AKTUALISIERUNG:2. September 2021 (Ursprünglich veröffentlicht am 26. Juli 2012.)
Viele Dinge ändern sich im Laufe einiger Hauptversionen unserer bevorzugten Datenbankplattform. SQL Server 2016 brachte uns STRING_SPLIT, eine native Funktion, die viele der zuvor benötigten benutzerdefinierten Lösungen überflüssig macht. Es ist auch schnell, aber es ist nicht perfekt. Beispielsweise unterstützt es nur ein Trennzeichen aus einem Zeichen und gibt nichts zurück, um die Reihenfolge der Eingabeelemente anzugeben. Ich habe mehrere Artikel über diese Funktion (und STRING_AGG, das in SQL Server 2017 eingeführt wurde) geschrieben, seit dieser Beitrag geschrieben wurde:
- Leistungsüberraschungen und Annahmen:STRING_SPLIT()
- STRING_SPLIT() in SQL Server 2016:Follow-up Nr. 1
- STRING_SPLIT() in SQL Server 2016:Follow-up Nr. 2
- SQL Server-Split-String-Ersetzungscode mit STRING_SPLIT
- Vergleich von String-Aufteilungs-/Verkettungsmethoden
- Lösen Sie alte Probleme mit den neuen Funktionen STRING_AGG und STRING_SPLIT von SQL Server
- Umgang mit dem Einzelzeichen-Trennzeichen in der STRING_SPLIT-Funktion von SQL Server
- Bitte helfen Sie mit STRING_SPLIT Verbesserungen
- Ein Weg, STRING_SPLIT in SQL Server zu verbessern – und Sie können dabei helfen
Ich werde den folgenden Inhalt hier für die Nachwelt und historische Relevanz belassen, und auch, weil ein Teil der Testmethodik neben dem Teilen von Strings auch für andere Probleme relevant ist, aber bitte sehen Sie sich einige der obigen Referenzen an, um Informationen darüber zu erhalten, wie Sie teilen sollten Strings in modernen, unterstützten Versionen von SQL Server – sowie dieser Beitrag, der erklärt, warum das Aufteilen von Strings vielleicht gar kein Problem ist, das die Datenbank lösen soll, neue Funktion hin oder her.
- Strings aufteilen:Jetzt mit weniger T-SQL
Ich weiß, dass viele Leute das Problem der "geteilten Saiten" langweilen, aber es scheint immer noch fast täglich in Foren und Q &A-Sites wie Stack Overflow aufzutauchen. Das ist das Problem, wenn Leute einen String wie diesen übergeben wollen:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Innerhalb der Prozedur wollen sie so etwas tun:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Dies funktioniert nicht, weil @FavoriteTeams eine einzelne Zeichenfolge ist und das Obige übersetzt zu:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server wird daher versuchen, ein Team namens Patriots,Red Sox,Bruins zu finden , und ich vermute, es gibt kein solches Team. Was sie hier wirklich wollen, ist das Äquivalent zu:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Aber da es in SQL Server keinen Array-Typ gibt, wird die Variable überhaupt nicht so interpretiert – es ist immer noch eine einfache einzelne Zeichenfolge, die zufällig einige Kommas enthält. Abgesehen vom fragwürdigen Schema-Design muss in diesem Fall die kommagetrennte Liste in einzelne Werte "aufgeteilt" werden – und diese Frage führt häufig zu vielen "neuen" Debatten und Kommentaren über die beste Lösung, um genau das zu erreichen.
Die Antwort scheint fast immer zu sein, dass Sie CLR verwenden sollten. Wenn Sie CLR nicht verwenden können – und ich weiß, dass es viele von Ihnen da draußen gibt, die dies aufgrund von Unternehmensrichtlinien, dem spitzhaarigen Chef oder Sturheit nicht können – dann verwenden Sie eine der vielen existierenden Problemumgehungen. Und es gibt viele Problemumgehungen.
Aber welches sollten Sie verwenden?
