Wir bekommen einige nette Rückmeldungen zu unserem Produkt ClusterControl, insbesondere wie einfach es zu installieren und loszulegen ist. Neue Software zu installieren ist eine Sache, sie richtig zu verwenden eine andere.
Es ist nicht ungewöhnlich, dass man ungeduldig ist, neue Software zu testen, und lieber mit einer neuen spannenden Anwendung herumspielt, als die Dokumentation zu lesen, bevor man loslegt. Das ist ein bisschen unglücklich, da Sie möglicherweise wichtige Funktionen verpassen oder deren Verwendung falsch verstehen.
Diese Blogserie behandelt alle grundlegenden Operationen von ClusterControl für MySQL, MongoDB und PostgreSQL mit Beispielen, wie Sie das Beste aus Ihrem Setup machen. Es bietet Ihnen einen tiefen Einblick in verschiedene Themen, um Zeit zu sparen.
Dies sind die Themen, die in dieser Reihe behandelt werden:
- Bereitstellung der ersten Cluster
- Hinzufügen Ihrer bestehenden Infrastruktur
- Leistungs- und Integritätsüberwachung
- Machen Sie Ihre Komponenten HA
- Workflow-Management
- Schutz Ihrer Daten
- Schutz Ihrer Daten
- Eingehender Anwendungsfall
Im heutigen Beitrag behandeln wir die Installation von ClusterControl und die Bereitstellung Ihrer ersten Cluster.
Vorbereitungen
In dieser Serie verwenden wir eine Reihe von Vagrant-Boxen, aber Sie können Ihre eigene Infrastruktur verwenden, wenn Sie möchten. Falls Sie es mit Vagrant testen möchten, haben wir ein Beispiel-Setup aus dem folgenden Github-Repository zur Verfügung gestellt:https://github.com/severalnines/vagrant
Klonen Sie das Repo auf Ihren eigenen Rechner:
$ git clone example@sqldat.com:severalnines/vagrant.gitDie Topologie der vagabundierenden Knoten ist wie folgt:
- vm1:Clustersteuerung
- vm2:Datenbankknoten1
- vm3:Datenbankknoten2
- vm4:Datenbankknoten3
Sie können ganz einfach weitere Knoten hinzufügen, wenn Sie möchten, indem Sie die folgende Zeile ändern:
4.times do |n|Die Vagrant-Datei ist so konfiguriert, dass sie ClusterControl automatisch auf dem ersten Knoten installiert und die Benutzeroberfläche von ClusterControl an Port 8080 auf Ihrem Host weiterleitet, auf dem Vagrant ausgeführt wird. Wenn also die IP-Adresse Ihres Hosts 192.168.1.10 lautet, finden Sie die ClusterControl-Benutzeroberfläche hier:https://192.168.1.10:8080/clustercontrol/
ClusterControl installieren
Sie können dies überspringen, wenn Sie sich für die Verwendung der Vagrant-Datei entschieden haben, und erhalten die automatische Installation. Die Installation von ClusterControl ist jedoch unkompliziert und dauert weniger als fünf Minuten.
Bei der Paketinstallation müssen Sie lediglich die folgenden drei Befehle auf dem ClusterControl-Knoten ausführen, um es zu installieren:
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userDas ist es:Einfacher geht es nicht. Wenn das Installationsskript keine Probleme festgestellt hat, sollte ClusterControl installiert und betriebsbereit sein. Sie können sich jetzt unter folgender URL bei ClusterControl anmelden:https://192.168.1.210/clustercontrol
Nachdem Sie ein Administratorkonto erstellt und sich angemeldet haben, werden Sie aufgefordert, Ihren ersten Cluster hinzuzufügen.
