In einem früheren Beitrag haben wir besprochen, wie Sie den Failover-Prozess in ClusterControl durch die Verwendung von Whitelists und Blacklists steuern können. In diesem Beitrag werden wir ein ähnliches Konzept diskutieren. Aber dieses Mal konzentrieren wir uns auf Integrationen mit externen Skripten und Anwendungen durch zahlreiche Hooks, die von ClusterControl zur Verfügung gestellt werden.
Infrastrukturumgebungen können auf unterschiedliche Weise erstellt werden, da für ein bestimmtes Puzzleteil oft viele Optionen zur Auswahl stehen. Wie definieren wir, in welchen Datenbankknoten geschrieben werden soll? Verwenden Sie virtuelle IP? Verwenden Sie eine Art Diensterkennung? Vielleicht gehen Sie mit DNS-Einträgen und ändern die A-Einträge bei Bedarf? Was ist mit der Proxy-Schicht? Verlassen Sie sich bei Ihren Proxys auf den „read_only“-Wert, um über den Writer zu entscheiden, oder nehmen Sie die erforderlichen Änderungen direkt in der Konfiguration des Proxys vor? Wie geht Ihre Umgebung mit Umschaltungen um? Können Sie es einfach ausführen oder müssen Sie vorher einige vorbereitende Maßnahmen ergreifen? Zum Beispiel einige andere Prozesse anhalten, bevor Sie tatsächlich umschalten können?
Es ist nicht möglich, dass eine Failover-Software so vorkonfiguriert wird, dass sie alle unterschiedlichen Konfigurationen abdeckt, die Benutzer erstellen können. Dies ist der Hauptgrund dafür, verschiedene Möglichkeiten zum Einhängen in den Failover-Prozess bereitzustellen. Auf diese Weise können Sie es anpassen und es ermöglichen, alle Feinheiten Ihres Setups zu handhaben. In diesem Blogbeitrag werden wir untersuchen, wie der Failover-Prozess von ClusterControl mithilfe verschiedener Pre- und Post-Failover-Skripte angepasst werden kann. Wir werden auch einige Beispiele dafür diskutieren, was mit einer solchen Anpassung erreicht werden kann.
ClusterControl integrieren
ClusterControl stellt mehrere Hooks bereit, die zum Einbinden externer Skripte verwendet werden können. Unten finden Sie eine Liste mit Erklärungen.
- Replication_onfail_failover_script – Dieses Skript wird ausgeführt, sobald festgestellt wurde, dass ein Failover erforderlich ist. Wenn das Skript einen Wert ungleich Null zurückgibt, wird das Failover abgebrochen. Wenn das Skript definiert ist, aber nicht gefunden wird, wird das Failover abgebrochen. Dem Skript werden vier Argumente übergeben:arg1='alle Server' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' und wie folgt übergeben:'scriptname arg1 arg2 arg3 arg4'. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_pre_failover_script – Dieses Skript wird ausgeführt, bevor das Failover stattfindet, aber nachdem ein Kandidat gewählt wurde und es möglich ist, den Failover-Prozess fortzusetzen. Wenn das Skript einen Wert ungleich Null zurückgibt, wird das Failover abgebrochen. Wenn das Skript definiert ist, aber nicht gefunden wird, wird das Failover abgebrochen. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_post_failover_script – Dieses Skript wird ausgeführt, nachdem das Failover stattgefunden hat. Wenn das Skript einen Wert ungleich Null zurückgibt, wird eine Warnung in das Auftragsprotokoll geschrieben. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_post_unsuccessful_failover_script – Dieses Skript wird ausgeführt, nachdem der Failover-Versuch fehlgeschlagen ist. Wenn das Skript einen Wert ungleich Null zurückgibt, wird eine Warnung in das Auftragsprotokoll geschrieben. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_failed_reslave_failover_script - dieses Skript wird ausgeführt, nachdem ein neuer Master hochgestuft wurde und wenn das Reslaving der Slaves zum neuen Master fehlschlägt. Wenn das Skript einen Wert ungleich Null zurückgibt, wird eine Warnung in das Auftragsprotokoll geschrieben. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_pre_switchover_script - Dieses Skript wird ausgeführt, bevor die Umschaltung stattfindet. Wenn das Skript einen Wert ungleich Null zurückgibt, erzwingt es ein Scheitern der Umschaltung. Wenn das Skript definiert ist, aber nicht gefunden wird, wird die Umschaltung abgebrochen. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
- Replication_post_switchover_script - dieses Skript wird ausgeführt, nachdem die Umschaltung stattgefunden hat. Wenn das Skript einen Wert ungleich Null zurückgibt, wird eine Warnung in das Auftragsprotokoll geschrieben. Das Skript muss auf dem Controller erreichbar und ausführbar sein.
