Ist SQL DISTINCT gut (oder schlecht), wenn Du Duplikate in Ergebnissen entfernen müssen?
Einige sagen, es sei gut und fügen DISTINCT hinzu, wenn Duplikate auftreten. Einige sagen, es sei schlecht und schlagen vor, GROUP BY ohne eine Aggregatfunktion zu verwenden. Andere sagen, dass DISTINCT und GROUP BY dasselbe sind, wenn Sie Duplikate entfernen müssen.
Dieser Beitrag wird in die Details eintauchen, um die richtigen Antworten zu erhalten. Letztendlich werden Sie also je nach Bedarf das beste Schlüsselwort verwenden. Fangen wir an.
Eine kurze Erinnerung an die Grundlagen der SQL SELECT DISTINCT-Anweisung
Bevor wir tiefer eintauchen, erinnern wir uns daran, was die SQL SELECT DISTINCT-Anweisung ist. Eine Datenbanktabelle kann aus vielen Gründen doppelte Werte enthalten, aber wir möchten vielleicht nur die eindeutigen Werte erhalten. In diesem Fall ist SELECT DISTINCT praktisch. Diese DISTINCT-Klausel veranlasst die SELECT-Anweisung, nur eindeutige Datensätze abzurufen.
Die Syntax der Anweisung ist einfach:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Hier ist die WHERE-Bedingung optional.
Die Aussage gilt sowohl für eine einzelne Spalte als auch für mehrere Spalten. Die auf mehrere Spalten angewendete Syntax dieser Anweisung lautet wie folgt:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Beachten Sie, dass das Szenario der Abfrage mehrerer Spalten vorschlägt, die Kombination von Werten in allen Spalten zu verwenden, die durch die Anweisung definiert werden, um die Eindeutigkeit zu bestimmen.
Lassen Sie uns nun die praktische Verwendung und die Haken bei der Anwendung der Anweisung SELECT DISTINCT untersuchen.
Wie SQL DISTINCT zum Entfernen von Duplikaten funktioniert
Antworten zu bekommen ist nicht so schwer zu finden. SQL Server stellte uns Ausführungspläne zur Verfügung, um zu sehen, wie eine Abfrage verarbeitet wird, um uns die erforderlichen Ergebnisse zu liefern.
Der folgende Abschnitt konzentriert sich auf den Ausführungsplan bei Verwendung von DISTINCT. Sie müssen Strg-M drücken in SQL Server Management Studio, bevor Sie die folgenden Abfragen ausführen. Oder klicken Sie auf Aktuellen Ausführungsplan einschließen aus der Symbolleiste.
Abfragepläne in SQL DISTINCT
Beginnen wir mit dem Vergleich von 2 Abfragen. Die erste wird DISTINCT nicht verwenden und die zweite Abfrage wird.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Hier ist der Ausführungsplan:
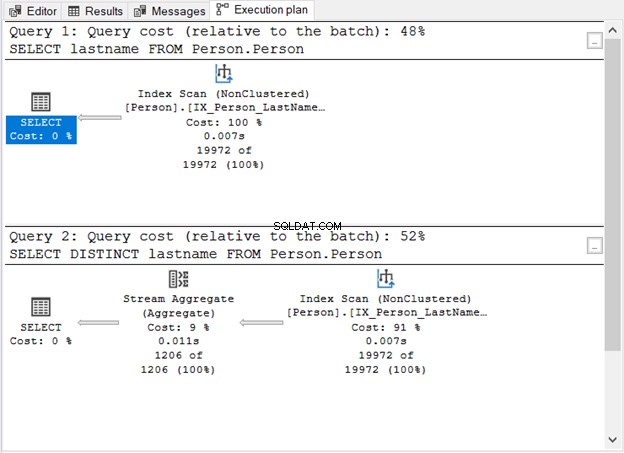
Was hat uns Abbildung 1 gezeigt?
- Ohne das Schlüsselwort DISTINCT ist die Abfrage einfach.
- Ein zusätzlicher Schritt erscheint nach dem Hinzufügen von DISTINCT.
- Die Abfragekosten bei der Verwendung von DISTINCT sind höher als ohne.
- Beide haben Index-Scan-Operatoren. Dies ist verständlich, da es in unseren Abfragen keine spezifische WHERE-Klausel gibt.
- Der zusätzliche Schritt, der Stream Aggregate-Operator, wird verwendet, um die Duplikate zu entfernen.
Die Anzahl der logischen Lesevorgänge ist dieselbe (107), wenn Sie das STATISTICS IO überprüfen. Die Anzahl der Datensätze ist jedoch sehr unterschiedlich. 19.972 Zeilen werden von der ersten Abfrage zurückgegeben. Inzwischen werden 1.206 Zeilen von der zweiten Abfrage zurückgegeben.
