Bucketizing von Datums- und Zeitdaten beinhaltet das Organisieren von Daten in Gruppen, die feste Zeitintervalle für Analysezwecke darstellen. Häufig handelt es sich bei der Eingabe um Zeitreihendaten, die in einer Tabelle gespeichert sind, wobei die Zeilen Messungen darstellen, die in regelmäßigen Zeitintervallen durchgeführt wurden. Die Messungen könnten beispielsweise Temperatur- und Feuchtigkeitsmessungen sein, die alle 5 Minuten erfasst werden, und Sie möchten die Daten mithilfe von stündlichen Buckets gruppieren und Aggregate wie den Durchschnitt pro Stunde berechnen. Auch wenn Zeitreihendaten eine gängige Quelle für Bucket-basierte Analysen sind, ist das Konzept genauso relevant für alle Daten, die Datums- und Zeitattribute und zugehörige Kennzahlen beinhalten. Beispielsweise möchten Sie möglicherweise Verkaufsdaten in Geschäftsjahresgruppen organisieren und Aggregate wie den Gesamtverkaufswert pro Geschäftsjahr berechnen. In diesem Artikel behandle ich zwei Methoden zum Bucketizing von Datums- und Zeitdaten. Einer verwendet eine Funktion namens DATE_BUCKET, die zum Zeitpunkt des Schreibens nur in Azure SQL Edge verfügbar ist. Eine andere ist die Verwendung einer benutzerdefinierten Berechnung, die die DATE_BUCKET-Funktion emuliert, die Sie in jeder Version, Edition und Variante von SQL Server und Azure SQL-Datenbank verwenden können.
In meinen Beispielen verwende ich die Beispieldatenbank TSQLV5. Das Skript, das TSQLV5 erstellt und füllt, finden Sie hier und sein ER-Diagramm hier.
DATE_BUCKET
Wie bereits erwähnt, ist die DATE_BUCKET-Funktion derzeit nur in Azure SQL Edge verfügbar. SQL Server Management Studio verfügt bereits über IntelliSense-Unterstützung, wie in Abbildung 1 gezeigt:
 Abbildung 1:Intellisence-Unterstützung für DATE_BUCKET in SSMS
Abbildung 1:Intellisence-Unterstützung für DATE_BUCKET in SSMS
Die Syntax der Funktion lautet wie folgt:
DATE_BUCKET (Der Ursprung der Eingabe stellt einen Ankerpunkt auf dem Zeitpfeil dar. Es kann jeder der unterstützten Datums- und Zeitdatentypen sein. Wenn nicht angegeben, ist der Standardwert 1900, 1. Januar, Mitternacht. Sie können sich dann vorstellen, dass die Zeitachse in diskrete Intervalle unterteilt ist, beginnend mit dem Ursprungspunkt, wobei die Länge jedes Intervalls auf der Bucket-Breite der Eingaben basiert und Datumsteil . Ersteres ist die Menge und letzteres die Einheit. Um die Zeitachse beispielsweise in 2-Monats-Einheiten zu organisieren, würden Sie 2 angeben als Bucket-Breite Eingabe und Monat als Datumsteil Eingabe.
Der eingegebene Zeitstempel ist ein beliebiger Zeitpunkt, der mit dem ihn enthaltenden Bucket verknüpft werden muss. Sein Datentyp muss mit dem Datentyp des Ursprungs der Eingabe übereinstimmen . Der eingegebene Zeitstempel ist der Datums- und Uhrzeitwert, der den von Ihnen erfassten Kennzahlen zugeordnet ist.
Die Ausgabe der Funktion ist dann der Startpunkt des enthaltenden Buckets. Der Datentyp der Ausgabe ist der der Eingabe timestamp .
Wenn es nicht schon offensichtlich war, würden Sie normalerweise die DATE_BUCKET-Funktion als Gruppierungssatzelement in der GROUP BY-Klausel der Abfrage verwenden und sie natürlich auch in der SELECT-Liste zusammen mit aggregierten Kennzahlen zurückgeben.