Wie Sie sehen können, decken die Hooks die meisten Fälle ab, in denen Sie möglicherweise einige Aktionen ausführen möchten – vor und nach einem Switchover, vor und nach einem Failover, wenn das Reslave fehlgeschlagen ist oder wenn das Failover fehlgeschlagen ist. Alle Skripte werden mit vier Argumenten aufgerufen (die im Skript behandelt werden können oder nicht, es ist nicht erforderlich, dass das Skript alle verwendet):alle Server, Hostname (oder IP - wie in ClusterControl definiert) des alten Masters, Hostname (oder IP - wie in ClusterControl definiert) des Master-Kandidaten und der vierte, alle Replikate des alten Masters. Diese Optionen sollten es ermöglichen, die Mehrheit der Fälle zu bearbeiten.
Alle diese Hooks sollten in einer Konfigurationsdatei für einen bestimmten Cluster definiert werden (/etc/cmon.d/cmon_X.cnf, wobei X die ID des Clusters ist). Ein Beispiel könnte so aussehen:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shAufgerufene Skripte müssen natürlich ausführbar sein, sonst kann cmon sie nicht ausführen. Nehmen wir uns jetzt einen Moment Zeit und gehen den Failover-Prozess in ClusterControl durch und sehen, wann die externen Skripte ausgeführt werden.
Failover-Prozess in ClusterControl
Wir haben alle verfügbaren Hooks definiert:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shDanach müssen Sie den cmon-Prozess neu starten. Sobald dies erledigt ist, können wir das Failover testen. Die ursprüngliche Topologie sieht so aus:
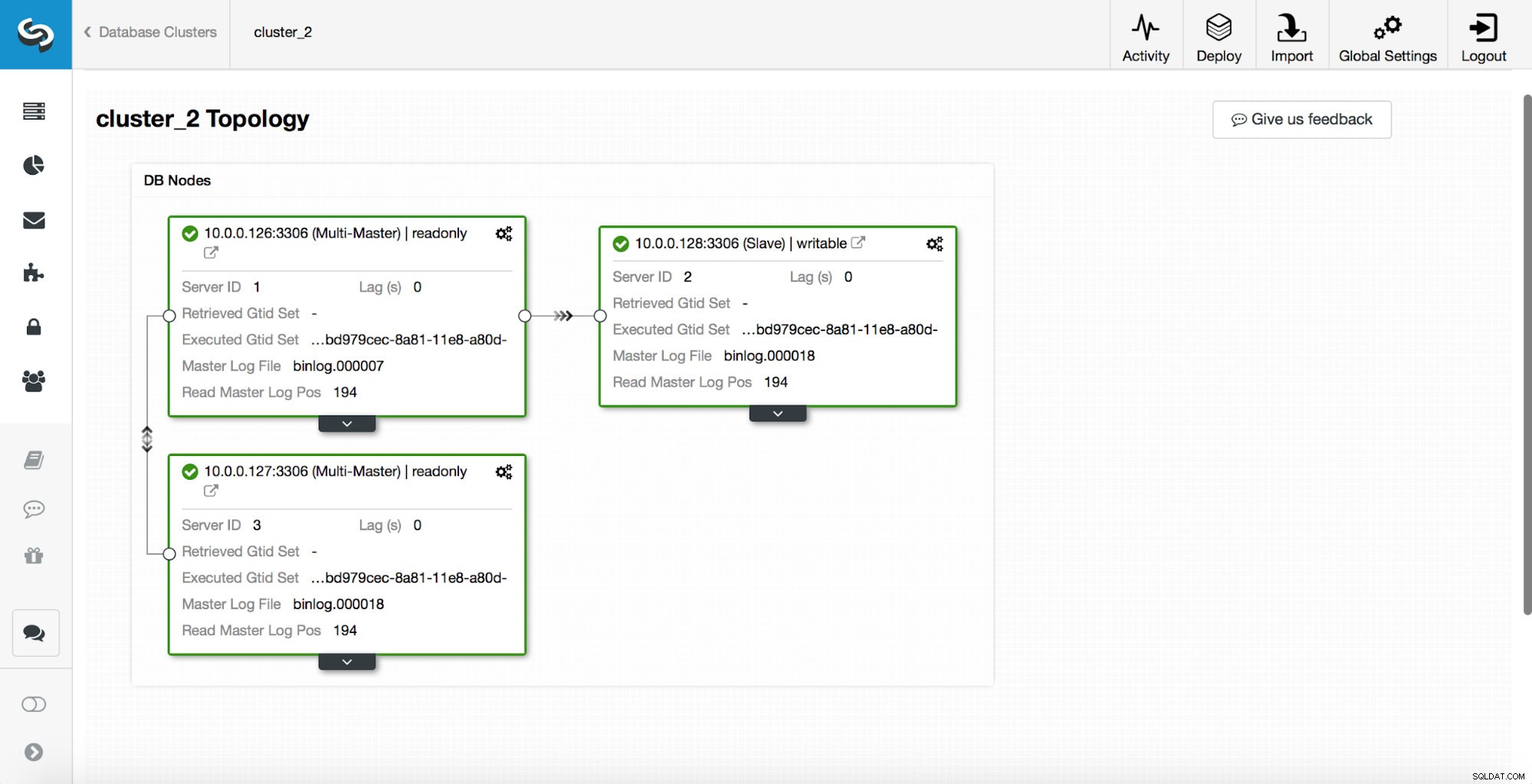
Ein Master wurde beendet und der Failover-Prozess gestartet. Bitte beachten Sie, dass die neueren Protokolleinträge ganz oben stehen, sodass Sie das Failover von unten nach oben verfolgen sollten.
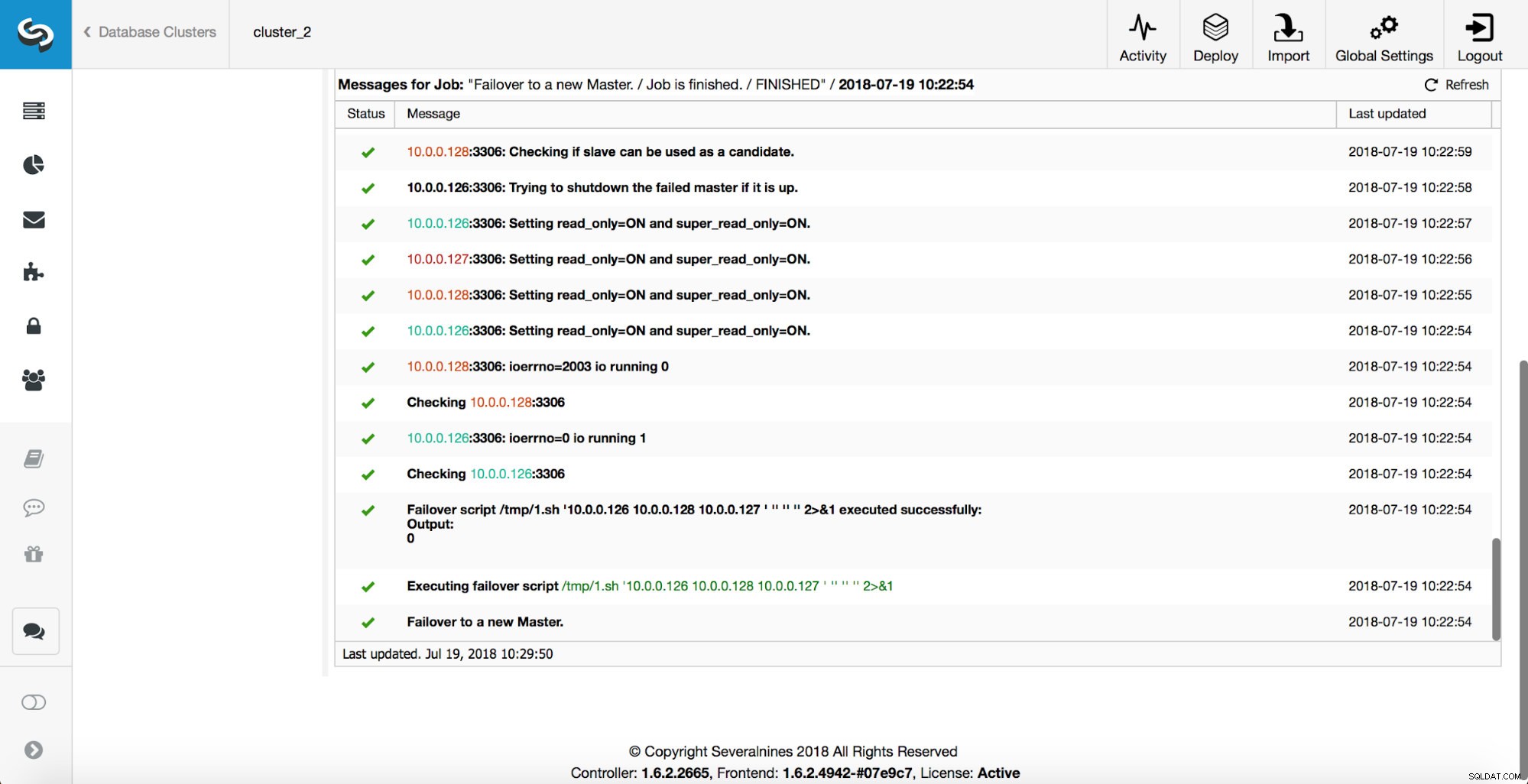
Wie Sie sehen, löst der Failover-Job unmittelbar nach dem Start den Hook „replication_onfail_failover_script“ aus. Dann werden alle erreichbaren Hosts als read_only markiert und ClusterControl versucht zu verhindern, dass der alte Master läuft.