Daher können Sie DISTINCT nicht jederzeit hinzufügen. Wenn Sie jedoch eindeutige Werte benötigen, ist dies ein notwendiger Overhead.
Es gibt Operatoren, die verwendet werden, um eindeutige Werte auszugeben. Sehen wir uns einige davon an.
STREAM-AGGREGAT
Dies ist der Operator, den Sie in Abbildung 1 gesehen haben. Er akzeptiert eine einzelne Eingabe und gibt ein aggregiertes Ergebnis aus. In Abbildung 1 kommt die Eingabe vom Index Scan-Operator. Stream Aggregate benötigt jedoch eine sortierte Eingabe.
Wie Sie in Abbildung 1 sehen können, verwendet es den IX_Person_LastName_FirstName_MiddleName , ein nicht eindeutiger Index für Namen. Da der Index die Datensätze bereits nach Namen sortiert, akzeptiert das Stream Aggregate die Eingabe. Ohne den Index kann sich der Abfrageoptimierer dafür entscheiden, einen zusätzlichen Sortieroperator im Plan zu verwenden. Und das wird teurer. Oder es kann ein Hash-Match verwendet werden.
HASH-VERGLEICH (AGGREGAT)
Ein weiterer von DISTINCT verwendeter Operator ist Hash Match. Dieser Operator wird für Joins und Aggregationen verwendet.
Bei Verwendung von DISTINCT aggregiert Hash Match die Ergebnisse, um eindeutige Werte zu erzeugen. Hier ist ein Beispiel.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Und hier ist der Ausführungsplan:
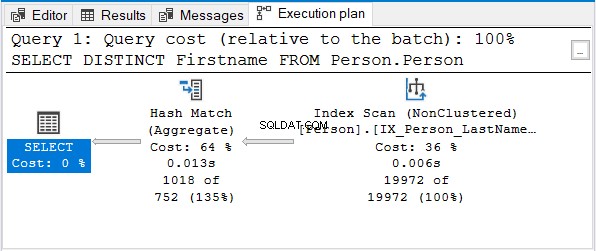
Aber warum nicht Stream Aggregate?
Beachten Sie, dass derselbe Namensindex verwendet wird. Dieser Index sortiert nach Nachname Erste. Also ein Vorname nur die Abfrage wird unsortiert.
Hash Match (Aggregate) ist die nächste logische Wahl, um die Duplikate zu entfernen.
HASH-VERGLEICH (FLOW DISTINCT)
Der Hash Match (Aggregate) ist ein blockierender Operator. Daher wird es nicht die Ausgabe erzeugen, die es den gesamten Eingabestrom verarbeitet hat. Wenn wir die Anzahl der Zeilen einschränken (wie bei der Verwendung von TOP mit DISTINCT), wird eine eindeutige Ausgabe erzeugt, sobald diese Zeilen verfügbar sind. Darum geht es bei Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Die Abfrage verwendet TOP 100 zusammen mit DISTINCT. Hier ist der Ausführungsplan:
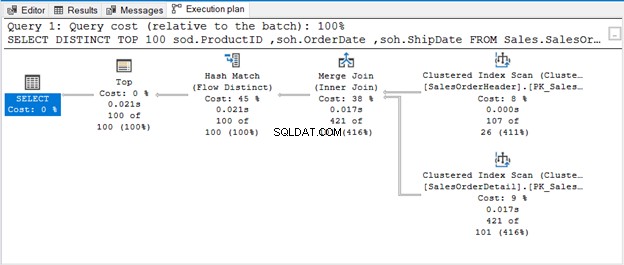
WENN ES KEINEN OPERATOR ZUM ENTFERNEN VON DUPLIKATEN GIBT
Jep. Das kann passieren. Betrachten Sie das folgende Beispiel.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Überprüfen Sie dann den Ausführungsplan:
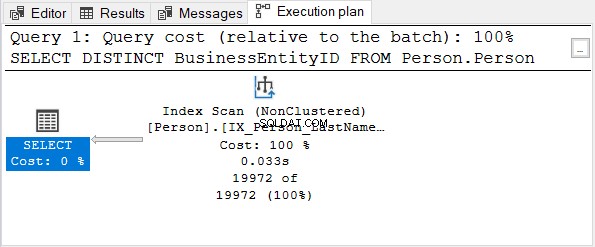
Die BusinessEntityID Spalte ist der Primärschlüssel. Da diese Spalte bereits eindeutig ist, macht es keinen Sinn, DISTINCT anzuwenden. Versuchen Sie, DISTINCT aus der SELECT-Anweisung zu entfernen – der Ausführungsplan ist derselbe wie in Abbildung 4.
