Das Ausführen von Datenbanken auf einer Cloud-Infrastruktur wird heutzutage immer beliebter. Obwohl eine Cloud-VM möglicherweise nicht so zuverlässig ist wie ein Server der Enterprise-Klasse, bieten die wichtigsten Cloud-Anbieter eine Vielzahl von Tools an, um die Serviceverfügbarkeit zu erhöhen. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie Ihre MySQL- oder MariaDB-Datenbank für Hochverfügbarkeit in der Cloud konfigurieren. Wir werden uns speziell mit Amazon Web Services und Google Cloud Platform befassen, aber die meisten Tipps können auch mit anderen Cloud-Anbietern verwendet werden.
Sowohl AWS als auch Google bieten Datenbankdienste in ihren Clouds an, und diese Dienste können für Hochverfügbarkeit konfiguriert werden. Es ist möglich, Kopien in verschiedenen Verfügbarkeitszonen (oder Zonen in der GCP) zu haben, um Ihre Chancen zu erhöhen, einen teilweisen Ausfall von Diensten innerhalb einer Region zu überstehen. Obwohl ein gehosteter Dienst eine sehr bequeme Möglichkeit zum Ausführen einer Datenbank darstellt, beachten Sie, dass der Dienst so konzipiert ist, dass er sich auf eine bestimmte Weise verhält und dass dies möglicherweise Ihren Anforderungen entspricht oder nicht. So hat beispielsweise AWS RDS für MySQL eine ziemlich begrenzte Liste von Optionen, wenn es um die Failover-Handhabung geht. Multi-AZ-Bereitstellungen haben eine Failover-Zeit von 60–120 Sekunden gemäß der Dokumentation. Angesichts der Tatsache, dass die „Schatten“-MySQL-Instanz von einem „beschädigten“ Datensatz aus starten muss, kann dies sogar noch länger dauern, da möglicherweise mehr Arbeit beim Anwenden oder Zurücksetzen von Transaktionen aus InnoDB-Redo-Protokollen erforderlich ist. Es besteht die Möglichkeit, einen Sklaven zu einem Meister zu machen, aber es ist nicht möglich, da Sie bestehende Sklaven nicht vom neuen Meister ablösen können. Im Falle eines verwalteten Dienstes ist es auch an sich komplexer und schwieriger, Leistungsprobleme zu verfolgen. Weitere Einblicke in RDS für MySQL und seine Einschränkungen in diesem Blogbeitrag.
Wenn Sie sich dagegen entscheiden, die Datenbanken zu verwalten, befinden Sie sich in einer anderen Welt der Möglichkeiten. Eine Reihe von Dingen, die Sie auf Bare Metal tun können, sind auch auf EC2- oder Compute Engine-Instanzen möglich. Sie haben keinen Overhead für die Verwaltung der zugrunde liegenden Hardware und behalten dennoch die Kontrolle über die Architektur des Systems. Beim Entwerfen für MySQL-Verfügbarkeit gibt es zwei Hauptoptionen – MySQL-Replikation und Galera-Cluster. Lassen Sie uns darüber sprechen.
MySQL-Replikation
Die MySQL-Replikation ist eine gängige Methode zur Skalierung von MySQL mit mehreren Kopien der Daten. Asynchron oder halbsynchron ermöglicht es, Änderungen, die auf einem einzelnen Writer, dem Master, ausgeführt werden, an Replikate/Slaves weiterzugeben, von denen jeder den vollständigen Datensatz enthalten würde und zum neuen Master befördert werden kann. Die Replikation kann auch zum Skalieren von Lesevorgängen verwendet werden, indem der Leseverkehr an Replikate geleitet und der Master auf diese Weise entlastet wird. Der Hauptvorteil der Replikation ist die Benutzerfreundlichkeit – sie ist so weithin bekannt und beliebt (sie ist auch einfach zu konfigurieren), dass es zahlreiche Ressourcen und Tools gibt, die Ihnen bei der Verwaltung und Konfiguration helfen. Unser eigenes ClusterControl ist eines davon – Sie können damit ganz einfach ein MySQL-Replikations-Setup mit integrierten Load-Balancern bereitstellen, Topologieänderungen, Failover/Wiederherstellung usw. verwalten.