Immer noch etwas verwirrt über die Funktion, ihre Eingaben und ihre Ausgabe? Vielleicht hilft ein konkretes Beispiel mit einer visuellen Darstellung der Funktionslogik. Ich beginne mit einem Beispiel, das Eingabevariablen verwendet, und zeige später in diesem Artikel die typischere Art und Weise, wie Sie es als Teil einer Abfrage für eine Eingabetabelle verwenden würden.
Betrachten Sie das folgende Beispiel:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Eine visuelle Darstellung der Funktionslogik finden Sie in Abbildung 2.
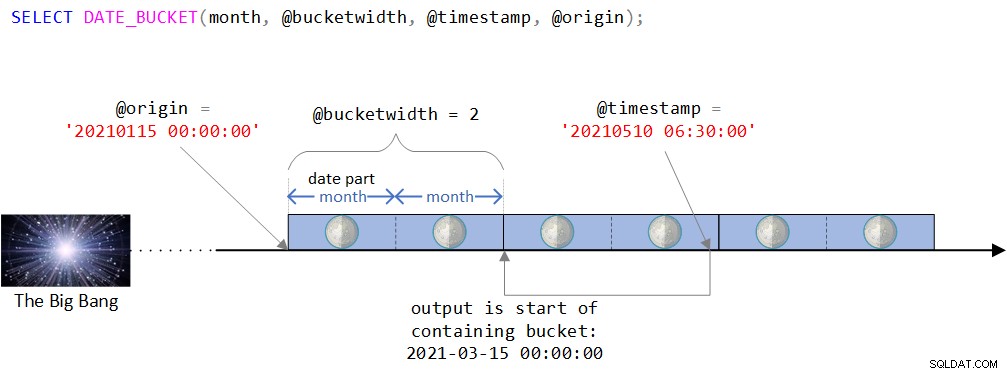 Abbildung 2:Visuelle Darstellung der Logik der DATE_BUCKET-Funktion
Abbildung 2:Visuelle Darstellung der Logik der DATE_BUCKET-Funktion
Wie Sie in Abbildung 2 sehen können, ist der Ursprungspunkt der DATETIME2-Wert am 15. Januar 2021, Mitternacht. Wenn dieser Ursprungspunkt etwas seltsam erscheint, haben Sie recht, wenn Sie intuitiv spüren, dass Sie normalerweise einen natürlicheren wie den Beginn eines Jahres oder den Beginn eines Tages verwenden würden. Tatsächlich sind Sie oft mit dem Standardwert zufrieden, der, wie Sie sich erinnern, der 1. Januar 1900 um Mitternacht ist. Ich wollte absichtlich einen weniger trivialen Ursprungspunkt verwenden, um bestimmte Komplexitäten diskutieren zu können, die bei Verwendung eines natürlicheren Ursprungs möglicherweise nicht relevant sind. Mehr dazu in Kürze.
Die Zeitachse wird dann beginnend mit dem Ursprungspunkt in diskrete 2-Monats-Intervalle unterteilt. Der Eingabezeitstempel ist der DATETIME2-Wert vom 10. Mai 2021, 6:30 Uhr.
Beachten Sie, dass der Eingabezeitstempel Teil des Buckets ist, der am 15. März 2021 um Mitternacht beginnt. Tatsächlich gibt die Funktion diesen Wert als Wert vom Typ DATETIME2 zurück:
--------------------------- 2021-03-15 00:00:00.0000000
DATE_BUCKET emulieren
Sofern Sie nicht Azure SQL Edge verwenden, müssten Sie, wenn Sie Datums- und Uhrzeitdaten in Buckets zusammenfassen möchten, vorerst Ihre eigene benutzerdefinierte Lösung erstellen, um zu emulieren, was die DATE_BUCKET-Funktion tut. Dies ist nicht übermäßig komplex, aber auch nicht zu einfach. Der Umgang mit Datums- und Uhrzeitdaten ist oft mit kniffliger Logik und Fallstricken verbunden, auf die Sie achten müssen.
