Die Bedeutung von Failover
Failover ist eine der wichtigsten Datenbankpraktiken für die Datenbankverwaltung. Es ist nicht nur nützlich, wenn Sie große Datenbanken in der Produktion verwalten, sondern auch, wenn Sie sicher sein möchten, dass Ihr System immer verfügbar ist, wann immer Sie darauf zugreifen – insbesondere auf Anwendungsebene.
Bevor ein Failover stattfinden kann, müssen Ihre Datenbankinstanzen bestimmte Voraussetzungen erfüllen. Diese Anforderungen sind in der Tat sehr wichtig für eine hohe Verfügbarkeit. Eine der Anforderungen, die Ihre Datenbankinstanzen erfüllen müssen, ist Redundanz. Redundanz ermöglicht die Fortsetzung des Failover, wobei die Redundanz so eingerichtet ist, dass sie einen Failover-Kandidaten hat, der ein (sekundärer) Replikatknoten oder aus einem Pool von Replikaten sein kann, die als Standby- oder Hot-Standby-Knoten fungieren. Der Kandidat wird entweder manuell oder automatisch basierend auf dem fortschrittlichsten oder aktuellsten Knoten ausgewählt. Normalerweise möchten Sie ein Hot-Standby-Replikat, da es Ihre Datenbank davor bewahren kann, Indizes von der Festplatte zu ziehen, da ein Hot-Standby häufig Indizes in den Pufferpool der Datenbank füllt.
Failover ist der Begriff, der verwendet wird, um zu beschreiben, dass ein Wiederherstellungsprozess stattgefunden hat. Vor dem Wiederherstellungsprozess tritt dies auf, wenn ein primärer (oder Master-) Datenbankknoten nach einem Absturz, nach Naturkatastrophen, nach einem Hardwarefehler ausfällt oder möglicherweise eine Netzwerkpartitionierung erlitten hat; Dies sind die häufigsten Fälle, in denen ein Failover stattfinden kann. Der Wiederherstellungsprozess wird normalerweise automatisch fortgesetzt und sucht dann nach der gewünschten und aktuellsten sekundären (Replik) wie zuvor angegeben.
Erweitertes Failover
Obwohl der Wiederherstellungsprozess während eines Failovers automatisch abläuft, gibt es bestimmte Fälle, in denen es nicht notwendig ist, den Prozess zu automatisieren und ein manueller Prozess übernehmen muss. Komplexität ist oft die Hauptüberlegung im Zusammenhang mit den Technologien, die den gesamten Stack Ihrer Datenbank umfassen - automatisches Failover kann auch mit manuellem Failover gemischt werden.
Bei den meisten alltäglichen Überlegungen zur Verwaltung von Datenbanken sind die meisten Bedenken im Zusammenhang mit dem automatischen Failover wirklich nicht trivial. Es ist oft praktisch, ein automatisches Failover zu implementieren und einzurichten, falls Probleme auftreten. Obwohl das vielversprechend klingt, da es die Komplexität abdeckt, kommen die erweiterten Failover-Mechanismen hinzu, und dazu gehören „Pre“-Ereignisse und „Post“-Ereignisse, die als Hooks in eine Failover-Software oder -Technologie eingebunden sind.
Diese Pre- und Post-Ereignisse beinhalten entweder Überprüfungen oder bestimmte Aktionen, die durchgeführt werden müssen, bevor das Failover endgültig fortgesetzt werden kann, und nachdem ein Failover durchgeführt wurde, einige Aufräumarbeiten, um sicherzustellen, dass das Failover schließlich erfolgreich ist ein. Glücklicherweise gibt es Tools, die nicht nur ein automatisches Failover ermöglichen, sondern auch Funktionen zum Anwenden von Pre- und Post-Script-Hooks bieten.
In diesem Blog verwenden wir das automatische ClusterControl (CC)-Failover und erklären, wie die Pre- und Post-Skript-Hooks verwendet werden und auf welchen Cluster sie sich beziehen.