Ein Hauptproblem bei der MySQL-Replikation ist, dass sie nicht darauf ausgelegt ist, Netzwerkaufteilungen oder Master-Ausfälle zu bewältigen. Wenn ein Master ausfällt, müssen Sie eines der Replikate hochstufen. Dies ist ein manueller Prozess, der jedoch mit externen Tools (z. B. ClusterControl) automatisiert werden kann. Es gibt auch keinen Quorum-Mechanismus und es gibt keine Unterstützung für das Fencing fehlgeschlagener Master-Instanzen in der MySQL-Replikation. Leider kann dies zu ernsthaften Problemen in verteilten Umgebungen führen – wenn Sie einen neuen Master heraufstufen, während Ihr alter wieder online geht, schreiben Sie möglicherweise auf zwei Knoten, was zu Datendrift und schwerwiegenden Datenkonsistenzproblemen führt.
Wir werden uns später in diesem Beitrag einige Beispiele ansehen, die Ihnen zeigen, wie Sie Netzwerkaufteilungen erkennen und STONITH oder einen anderen Fencing-Mechanismus für Ihr MySQL-Replikations-Setup implementieren.
Galera-Cluster
Wir haben im vorherigen Abschnitt gesehen, dass es der MySQL-Replikation an Fencing und Quorum-Unterstützung fehlt – hier glänzt Galera Cluster. Es verfügt über eine integrierte Quorum-Unterstützung und einen Fencing-Mechanismus, der verhindert, dass partitionierte Knoten Schreibvorgänge akzeptieren. Dadurch eignet sich Galera Cluster besser als die Replikation in Multi-Rechenzentrum-Setups. Galera Cluster unterstützt auch mehrere Schreiber und kann Schreibkonflikte lösen. Sie sind daher nicht auf einen einzigen Writer in einem Setup mit mehreren Rechenzentren beschränkt, es ist möglich, einen Writer in jedem Rechenzentrum zu haben, was die Latenz zwischen Ihrer Anwendung und der Datenbankschicht verringert. Schreibvorgänge werden dadurch nicht beschleunigt, da jeder Schreibvorgang weiterhin zur Zertifizierung an jeden Galera-Knoten gesendet werden muss, aber es ist immer noch einfacher, als Schreibvorgänge von allen Anwendungsservern über das WAN an einen einzigen Remote-Master zu senden.
So gut Galera auch ist, es ist nicht immer die beste Wahl für alle Workloads. Galera ist kein Drop-in-Ersatz für MySQL/InnoDB. Es hat gemeinsame Merkmale mit „normalem“ MySQL – es verwendet InnoDB als Speicher-Engine, es enthält den gesamten Datensatz auf jedem Knoten, was JOINs möglich macht. Dennoch unterscheiden sich einige der Leistungsmerkmale von Galera (wie die Leistung von Schreibvorgängen, die durch Netzwerklatenz beeinträchtigt werden) von dem, was Sie von Replikations-Setups erwarten würden. Auch die Wartung sieht anders aus:Die Behandlung von Schemaänderungen funktioniert etwas anders. Einige Schemadesigns sind nicht optimal:Wenn Sie Hotspots in Ihren Tabellen haben, wie z. B. häufig aktualisierte Zähler, kann dies zu Leistungsproblemen führen. Es gibt auch einen Unterschied in den Best Practices in Bezug auf die Stapelverarbeitung – anstatt Abfragen in großen Transaktionen auszuführen, möchten Sie, dass Ihre Transaktionen klein sind.
Proxy-Stufe
Es ist sehr schwierig und umständlich, ein hochverfügbares Setup ohne Proxys aufzubauen. Sicher, Sie können Code in Ihre Anwendung schreiben, um Datenbankinstanzen nachzuverfolgen, fehlerhafte auf die Blacklist zu setzen, beschreibbare Master zu verfolgen und so weiter. Dies ist jedoch viel komplexer, als nur Datenverkehr an einen einzelnen Endpunkt zu senden – und hier kommt ein Proxy ins Spiel. Mit ClusterControl können Sie ProxySQL, HAProxy und MaxScale bereitstellen. Wir werden einige Beispiele mit ProxySQL geben, da es uns eine gute Flexibilität bei der Kontrolle des Datenbankverkehrs gibt.
