Im vorherigen Teil haben wir die Sicherungszeit und Effektivität der Komprimierung für verschiedene Sicherungskomprimierungsstufen und -methoden getestet. In diesem Blog werden wir unsere Bemühungen fortsetzen und über weitere Einstellungen sprechen, die wahrscheinlich die meisten Benutzer nicht wirklich ändern, aber sie können einen sichtbaren Einfluss auf den Backup-Prozess haben.
Das Setup ist das gleiche wie im vorherigen Teil:Wir werden MariaDB-Master-Slave-Replikationscluster mit ProxySQL und Keepalived verwenden.
Wir haben mit Sysbench 7,6 GB Daten generiert:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 preparePIGZ verwenden
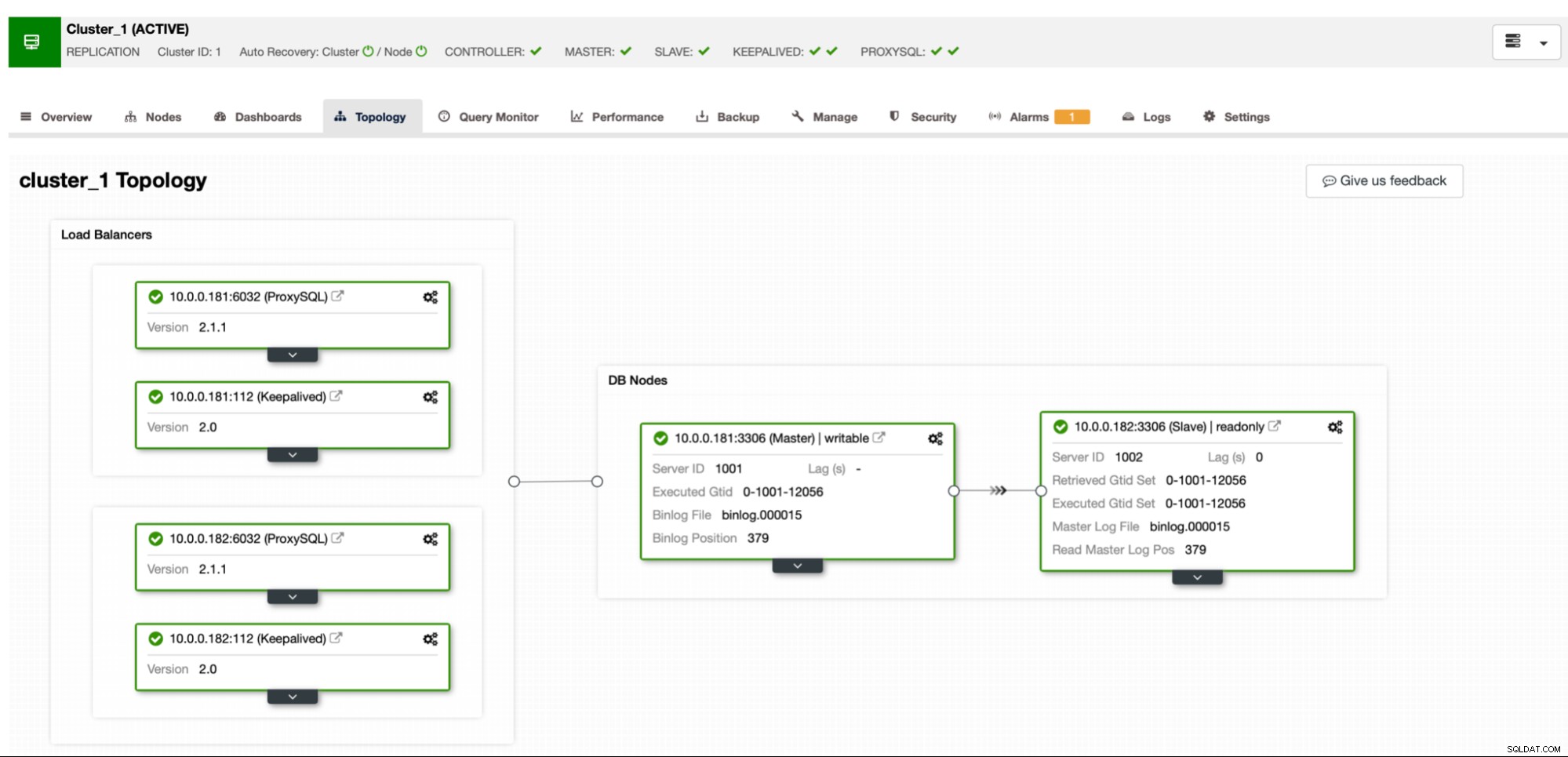
Dieses Mal werden wir Use PIGZ for parallel gzip für unsere Backups aktivieren. Wie zuvor werden wir jede Komprimierungsstufe testen, um zu sehen, wie sie sich verhält.