Stellen Sie einen Galera-Cluster bereit
Sie werden aufgefordert, einen neuen Datenbankserver/-cluster zu erstellen oder einen vorhandenen (d. h. bereits bereitgestellten) Server oder Cluster zu importieren:
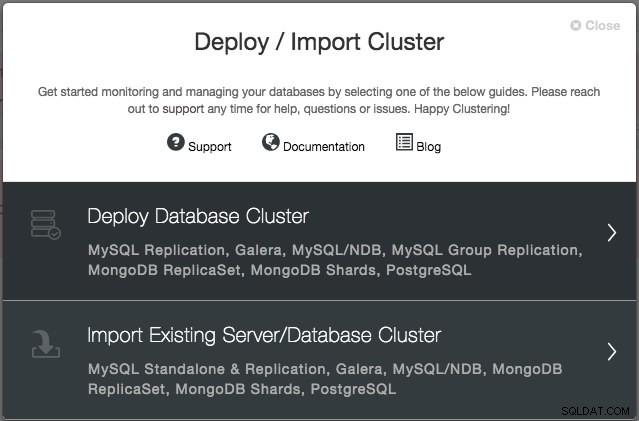
Wir werden einen Galera-Cluster bereitstellen. Es gibt zwei Abschnitte, die ausgefüllt werden müssen. Die erste Registerkarte bezieht sich auf SSH und allgemeine Einstellungen:
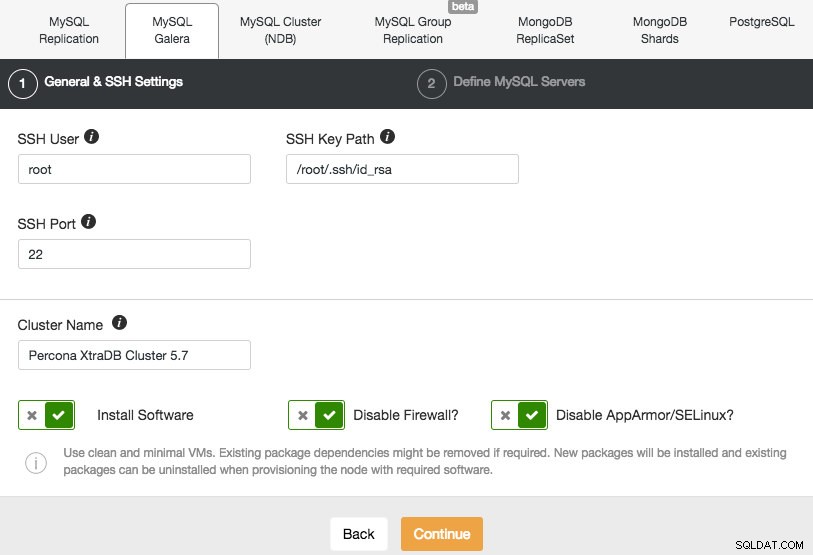
Damit ClusterControl die Galera-Knoten installieren kann, verwenden wir den Root-Benutzer, dem von den Vagrant-Bootstrap-Skripten SSH-Zugriff gewährt wurde. Falls Sie sich entschieden haben, Ihre eigene Infrastruktur zu verwenden, müssen Sie hier einen Benutzer eingeben, der berechtigt ist, passwortloses SSH zu den Knoten auszuführen, die ClusterControl steuert. Denken Sie nur daran, dass Sie zuvor selbst passwortloses SSH von ClusterControl zu allen Datenbankknoten einrichten müssen.
Stellen Sie außerdem sicher, dass Sie AppArmor/SELinux deaktivieren. Sehen Sie hier warum.
Fahren Sie dann mit der zweiten Stufe fort und geben Sie die datenbankbezogenen Informationen und die Zielhosts an:
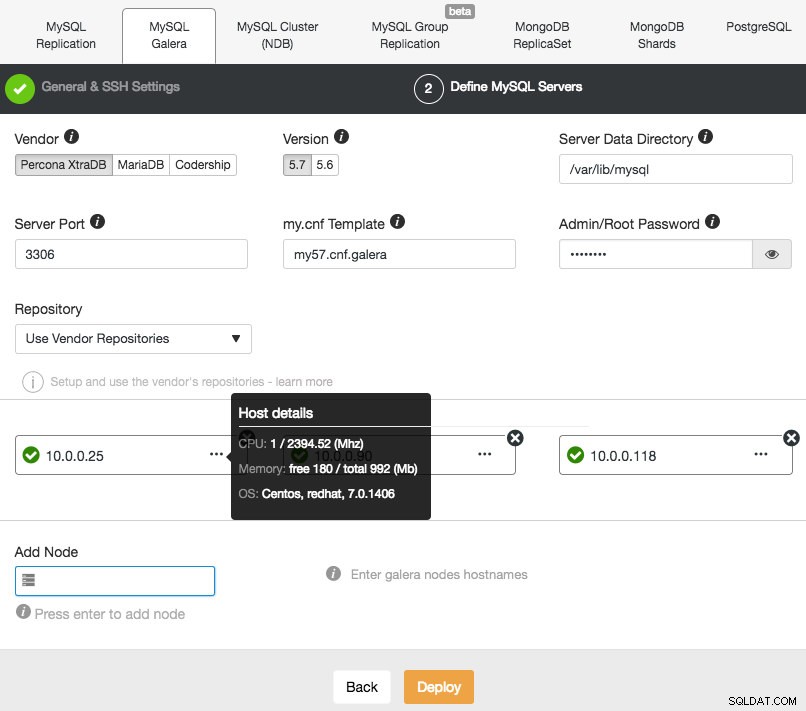
