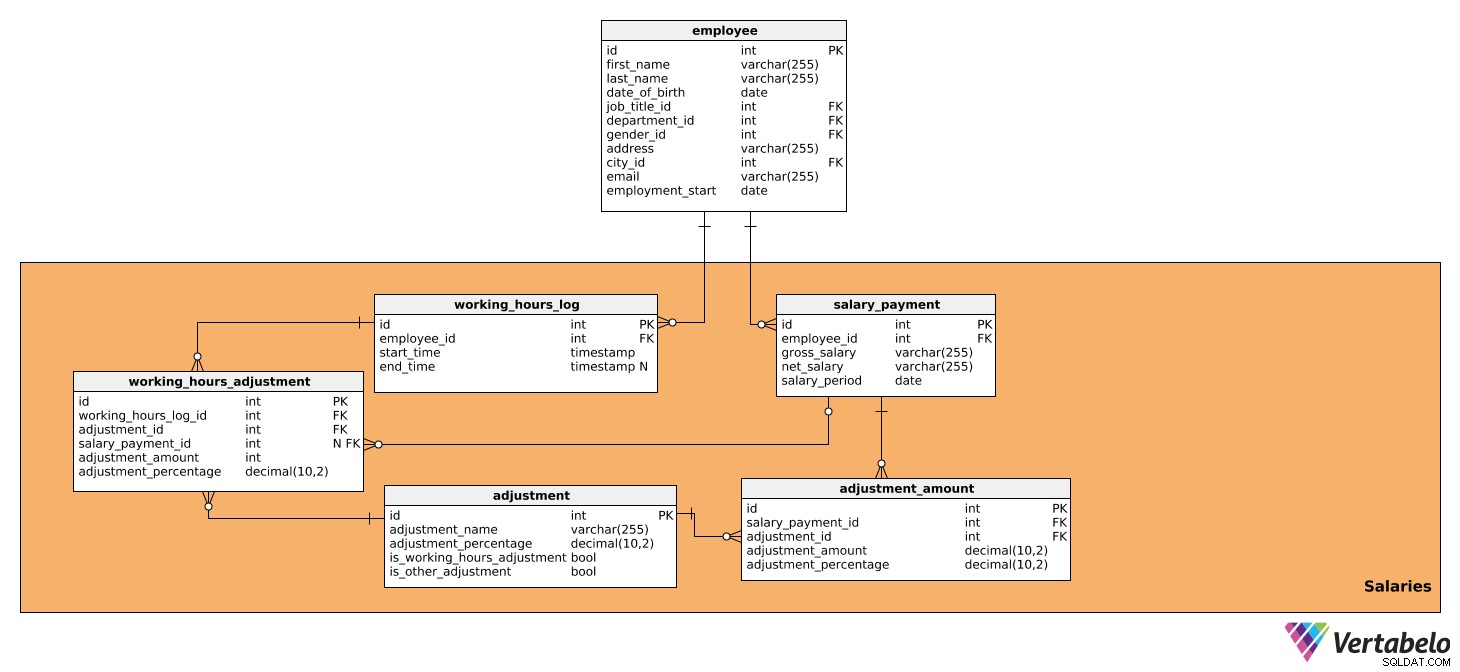
Dieser Themenbereich besteht aus Tabellen, die alle Daten enthalten, die die Gehaltsberechnung für jede Periode direkt beeinflussen, sowie den auszuzahlenden Betrag. Es besteht aus fünf Tabellen:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Sehen wir uns nun die einzelnen Tabellen an.
Die erste Tabelle ist salary_payment . Es enthält alle relevanten Details über das an jeden Mitarbeiter gezahlte Gehalt und hat die folgenden Attribute:
id– Eine eindeutige ID für jedes Gehalt.employee_id– Verweist auf denEmployeesTabelle.gross_salary– Das Bruttogehalt, das die Grundlage für weitere Anpassungen bildet.net_salary– Das Nettogehalt (d. h. der Betrag, den der Arbeitnehmer nach Abzug verschiedener Abzüge erhält).salary_period– Der Zeitraum, für den das Gehalt berechnet und gezahlt wird.
Zweitens ist das working_hours_log Tisch. Es enthält Daten über die Anzahl der von jedem Mitarbeiter geleisteten Arbeitsstunden, die bestimmte Gehaltsanpassungen beeinflussen können. Diese Tabelle hat die folgenden Attribute:
id– Eine eindeutige ID für jeden Protokolleintrag.employee_id– Verweist auf denEmployeesTabelle.start_time– Die Uhrzeit, zu der sich der Mitarbeiter angemeldet hat, d. h. mit der Arbeit für den Tag begonnen hat.end_time– Wenn sich der Mitarbeiter abgemeldet hat. Es kann NULL sein, da wir die genaue Zeit nicht kennen, bis sich der Mitarbeiter abmeldet.