ProxySQL kann auf verschiedene Arten bereitgestellt werden. Für den Anfang kann es auf separaten Hosts bereitgestellt werden und Keepalived kann verwendet werden, um virtuelle IP bereitzustellen. Die virtuelle IP wird verschoben, falls eine der ProxySQL-Instanzen ausfällt. In der Cloud kann dieses Setup problematisch sein, da das Hinzufügen einer IP zur Schnittstelle normalerweise nicht ausreicht. Sie müssten die Keepalived-Konfiguration und -Skripts ändern, um mit elastischer IP (oder statischer IP – wie auch immer sie von Ihrem Cloud-Anbieter aufgerufen werden mag) zu arbeiten. Dann würde man Cloud-API oder CLI verwenden, um diese IP-Adresse auf einen anderen Host zu verschieben. Aus diesem Grund empfehlen wir, ProxySQL mit der Anwendung zu verbinden. Jeder Anwendungsserver würde so konfiguriert, dass er über Unix-Sockets eine Verbindung zum lokalen ProxySQL herstellt. Da ProxySQL einen Angel-Prozess verwendet, können ProxySQL-Abstürze innerhalb einer Sekunde erkannt/neu gestartet werden. Im Falle eines Hardwareabsturzes wird dieser bestimmte Anwendungsserver zusammen mit ProxySQL heruntergefahren. Die verbleibenden Anwendungsserver können weiterhin auf ihre jeweiligen lokalen ProxySQL-Instanzen zugreifen. Dieses spezielle Setup hat zusätzliche Funktionen. Sicherheit – ProxySQL ab Version 1.4.8 bietet keine Unterstützung für clientseitiges SSL. Es kann nur eine SSL-Verbindung zwischen ProxySQL und dem Backend einrichten. Das Zusammenstellen von ProxySQL auf dem Anwendungshost und die Verwendung von Unix-Sockets ist eine gute Problemumgehung. ProxySQL kann auch Abfragen zwischenspeichern, und wenn Sie diese Funktion verwenden möchten, ist es sinnvoll, sie so nah wie möglich an der Anwendung zu halten, um die Latenz zu reduzieren. Wir empfehlen, dieses Muster zum Bereitstellen von ProxySQL zu verwenden.
Typische Einstellungen
Sehen wir uns Beispiele für hochverfügbare Setups an.
Einzelnes Rechenzentrum, MySQL-Replikation
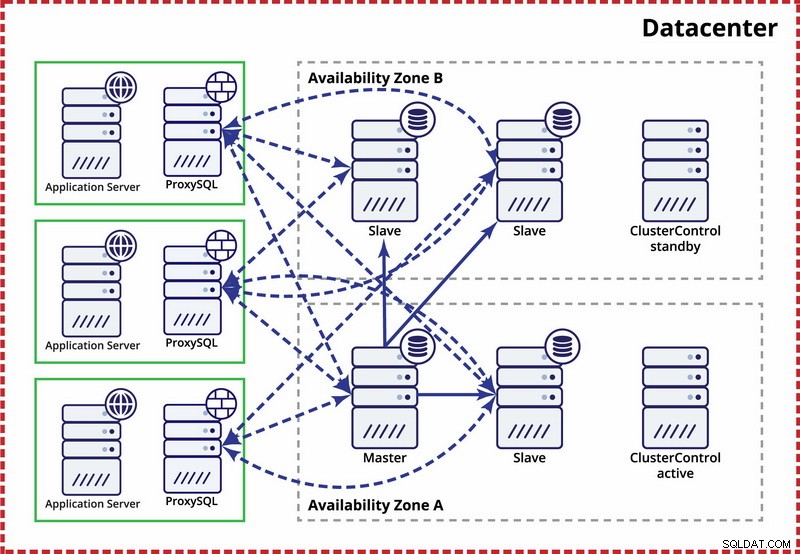
Die Annahme hier ist, dass es zwei getrennte Zonen innerhalb des Rechenzentrums gibt. Jede Zone verfügt über redundante und separate Stromversorgung, Netzwerke und Konnektivität, um die Wahrscheinlichkeit zu verringern, dass zwei Zonen gleichzeitig ausfallen. Es ist möglich, eine Replikationstopologie einzurichten, die sich über beide Zonen erstreckt.
Hier verwenden wir ClusterControl, um das Failover zu verwalten. Um das Split-Brain-Szenario zwischen Verfügbarkeitszonen zu lösen, stellen wir das aktive ClusterControl mit dem Master zusammen. Wir setzen auch Slaves in der anderen Verfügbarkeitszone auf die schwarze Liste, um sicherzustellen, dass das automatisierte Failover nicht dazu führt, dass zwei Master verfügbar sind.