ClusterControl führt jedes Mal, wenn Sie beim Hinzufügen eines Knotens die Eingabetaste drücken, sofort einige Plausibilitätsprüfungen durch. Sie können die Hostzusammenfassung anzeigen, indem Sie den Mauszeiger über jeden definierten Knoten bewegen. Sobald alles grün ist, bedeutet dies, dass ClusterControl eine Verbindung zu allen Knoten hat, können Sie auf Deploy klicken. Es wird ein Job erzeugt, um den neuen Cluster zu erstellen. Das Schöne ist, dass Sie den Fortschritt dieses Jobs verfolgen können, indem Sie auf Aktivität -> Jobs -> Cluster erstellen -> Vollständige Jobdetails klicken :
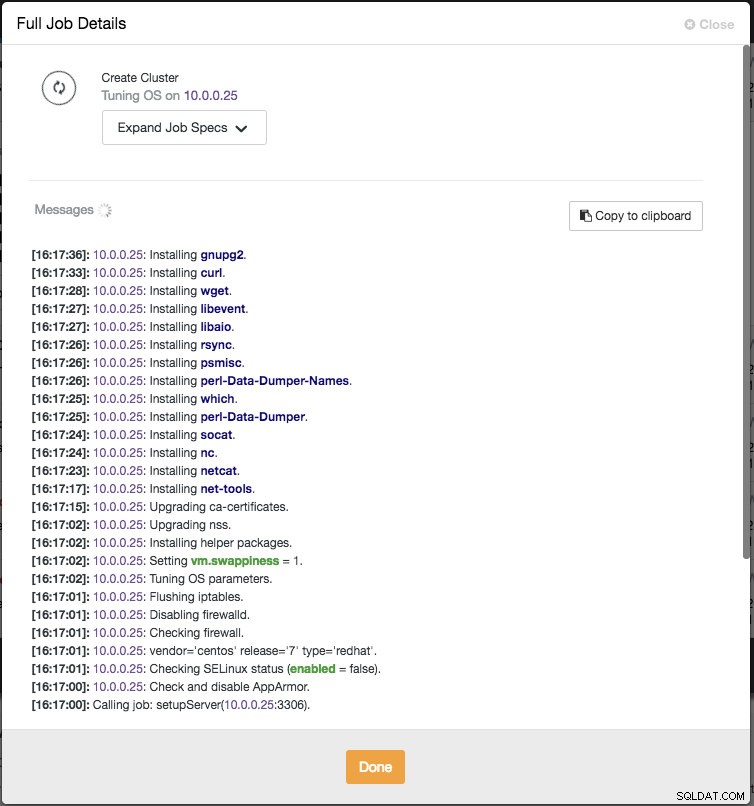
Wenn der Job abgeschlossen ist, haben Sie gerade Ihren ersten Cluster erstellt. Die Clusterübersicht sollte wie folgt aussehen:
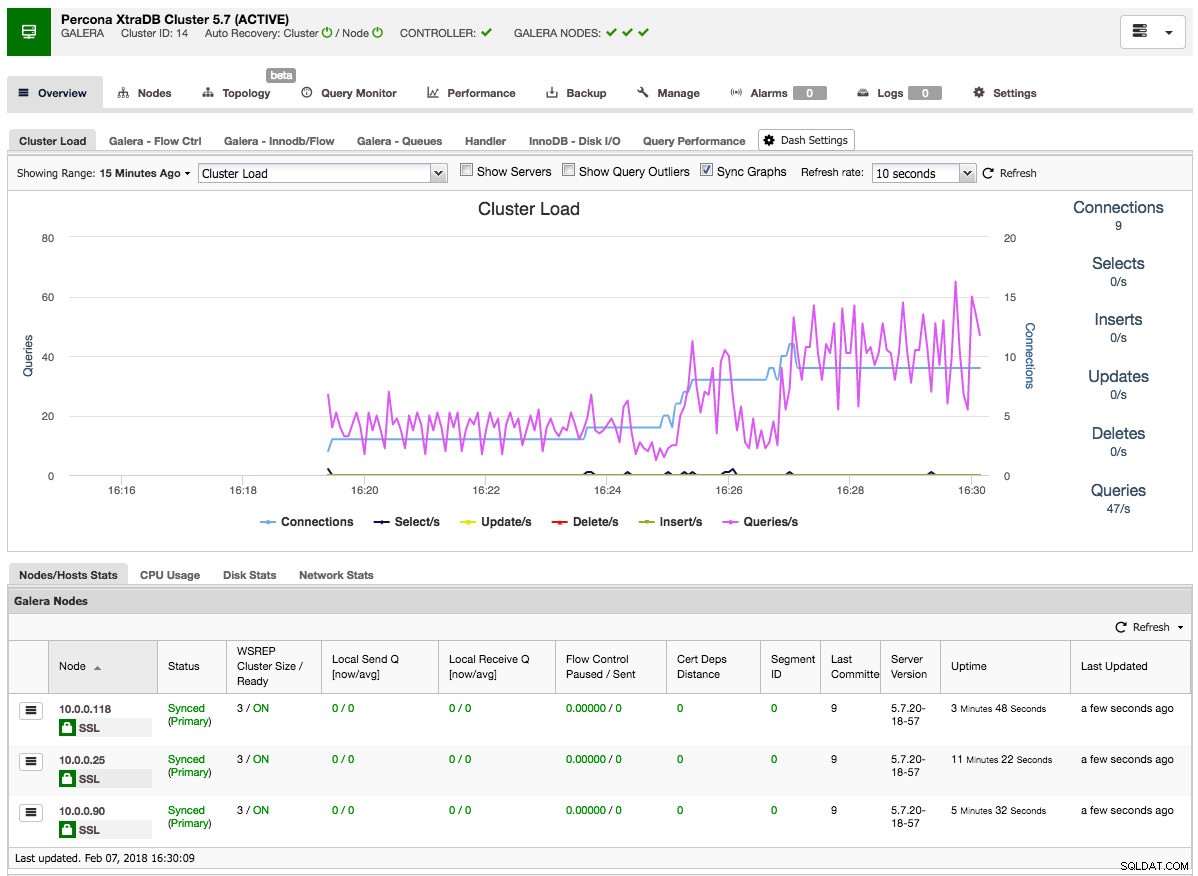
Auf der Registerkarte Knoten können Sie alle Vorgänge ausführen, die Sie normalerweise auf einem Cluster ausführen würden. Der Abfragemonitor gibt Ihnen einen guten Überblick über laufende und Top-Abfragen. Die Registerkarte Leistung hilft Ihnen dabei, die Leistung Ihres Clusters genau im Auge zu behalten, und enthält auch die Berater, die Ihnen helfen, proaktiv auf