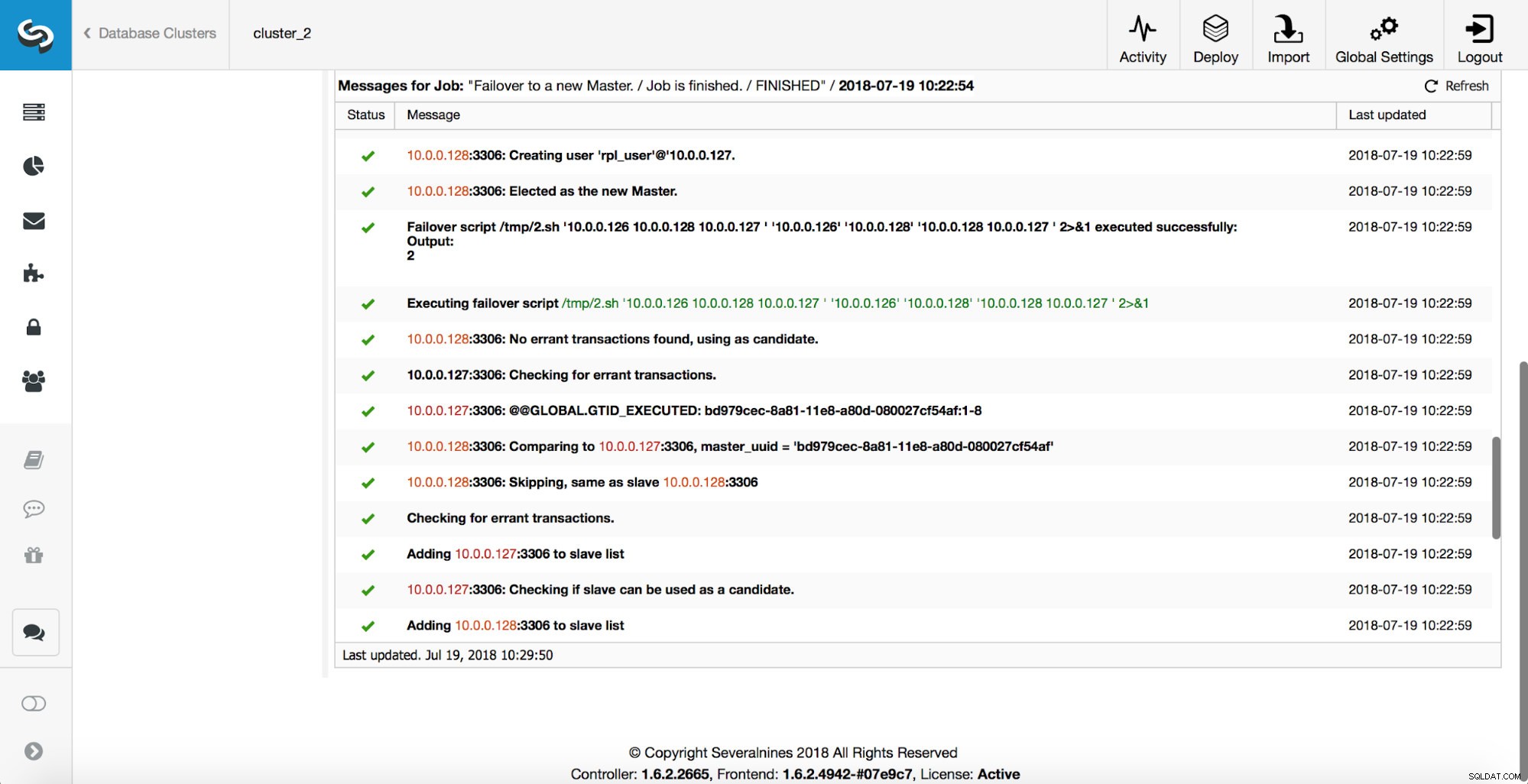
Als nächstes wird der Meisterkandidat ausgewählt, Plausibilitätsprüfungen werden durchgeführt. Sobald bestätigt ist, dass der Masterkandidat als neuer Master verwendet werden kann, wird das „replication_pre_failover_script“ ausgeführt.