Ich baue die Berechnung schrittweise auf und verwende die gleichen Eingaben, die ich mit dem DATE_BUCKET-Beispiel verwendet habe, das ich zuvor gezeigt habe:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Stellen Sie sicher, dass Sie diesen Teil vor jedem der Codebeispiele einfügen, die ich zeigen werde, wenn Sie den Code tatsächlich ausführen möchten.
In Schritt 1 verwenden Sie die DATEDIFF-Funktion, um die Differenz im Datumsteil zu berechnen Einheiten zwischen Ursprung und Zeitstempel . Ich bezeichne diesen Unterschied als diff1 . Dies geschieht mit folgendem Code:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Mit unseren Beispieleingaben gibt dieser Ausdruck 4 zurück.
Der knifflige Teil hier ist, dass Sie berechnen müssen, wie viele ganze Einheiten Datumsteil sind existieren zwischen Ursprung und Zeitstempel . Bei unseren Beispieleingaben liegen 3 ganze Monate zwischen den beiden und nicht 4. Der Grund, warum die DATEDIFF-Funktion 4 meldet, ist, dass sie bei der Berechnung der Differenz nur den angeforderten Teil der Eingaben und höhere Teile, aber keine niedrigeren Teile betrachtet . Wenn Sie also nach der Differenz in Monaten fragen, kümmert sich die Funktion nur um die Jahres- und Monatsteile der Eingaben und nicht um die Teile unterhalb des Monats (Tag, Stunde, Minute, Sekunde usw.). Tatsächlich liegen zwischen Januar 2021 und Mai 2021 4 Monate, aber nur 3 ganze Monate zwischen den vollständigen Eingaben.
Der Zweck von Schritt 2 besteht dann darin, zu berechnen, wie viele ganze Einheiten Datumsteil haben existieren zwischen Ursprung und Zeitstempel . Ich bezeichne diesen Unterschied als diff2 . Um dies zu erreichen, können Sie diff1 hinzufügen Einheiten des Datumsteils zum Ursprung . Wenn das Ergebnis größer als timestamp ist , subtrahieren Sie 1 von diff1 um diff2 zu berechnen , andernfalls 0 subtrahieren und daher diff1 verwenden als diff2 . Dies kann mit einem CASE-Ausdruck wie folgt erfolgen:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Dieser Ausdruck gibt 3 zurück, was die Anzahl der ganzen Monate zwischen den beiden Eingaben ist.
Erinnern Sie sich daran, dass ich zuvor erwähnt habe, dass ich in meinem Beispiel absichtlich einen Ursprungspunkt verwendet habe, der kein natürlicher ist, wie ein runder Beginn einer Periode, damit ich bestimmte Komplexitäten diskutieren kann, die dann relevant sein könnten. Zum Beispiel, wenn Sie Monat verwenden als Datumsteil und den genauen Beginn eines Monats (1 eines Monats um Mitternacht) als Ursprung, können Sie Schritt 2 getrost überspringen und diff1 verwenden als diff2 . Das liegt an der Herkunft + diff1 kann niemals> timestamp sein in einem solchen Fall. Mein Ziel ist es jedoch, eine logisch äquivalente Alternative zur DATE_BUCKET-Funktion bereitzustellen, die für jeden Ursprungspunkt, ob gemeinsam oder nicht, korrekt funktioniert. Daher füge ich die Logik für Schritt 2 in meine Beispiele ein, aber denken Sie daran, wenn Sie Fälle identifizieren, in denen dieser Schritt nicht relevant ist, können Sie den Teil, in dem Sie die Ausgabe des CASE-Ausdrucks subtrahieren, sicher entfernen.
