Als ich aufwuchs, liebte ich Spiele, die Gedächtnis- und Mustererkennungsfähigkeiten testeten. Einige meiner Freunde hatten Simon, während ich eine Fälschung namens Einstein hatte. Andere hatten einen Atari Touch Me, von dem ich schon damals wusste, dass es eine fragwürdige Namensentscheidung war. Heutzutage bedeutet Musterabgleich für mich etwas ganz anderes und kann ein teurer Teil alltäglicher Datenbankabfragen sein.
Als ich aufwuchs, liebte ich Spiele, die Gedächtnis- und Mustererkennungsfähigkeiten testeten. Einige meiner Freunde hatten Simon, während ich eine Fälschung namens Einstein hatte. Andere hatten einen Atari Touch Me, von dem ich schon damals wusste, dass es eine fragwürdige Namensentscheidung war. Heutzutage bedeutet Musterabgleich für mich etwas ganz anderes und kann ein teurer Teil alltäglicher Datenbankabfragen sein.
Ich bin kürzlich auf ein paar Kommentare zu Stack Overflow gestoßen, in denen ein Benutzer so als ob es eine Tatsache wäre, dass CHARINDEX performt besser als LEFT oder LIKE . In einem Fall zitierte die Person einen Artikel von David Lozinski, „SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX“. Ja, der Artikel zeigt das in dem erfundenen Beispiel CHARINDEX am besten abgeschnitten. Da ich solchen pauschalen Aussagen aber immer skeptisch gegenüberstehe und mir kein logischer Grund einfallen würde, warum ein String immer funktionieren würde besser abschneiden als andere, bei ansonsten gleichen Bedingungen , lief ich seine Tests. Tatsächlich hatte ich wiederholt unterschiedliche Ergebnisse auf meiner Maschine (zum Vergrößern anklicken):
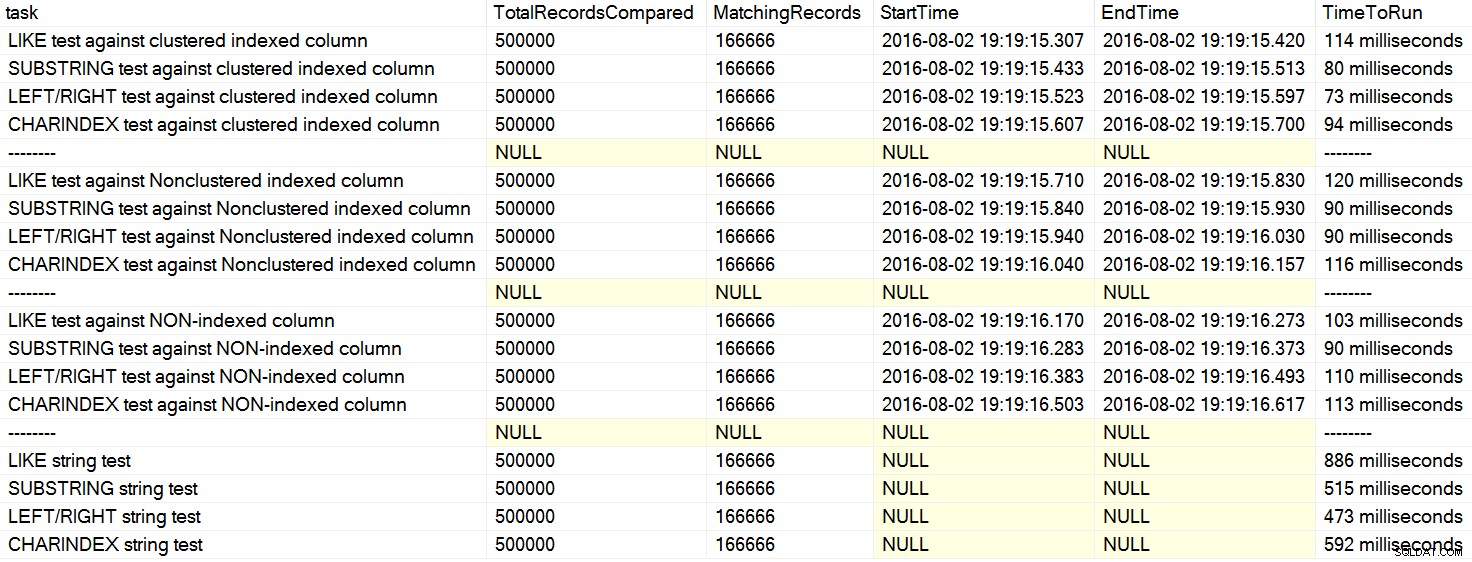 Auf meinem Rechner war CHARINDEX langsamer als LEFT/RIGHT/SUBSTRING.