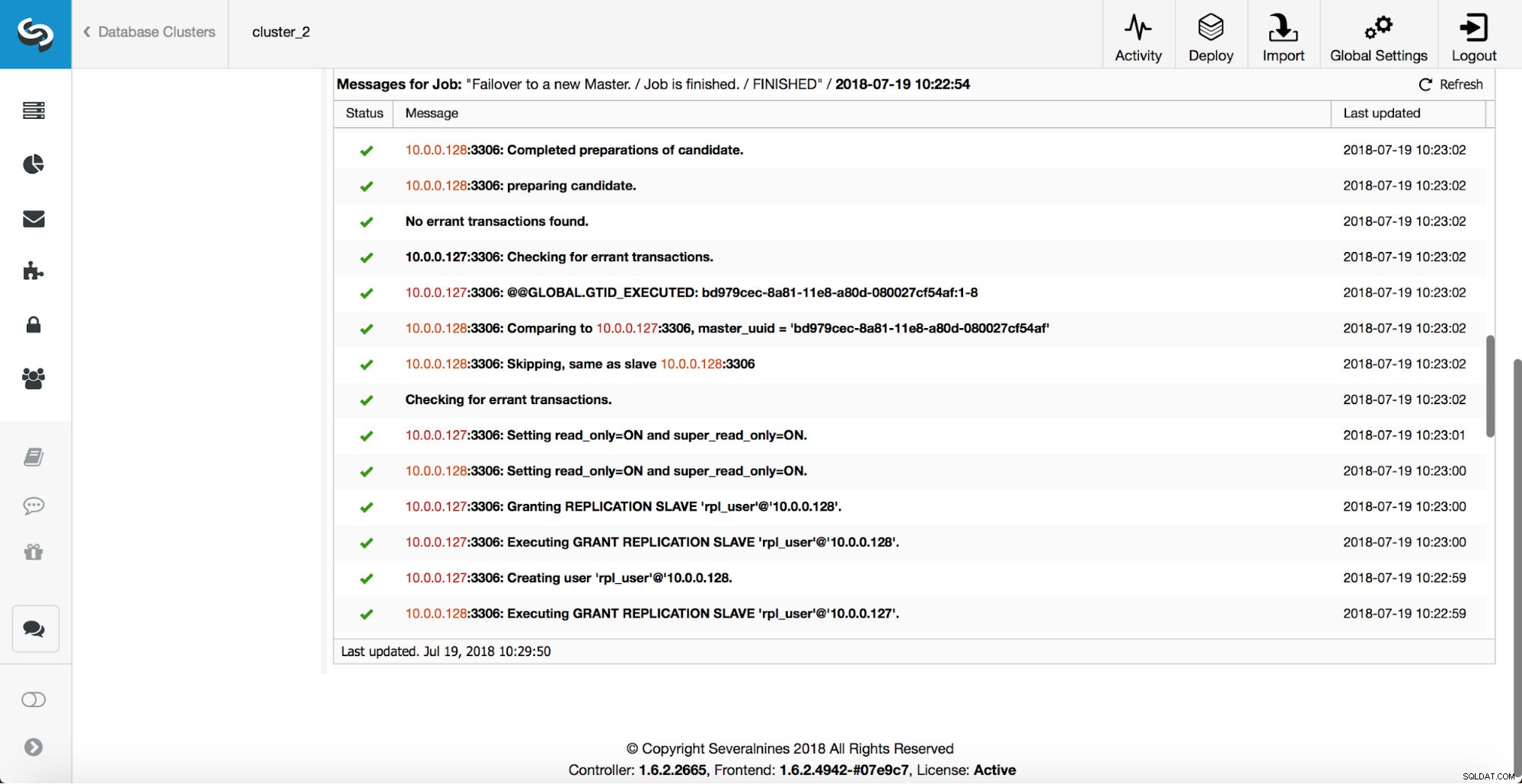
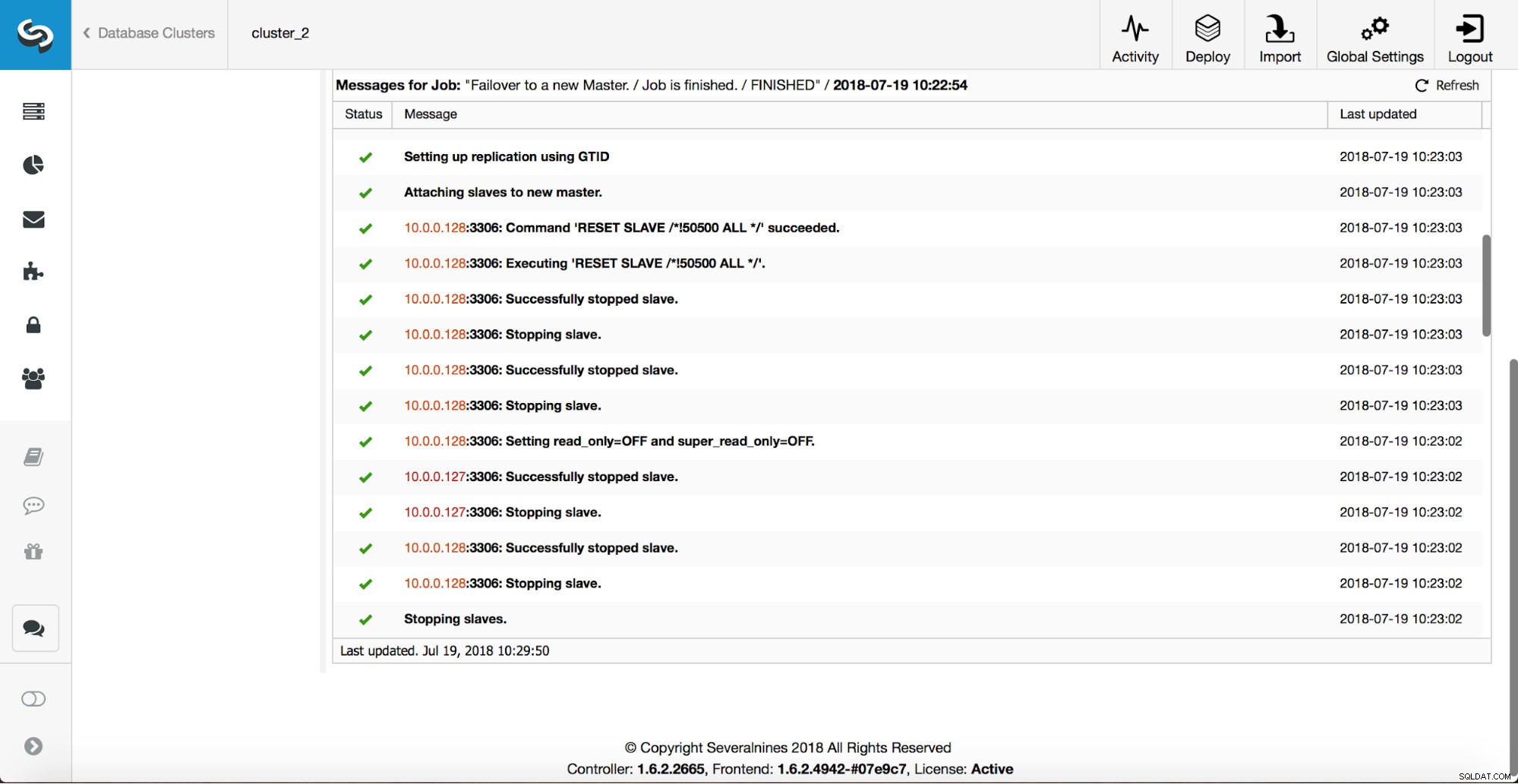
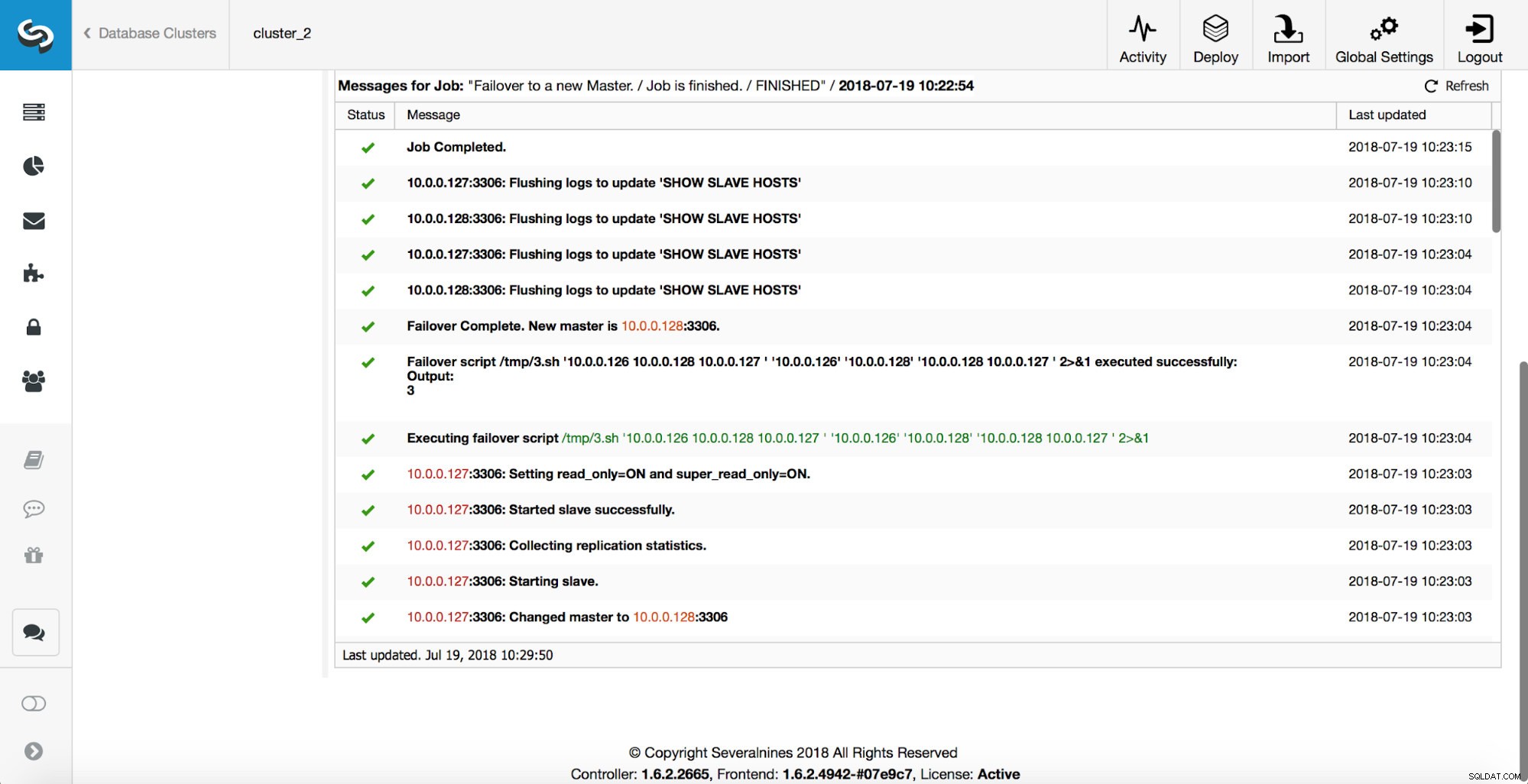
Weitere Überprüfungen werden durchgeführt, Replikate werden angehalten und vom neuen Master abgelenkt. Schließlich, nachdem das Failover abgeschlossen ist, wird ein letzter Hook, „replication_post_failover_script“, ausgelöst.
Wann können Hooks nützlich sein?
In diesem Abschnitt gehen wir einige Beispiele durch, in denen es eine gute Idee sein könnte, externe Skripte zu implementieren. Wir werden nicht auf Details eingehen, da diese zu eng mit einer bestimmten Umgebung verbunden sind. Es handelt sich eher um eine Liste von Vorschlägen, deren Umsetzung nützlich sein könnte.