ClusterControl-Replikations-Failover
Der ClusterControl-Failover-Mechanismus ist effizient über die asynchrone Replikation anwendbar, die auf MySQL-Varianten anwendbar ist (MySQL/Percona Server/MariaDB). Es ist auch auf PostgreSQL/TimescaleDB-Cluster anwendbar – ClusterControl unterstützt die Streaming-Replikation. MongoDB- und Galera-Cluster haben einen eigenen Mechanismus für automatisches Failover, der in ihre eigene Datenbanktechnologie integriert ist. Lesen Sie mehr darüber, wie ClusterControl automatische Datenbankwiederherstellung und Failover durchführt.
ClusterControl-Failover funktioniert nur, wenn die Knoten- und Clusterwiederherstellung (automatische Wiederherstellung) aktiviert ist. Das bedeutet, dass diese Schaltflächen grün sein sollten.

Die Dokumentation gibt an, dass diese Konfigurationsoptionen auch verwendet werden können, um / Folgendes deaktivieren:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Für diesen Blog konzentrieren wir uns hauptsächlich darauf, wie man die Prä-/Post-Skript-Hooks verwendet, was im Wesentlichen ein großer Vorteil für fortgeschrittenes Replikations-Failover ist.
Cluster-Failover-Replikation Pre/Post-Skriptunterstützung
Wie bereits erwähnt, unterstützen MySQL-Varianten, die asynchrone (einschließlich halbsynchrone) Replikation und Streaming-Replikation für PostgreSQL/TimescaleDB verwenden, diesen Mechanismus. ClusterControl hat die folgenden Konfigurationsoptionen, die für Pre- und Post-Script-Hooks verwendet werden können. Grundsätzlich können diese Konfigurationsoptionen über ihre Konfigurationsdateien oder über die Web-Benutzeroberfläche festgelegt werden (dazu kommen wir später).
Unsere Dokumentation gibt an, dass dies die folgenden Konfigurationsoptionen sind, die den Failover-Mechanismus ändern können, indem sie die Prä-/Post-Skript-Hooks verwenden:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Technisch gesehen, sobald Sie die folgenden Konfigurationsoptionen in Ihrer Konfigurationsdatei /etc/cmon.d/cmon_
$ systemctl restart cmonAlternativ können Sie die Konfigurationsoptionen auch festlegen, indem Sie zu
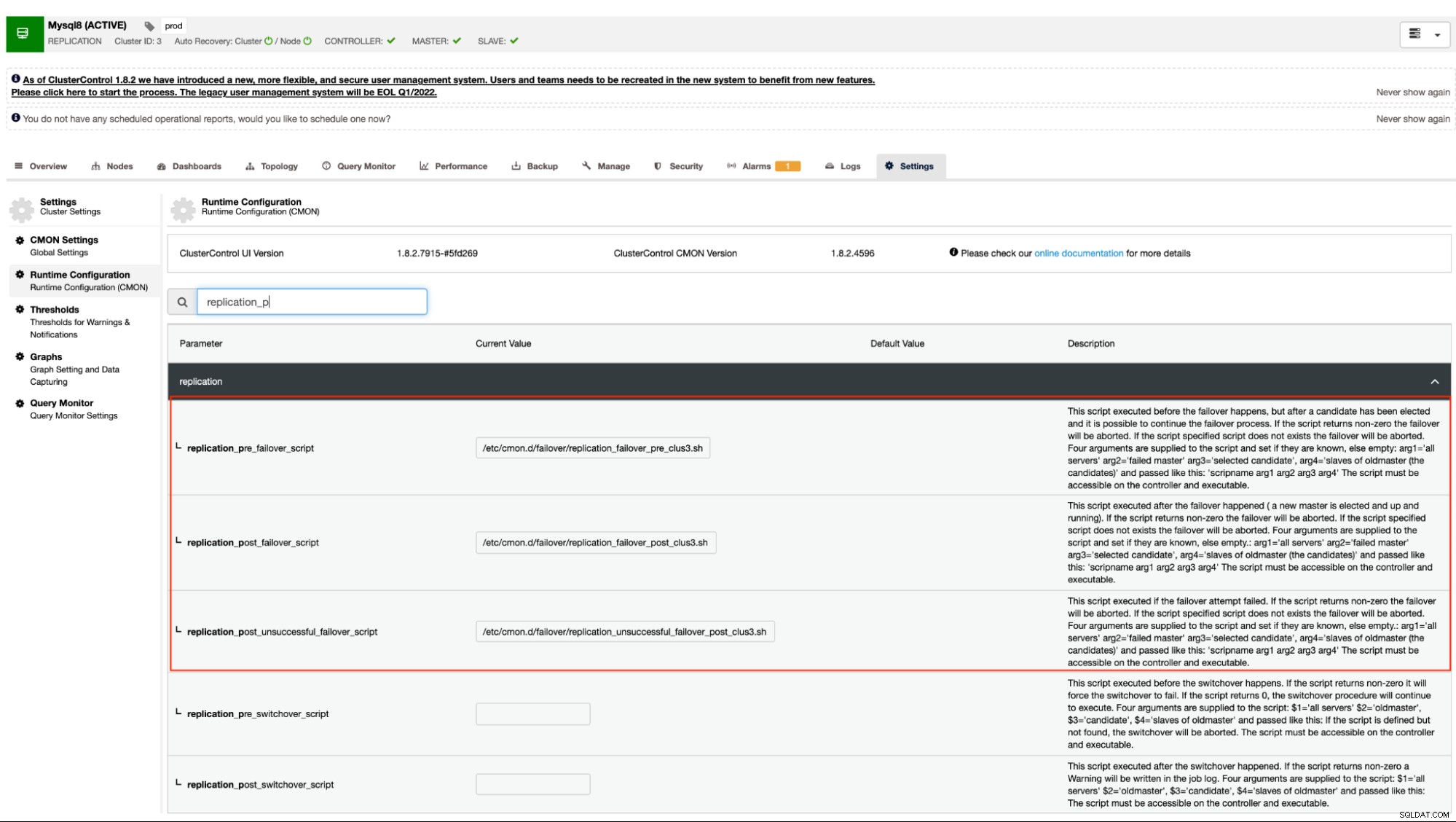
Dieser Ansatz würde immer noch einen Neustart des cmon-Dienstes erfordern, bevor er die Änderungen an diesen Konfigurationsoptionen für Prä-/Post-Skript-Hooks.
Beispiel für Prä-/Post-Skript-Hooks
