Eine der beliebtesten Methoden, um eine hohe Verfügbarkeit für MySQL zu erreichen, ist die Replikation. Die Replikation gibt es schon seit vielen Jahren und wurde mit der Einführung von GTIDs viel stabiler. Aber selbst mit diesen Verbesserungen kann der Replikationsprozess aus verschiedenen Gründen abbrechen – zum Beispiel, wenn Master und Slave nicht synchron sind, weil Schreibvorgänge direkt an den Slave gesendet wurden. Wie beheben Sie Replikationsprobleme und wie beheben Sie sie?
In diesem Blogbeitrag werden wir einige der häufigsten Probleme mit der Replikation diskutieren und wie sie mit ClusterControl behoben werden können. Beginnen wir mit dem ersten.
Replikation wurde mit einem Fehler beendet
Die meisten MySQL-DBAs werden normalerweise mindestens einmal in ihrer Karriere mit solchen Problemen konfrontiert. Aus verschiedenen Gründen kann ein Slave beschädigt werden oder die Synchronisierung mit dem Master stoppen. In diesem Fall müssen Sie zum Starten der Fehlerbehebung zunächst das Fehlerprotokoll auf Meldungen überprüfen. Meistens ist die Fehlermeldung im Fehlerprotokoll oder durch Ausführen der Abfrage SHOW SLAVE STATUS leicht nachzuvollziehen.
Schauen wir uns das folgende Beispiel aus dem SHOW STATUS SLAVE an:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Wir können deutlich sehen, dass der Fehler mit Fatal Error 1236 vom Master beim Lesen von Daten aus dem Binärlog zusammenhängt:'Der vom Slave angeforderte GTID-Status konnte in keiner Binlog-Datei gefunden werden. Wahrscheinlich ist der Slave-Status zu alt und die erforderlichen Binlog-Dateien wurden gelöscht.'. Mit anderen Worten, der Fehler sagt uns im Wesentlichen, dass die Daten inkonsistent sind und die erforderlichen binären Protokolldateien bereits gelöscht wurden.