Ich vergleiche die Leistung einiger Lösungen – und konzentriere mich auf die Frage, die sich jeder immer stellt:„Welche ist die schnellste?“ Ich werde die Diskussion um *alle* möglichen Methoden nicht weiter führen, da einige bereits eliminiert wurden, weil sie einfach nicht skalierbar sind. Und ich werde dies in Zukunft vielleicht noch einmal besuchen, um die Auswirkungen auf andere Metriken zu untersuchen, aber im Moment werde ich mich nur auf die Dauer konzentrieren. Hier sind die Konkurrenten, die ich vergleichen werde (unter Verwendung von SQL Server 2012, 11.00.2316, auf einer Windows 7-VM mit 4 CPUs und 8 GB RAM):
CLR
Wenn Sie CLR verwenden möchten, sollten Sie sich auf jeden Fall Code von MVP Adam Machanic ausleihen, bevor Sie darüber nachdenken, Ihren eigenen zu schreiben (ich habe bereits darüber gebloggt, das Rad neu zu erfinden, und das gilt auch für kostenlose Code-Snippets wie diesen). Er verbrachte viel Zeit mit der Feinabstimmung dieser CLR-Funktion, um eine Zeichenfolge effizient zu analysieren. Wenn Sie derzeit eine CLR-Funktion verwenden und dies nicht der Fall ist, empfehle ich Ihnen dringend, sie bereitzustellen und zu vergleichen – ich habe sie mit einer viel einfacheren, VB-basierten CLR-Routine getestet, die funktional gleichwertig war, aber der VB-Ansatz schnitt etwa dreimal schlechter ab als Adams.
Also nahm ich Adams Funktion, kompilierte den Code in eine DLL (mit csc) und stellte genau diese Datei auf dem Server bereit. Dann habe ich meiner Datenbank die folgende Assembly und Funktion hinzugefügt:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Dies ist die typische Funktion, die ich für einmalige Szenarien verwende, in denen ich weiß, dass die Eingabe "sicher" ist, aber ich empfehle sie nicht für Produktionsumgebungen (mehr dazu weiter unten).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Ein sehr starker Vorbehalt muss mit dem XML-Ansatz einhergehen:Er kann nur verwendet werden, wenn Sie garantieren können, dass Ihre Eingabezeichenfolge keine illegalen XML-Zeichen enthält. Ein Name mit <,> oder &und die Funktion wird explodieren. Wenn Sie also diesen Ansatz verwenden, sollten Sie sich unabhängig von der Leistung der Einschränkungen bewusst sein – er sollte nicht als praktikable Option für einen generischen String-Splitter angesehen werden. Ich nehme es in diese Zusammenfassung auf, weil Sie vielleicht einen Fall haben, in dem Sie können Vertrauen Sie der Eingabe – zum Beispiel ist es möglich, für durch Kommas getrennte Listen von Ganzzahlen oder GUIDs zu verwenden.
Zahlentabelle
Diese Lösung verwendet eine Numbers-Tabelle, die Sie selbst erstellen und füllen müssen. (Wir haben seit Ewigkeiten nach einer integrierten Version gefragt.) Die Numbers-Tabelle sollte genügend Zeilen enthalten, um die Länge der längsten Zeichenfolge zu überschreiten, die Sie aufteilen werden. In diesem Fall verwenden wir 1.000.000 Zeilen:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Durch die Verwendung der Datenkomprimierung wird die Anzahl der erforderlichen Seiten drastisch reduziert, aber natürlich sollten Sie diese Option nur verwenden, wenn Sie die Enterprise Edition ausführen. In diesem Fall erfordern die komprimierten Daten 1.360 Seiten gegenüber 2.102 Seiten ohne Komprimierung – eine Einsparung von etwa 35 %. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Allgemeiner Tabellenausdruck
Diese Lösung verwendet einen rekursiven CTE, um jeden Teil der Zeichenfolge aus dem "Rest" des vorherigen Teils zu extrahieren. Als rekursiver CTE mit lokalen Variablen werden Sie feststellen, dass dies eine Tabellenwertfunktion mit mehreren Anweisungen sein musste, im Gegensatz zu den anderen, die alle inline sind.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Jeff Modens Splitter Eine auf Jeff Modens Splitter basierende Funktion mit geringfügigen Änderungen zur Unterstützung längerer Zeichenfolgen
Drüben auf SQLServerCentral präsentierte Jeff Moden eine Splitterfunktion, die mit der Leistung von CLR konkurrierte, daher hielt ich es für nur fair, eine Variation mit einem ähnlichen Ansatz in diese Zusammenfassung aufzunehmen. Ich musste ein paar kleinere Änderungen an seiner Funktion vornehmen, um unsere längste Zeichenkette (500.000 Zeichen) handhaben zu können, und auch die Namenskonventionen ähnlich gestalten:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Abgesehen davon, für diejenigen, die die Lösung von Jeff Moden verwenden, können Sie erwägen, eine Zahlentabelle wie oben zu verwenden und mit einer leichten Variation von Jeffs Funktion zu experimentieren:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Dies tauscht geringfügig höhere Lesevorgänge gegen eine geringfügig niedrigere CPU ein, kann also besser sein, je nachdem, ob Ihr System bereits CPU- oder I/O-gebunden ist.)