Datentrends zu reagieren. Auf der Registerkarte Backup können Sie Backups einfach planen und auf lokalem oder Cloud-Speicher speichern. Auf der Registerkarte „Verwalten“ können Sie Ihren Cluster erweitern oder über einen Load Balancer hochverfügbar für Ihre Anwendungen machen.
Alle diese Funktionen werden in späteren Blog-Beiträgen dieser Serie behandelt.
Stellen Sie einen MySQL-Replikationscluster bereit
Das Bereitstellen eines MySQL-Replikations-Setups ähnelt dem Bereitstellen einer Galera-Datenbank, außer dass es eine zusätzliche Registerkarte im Bereitstellungsdialog gibt, auf der Sie die Replikationstopologie definieren können:
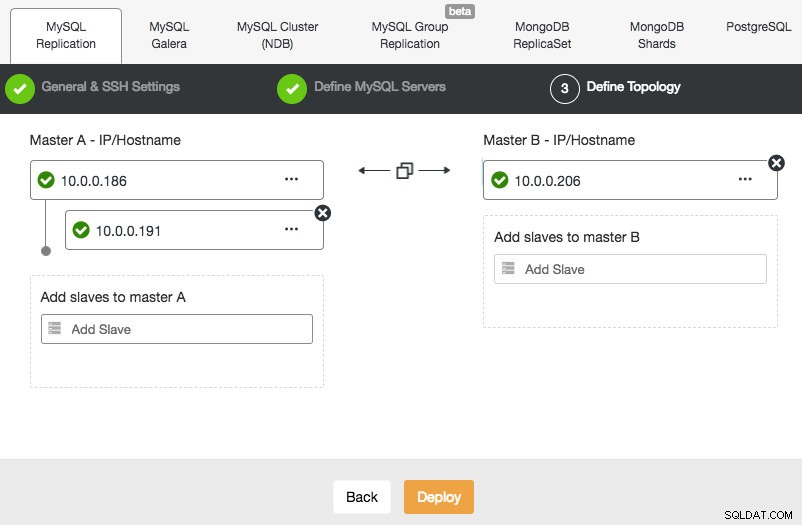
Sie können eine standardmäßige Master-Slave-Replikation sowie eine Master-Master-Replikation einrichten. Im letzteren Fall bleibt jeweils nur ein Master beschreibbar. Denken Sie daran, dass die Master-Master-Replikation nicht mit Konfliktlösung und garantierter Datenkonsistenz einhergeht, wie im Fall von Galera. Verwenden Sie dieses Setup mit Vorsicht oder sehen Sie sich den Galera-Cluster an. Sobald alles grün ist und Sie auf Bereitstellen geklickt haben, wird ein Job zum Erstellen des neuen Clusters erstellt.
