Um eine Datenbank effizient zu betreiben, müssen Sie Einblick in die Datenbankleistung haben. Dies mag nicht offensichtlich sein, wenn alles gut läuft, aber sobald etwas schief geht, kann der Zugriff auf Informationen hilfreich sein, um das Problem schnell und richtig zu diagnostizieren.
Alle Datenbanken stellen Benutzern einige ihrer internen Statusdaten zur Verfügung. In MySQL erhalten Sie diese Daten hauptsächlich durch Ausführen von 'SHOW STATUS' und 'SHOW GLOBAL STATUS', durch Ausführen von 'SHOW ENGINE INNODB STATUS', Überprüfen von information_schema-Tabellen und in neueren Versionen durch Abfragen von performance_schema-Tabellen.

Diese Methoden sind im täglichen Betrieb alles andere als praktisch, daher die Beliebtheit verschiedener Überwachungs- und Trending-Lösungen. Tools wie Nagios/Icinga wurden entwickelt, um Hosts/Dienste zu überwachen und zu warnen, wenn ein Dienst außerhalb eines akzeptablen Bereichs liegt. Andere Tools wie Cacti und Munin bieten einen grafischen Blick auf Host-/Service-Informationen und geben einen historischen Kontext zu Leistung und Nutzung. ClusterControl kombiniert diese beiden Arten der Überwachung, also werfen wir einen Blick auf die Informationen, die es präsentiert, und wie wir sie interpretieren sollten.
Wenn Sie Galera Cluster (MySQL Galera Cluster von Codership oder MariaDB Cluster oder Percona XtraDB Cluster) verwenden, ist Ihnen möglicherweise der folgende Abschnitt auf der Registerkarte „Übersicht“ von ClusterControl aufgefallen:
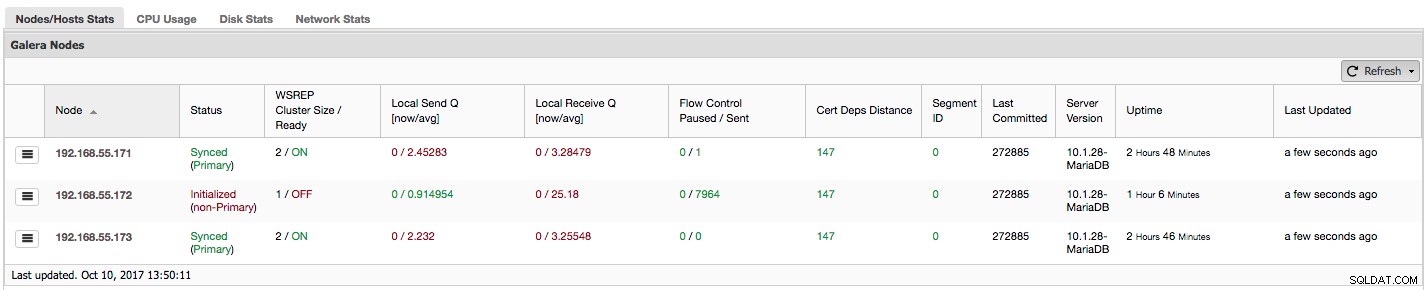
Sehen wir uns Schritt für Schritt an, welche Art von Daten wir hier haben.
Die erste Spalte enthält die Liste der Knoten mit ihren IP-Adressen - mehr gibt es dazu nicht zu sagen.
Die zweite Spalte ist interessanter - sie beschreibt den Knotenstatus (wsrep_local_state_comment Status). Ein Knoten kann sich in verschiedenen Zuständen befinden:
- Initialisiert – Der Knoten ist betriebsbereit, aber nicht Teil eines Clusters. Dies kann beispielsweise durch Netzwerkprobleme verursacht werden;
- Joining – Der Knoten ist dabei, dem Cluster beizutreten, und er empfängt oder fordert eine Zustandsübertragung von einem der anderen Knoten an;
- Donor/Desynced – Der Knoten dient als Spender für einen anderen Knoten, der dem Cluster beitritt;
- Beigetreten – Der Knoten ist dem Cluster beigetreten, aber er ist damit beschäftigt, zugesicherte Schreibsätze nachzuholen;
- Synchronisiert - Der Knoten funktioniert normal.
In derselben Spalte innerhalb der Klammer befindet sich der Clusterstatus (wsrep_cluster_status Status). Es kann drei unterschiedliche Zustände haben:
- Primär - Die Kommunikation zwischen den Knoten funktioniert und das Quorum ist vorhanden (die Mehrheit der Knoten ist verfügbar)
- Non-Primary - Der Knoten war Teil des Clusters, hat aber aus irgendeinem Grund den Kontakt zum Rest des Clusters verloren. Daher wird dieser Knoten als inaktiv betrachtet und akzeptiert keine Anfragen
- Getrennt – Der Knoten konnte keine Gruppenkommunikation aufbauen.