Wir speichern das Backup lokal auf der Instanz, mit der die Instanz konfiguriert ist 4 vCPUs.
Das Ergebnis ist irgendwie erwartet. Der Backup-Prozess war deutlich schneller als bei Verwendung nur eines einzelnen CPU-Kerns. Die Größe des Backups bleibt ziemlich gleich, es gibt keinen wirklichen Grund, sich wesentlich zu ändern. Es ist klar, dass die Verwendung von pigz die Sicherungszeit verbessert. Es gibt jedoch eine Schattenseite bei der Verwendung von parallelem gzip, und zwar die CPU-Auslastung:
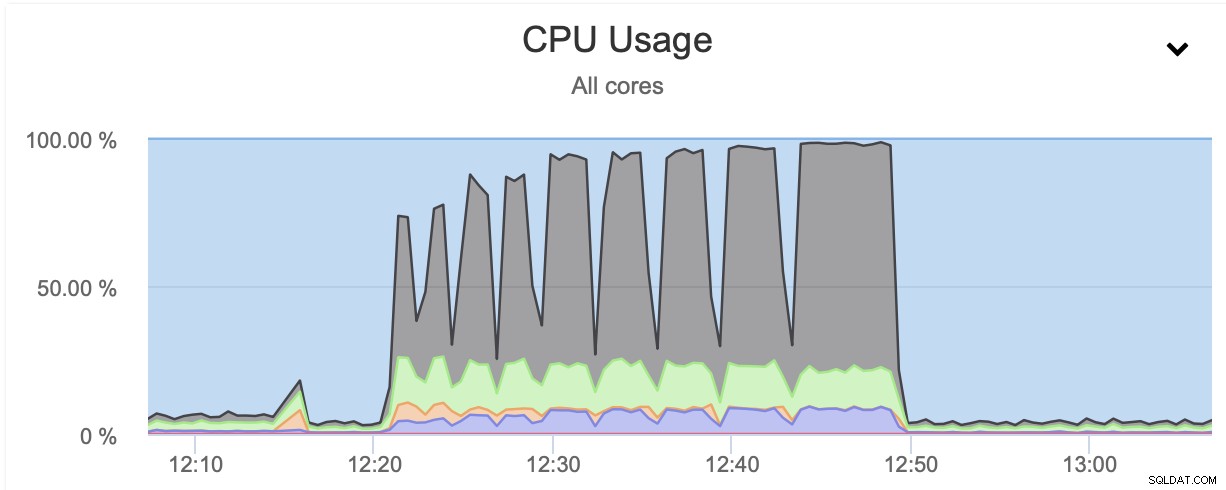
Wie Sie sehen können, schießt die CPU-Auslastung in die Höhe und erreicht fast 100 % für höhere Kompressionsstufen. Eine Erhöhung der CPU-Auslastung auf dem Datenbankserver ist nicht unbedingt die beste Idee, da wir normalerweise möchten, dass die CPU für die Datenbank verfügbar ist. Wenn wir andererseits zufällig ein Replikat haben, das für Backups und, sagen wir, schwerere Abfragen vorgesehen ist – ein Knoten, der nicht für die Bereitstellung von OLTP-Datenverkehr verwendet wird, können wir parallel gzip aktivieren, um das Backup erheblich zu reduzieren Zeit. Wie deutlich zu sehen ist, ist es keine Option für jedermann, aber es ist definitiv etwas, das Sie in einigen bestimmten Szenarien nützlich finden können. Denken Sie nur daran, dass Sie die CPU-Auslastung nachverfolgen müssen, da sie sich auf die Latenz der Abfragen auswirkt und sich dadurch auf die Benutzererfahrung auswirkt - etwas, das wir bei der Arbeit mit den Datenbanken immer berücksichtigen sollten.