STONITH-Skript
Shoot The Other Node In The Head (STONITH) ist ein Prozess, um sicherzustellen, dass der alte Meister, der tot ist, tot bleibt (und ja … wir mögen es nicht, wenn Zombies in unserer Infrastruktur herumlaufen). Das Letzte, was Sie wahrscheinlich wollen, ist, einen nicht reagierenden alten Master zu haben, der dann wieder online geht, und als Ergebnis haben Sie am Ende zwei beschreibbare Master. Es gibt Vorkehrungen, die Sie treffen können, um sicherzustellen, dass der alte Master nicht verwendet wird, selbst wenn er wieder auftaucht, und es sicherer ist, dass er offline bleibt. Möglichkeiten, wie sichergestellt werden kann, dass es sich von Umgebung zu Umgebung unterscheidet. Daher wird es höchstwahrscheinlich keine integrierte Unterstützung für STONITH im Failover-Tool geben. Abhängig von der Umgebung möchten Sie möglicherweise einen CLI-Befehl ausführen, der eine VM stoppt (und sogar entfernt), auf der der alte Master ausgeführt wird. Wenn Sie ein On-Prem-Setup haben, haben Sie möglicherweise mehr Kontrolle über die Hardware. Es ist möglicherweise möglich, eine Art Remote-Management (integriertes Lights-out oder einen anderen Remote-Zugriff auf den Server) zu verwenden. Möglicherweise haben Sie auch Zugang zu überschaubaren Steckdosen und schalten den Strom in einer davon aus, um sicherzustellen, dass der Server nie wieder ohne menschliches Eingreifen startet.
Diensterkennung
Wir haben bereits ein wenig über Service Discovery gesprochen. Es gibt zahlreiche Möglichkeiten, Informationen über eine Replikationstopologie zu speichern und zu erkennen, welcher Host ein Master ist. Eine der beliebtesten Optionen ist definitiv die Verwendung von etc.d oder Consul, um Daten über die aktuelle Topologie zu speichern. Damit kann sich eine Anwendung oder ein Proxy auf diese Daten verlassen, um den Datenverkehr an den richtigen Knoten zu senden. ClusterControl hat (wie die meisten Tools, die Failover-Handling unterstützen) keine direkte Integration mit etc.d oder Consul. Die Aufgabe, die Topologiedaten zu aktualisieren, liegt beim Benutzer. Sie kann Hooks wie replication_post_failover_script oder replication_post_switchover_script verwenden, um einige der Skripts aufzurufen und die erforderlichen Änderungen vorzunehmen. Eine andere ziemlich verbreitete Lösung besteht darin, DNS zu verwenden, um den Datenverkehr an die richtigen Instanzen zu leiten. Wenn Sie die Lebensdauer eines DNS-Eintrags niedrig halten, sollten Sie in der Lage sein, eine Domain zu definieren, die auf Ihren Master verweist (z. B. writes.cluster1.example.com). Dies erfordert eine Änderung an den DNS-Einträgen, und wiederum können Hooks wie replication_post_failover_script oder replication_post_switchover_script sehr hilfreich sein, um erforderliche Änderungen vorzunehmen, nachdem ein Failover stattgefunden hat.
Proxy-Neukonfiguration
Jeder verwendete Proxy-Server muss Datenverkehr an die richtigen Instanzen senden. Abhängig vom Proxy selbst kann die Durchführung einer Master-Erkennung entweder (teilweise) fest codiert sein oder dem Benutzer überlassen bleiben, was er will. Der Failover-Mechanismus von ClusterControl ist so konzipiert, dass er sich gut in Proxys integrieren lässt, die er bereitgestellt und konfiguriert hat. Es kann dennoch vorkommen, dass Proxys vorhanden sind, die nicht von ClusterControl installiert wurden und einige manuelle Aktionen erfordern, während ein Failover ausgeführt wird. Solche Proxys können auch über externe Skripte und Hooks wie replication_post_failover_script oder replication_post_switchover_script in den ClusterControl-Failover-Prozess integriert werden.
Zusätzliche Protokollierung
Es kann vorkommen, dass Sie Daten des Failover-Prozesses zu Debugging-Zwecken sammeln möchten. ClusterControl verfügt über umfangreiche Ausdrucke, um sicherzustellen, dass es möglich ist, den Prozess zu verfolgen und herauszufinden, was passiert ist und warum. Es kann dennoch vorkommen, dass Sie einige zusätzliche, benutzerdefinierte Informationen sammeln möchten. Grundsätzlich können hier alle Hooks verwendet werden – Sie können den Anfangszustand vor dem Failover erfassen, Sie können den Zustand der Umgebung in allen Phasen des Failovers verfolgen.