Auch hier ist der Bereitstellungsfortschritt unter Aktivität -> Jobs verfügbar.
Um den Slave zu skalieren (Kopie lesen), verwenden Sie einfach die Option „Knoten hinzufügen“ in der Clusterliste:
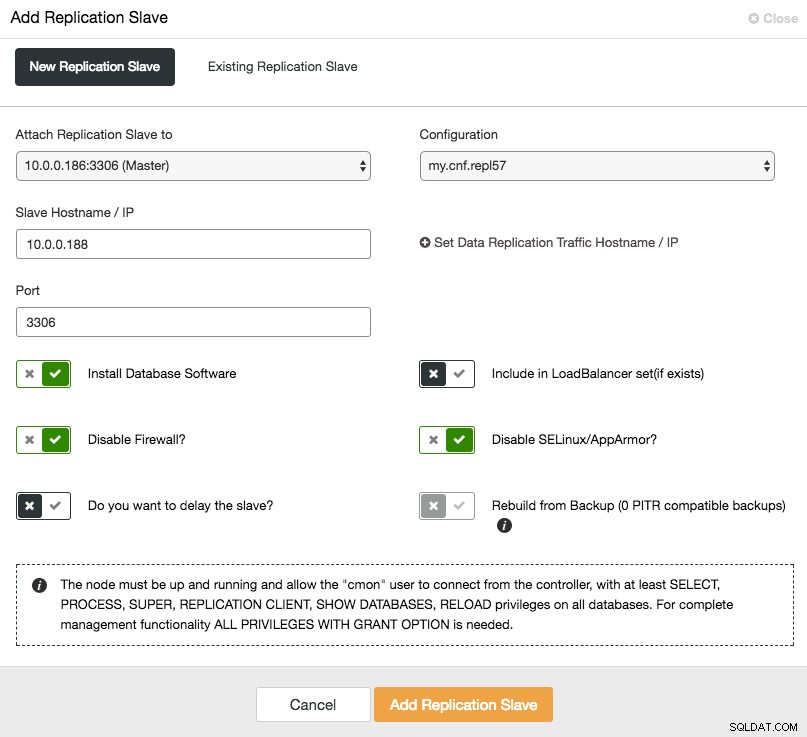
Nach dem Hinzufügen des Slave-Knotens stellt ClusterControl dem Slave eine Kopie der Daten von seinem Master unter Verwendung von Xtrabackup oder von vorhandenen PITR-kompatiblen Backups für diesen Cluster bereit.
PostgreSQL-Replikation bereitstellen
ClusterControl unterstützt die Bereitstellung von PostgreSQL Version 9.x und höher. Die Schritte sind ähnlich wie bei der Bereitstellung von MySQL Replication, wo Sie am Ende des Bereitstellungsschritts die Datenbanktopologie definieren können, wenn Sie die Knoten hinzufügen:
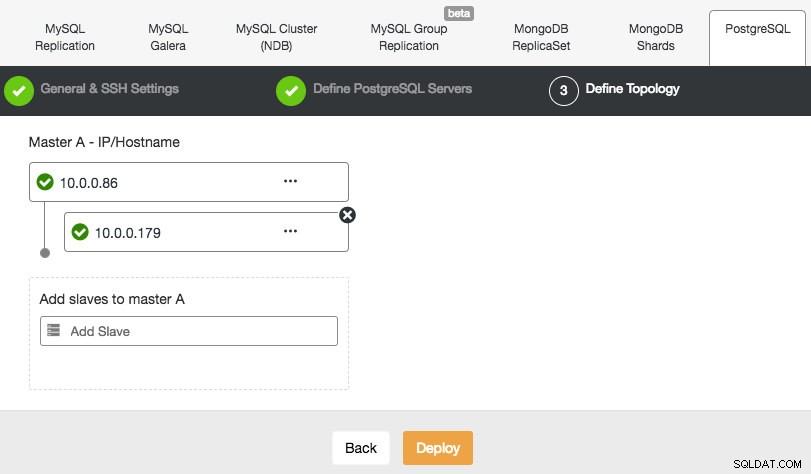