Xtrabackup-Parallelkopie-Threads
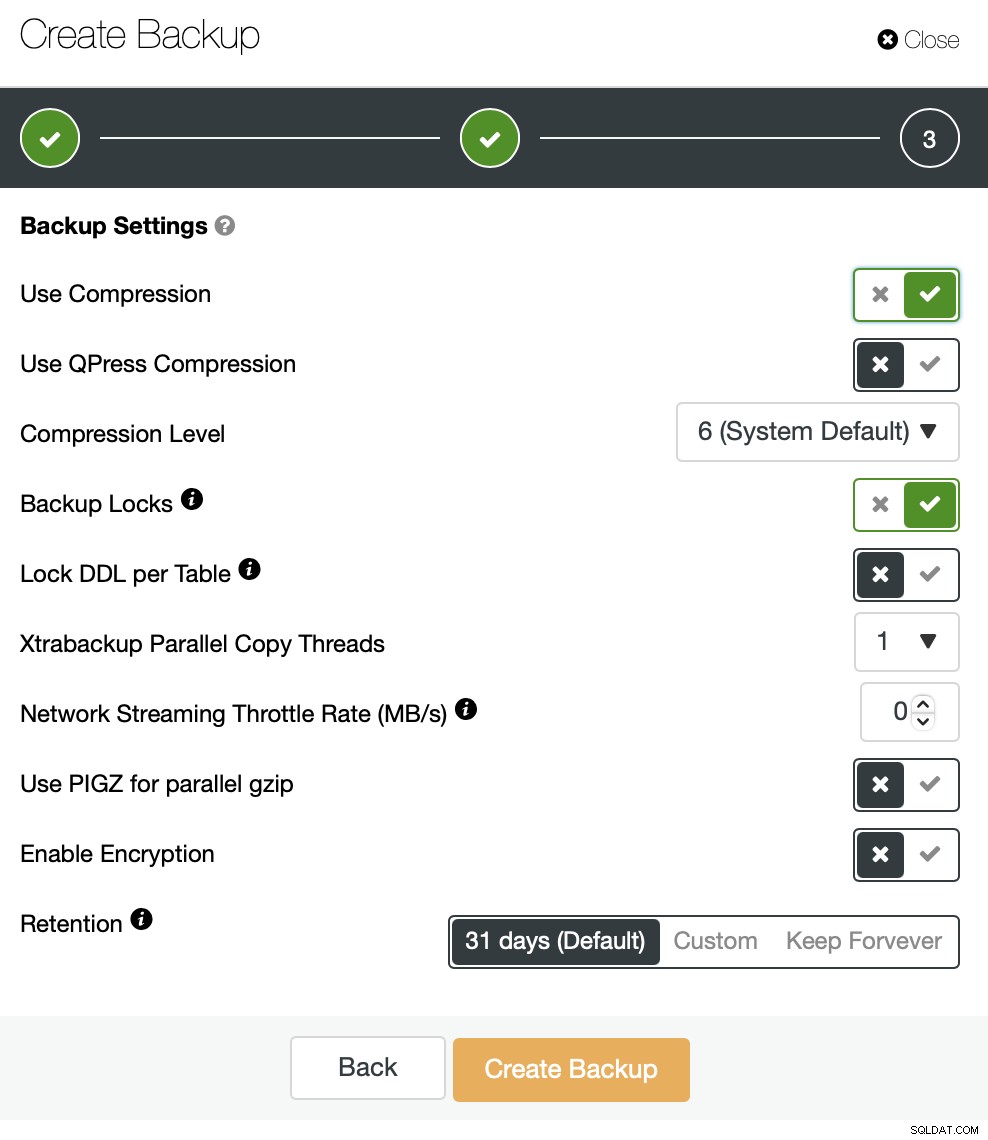
Eine weitere Einstellung, die wir hervorheben möchten, sind Xtrabackup Parallel Copy Threads. Um zu verstehen, was es ist, lassen Sie uns ein wenig über die Funktionsweise von Xtrabackup (oder MariaBackup) sprechen. Kurz gesagt, diese Tools führen zwei Aktionen gleichzeitig aus. Sie kopieren die Daten, physische Dateien, vom Datenbankserver zum Backup-Speicherort, während sie die InnoDB-Redo-Logs auf Aktualisierungen überwachen. Das Backup besteht aus den Dateien und der Aufzeichnung aller Änderungen an InnoDB, die während des Backup-Prozesses vorgenommen wurden. Dies ermöglicht mit Backup-Sperren oder FLUSH TABLES WITH READ LOCK eine konsistente Sicherung zu dem Zeitpunkt, an