Dies ist ein gutes Beispiel dafür, dass der Replikationsprozess nicht mehr funktioniert. Neben SHOW SLAVE STATUS können Sie den Status auch im Reiter „Overview“ des Clusters in ClusterControl verfolgen. Wie kann man das also mit ClusterControl beheben? Sie haben zwei Möglichkeiten, es zu versuchen:
-
Sie können versuchen, den Slave erneut über die „Node Action“ zu starten
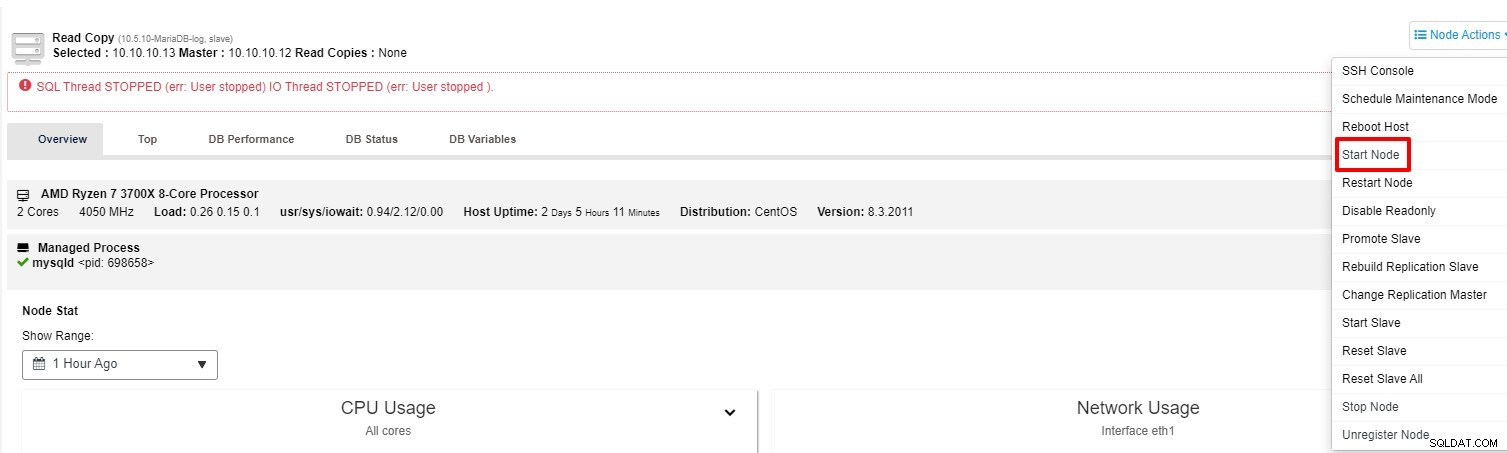
-
Wenn der Slave immer noch nicht funktioniert, können Sie den Job „Rebuild Replication Slave“ ausführen aus der „Node Action“
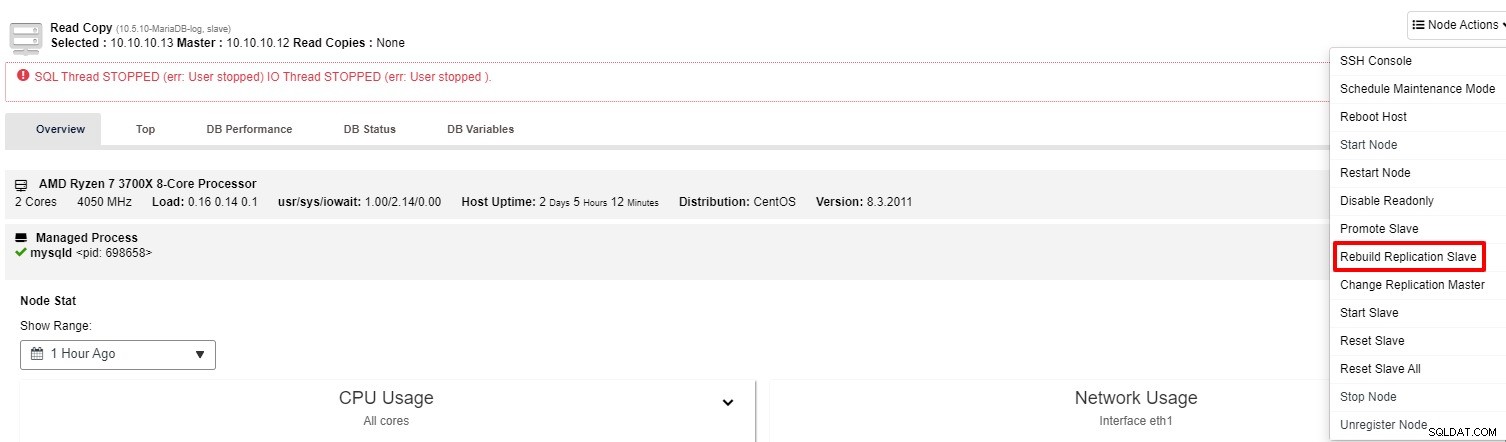
Meistens löst die zweite Option das Problem. ClusterControl erstellt ein Backup des Masters und baut den defekten Slave durch Wiederherstellen der Daten wieder auf. Sobald die Daten wiederhergestellt sind, wird der Slave mit dem Master verbunden, damit er aufholen kann.
Es gibt auch mehrere manuelle Möglichkeiten, Slaves wie unten aufgeführt neu zu erstellen. Weitere Informationen finden Sie auch unter diesem Link:
-
Verwenden von Mysqldump zum Neuerstellen eines inkonsistenten MySQL-Slaves
-
Verwenden von Mydumper zum Neuerstellen eines inkonsistenten MySQL-Slaves
-
Einen Snapshot verwenden, um einen inkonsistenten MySQL-Slave neu aufzubauen
-
Ein Xtrabackup oder Mariabackup verwenden, um einen inkonsistenten MySQL-Slave neu aufzubauen
Befördere einen Sklaven zum Meister
Im Laufe der Zeit muss das Betriebssystem oder die Datenbank gepatcht oder aktualisiert werden, um Stabilität und Sicherheit zu gewährleisten. Eine der bewährten Methoden zur Minimierung der Ausfallzeit, insbesondere bei einem größeren Upgrade, besteht darin, einen der Slaves zum Master zu machen, nachdem das Upgrade auf diesem bestimmten Knoten erfolgreich durchgeführt wurde.