Prüfung der Plausibilität
Nur um sicherzugehen, dass wir auf dem richtigen Weg sind, können wir überprüfen, ob alle fünf Funktionen die erwarteten Ergebnisse zurückgeben:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Und tatsächlich sind dies die Ergebnisse, die wir in allen fünf Fällen sehen …

Die Testdaten
Jetzt, da wir wissen, dass sich die Funktionen wie erwartet verhalten, können wir zum lustigen Teil kommen:Testen der Leistung mit einer unterschiedlichen Anzahl von Strings unterschiedlicher Länge. Aber zuerst brauchen wir einen Tisch. Ich habe das folgende einfache Objekt erstellt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Ich habe diese Tabelle mit einer Reihe von Strings unterschiedlicher Länge gefüllt und dabei darauf geachtet, dass für jeden Test ungefähr derselbe Datensatz verwendet wird – zuerst 10.000 Zeilen, in denen die Zeichenfolge 50 Zeichen lang ist, dann 1.000 Zeilen, in denen die Zeichenfolge 500 Zeichen lang ist , 100 Zeilen mit einer Zeichenfolge von 5.000 Zeichen, 10 Zeilen mit einer Zeichenfolge von 50.000 Zeichen usw. bis zu einer Zeile mit 500.000 Zeichen. Ich habe dies sowohl getan, um die gleiche Menge an Gesamtdaten zu vergleichen, die von den Funktionen verarbeitet werden, als auch um zu versuchen, meine Testzeiten einigermaßen vorhersehbar zu halten.
Ich verwende eine #temp-Tabelle, damit ich einfach GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Das Erstellen und Auffüllen dieser Tabelle dauerte auf meinem Computer etwa 20 Sekunden, und die Tabelle stellt etwa 6 MB Daten dar (etwa 500.000 Zeichen mal 2 Bytes oder 1 MB pro Zeichenfolgentyp, plus Zeilen- und Index-Overhead). Keine riesige Tabelle, aber sie sollte groß genug sein, um Leistungsunterschiede zwischen den Funktionen hervorzuheben.
Die Tests
Wenn die Funktionen vorhanden sind und der Tisch richtig mit großen Saiten zum Kauen gefüllt ist, können wir endlich einige tatsächliche Tests durchführen, um zu sehen, wie sich die verschiedenen Funktionen gegenüber echten Daten verhalten. Um die Leistung ohne Berücksichtigung des Netzwerk-Overheads zu messen, habe ich SQL Sentry Plan Explorer verwendet, jede Testreihe zehnmal ausgeführt, die Dauermetriken erfasst und den Durchschnitt ermittelt.