Auf meinem Rechner war CHARINDEX langsamer als LEFT/RIGHT/SUBSTRING.
Davids Tests verglichen diese Abfragestrukturen im Wesentlichen – indem er entweder am Anfang oder am Ende eines Spaltenwerts nach einem Zeichenfolgenmuster suchte – in Bezug auf die Rohdauer:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Wenn Sie sich diese Klauseln ansehen, können Sie sehen, warum CHARINDEX ist möglicherweise weniger effizient – es werden mehrere zusätzliche Funktionsaufrufe ausgeführt, die die anderen Ansätze nicht ausführen müssen. Warum dieser Ansatz auf Davids Maschine am besten funktionierte, bin ich mir nicht sicher; Vielleicht hat er den Code genau wie gepostet ausgeführt und zwischen den Tests keine Puffer gelöscht, sodass die letzteren Tests von den zwischengespeicherten Daten profitierten.
Theoretisch CHARINDEX hätte einfacher ausgedrückt werden können, z. B.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Aber das schnitt in meinen Gelegenheitstests sogar noch schlechter ab.)
Und warum diese überhaupt OR sind Bedingungen, ich bin mir nicht sicher. Realistisch gesehen führen Sie die meiste Zeit eine von zwei Arten von Mustersuchen durch:beginnt mit oder enthält (Es ist weit weniger üblich, nach endet auf zu suchen ). Und in den meisten dieser Fälle neigt der Benutzer dazu, im Voraus anzugeben, ob er beginnt mit möchte oder enthält , zumindest bei jeder Anwendung, an der ich in meiner Karriere beteiligt war.
Es ist sinnvoll, diese als separate Abfragetypen zu trennen, anstatt ein ODER zu verwenden bedingt, da beginnt mit kann einen Index verwenden (falls vorhanden, der für eine Suche geeignet oder dünner als der Clustered-Index ist), während mit endet kann nicht (und ODER Bedingungen neigen dazu, dem Optimierer im Allgemeinen Schraubenschlüssel zuzuwerfen). Wenn ich LIKE vertrauen kann einen Index zu verwenden, wenn es möglich ist, und in den meisten oder allen Fällen so gut oder besser als die anderen oben genannten Lösungen zu sein, dann kann ich diese Logik sehr einfach machen. Eine gespeicherte Prozedur kann zwei Parameter annehmen – das Muster, nach dem gesucht wird, und die Art der durchzuführenden Suche (im Allgemeinen gibt es vier Arten von String-Übereinstimmungen – beginnt mit, endet mit, enthält oder exakte Übereinstimmung).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Dadurch wird jeder potenzielle Fall behandelt, ohne dynamisches SQL zu verwenden. die OPTION (RECOMPILE) ist da, weil Sie nicht möchten, dass ein für "endet mit" optimierter Plan (der mit ziemlicher Sicherheit gescannt werden muss) für eine "beginnt mit"-Abfrage wiederverwendet werden soll oder umgekehrt; Es wird auch sicherstellen, dass die Schätzungen korrekt sind ("beginnt mit S" hat wahrscheinlich eine ganz andere Kardinalität als "beginnt mit QX"). Selbst wenn Sie ein Szenario haben, in dem Benutzer in 99 % der Fälle einen Suchtyp auswählen, könnten Sie hier dynamisches SQL verwenden, anstatt es neu zu kompilieren, aber in diesem Fall wären Sie immer noch anfällig für Parameter-Sniffing. Bei vielen Abfragen mit bedingter Logik sind Neukompilierung und/oder vollständiges dynamisches SQL oft der sinnvollste Ansatz (siehe meinen Beitrag über "the Kitchen Sink").