Dasselbe gilt, wenn DISTINCT für Spalten mit einem eindeutigen Index verwendet wird.
SQL DISTINCT funktioniert auf ALLEN Spalten in der SELECT-Liste
Bisher haben wir in unseren Beispielen nur 1 Spalte verwendet. DISTINCT funktioniert jedoch mit ALLEN Spalten, die Sie in der SELECT-Liste angeben.
Hier ist ein Beispiel. Diese Abfrage stellt sicher, dass die Werte aller 3 Spalten eindeutig sind.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Beachten Sie die ersten paar Zeilen in der Ergebnismenge in Abbildung 5.
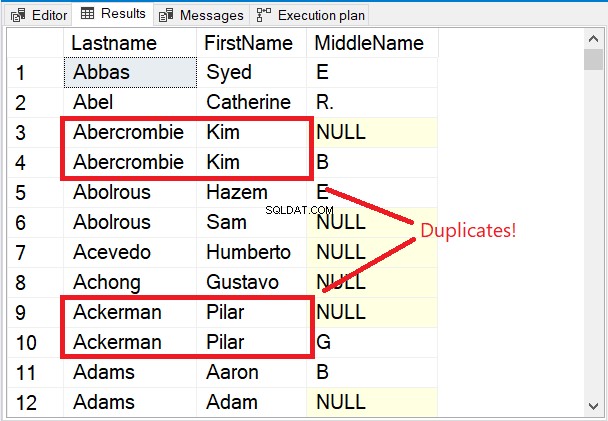
Die ersten Zeilen sind alle einzigartig. Das Schlüsselwort DISTINCT stellte sicher, dass der Middlename Spalte wird ebenfalls berücksichtigt. Beachten Sie die 2 rot umrandeten Namen. Unter Berücksichtigung des Nachnamens und Vorname macht sie nur zu Duplikaten. Aber Hinzufügen von Middlename der Mix änderte alles.
Was ist, wenn Sie eindeutige Vor- und Nachnamen erhalten möchten, aber den zweiten Vornamen in das Ergebnis einbeziehen?
Sie haben 2 Möglichkeiten:
- Fügen Sie eine WHERE-Klausel hinzu, um NULL-Zweitnamen zu entfernen. Dadurch werden alle Namen mit einem zweiten Vornamen NULL entfernt.
- Oder fügen Sie eine GROUP BY-Klausel zu Nachname hinzu und Vorname Säulen. Verwenden Sie dann die Aggregatfunktion MIN für den Middlename Säule. Dadurch erhältst du 1 zweiten Vornamen mit demselben Nach- und Vornamen.
SQL DISTINCT vs. GROUP BY
Bei Verwendung von GROUP BY ohne Aggregatfunktion verhält es sich wie DISTINCT. Woher wissen wir? Eine Möglichkeit, dies herauszufinden, ist die Verwendung eines Beispiels.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Führen Sie sie aus und sehen Sie sich den Ausführungsplan an. Ist es wie im Screenshot unten?
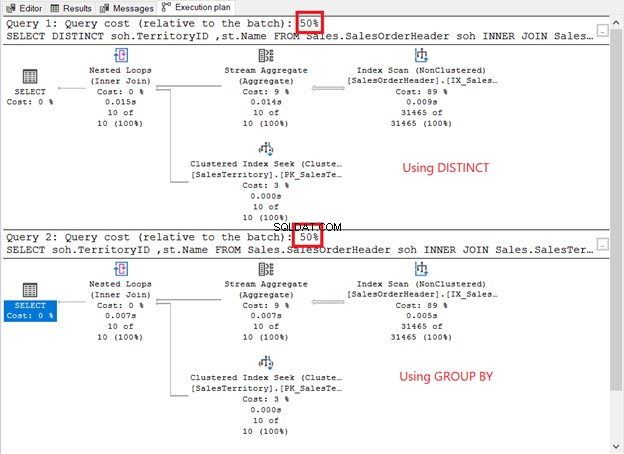
Wie schneiden sie ab?
- Sie haben dieselben Planoperatoren und dieselbe Reihenfolge.
- Die Betreiberkosten für beide und die Abfragekosten sind gleich.
Wenn Sie den QueryPlanHash prüfen Eigenschaften der 2 SELECT-Operatoren sind sie gleich. Daher hat der Abfrageoptimierer denselben Prozess verwendet, um dieselben Ergebnisse zurückzugeben.