Beim ersten Test wurden die Elemente einfach als Satz aus jeder Zeichenfolge gezogen:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
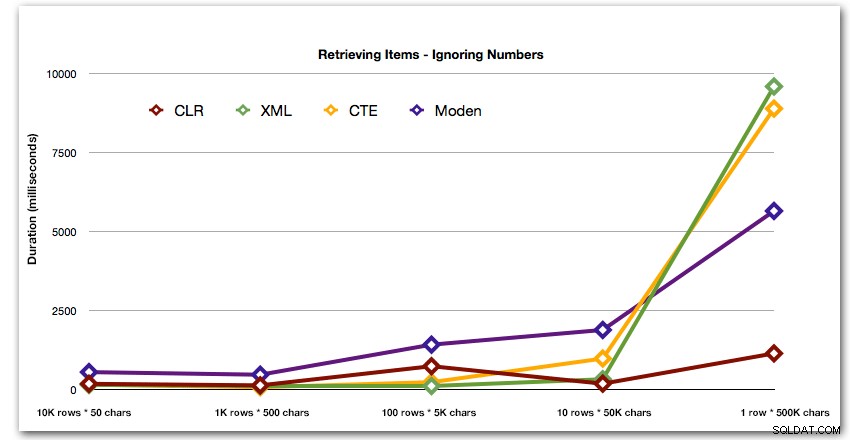
Die Ergebnisse zeigen, dass der Vorteil von CLR bei größer werdenden Saiten wirklich glänzt. Am unteren Ende waren die Ergebnisse gemischt, aber auch hier sollte die XML-Methode ein Sternchen daneben haben, da ihre Verwendung davon abhängt, dass man sich auf XML-sichere Eingaben verlässt. Für diesen speziellen Anwendungsfall schnitt die Numbers-Tabelle durchgehend am schlechtesten ab:
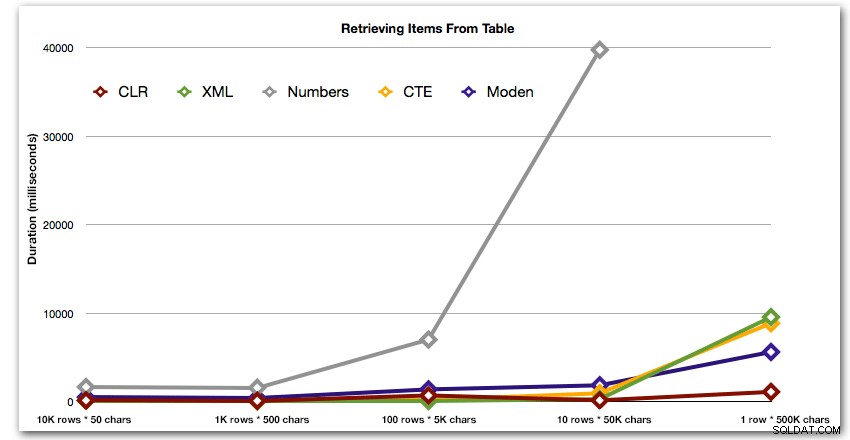
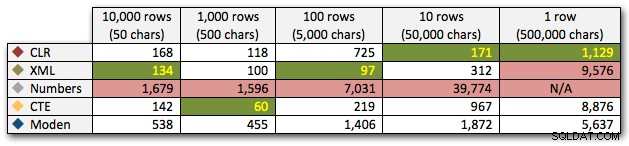
Dauer in Millisekunden
Nach der hyperbolischen 40-Sekunden-Leistung für die Zahlentabelle gegen 10 Zeilen mit 50.000 Zeichen ließ ich sie für den letzten Test aus dem Rennen. Um die relative Leistung der vier besten Methoden in diesem Test besser darzustellen, habe ich die Numbers-Ergebnisse vollständig aus dem Diagramm entfernt:
Lassen Sie uns als Nächstes vergleichen, wann wir eine Suche nach dem durch Kommas getrennten Wert durchführen (z. B. die Zeilen zurückgeben, in denen eine der Zeichenfolgen „foo“ ist). Auch hier werden wir die fünf obigen Funktionen verwenden, aber wir werden das Ergebnis auch mit einer Suche vergleichen, die zur Laufzeit unter Verwendung von LIKE durchgeführt wird, anstatt sich mit der Aufteilung zu beschäftigen.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Diese Ergebnisse zeigen, dass CLR für kleine Zeichenfolgen tatsächlich am langsamsten war und dass die beste Lösung darin besteht, einen Scan mit LIKE durchzuführen, ohne sich die Mühe zu machen, die Daten überhaupt aufzuteilen. Wieder habe ich die Lösung der Zahlentabelle aus dem 5. Ansatz fallen gelassen, als klar war, dass ihre Dauer mit zunehmender Größe der Zeichenfolge exponentiell zunehmen würde:
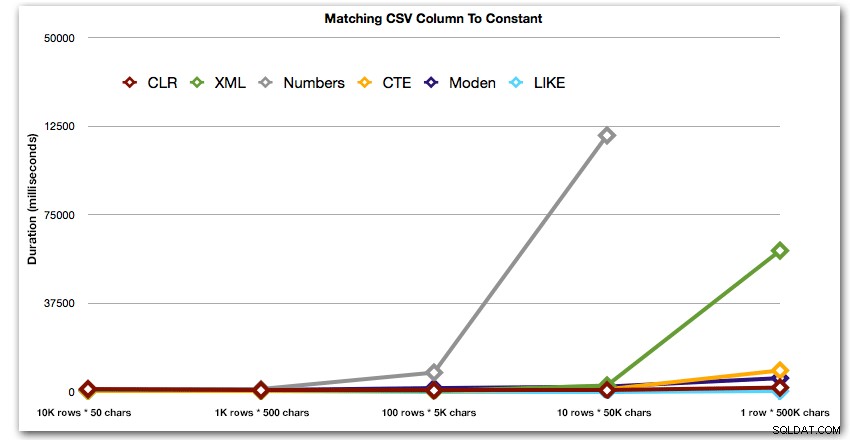