Ähnlich wie bei der MySQL-Replikation können Sie nach Abschluss der Bereitstellung skalieren, indem Sie Replikations-Slaves zum Cluster hinzufügen. Der Schritt ist so einfach wie das Auswählen des Masters und das Ausfüllen des FQDN für den neuen Slave:
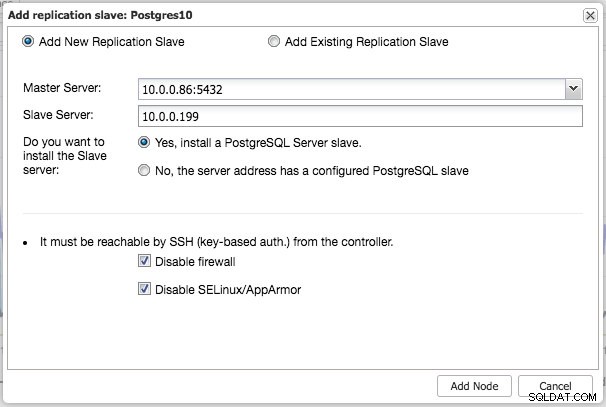
ClusterControl führt dann mit pg_basebackup das erforderliche Daten-Staging vom ausgewählten Master durch, konfiguriert den Replikationsbenutzer und aktiviert die Streaming-Replikation. Die PostgreSQL-Clusterübersicht gibt Ihnen einen Einblick in Ihr Setup:
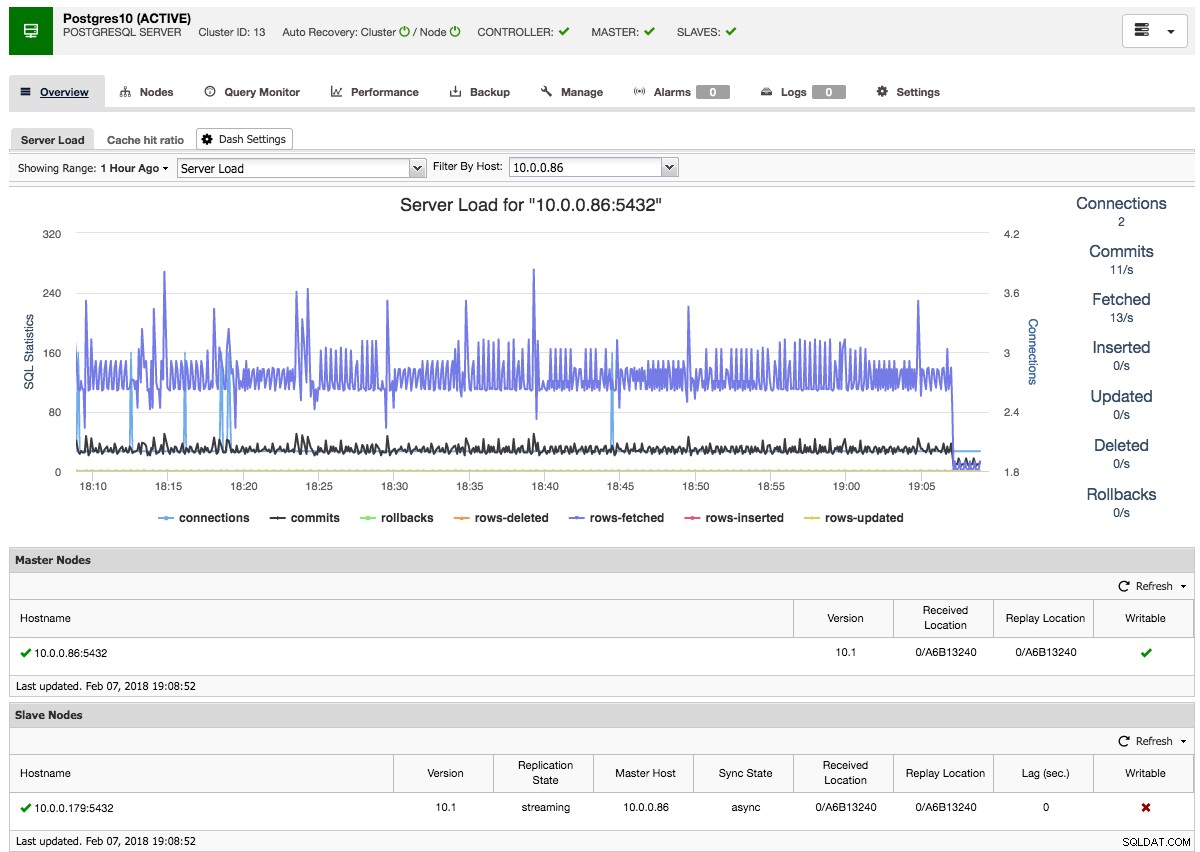
Genau wie bei den Galera- und MySQL-Cluster-Übersichten finden Sie hier alle erforderlichen Registerkarten und Funktionen:Die Registerkarten Abfrageüberwachung, Leistung und Sicherung ermöglichen es Ihnen, die erforderlichen Vorgänge auszuführen.