Mehrere Rechenzentren, MySQL-Replikation
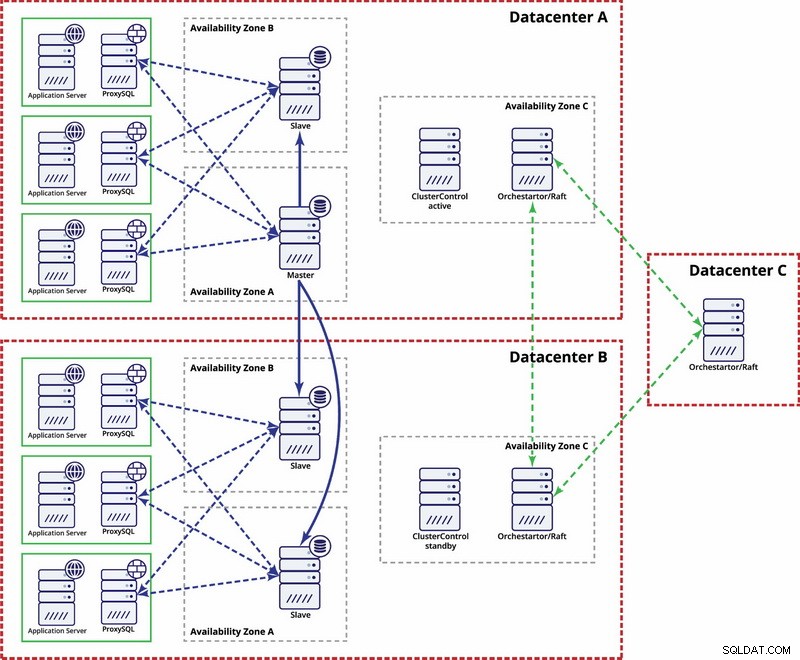
In diesem Beispiel verwenden wir drei Rechenzentren und Orchestrator/Raft für die Quorumberechnung. Möglicherweise müssen Sie Ihre eigenen Skripts schreiben, um STONITH zu implementieren, wenn sich der Master im partitionierten Segment der Infrastruktur befindet. ClusterControl wird für Knotenwiederherstellungs- und Verwaltungsfunktionen verwendet.
Mehrere Rechenzentren, Galera-Cluster
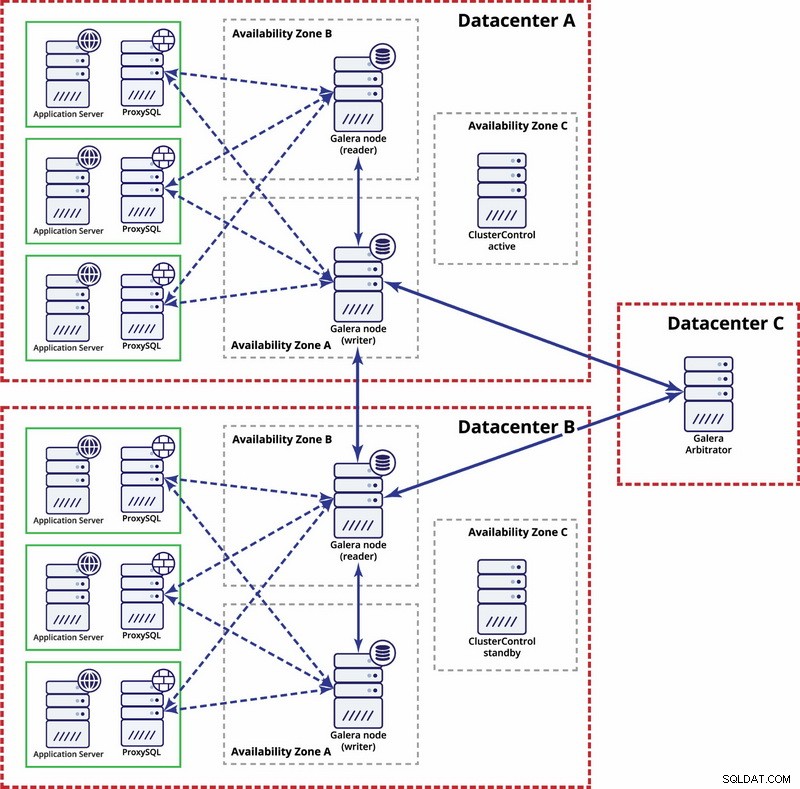
In diesem Fall verwenden wir drei Rechenzentren mit einem Galera-Schiedsrichter im dritten - dies ermöglicht den Ausfall des gesamten Rechenzentrums und reduziert das Risiko einer Netzwerkpartitionierung, da das dritte Rechenzentrum als Relais verwendet werden kann.
Weitere Informationen finden Sie im Whitepaper „How to Design Highly Available Open Source Database Environments“ und in der Webinar-Aufzeichnung „Designing Open Source Databases for High Availability“.