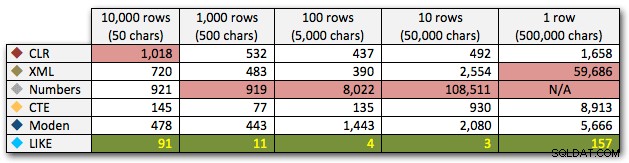
Dauer in Millisekunden
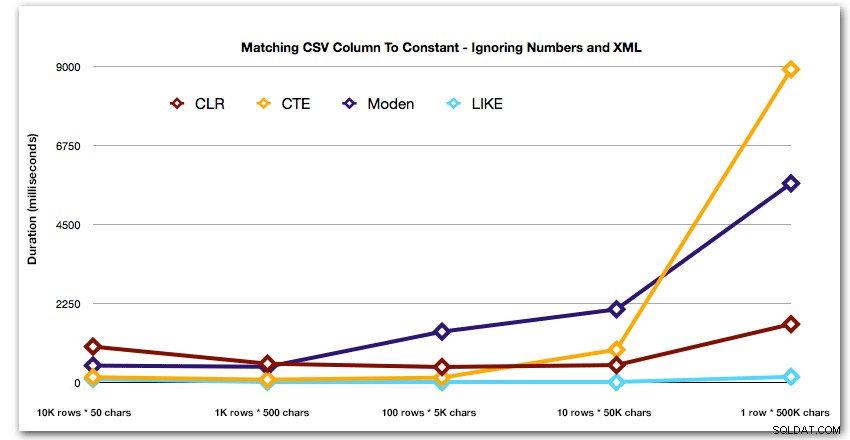
Und um die Muster für die Top-4-Ergebnisse besser zu demonstrieren, habe ich die Numbers- und XML-Lösungen aus dem Diagramm entfernt:
Schauen wir uns als Nächstes die Replikation des Anwendungsfalls vom Anfang dieses Beitrags an, in dem wir versuchen, alle Zeilen in einer Tabelle zu finden, die in der übergebenen Liste vorhanden sind. Wie bei den Daten in der Tabelle, die wir oben erstellt haben, wir Wir erstellen Strings mit unterschiedlichen Längen von 50 bis 500.000 Zeichen, speichern sie in einer Variablen und prüfen dann, ob eine allgemeine Katalogansicht in der Liste vorhanden ist.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
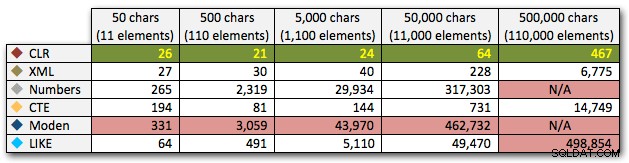
ORDER BY [object_id]; Diese Ergebnisse zeigen, dass bei diesem Muster bei mehreren Methoden die Dauer exponentiell ansteigt, wenn die Größe der Zeichenfolge zunimmt. Am unteren Ende hält XML gut mit CLR mit, aber auch das verschlechtert sich schnell. CLR ist hier durchweg der klare Gewinner:
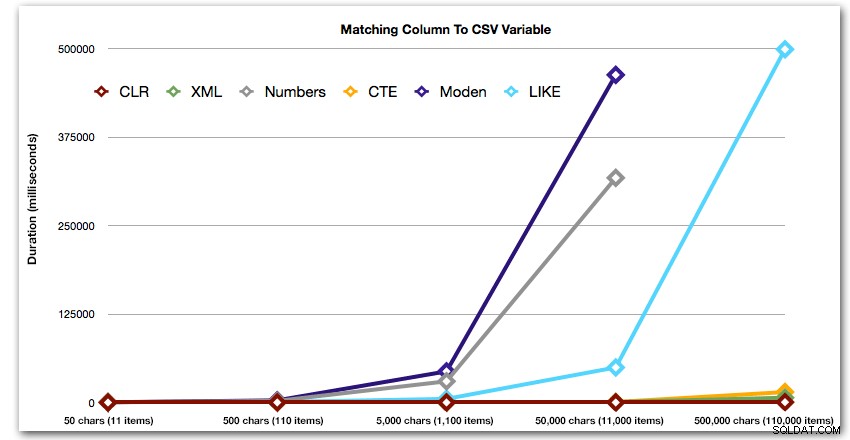
Dauer in Millisekunden
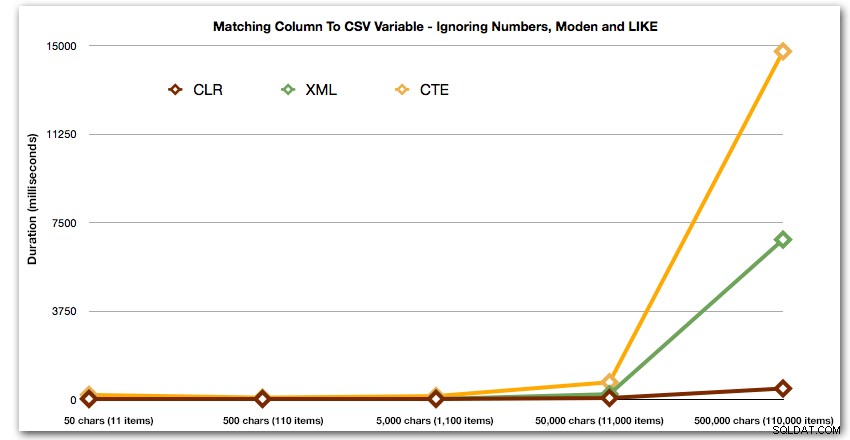
Und wieder ohne die Methoden, die in Sachen Dauer nach oben explodieren:
Vergleichen wir abschließend die Kosten für das Abrufen der Daten aus einer einzelnen Variablen unterschiedlicher Länge, wobei die Kosten für das Lesen von Daten aus einer Tabelle außer Acht gelassen werden. Auch hier generieren wir Strings unterschiedlicher Länge, von 50 bis 500.000 Zeichen, und geben dann die Werte einfach als Set zurück:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Diese Ergebnisse zeigen auch, dass CLR in Bezug auf die Dauer bis zu 110.000 Elementen in der Menge ziemlich flach ist, während die anderen Methoden bis einige Zeit nach 11.000 Elementen ein anständiges Tempo beibehalten:
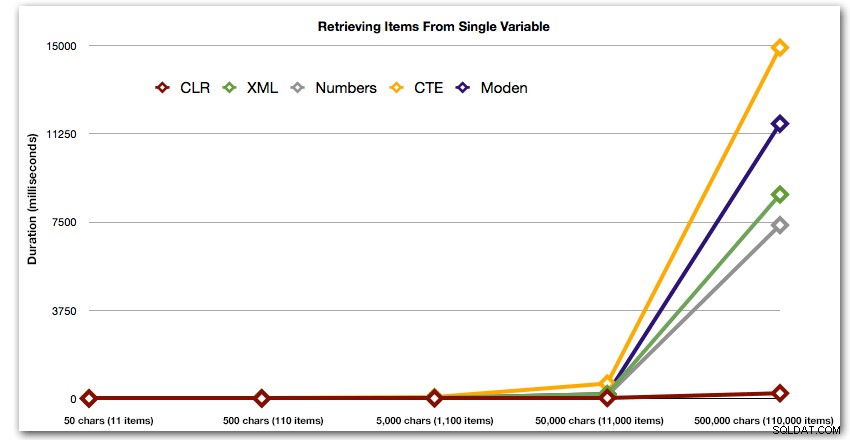
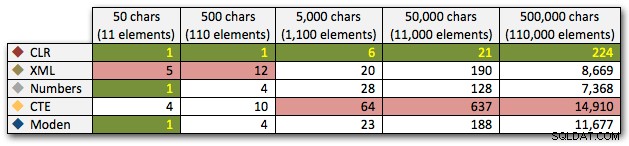
Dauer in Millisekunden
Schlussfolgerung
In fast allen Fällen übertrifft die CLR-Lösung die anderen Ansätze deutlich – in einigen Fällen ist es ein Erdrutschsieg, insbesondere wenn die String-Größen zunehmen; in einigen anderen ist es ein Fotofinish, das in beide Richtungen fallen könnte. Im ersten Test haben wir gesehen, dass XML und CTE CLR am unteren Ende übertroffen haben. Wenn dies also ein typischer Anwendungsfall ist *und* Sie sicher sind, dass Ihre Zeichenfolgen im Bereich von 1 bis 10.000 Zeichen liegen, könnte einer dieser Ansätze sein eine bessere Option sein. Wenn Ihre Saitenstärke weniger vorhersehbar ist, ist CLR wahrscheinlich immer noch Ihre beste Wahl – Sie verlieren ein paar Millisekunden am unteren Ende, aber Sie gewinnen eine ganze Menge am oberen Ende. Hier sind die Entscheidungen, die ich je nach Aufgabe treffen würde, wobei der zweite Platz für Fälle hervorgehoben wird, in denen CLR keine Option ist. Beachten Sie, dass XML nur dann meine bevorzugte Methode ist, wenn ich weiß, dass die Eingabe XML-sicher ist; Dies sind möglicherweise nicht unbedingt Ihre besten Alternativen, wenn Sie Ihrem Beitrag weniger vertrauen.
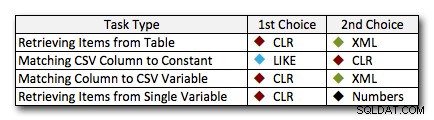
Die einzige wirkliche Ausnahme, bei der CLR nicht generell meine Wahl ist, ist der Fall, in dem Sie tatsächlich durch Kommas getrennte Listen in einer Tabelle speichern und dann Zeilen finden, in denen sich eine definierte Entität in dieser Liste befindet. In diesem speziellen Fall würde ich wahrscheinlich zuerst empfehlen, das Schema neu zu entwerfen und richtig zu normalisieren, sodass diese Werte separat gespeichert werden, anstatt es als Ausrede zu verwenden, CLR nicht zum Aufteilen zu verwenden.