Idealerweise sind die Pre/Post-Skript-Hooks dediziert, wenn Sie ein erweitertes Failover benötigen, für das ClusterControl die Komplexität Ihres Datenbank-Setups nicht bewältigen könnte. Wenn Sie beispielsweise verschiedene Rechenzentren mit verschärfter Sicherheit betreiben und feststellen möchten, ob die Warnung, dass das Netzwerk nicht erreichbar ist, kein falscher positiver Alarm ist. Es muss prüfen, ob der Primary und der Slave einander erreichen können und umgekehrt, und es kann auch von den Datenbankknoten aus erreichen, die zum ClusterControl-Host gehen.
Lassen Sie uns das in unserem Beispiel tun und zeigen, wie Sie davon profitieren können.
Serverdetails und die Skripte
In diesem Beispiel verwende ich einen MariaDB-Replikationscluster mit nur einem primären und einem Replikat. Wird von ClusterControl verwaltet, um das Failover zu verwalten.
ClusterControl =192.168.40.110
primär (debnode5) =192.168.30.50
replica (debnode9) =192.168.30.90
Erstellen Sie im primären Knoten das Skript wie unten beschrieben
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Stellen Sie sicher, dass /opt/pre_failover.sh ausführbar ist, d.h.
$ chmod +x /opt/pre_failover.shDann verwenden Sie dieses Skript, um per Cron beteiligt zu sein. In diesem Beispiel habe ich eine Datei /etc/cron.d/ccfailover mit folgendem Inhalt erstellt:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shIn Ihrem Replikat verwenden Sie einfach die folgenden Schritte, die wir für das primäre ausgeführt haben, außer dass Sie den Hostnamen ändern. Siehe das Folgende von dem, was ich unten in meiner Replik habe:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"und stellen Sie sicher, dass das in unserem Cron aufgerufene Skript ausführbar ist,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl Pre-/Post-Skripte
In dieser Demonstration ist meine cluster_id 3. Wie bereits in unserer Dokumentation erwähnt, müssen sich diese Skripte auf unserem CC-Controller-Host befinden. In meiner /etc/cmon.d/cmon_3.cnf habe ich also Folgendes:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shDagegen bestimmt das folgende "Pre"-Failover-Skript, ob beide Knoten den CC-Controller-Host erreichen konnten. Siehe Folgendes:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Failover vorführen
Lassen Sie uns nun versuchen, einen Netzwerkausfall auf dem primären Knoten zu simulieren und zu sehen, wie er reagiert. In meinem primären Knoten deaktiviere ich die Netzwerkschnittstelle, die für die Kommunikation mit dem Replikat und dem CC-Controller verwendet wird.