In Schritt 3 bestimmen Sie, wie viele Einheiten des Datumsteils es gibt ganze Buckets, die zwischen Ursprung existieren und Zeitstempel . Ich bezeichne diesen Wert als diff3 . Dies kann mit der folgenden Formel erfolgen:
diff3 = diff2 / <bucket width> * <bucket width>
Der Trick dabei ist, dass Sie bei Verwendung des Divisionsoperators / in T-SQL mit ganzzahligen Operanden eine ganzzahlige Division erhalten. Beispielsweise ist 3 / 2 in T-SQL 1 und nicht 1,5. Der Ausdruck diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Dieser Ausdruck gibt 2 zurück, was die Anzahl der Monate in den gesamten 2-Monats-Buckets ist, die zwischen den beiden Eingaben liegen.
In Schritt 4, dem letzten Schritt, fügen Sie diff3 hinzu Einheiten des Datumsteils zum Ursprung um den Start des enthaltenden Buckets zu berechnen. Hier ist der Code, um dies zu erreichen:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Dieser Code generiert die folgende Ausgabe:
--------------------------- 2021-03-15 00:00:00.0000000
Wie Sie sich erinnern, ist dies dieselbe Ausgabe, die von der DATE_BUCKET-Funktion für dieselben Eingaben erzeugt wird.
Ich schlage vor, dass Sie diesen Ausdruck mit verschiedenen Eingaben und Teilen ausprobieren. Ich zeige hier ein paar Beispiele, aber Sie können gerne Ihre eigenen ausprobieren.
Hier ist ein Beispiel, in dem Ursprung liegt nur knapp vor timestamp im Monat:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Dieser Code generiert die folgende Ausgabe:
--------------------------- 2021-03-10 06:30:01.0000000
Beachten Sie, dass der Beginn des enthaltenden Buckets im März ist.
Hier ist ein Beispiel, in dem Ursprung liegt am gleichen Punkt innerhalb des Monats wie timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Dieser Code generiert die folgende Ausgabe:
--------------------------- 2021-05-10 06:30:00.0000000
Beachten Sie, dass der Beginn des Containers dieses Mal im Mai liegt.
Hier ist ein Beispiel mit 4-Wochen-Buckets:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Beachten Sie, dass der Code die Woche verwendet Teil diesmal.
Dieser Code generiert die folgende Ausgabe:
--------------------------- 2021-02-12 00:00:00.0000000
Hier ist ein Beispiel mit 15-Minuten-Buckets:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Dieser Code generiert die folgende Ausgabe:
--------------------------- 2021-02-03 21:15:00.0000000
Beachten Sie, dass der Teil Minute ist . In diesem Beispiel möchten Sie 15-Minuten-Buckets verwenden, die am Ende der Stunde beginnen, sodass ein Ausgangspunkt am Ende jeder Stunde funktionieren würde. Tatsächlich würde ein Ursprungspunkt mit einer Minuteneinheit von 00, 15, 30 oder 45 mit Nullen in den unteren Teilen mit jedem Datum und jeder Stunde funktionieren. Also der Standardwert, den die DATE_BUCKET-Funktion für die Eingabe Herkunft verwendet würde funktionieren. Wenn Sie den benutzerdefinierten Ausdruck verwenden, müssen Sie den Ursprungspunkt natürlich explizit angeben. Um also mit der DATE_BUCKET-Funktion zu sympathisieren, könnten Sie das Basisdatum um Mitternacht verwenden, wie ich es im obigen Beispiel tue.
Können Sie übrigens erkennen, warum dies ein gutes Beispiel wäre, bei dem es absolut sicher ist, Schritt 2 in der Lösung zu überspringen? Wenn Sie Schritt 2 tatsächlich überspringen, erhalten Sie den folgenden Code:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Der Code wird deutlich einfacher, wenn Schritt 2 nicht benötigt wird.