Indem Sie dies ausführen, könnten Sie Ihre Anwendung auf den neuen Master verweisen und die Master-Slave-Replikation wird weiterhin funktionieren. In der Zwischenzeit könnten Sie auch beruhigt mit dem Upgrade auf den alten Master fortfahren. Mit ClusterControl kann dies mit wenigen Klicks durchgeführt werden, vorausgesetzt, die Replikation ist als Global Transaction ID-basiert oder kurz GTID-basiert konfiguriert. Um Datenverluste zu vermeiden, lohnt es sich, alle Anwendungsanfragen zu stoppen, falls der alte Master korrekt funktioniert. Dies ist nicht die einzige Situation, in der Sie den Sklaven fördern könnten. Falls der Master-Knoten ausgefallen ist, können Sie diese Aktion auch ausführen.
Ohne ClusterControl gibt es ein paar Schritte, um den Slave zu befördern. Für jeden der Schritte müssen auch einige Abfragen ausgeführt werden:
-
Master manuell herunterfahren
-
Wähle den fortgeschrittensten Sklaven als Meister aus und bereite ihn vor
-
Andere Slaves wieder mit dem neuen Master verbinden
-
Den alten Meister in einen Sklaven verwandeln
Nichtsdestotrotz sind die Schritte zum Promoten von Slaves mit ClusterControl nur wenige Klicks:Cluster> Knoten> Slave-Knoten auswählen> Slave promoten, wie im Screenshot unten gezeigt:
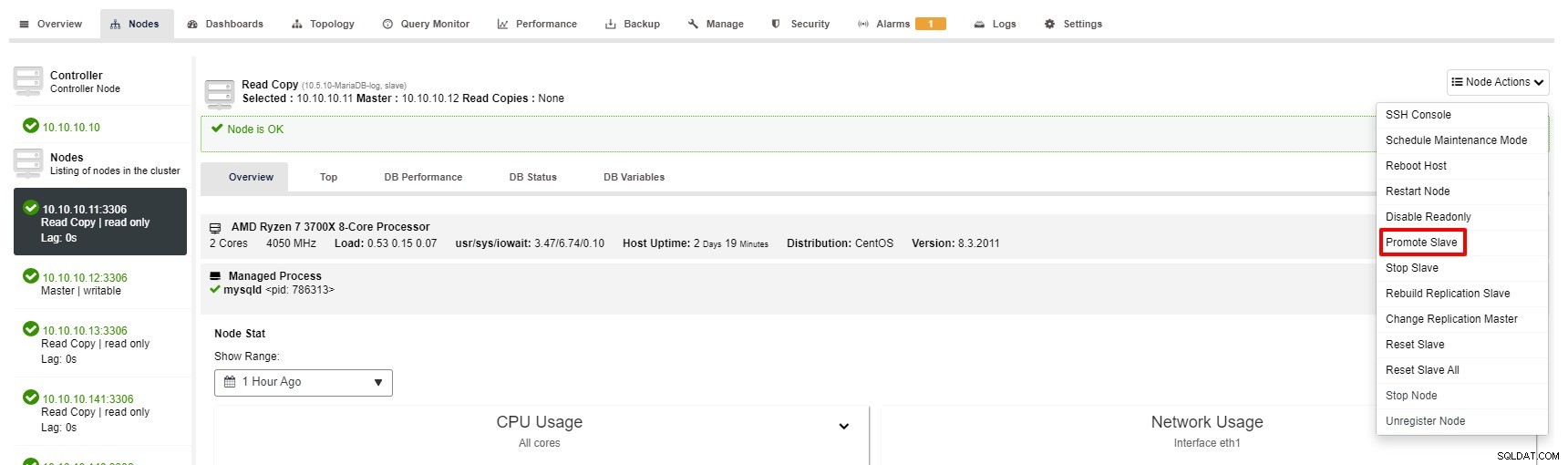
Master wird nicht mehr verfügbar
Stellen Sie sich vor, Sie müssen große Transaktionen ausführen, aber die Datenbank ist ausgefallen. Es spielt keine Rolle, wie vorsichtig Sie sind, dies ist wahrscheinlich die schwerwiegendste oder kritischste Situation für eine Replikationskonfiguration. Wenn dies passiert, kann Ihre Datenbank keinen einzigen Schreibvorgang akzeptieren, was schlecht ist. Außerdem funktionieren Ihre Anwendung(en) natürlich nicht richtig.
Es gibt einige Gründe oder Ursachen, die zu diesem Problem führen. Einige der Beispiele sind Hardwarefehler, Betriebssystembeschädigung, Datenbankbeschädigung und so weiter. Als DBA müssen Sie schnell handeln, um die Master-Datenbank wiederherzustellen.