dem die Datenübertragung abgeschlossen ist. Xtrabackup Parallel Copy Threads definieren die Anzahl der Threads, die die Datenübertragung durchführen. Wenn wir es auf 1 setzen, wird eine Datei gleichzeitig kopiert. Wenn wir es auf 8 setzen, können theoretisch bis zu 8 Dateien gleichzeitig übertragen werden. Natürlich muss der Speicher schnell genug sein, um von einer solchen Einstellung tatsächlich zu profitieren. Wir werden mehrere Tests durchführen und Xtrabackup Parallel Copy Threads von 1 bis 2 und 4 auf 8 ändern. Wir werden Tests auf Komprimierungsstufe 6 (Standardeinstellung) mit und ohne aktiviertem parallelem gzip durchführen.
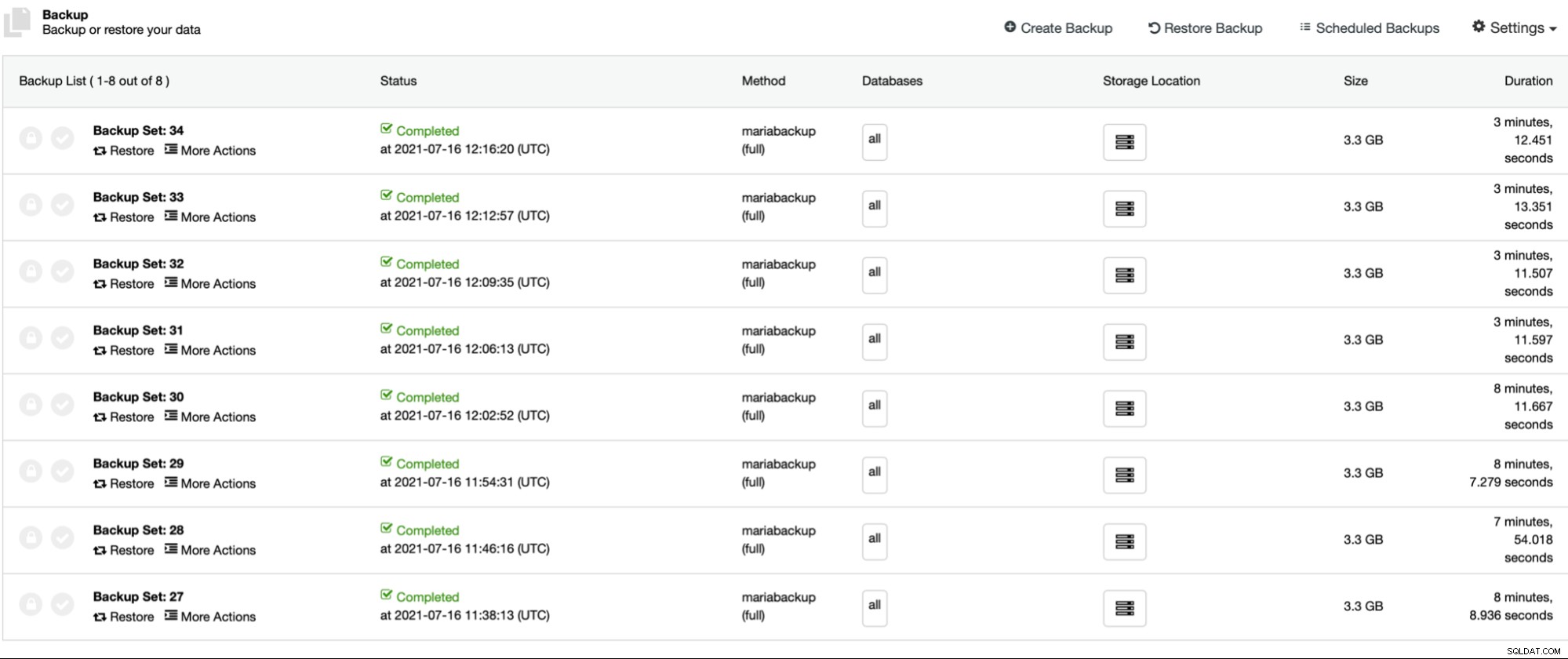
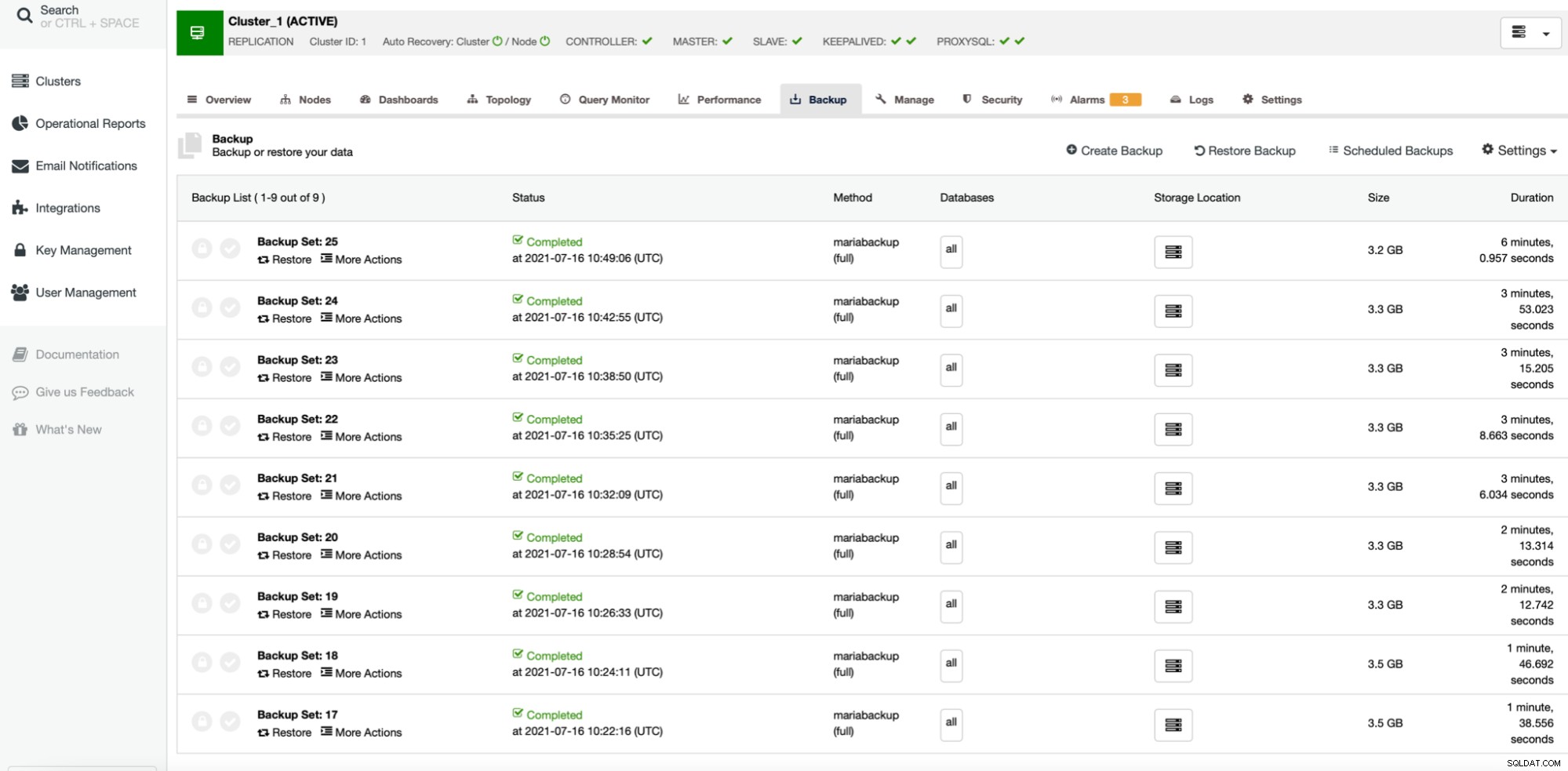