Gruppieren und Aggregieren von Daten nach Datum und Uhrzeit
Es gibt Fälle, in denen Sie Datums- und Uhrzeitdaten bündeln müssen, die keine ausgefeilten Funktionen oder unhandlichen Ausdrücke erfordern. Angenommen, Sie möchten die Ansicht Sales.OrderValues in der TSQLV5-Datenbank abfragen, die Daten jährlich gruppieren und die Gesamtzahl der Bestellungen und Werte pro Jahr berechnen. Natürlich reicht es aus, die YEAR(orderdate)-Funktion als Gruppierungssatzelement zu verwenden, etwa so:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Dieser Code generiert die folgende Ausgabe:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Aber was wäre, wenn Sie die Daten nach dem Geschäftsjahr Ihrer Organisation bündeln möchten? Einige Organisationen verwenden ein Geschäftsjahr für Buchhaltungs-, Budget- und Finanzberichtszwecke, das nicht mit dem Kalenderjahr übereinstimmt. Nehmen wir zum Beispiel an, dass das Geschäftsjahr Ihrer Organisation nach einem Steuerkalender von Oktober bis September abläuft und durch das Kalenderjahr gekennzeichnet ist, in dem das Geschäftsjahr endet. Ein Ereignis, das am 3. Oktober 2018 stattfand, gehört also zum Geschäftsjahr, das am 1. Oktober 2018 begann, am 30. September 2019 endete, und wird mit dem Jahr 2019 bezeichnet.
Dies ist ganz einfach mit der DATE_BUCKET-Funktion zu erreichen, etwa so:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Und hier ist der Code, der das benutzerdefinierte logische Äquivalent der DATE_BUCKET-Funktion verwendet:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Dieser Code generiert die folgende Ausgabe:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Ich habe hier Variablen für die Bucket-Breite und den Ursprungspunkt verwendet, um den Code allgemeiner zu machen, aber Sie können diese durch Konstanten ersetzen, wenn Sie immer dieselben verwenden, und dann die Berechnung entsprechend vereinfachen.
Nehmen Sie als geringfügige Abweichung davon an, dass Ihr Geschäftsjahr vom 15. Juli eines Kalenderjahres bis zum 14. Juli des nächsten Kalenderjahres läuft und durch das Kalenderjahr gekennzeichnet ist, zu dem der Beginn des Geschäftsjahres gehört. Ein Ereignis, das am 18. Juli 2018 stattfand, gehört also zum Geschäftsjahr 2018. Ein Ereignis, das am 14. Juli 2018 stattfand, gehört zum Geschäftsjahr 2017. Mit der Funktion DATE_BUCKET würden Sie dies folgendermaßen erreichen:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Die Änderungen gegenüber dem vorherigen Beispiel können Sie den Kommentaren entnehmen.
Und hier ist der Code, der das benutzerdefinierte logische Äquivalent zur DATE_BUCKET-Funktion verwendet:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Dieser Code generiert die folgende Ausgabe:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Natürlich gibt es alternative Methoden, die Sie in bestimmten Fällen anwenden können. Nehmen wir das vorletzte Beispiel, wo das Geschäftsjahr von Oktober bis September läuft und mit dem Kalenderjahr bezeichnet wird, in dem das Geschäftsjahr endet. In einem solchen Fall könnten Sie den folgenden, viel einfacheren Ausdruck verwenden:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Und dann würde Ihre Abfrage so aussehen:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Wenn Sie jedoch eine verallgemeinerte Lösung wünschen, die in viel mehr Fällen funktioniert und die Sie parametrisieren könnten, möchten Sie natürlich die allgemeinere Form verwenden. Wenn Sie Zugriff auf die DATE_BUCKET-Funktion haben, ist das großartig. Wenn nicht, können Sie das benutzerdefinierte logische Äquivalent verwenden.
Schlussfolgerung
Die DATE_BUCKET-Funktion ist eine ziemlich praktische Funktion, mit der Sie Datums- und Zeitdaten in Buckets zusammenfassen können. Es ist nützlich für die Handhabung von Zeitreihendaten, aber auch für die Zusammenfassung aller Daten, die Datums- und Zeitattribute beinhalten. In diesem Artikel habe ich erklärt, wie die DATE_BUCKET-Funktion funktioniert, und ein benutzerdefiniertes logisches Äquivalent bereitgestellt, falls die von Ihnen verwendete Plattform sie nicht unterstützt.