example@sqldat.com:~# ip link set enp0s8 downBeim ersten Failover-Versuch konnte CC mein Pre-Skript ausführen, das sich unter /etc/cmon.d/failover/replication_failover_pre_clus3.sh befindet. Sehen Sie unten, wie es funktioniert:
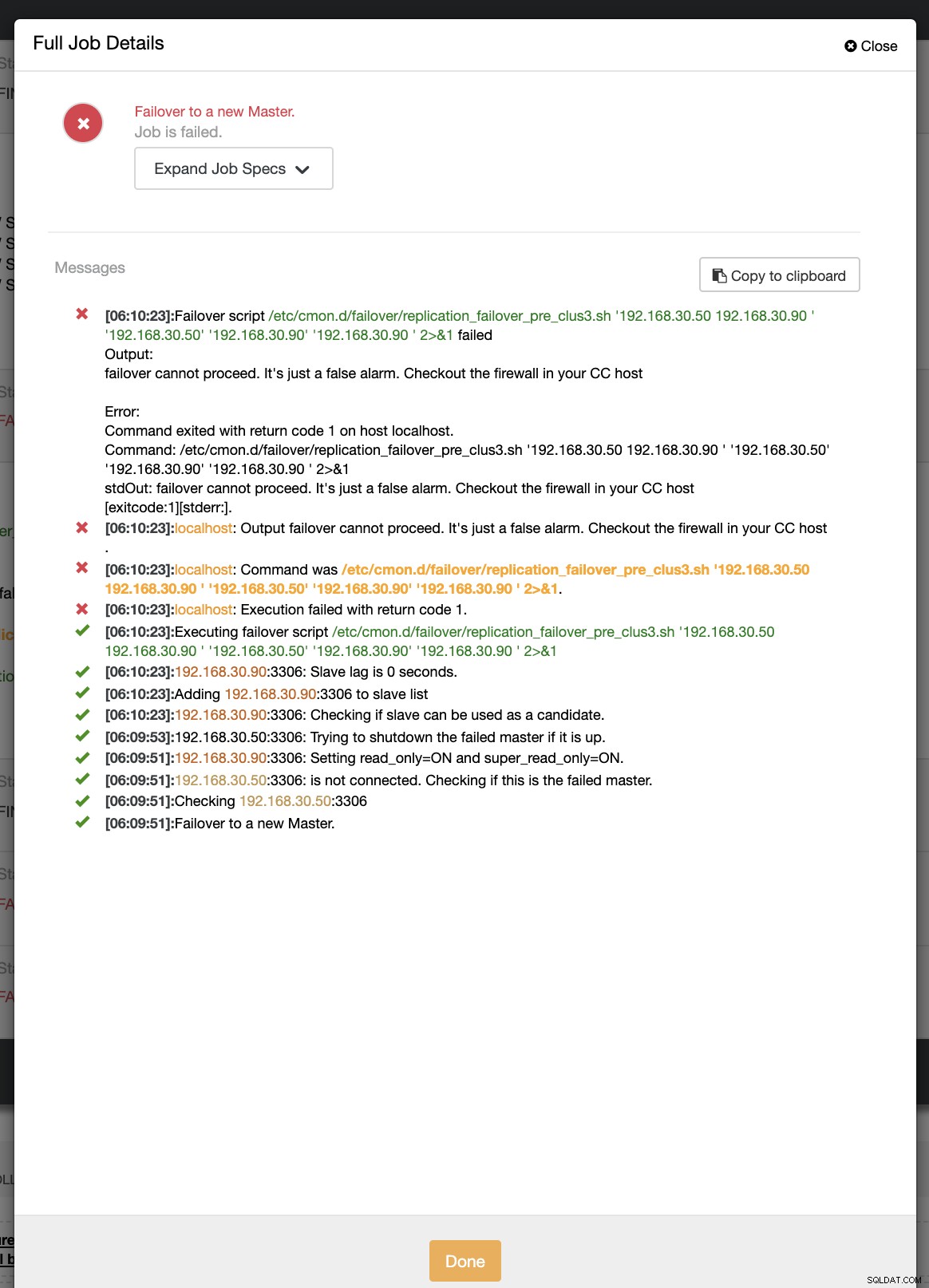
Offensichtlich schlägt es fehl, weil der protokollierte Zeitstempel noch nicht länger als eine Minute ist oder es nur wenige Sekunden her ist, dass sich der primäre Controller noch mit dem CC-Controller verbinden konnte. Offensichtlich ist dies nicht der perfekte Ansatz, wenn Sie es mit einem realen Szenario zu tun haben. ClusterControl konnte das Skript jedoch wie erwartet aufrufen und ausführen. Wie wäre es nun, wenn es tatsächlich mehr als eine Minute (d. h.> 60 Sekunden) erreicht?