Dank der in ClusterControl verfügbaren Cluster-Funktion „Auto Recovery“ kann der Failover-Prozess automatisiert werden. Es kann mit einem einzigen Klick aktiviert oder deaktiviert werden. Wie der Name schon sagt, wird bei Bedarf die gesamte Cluster-Topologie aufgerufen. Beispielsweise muss bei einer Master-Slave-Replikation immer mindestens ein Master aktiv sein, unabhängig von der Anzahl der verfügbaren Slaves. Wenn der Master nicht verfügbar ist, befördert er automatisch einen der Slaves.
Schauen wir uns den folgenden Screenshot an:
Im obigen Screenshot können wir sehen, dass „Automatische Wiederherstellung“ sowohl für Cluster als auch für Node aktiviert ist. Beachten Sie in der Topologie, dass die aktuelle Master-IP-Adresse 10.10.10.11 lautet. Was passiert, wenn wir den Master-Knoten zu Testzwecken herunterfahren?
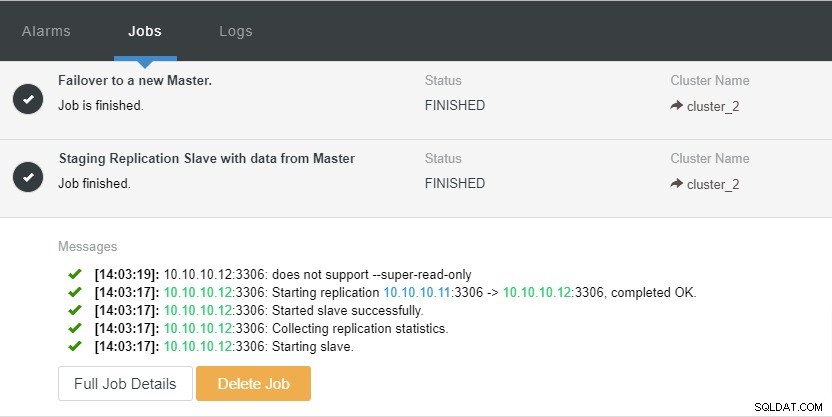
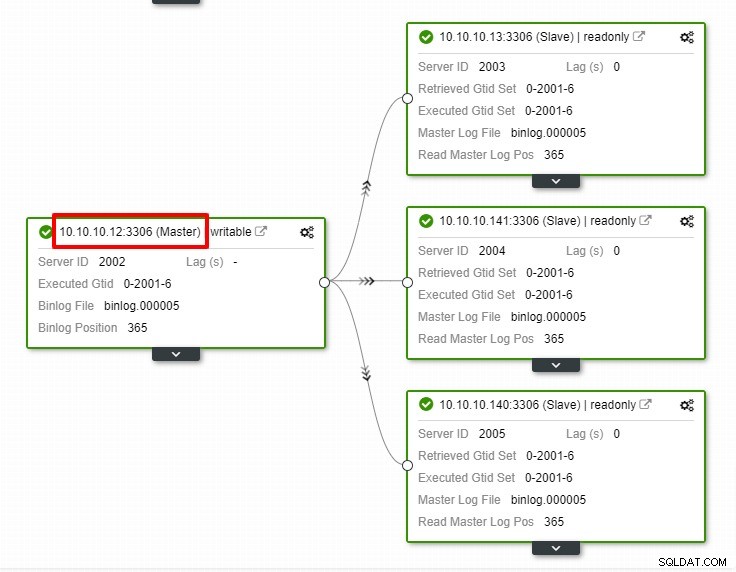
Wie Sie sehen können, ist der Slave-Knoten mit der IP 10.10.10.12 automatisch zum Master heraufgestuft, sodass die Replikationstopologie neu konfiguriert wird. Anstatt dies manuell zu tun, was natürlich viele Schritte erfordert, hilft Ihnen ClusterControl dabei, Ihr Replikations-Setup zu pflegen, indem es Ihnen den Ärger abnimmt.
Fazit
In jedem unglücklichen Fall mit Ihrer Replikation ist die Lösung mit ClusterControl sehr einfach und weniger mühsam. ClusterControl hilft Ihnen, Ihre Replikationsprobleme schnell zu beheben, was die Betriebszeit Ihrer Datenbanken erhöht.