Die nächste Tabelle, die wir analysieren, ist working_hours_adjustment . Diese Tabelle wird nur bei der Berechnung von Anpassungen basierend auf den geleisteten Arbeitsstunden verwendet, d. h. diejenigen, die einen TRUE-Wert in is_working_hours_adjustment haben in der adjustment Tisch. Die Attribute lauten wie folgt:
id– Eine eindeutige ID für jede Anpassung.working_hours_log_id– Verweist auf dasworking_hours_logTabelle.adjustment_id- Verweist auf dieadjustmentTabelle.salary_payment_id– Verweist aufsalary_paymentTisch. Dieser Wert kann NULL sein, weilsalary_payment_idwird nur einmal im Monat verwendet, wenn wir eine Gehaltsberechnung veranlassen.adjustment_amount– Die Höhe der Anpassung.adjustment_percentage– Der prozentuale Betrag der Anpassung. Dies wird zu historischen Zwecken verwendet, da sich der Prozentsatz im Laufe der Zeit ändern kann.
Die nächste Tabelle, über die wir sprechen werden, ist die adjustment Tisch. Es enthält Informationen über alle Anpassungen, die für die Gehaltsberechnung verwendet werden, dh alle Steuern und Abgaben, die sich auf die Gehaltshöhe auswirken. Außerdem enthält es alle Anpassungen, die von den geleisteten und nicht geleisteten Stunden abhängen, wie z. B. Prämien, Überstunden, Krankenstand und Mutterschafts-/Vaterschaftsurlaub. Dazu benötigen wir folgende Daten:
id– Eine eindeutige ID für jede Anpassung.adjustment_name– Ein Name, der diese Anpassung beschreibt.adjustment_percentage– Der prozentuale Betrag der jeweiligen Anpassung.is_working_hours_adjustment– Dies ist eine Flaggenmarkierung, wenn eine Anpassung direkt von der Arbeitszeit abhängt, z. Überstunden, Krankheitstage usw.is_other_adjustment– Dies ist eine Flagge, die Anpassungen markiert, die nicht direkt von den geleisteten Arbeitsstunden ab, wie Steuerabzüge, Sozialversicherungsbeiträge, Arbeitgeberbeiträge etc.
Danach benötigen wir den adjustment_amount Tisch. Es wird verwendet, um alle Gehaltsanpassungen zu berechnen, mit Ausnahme derjenigen, die bereits in working_hours_adjustment , d.h. diejenigen, die einen TRUE-Wert in is_other_adjustment haben in der adjustment Tisch. Die Tabelle enthält die folgenden Attribute:
id– Eine eindeutige ID für jeden Anpassungsbetragseintrag.salary_payment_id– Verweist aufsalary_paymentTabelle.adjustment_id– Verweist auf dieadjustmentTabelle.adjustment_amount– Der Betrag jeder berechneten Anpassung.adjustment_percentage- Der prozentuale Betrag der Anpassung. Er wird zu historischen Zwecken verwendet, da sich der Prozentsatz im Laufe der Zeit ändern kann.
Lassen Sie mich Ihnen ein Beispiel dafür geben, wie die Tabellen working_hours_log , working_hours_adjustment , adjustment und adjustment_amount zusammenarbeiten, um ein Gehalt zu berechnen. Jeden Tag protokolliert der Mitarbeiter, wann er zur Arbeit kommt und wann er geht. Diese Daten können im working_hours_log Tisch. Angenommen, unser Mitarbeiter hat einen Monat lang 10 Überstunden geleistet, und gemäß der Unternehmensrichtlinie erhält er oder sie für jede Überstunde 20 % mehr pro Stunde. Durch Verweis auf die adjustment Tabelle finden wir die erforderliche Anpassung, d. h. Überstunden, die einen bestimmten Prozentsatz (20 %) haben. Wir haben auch is_working_hours_adjustment auf WAHR setzen. Durch die Verwendung von Daten aus diesen beiden Tabellen können wir die Anpassung berechnen und in working_hours_adjustment Tisch.
Jetzt können wir alle anderen Anpassungen berechnen, die nicht hängen von den geleisteten Arbeitsstunden ab. Dies erfolgt im adjustment_amount Tisch. Genau wie oben verweisen wir auf die adjustment Tabelle und finden Sie die Anpassungen, die wir brauchen – z.B. Steuerabzug, Sozialversicherungsbeitrag oder Arbeitgeberbeitrag – und deren jeweilige Prozentsätze. Der is_other_adjustment Flag in der adjustment Tabelle wird für diese Anpassungen auf TRUE gesetzt.
Basierend auf diesen Berechnungen können wir Bruttogehalts- und Nettogehaltsdaten in salary_payment Tisch.
Indem wir dieses Beispiel durchgehen, haben wir alles in unserem Datenmodell abgedeckt!
Hat Ihnen das Lohndatenmodell gefallen?
Ich habe versucht, ein Modell zu erstellen, das in fast allen Situationen verwendet werden kann. Es ist jedoch unmöglich, alle spezifischen Parameter, die die Gehaltsberechnung beeinflussen, in einen Artikel dieser Länge aufzunehmen. Durch die Behandlung allgemeiner Prinzipien habe ich versucht, dieses Modell als solide Grundlage für Ihr Gehaltsdatenmodell nutzbar zu machen.
Was halten Sie vom Lohndatenmodell? Eignet es sich als Lösung für Ihre Gehaltsabrechnungsanforderungen? Ist dir was anderes eingefallen? Gibt es bestimmte Probleme, die Sie festgestellt haben und die das Datenmodell erheblich verändern würden? Sagen Sie Ihre Meinung im Kommentarbereich.