Die Tests
Da ich mir seit kurzem die neue Beispieldatenbank WideWorldImporters anschaue, habe ich mich entschieden, dort meine eigenen Tests durchzuführen. Es war schwierig, eine anständige Tabelle ohne einen ColumnStore-Index oder eine temporäre Verlaufstabelle zu finden, aber Sales.Invoices , das 70.510 Zeilen hat, hat ein einfaches nvarchar(20) Spalte namens CustomerPurchaseOrderNumber die ich für die Tests verwendet habe. (Warum es nvarchar(20) ist Wenn jeder einzelne Wert eine 5-stellige Zahl ist, habe ich keine Ahnung, aber der Musterabgleich kümmert sich nicht wirklich darum, ob die darunter liegenden Bytes Zahlen oder Zeichenfolgen darstellen.)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Muster | Anzahl Zeilen | % der Tabelle |
| Beginnt mit "1" | 70.505 | 99,993 % |
| Beginnt mit "2" | 5 | 0,007 % |
| Endet mit "5" | 6.897 | 9,782 % |
| Endet auf "30" | 749 | 1,062 % |
Ich habe in den Werten in der Tabelle herumgestochert, um mehrere Suchkriterien zu finden, die zu einer sehr unterschiedlichen Anzahl von Zeilen führen würden, um hoffentlich ein Kipppunktverhalten bei einem bestimmten Ansatz aufzudecken. Rechts sind die Suchanfragen, auf denen ich gelandet bin.
Ich wollte mir selbst beweisen, dass das obige Verfahren insgesamt für alle möglichen Suchen unbestreitbar besser war als alle Abfragen, die OR verwenden Bedingungen, unabhängig davon, ob sie LIKE verwenden , LEFT/RIGHT , SUBSTRING , oder CHARINDEX . Ich habe Davids grundlegende Abfragestrukturen genommen und sie in gespeicherte Prozeduren eingefügt (mit der Einschränkung, dass ich "contains" ohne seine Eingabe nicht wirklich testen kann und dass ich sein OR machen musste Logik etwas flexibler, um die gleiche Anzahl von Zeilen zu erhalten), zusammen mit einer Version meiner Logik. Ich hatte auch vor, die Prozeduren mit und ohne einen Index zu testen, den ich in der Suchspalte erstellen würde, und sowohl unter einem warmen als auch einem kalten Cache.
Die Verfahren:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Ich habe auch Versionen von Davids Prozeduren erstellt, die seiner ursprünglichen Absicht entsprechen, wobei ich annehme, dass die Anforderung wirklich darin besteht, alle Zeilen zu finden, in denen das Suchmuster am Anfang * oder * am Ende der Zeichenfolge steht. Ich tat dies einfach, damit ich die Leistung der verschiedenen Ansätze genau so vergleichen konnte, wie er sie geschrieben hatte, um zu sehen, ob meine Ergebnisse in diesem Datensatz mit meinen Tests seines ursprünglichen Skripts auf meinem System übereinstimmen würden. In diesem Fall gab es keinen Grund, eine eigene Version einzuführen, da sie einfach zu seinem LIKE % + @pattern OR LIKE @pattern + % passen würde Variante.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Mit den vorhandenen Verfahren konnte ich den Testcode generieren – was oft genauso viel Spaß macht wie das ursprüngliche Problem. Zuerst eine Logging-Tabelle:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Dann der Code, der Select-Operationen unter Verwendung der verschiedenen Prozeduren und Argumente ausführt:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Ergebnisse
Ich habe diese Tests auf einer virtuellen Maschine mit Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149) mit 4 CPUs und 32 GB RAM ausgeführt. Ich habe jede Testreihe 11 Mal durchgeführt; Bei den Warm-Cache-Tests habe ich die ersten Ergebnisse verworfen, weil einige davon wirklich Cold-Cache-Tests waren.