Bei unserem zweiten Failover-Versuch, da der Zeitstempel mehr als 60 Sekunden erreicht, wird er als echt positiv erachtet, und das bedeutet, dass wir wie beabsichtigt ein Failover durchführen müssen. CC konnte es perfekt ausführen und sogar das Postscript wie beabsichtigt ausführen. Dies ist im Auftragsprotokoll ersichtlich. Siehe Screenshot unten:
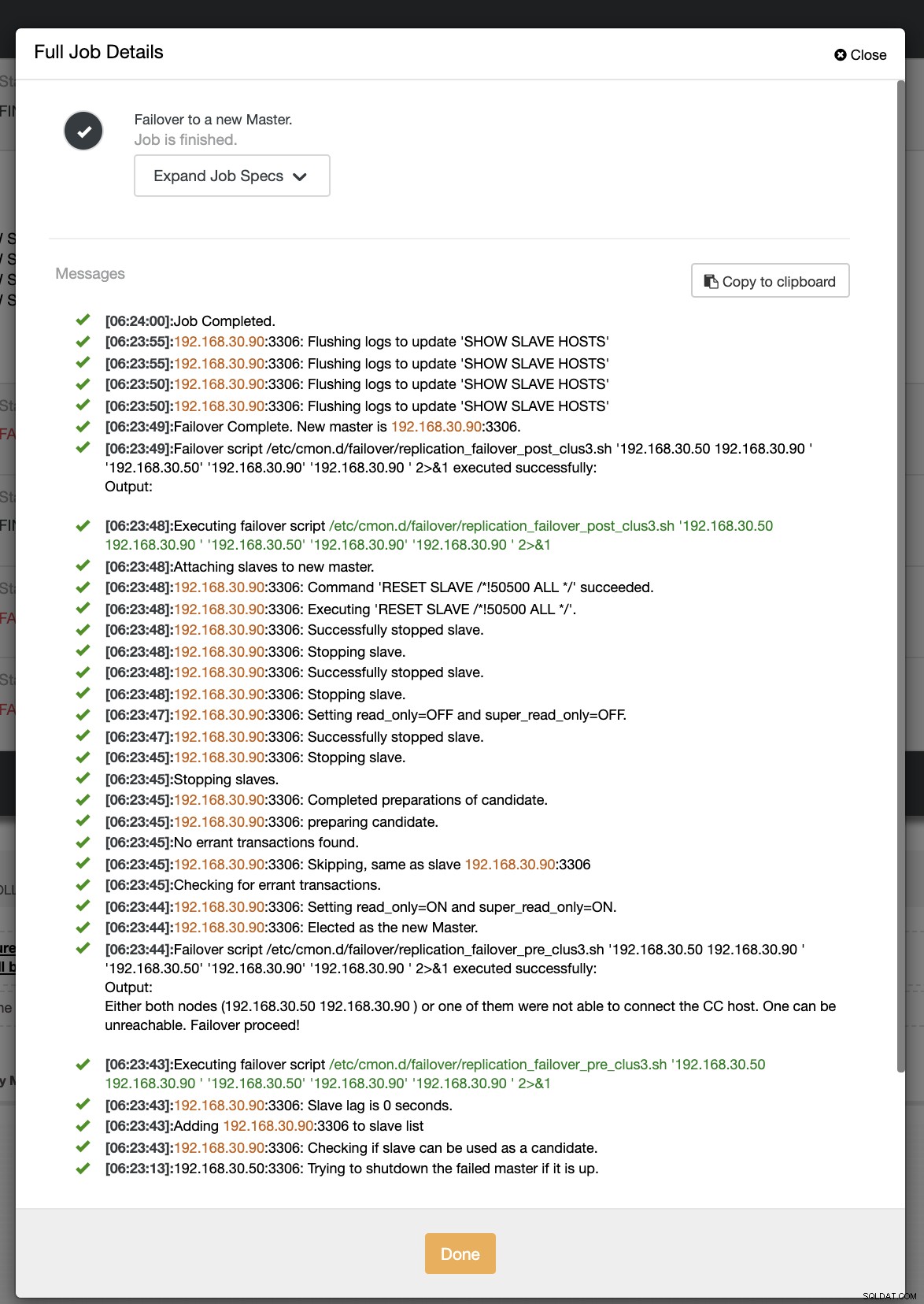
Beim Überprüfen, ob mein Post-Skript ausgeführt wurde, konnte es das Protokoll erstellen Datei wie erwartet im CC /tmp-Verzeichnis,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtFailover-Skript