Wenn Sie CLR aus anderen Gründen nicht verwenden können, gibt es bei diesen Tests keinen eindeutigen „zweiten Platz“. Meine obigen Antworten basierten auf der Gesamtskala und nicht auf einer bestimmten Saitengröße. Jede Lösung hier wurde in mindestens einem Szenario Zweiter – also ist CLR zwar eindeutig die Wahl, wenn Sie es verwenden können, aber was Sie verwenden sollten, wenn Sie es nicht können, ist eher eine „es kommt darauf an“-Antwort – Sie müssen basierend darauf beurteilen Ihre Anwendungsfälle und die obigen Tests (oder indem Sie Ihre eigenen Tests erstellen), welche Alternative für Sie besser ist.
Nachtrag:Eine Alternative zum Splitting überhaupt
Die oben genannten Ansätze erfordern keine Änderungen an Ihren vorhandenen Anwendungen, vorausgesetzt, sie erstellen bereits eine durch Kommas getrennte Zeichenfolge und werfen sie zur Bearbeitung in die Datenbank. Eine Option, die Sie in Betracht ziehen sollten, wenn entweder CLR keine Option ist und/oder Sie die Anwendung(en) ändern können, ist die Verwendung von Tabellenwertparametern (TVPs). Hier ist ein kurzes Beispiel für die Verwendung eines TVP im obigen Kontext. Erstellen Sie zunächst einen Tabellentyp mit einer einzelnen Zeichenfolgenspalte:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Dann kann die gespeicherte Prozedur dieses TVP als Eingabe nehmen und dem Inhalt beitreten (oder ihn auf andere Weise verwenden – dies ist nur ein Beispiel):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Statt zum Beispiel einen durch Kommas getrennten String zu erstellen, füllen Sie jetzt in Ihrem C#-Code eine DataTable aus (oder verwenden Sie eine beliebige kompatible Sammlung, die Ihren Wertesatz möglicherweise bereits enthält):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Sie könnten dies als Vorläufer eines Folgebeitrags betrachten.
Natürlich funktioniert das nicht gut mit JSON und anderen APIs – ziemlich oft der Grund, warum eine kommagetrennte Zeichenfolge überhaupt an SQL Server übergeben wird.