Ich hatte Probleme damit, die Ergebnisse grafisch darzustellen, um Muster zu zeigen, hauptsächlich weil es einfach keine Muster gab. Fast jede Methode war in einem Szenario die beste und in einem anderen die schlechteste. In den folgenden Tabellen habe ich die leistungsstärksten und leistungsschwächsten Verfahren für jede Spalte hervorgehoben, und Sie können sehen, dass die Ergebnisse alles andere als schlüssig sind:
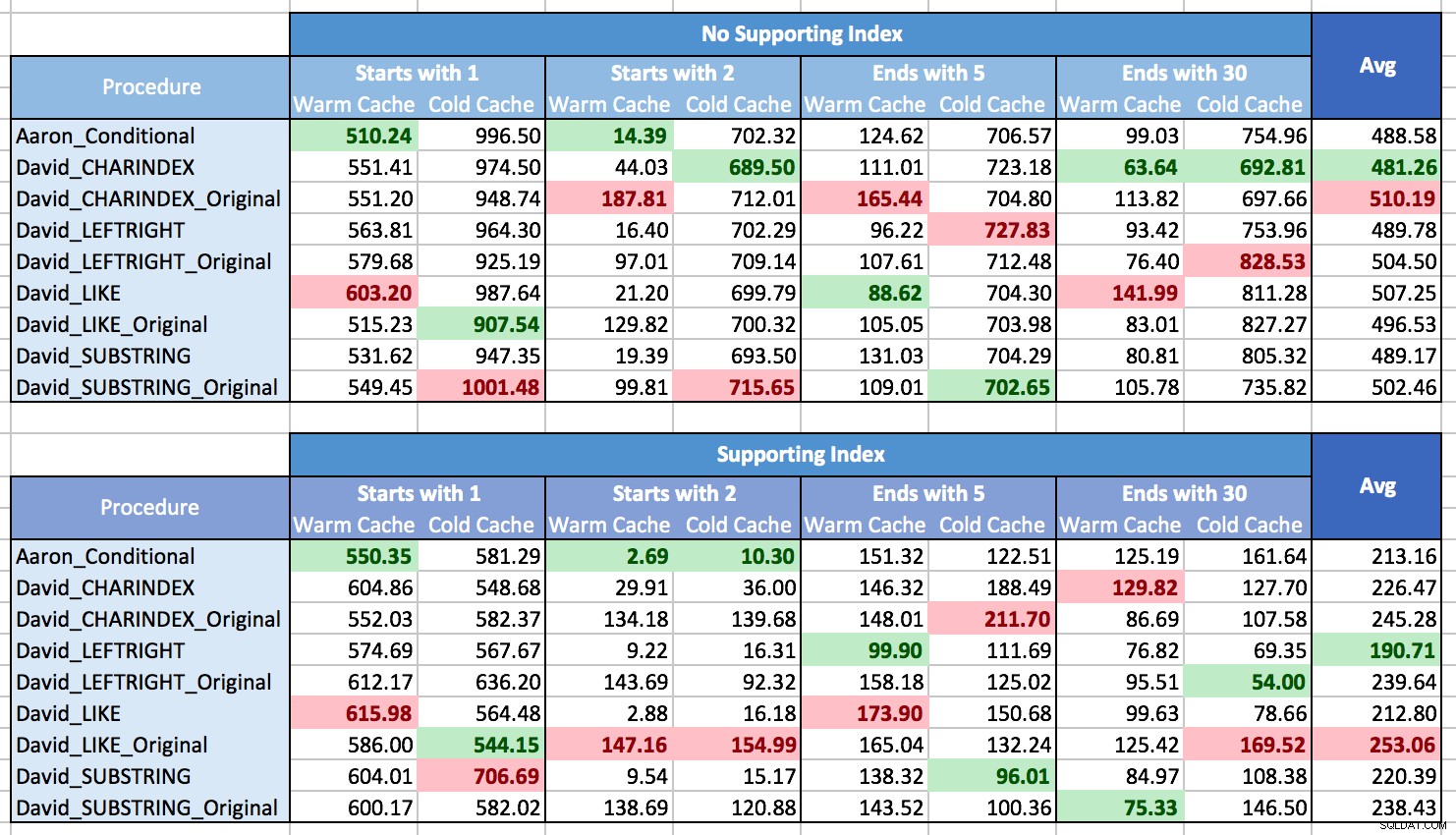 In diesen Tests hat CHARINDEX manchmal gewonnen und manchmal nicht.