auf Cluster 3 mit Argumenten posten:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
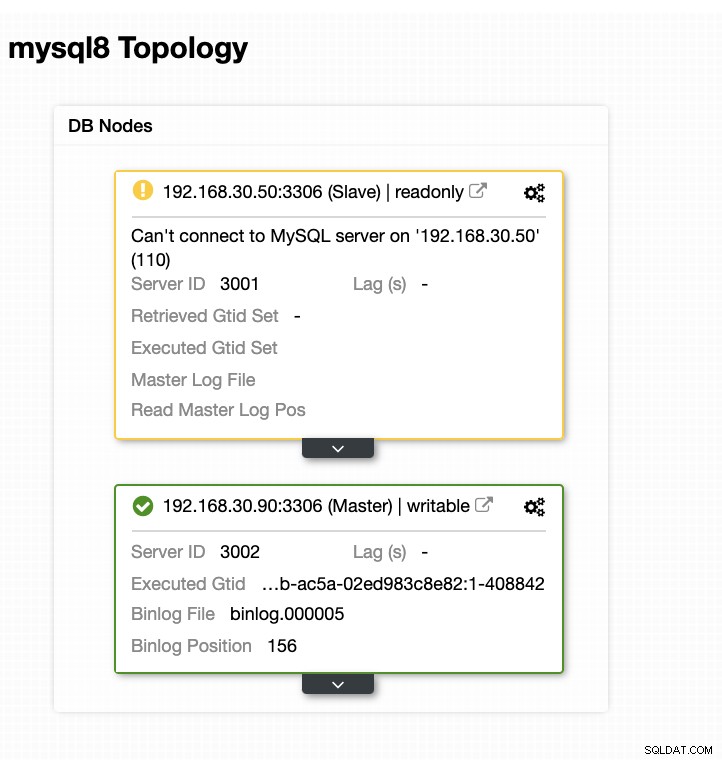
Jetzt wurde meine Topologie geändert und das Failover war erfolgreich!
Fazit
Für jede komplizierte Datenbankeinrichtung, die Sie möglicherweise haben, wenn ein erweitertes Failover erforderlich ist, können Pre-/Post-Skripte sehr hilfreich sein, um die Dinge erreichbar zu machen. Da ClusterControl diese Funktionen unterstützt, haben wir gezeigt, wie leistungsfähig und hilfreich es ist. Trotz seiner Einschränkungen gibt es immer Möglichkeiten, Dinge erreichbar und nützlich zu machen, insbesondere in Produktionsumgebungen.