Einen MongoDB-Replikatsatz bereitstellen
Das Bereitstellen eines neuen MongoDB-Replikatsatzes ist ähnlich wie bei anderen Clustern. Wählen Sie im Dialogfeld „Datenbankcluster bereitstellen“ MongoDB ReplicatSet aus, definieren Sie die bevorzugten Datenbankoptionen und fügen Sie die Datenbankknoten hinzu:
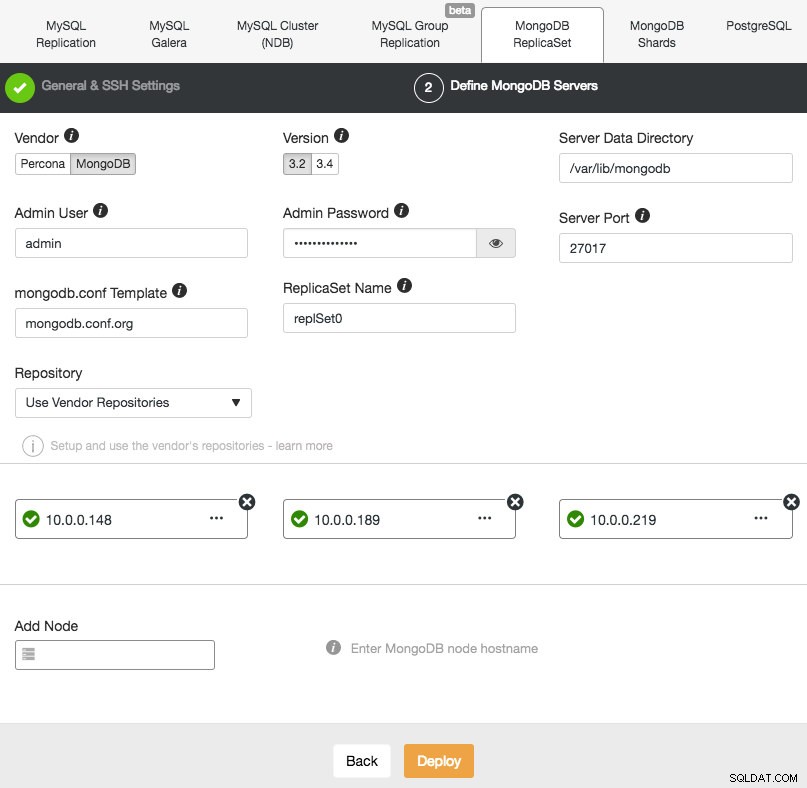
Sie können entweder Percona Server für MongoDB von Percona oder MongoDB Server von MongoDB, Inc (ehemals 10gen) installieren. Sie müssen auch den MongoDB-Administratorbenutzer und das Kennwort angeben, da ClusterControl standardmäßig einen MongoDB-Cluster mit aktivierter Authentifizierung bereitstellt.