In diesen Tests hat CHARINDEX manchmal gewonnen und manchmal nicht.
Was ich gelernt habe, ist, dass es im Großen und Ganzen, wenn Sie mit vielen verschiedenen Situationen konfrontiert werden (verschiedene Arten von Mustervergleichen, mit oder ohne unterstützendem Index, Daten können nicht immer im Speicher sein), wirklich keine gibt klarer Gewinner, und der Leistungsbereich ist im Durchschnitt ziemlich klein (da ein warmer Cache nicht immer geholfen hat, würde ich vermuten, dass die Ergebnisse mehr von den Kosten für das Rendern der Ergebnisse als von deren Abruf beeinflusst wurden). Verlassen Sie sich bei einzelnen Szenarien nicht auf meine Tests; Führen Sie anhand Ihrer Hardware, Konfiguration, Daten und Nutzungsmuster selbst einige Benchmarks durch.
Warnhinweise
Einige Dinge, die ich bei diesen Tests nicht berücksichtigt habe:
- Geclustert vs. nicht geclustert . Da es unwahrscheinlich ist, dass sich Ihr gruppierter Index in einer Spalte befindet, in der Sie Mustervergleichssuchen am Anfang oder Ende der Zeichenfolge durchführen, und da eine Suche in beiden Fällen weitgehend gleich ist (und die Unterschiede zwischen Scans weitgehend Funktion der Indexbreite vs. Tabellenbreite sein), habe ich die Leistung nur mit einem nicht gruppierten Index getestet. Wenn Sie bestimmte Szenarien haben, in denen dieser Unterschied allein einen großen Unterschied beim Musterabgleich ausmacht, lassen Sie es mich bitte wissen.
- MAX-Typen . Wenn Sie in
varchar(max)nach Zeichenfolgen suchen /nvarchar(max), diese können nicht indiziert werden. Wenn Sie also keine berechneten Spalten verwenden, um Teile des Werts darzustellen, ist ein Scan erforderlich – unabhängig davon, ob Sie nach beginnt mit, endet mit oder enthält suchen. Ob der Performance-Overhead mit der Größe des Strings korreliert oder einfach typbedingt zusätzlicher Overhead entsteht, habe ich nicht getestet.
- Volltextsuche . Ich habe hier und dort mit dieser Funktion gespielt, und ich kann sie buchstabieren, aber wenn mein Verständnis richtig ist, könnte dies nur hilfreich sein, wenn Sie nach ganzen durchgehenden Wörtern suchen und sich nicht darum kümmern, wo in der Zeichenfolge sie sich befinden gefunden. Es wäre nicht sinnvoll, wenn Sie Textabsätze speichern und alle finden möchten, die mit "Y" beginnen, das Wort "the" enthalten oder mit einem Fragezeichen enden.
Zusammenfassung
Die einzige pauschale Aussage, die ich von diesem Test wegnehmen kann, ist, dass es keine pauschalen Aussagen darüber gibt, wie der String-Musterabgleich am effizientesten durchgeführt werden kann. Obwohl ich meinem bedingten Ansatz für Flexibilität und Wartbarkeit voreingenommen bin, war es nicht in allen Szenarien der Gewinner der Leistung. Wenn ich nicht auf einen Leistungsengpass stoße und alle Möglichkeiten verfolge, werde ich meinen Ansatz für Konsistenz weiterverfolgen. Wie ich oben vorgeschlagen habe, sollten Sie, wenn Sie ein sehr enges Szenario haben und sehr empfindlich auf kleine Unterschiede in der Dauer reagieren, Ihre eigenen Tests durchführen, um festzustellen, welche Methode für Sie durchweg die beste Leistung bringt.