Die ersten vier Backups (27 - 30) wurden ohne paralleles gzip erstellt, beginnend mit 1 bis 2, 4 und 8 Parallelkopie-Threads. Dann wiederholten wir den gleichen Vorgang für die Backups 31 bis 34, diesmal mit parallelem gzip. Wie Sie sehen, gibt es in unserem Fall kaum einen Unterschied zwischen den parallelen Kopierthreads. Dies wird höchstwahrscheinlich wirkungsvoller sein, wenn wir die Größe des Datensatzes erhöhen würden. Es würde auch die Sicherungsleistung verbessern, wenn wir einen schnelleren und zuverlässigeren Speicher verwenden würden. Wie üblich wird Ihre Laufleistung variieren und in verschiedenen Umgebungen kann diese Einstellung den Backup-Prozess stärker beeinflussen als das, was wir hier sehen.
Netzwerkdrosselung
Schließlich möchten wir in diesem Teil unserer kurzen Serie über die Möglichkeit sprechen, die Netzwerknutzung zu drosseln.
Wie Sie vielleicht gesehen haben, können Sicherungen lokal auf dem Knoten oder gespeichert werden es kann auch zum Controller-Host gestreamt werden. Dies geschieht über das Netzwerk und standardmäßig „so schnell wie möglich“.
In einigen Fällen, in denen Ihr Netzwerkdurchsatz begrenzt ist (z. B. Cloud-Instanzen), möchten Sie möglicherweise die durch MariaBackup verursachte Netzwerknutzung reduzieren, indem Sie eine Begrenzung für die Netzwerkübertragung festlegen. Wenn Sie dies tun, verwendet ClusterControl das Tool „pv“, um die für den Prozess verfügbare Bandbreite zu begrenzen.
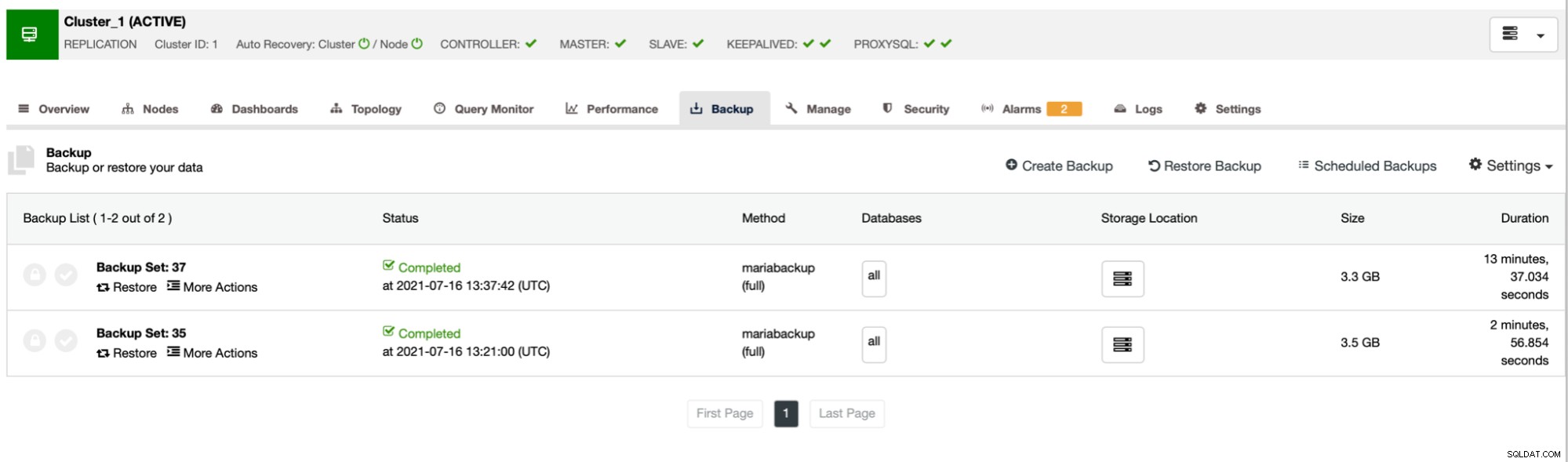