Letztendlich können wir nicht sagen, dass die Verwendung von GROUP BY besser als DISTINCT ist, um eindeutige Werte zurückzugeben. Sie können dies beweisen, indem Sie die obigen Beispiele verwenden, um DISTINCT durch GROUP BY zu ersetzen.
Es ist jetzt eine Frage der Präferenz, welche Sie verwenden werden. Ich bevorzuge DISTINCT. Es teilt ausdrücklich die Absicht in der Abfrage mit – einzigartige Ergebnisse zu erzeugen. Und für mich dient GROUP BY zum Gruppieren von Ergebnissen mithilfe einer Aggregatfunktion. Diese Absicht ist auch klar und konsistent mit dem Schlüsselwort selbst. Ich weiß nicht, ob jemand anderes meine Abfragen eines Tages pflegen wird. Der Code sollte also klar sein.
Aber das ist noch nicht das Ende der Geschichte.
Wenn SQL DISTINCT nicht dasselbe ist wie GROUP BY
Ich habe nur meine Meinung geäußert, und dann das?
Es ist wahr. Sie werden nicht immer gleich sein. Betrachten Sie dieses Beispiel.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Obwohl die Ergebnismenge unsortiert ist, sind die Zeilen die gleichen wie im vorherigen Beispiel. Der einzige Unterschied ist die Verwendung einer Unterabfrage:
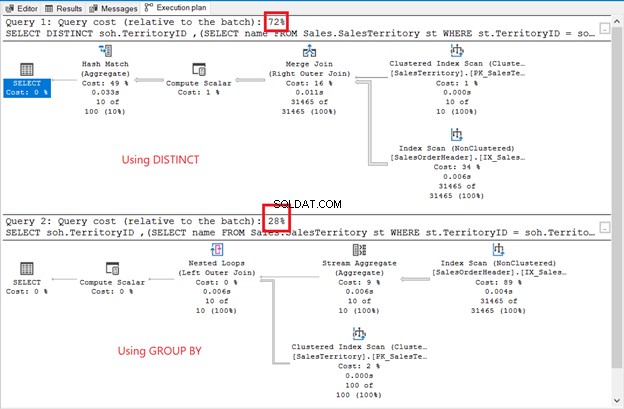
Die Unterschiede liegen auf der Hand:Betreiber, Abfragekosten, Gesamtplan. Diesmal gewinnt GROUP BY mit nur 28 % Abfragekosten. Aber hier ist die Sache.
Das Ziel ist, Ihnen zu zeigen, dass es auch anders geht. Das ist alles. Dies ist keinesfalls eine Empfehlung. Die Verwendung eines Joins hat einen besseren Ausführungsplan (siehe erneut Abbildung 6).
Das Endergebnis
Folgendes haben wir bisher gelernt:
- DISTINCT fügt einen Planoperator hinzu, um Duplikate zu entfernen.
- DISTINCT und GROUP BY ohne Aggregatfunktion führen zum selben Plan. Kurz gesagt, sie sind meistens gleich.
- Manchmal können DISTINCT und GROUP BY unterschiedliche Pläne haben, wenn eine Unterabfrage in der SELECT-Liste enthalten ist.
Ist SQL DISTINCT also gut oder schlecht beim Entfernen von Duplikaten in Ergebnissen?
Die Ergebnisse sagen, dass es gut ist. Es ist nicht besser oder schlechter als GROUP BY, weil die Pläne die gleichen sind. Aber es ist eine gute Angewohnheit, den Ausführungsplan zu überprüfen. Denken Sie von Anfang an an die Optimierung. Auf diese Weise werden Sie etwaige Unterschiede zwischen DISTINCT und GROUP BY erkennen.
Außerdem machen die modernen Tools diese Aufgabe viel einfacher. Beispielsweise verfügt ein beliebtes Produkt dbForge SQL Complete von Devart über eine spezielle Funktion, die Werte in den Aggregatfunktionen in der fertigen Ergebnismenge des SSMS-Ergebnisrasters berechnet. Dort sind auch die DISTINCT-Werte vorhanden.
Wie der Beitrag? Dann teilen Sie es bitte weiter, indem Sie es auf Ihren bevorzugten Social-Media-Plattformen teilen.
Verwandte Artikel für weitere Informationen
- SQL GROUP BY:3 einfache Tipps zum Gruppieren von Ergebnissen wie ein Profi
- SQL INSERT INTO SELECT:5 einfache Wege zum Umgang mit Duplikaten
- Was sind SQL-Aggregatfunktionen? (Einfache Tipps für Neulinge)
- SQL-Abfrageoptimierung:5 Kernfakten zur Steigerung von Abfragen