Nach der Installation des Clusters können Sie einen zusätzlichen Slave- oder Arbiter-Knoten zum Replica-Set hinzufügen, indem Sie das Menü "Knoten hinzufügen" unter derselben Dropdown-Liste aus der Cluster-Übersicht verwenden:
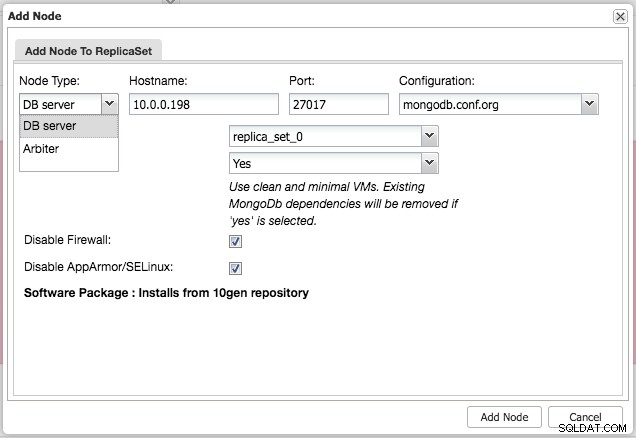
Nach dem Hinzufügen des Slaves oder Arbiters zum Replikatsatz wird ein Job erzeugt. Nachdem dieser Job abgeschlossen ist, dauert es eine Weile, bis MongoDB ihn dem Cluster hinzufügt und er in der Cluster-Übersicht sichtbar wird:
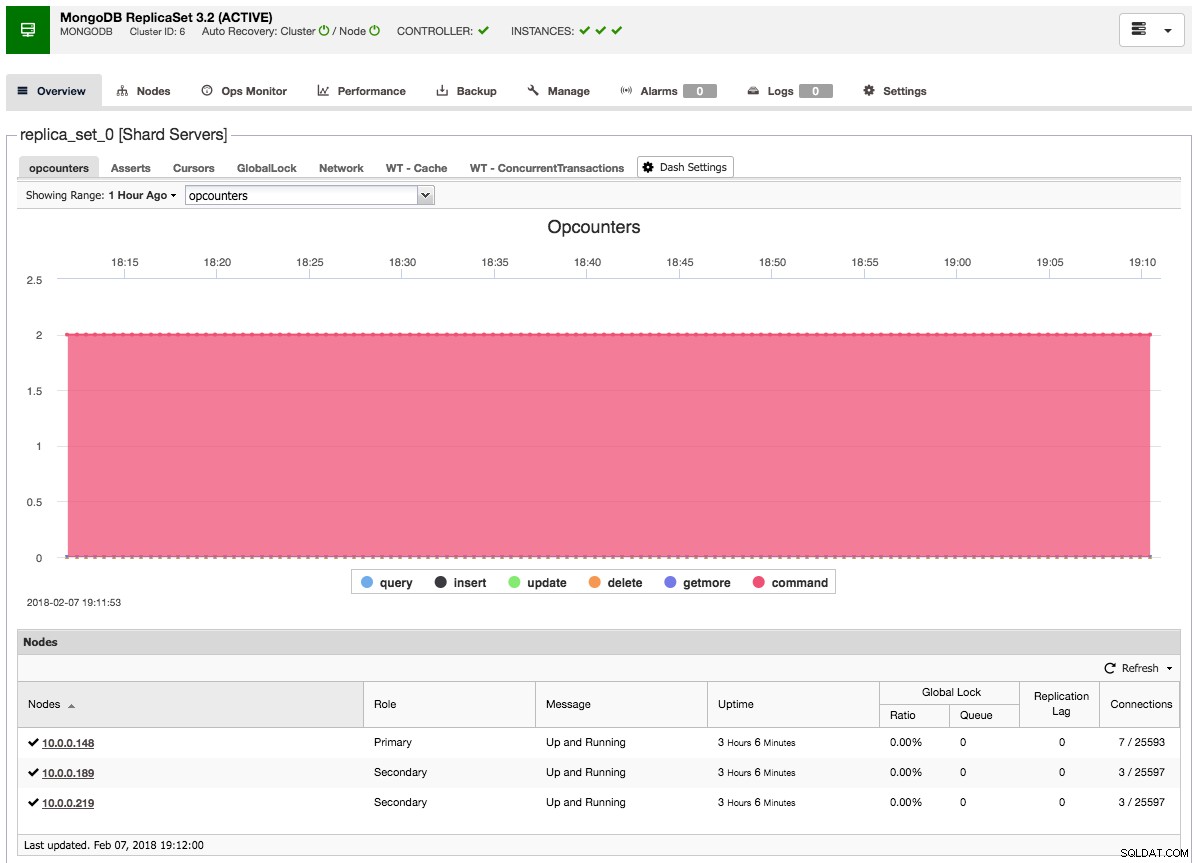
Abschließende Gedanken
Mit diesen drei Beispielen haben wir Ihnen gezeigt, wie einfach es ist, verschiedene Cluster in nur wenigen Minuten von Grund auf neu einzurichten. Das Schöne an der Verwendung dieses Vagrant-Setups ist, dass Sie diese Umgebung so einfach wie das Spawnen auch abbauen und dann erneut spawnen können. Beeindrucken Sie Ihre Kollegen, indem Sie zeigen, wie schnell Sie eine Arbeitsumgebung einrichten können.
Natürlich wäre es ebenso interessant, bestehende Hosts und bereits bereitgestellte Cluster zu ClusterControl hinzuzufügen, und darauf werden wir beim nächsten Mal eingehen.