Wie Sie sehen können, dauerte die erste Sicherung etwa 3 Minuten, aber als wir drosselte den Netzwerkdurchsatz, die Sicherung dauerte 13 Minuten und 37 Sekunden.
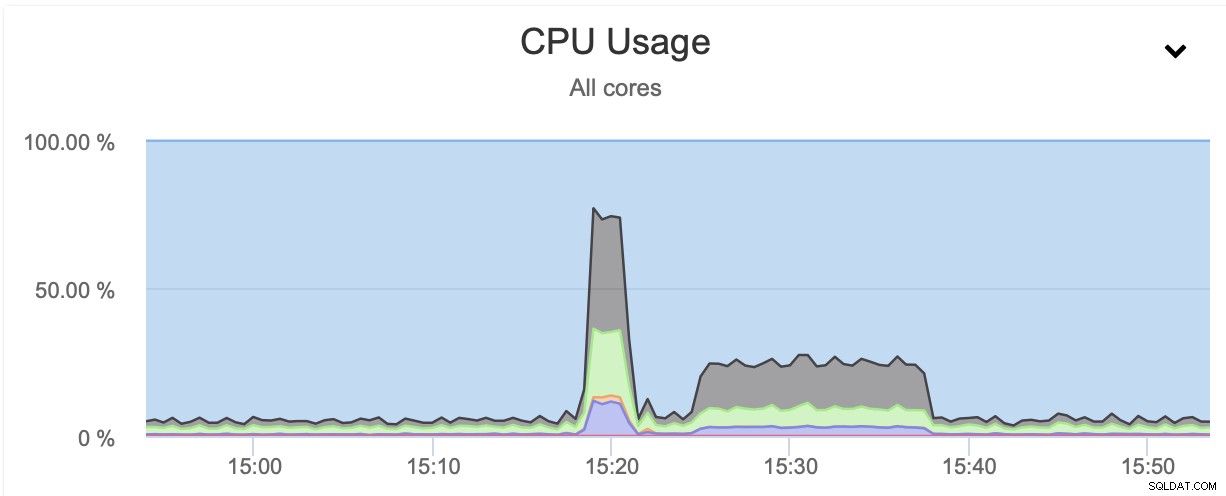
In beiden Fällen haben wir pigz und die Komprimierungsstufe 1 verwendet. Die Grafik oben zeigt, dass die Drosselung des Netzwerks auch die CPU-Auslastung reduziert. Es ist sinnvoll, wenn pigz warten muss, bis das Netzwerk die Daten überträgt, muss es die CPU nicht stark belasten, da es die meiste Zeit im Leerlauf ist.
Hoffentlich fanden Sie diesen kurzen Blog interessant und ermutigt Sie vielleicht, mit einigen der nicht so häufig verwendeten Funktionen und Optionen von MariaBackup zu experimentieren. Wenn Sie einige Ihrer Erfahrungen teilen möchten, würden wir uns freuen, von Ihnen in den Kommentaren unten zu hören.