„WSREP Cluster Size / Ready“ gibt Auskunft über eine Clustergröße, wie sie der Knoten sieht, und ob der Knoten bereit ist, Abfragen anzunehmen. Nicht-primäre Komponenten erstellen einen Cluster mit der Größe 1 und die wsrep-Bereitschaft ist AUS.
Werfen wir einen Blick auf den obigen Screenshot und sehen, was er uns über Galera sagt. Wir können drei Knoten sehen. Zwei davon (192.168.55.171 und 192.168.55.173) sind vollkommen in Ordnung, sie sind beide „Synced“ und der Cluster befindet sich im „Primary“-Zustand. Der Cluster besteht derzeit aus zwei Knoten. Knoten 192.168.55.172 ist „Initialisiert“ und bildet eine „Nicht-Primär“-Komponente. Dies bedeutet, dass dieser Knoten die Verbindung zum Cluster verloren hat – höchstwahrscheinlich irgendeine Art von Netzwerkproblemen (tatsächlich haben wir iptables verwendet, um den Datenverkehr zu diesem Knoten sowohl von 192.168.55.171 als auch von 192.168.55.173 zu blockieren).
An dieser Stelle müssen wir kurz innehalten und beschreiben, wie Galera Cluster intern funktioniert. Wir werden nicht zu sehr ins Detail gehen, da dies nicht Gegenstand dieses Blogbeitrags ist, aber einige Kenntnisse sind erforderlich, um die Bedeutung der in den nächsten Spalten präsentierten Daten zu verstehen.
Galera ist ein „virtuell“ synchroner Multi-Master-Cluster. Das bedeutet, dass Sie damit rechnen sollten, dass Daten "virtuell" gleichzeitig zwischen Knoten übertragen werden (keine lästigen Probleme mehr mit verzögerten Slaves) und dass Sie auf jeden Knoten in einem Cluster schreiben können (keine lästigen Probleme mehr, wenn Sie einen Slave zum Master machen ). Um dies zu erreichen, verwendet Galera Writesets – atomare Sätze von Änderungen, die im gesamten Cluster repliziert werden. Ein Writeset kann mehrere Zeilenänderungen und zusätzlich benötigte Informationen wie Daten zum Sperren enthalten.
Sobald ein Client COMMIT ausgibt, aber bevor MySQL tatsächlich irgendetwas festschreibt, wird ein Writeset erstellt und zur Zertifizierung an alle Knoten im Cluster gesendet. Alle Knoten prüfen, ob es möglich ist, die Änderungen festzuschreiben oder nicht (da Änderungen andere Schreibvorgänge stören können, die in der Zwischenzeit direkt auf einem anderen Knoten ausgeführt werden). Wenn ja, werden die Daten tatsächlich von MySQL übergeben, wenn nicht, wird ein Rollback ausgeführt.
Es ist wichtig, sich daran zu erinnern, dass Knoten, ähnlich wie Slaves bei der regulären Replikation, möglicherweise eine andere Leistung erbringen – einige haben möglicherweise eine bessere Hardware als andere, einige sind möglicherweise stärker belastet als andere. Doch Galera verlangt von ihnen, dass sie die Writesets kurz und schnell verarbeiten, um die „virtuelle“ Synchronisation aufrechtzuerhalten. Es muss einen Mechanismus geben, der die Replikation drosseln kann und es langsameren Knoten ermöglicht, mit dem Rest des Clusters Schritt zu halten.
Werfen wir einen Blick auf die Spalten „Local Send Q [now/avg]“ und „Local Receive Q [now/avg]“. Jeder Knoten hat eine lokale Warteschlange zum Senden und Empfangen von Writesets. Es ermöglicht die Parallelisierung einiger der Schreib- und Warteschlangendaten, die nicht sofort verarbeitet werden konnten, wenn der Knoten nicht mit dem Datenverkehr Schritt halten kann. In SHOW GLOBAL STATUS finden wir acht Zähler, die beide Warteschlangen beschreiben, vier Zähler pro Warteschlange:
- wsrep_local_send_queue - Aktueller Status der Sendewarteschlange
- wsrep_local_send_queue_min - Minimum seit FLUSH STATUS
- wsrep_local_send_queue_max - Maximum seit FLUSH STATUS
- wsrep_local_send_queue_avg - Durchschnitt seit FLUSH STATUS
- wsrep_local_recv_queue - Aktueller Zustand der Empfangswarteschlange
- wsrep_local_recv_queue_min - Minimum seit FLUSH STATUS
- wsrep_local_recv_queue_max - Maximum seit FLUSH STATUS
- wsrep_local_recv_queue_avg - Durchschnitt seit FLUSH STATUS
Die oben genannten Metriken sind knotenübergreifend unter ClusterControl -> Performance -> DB Status:
vereinheitlicht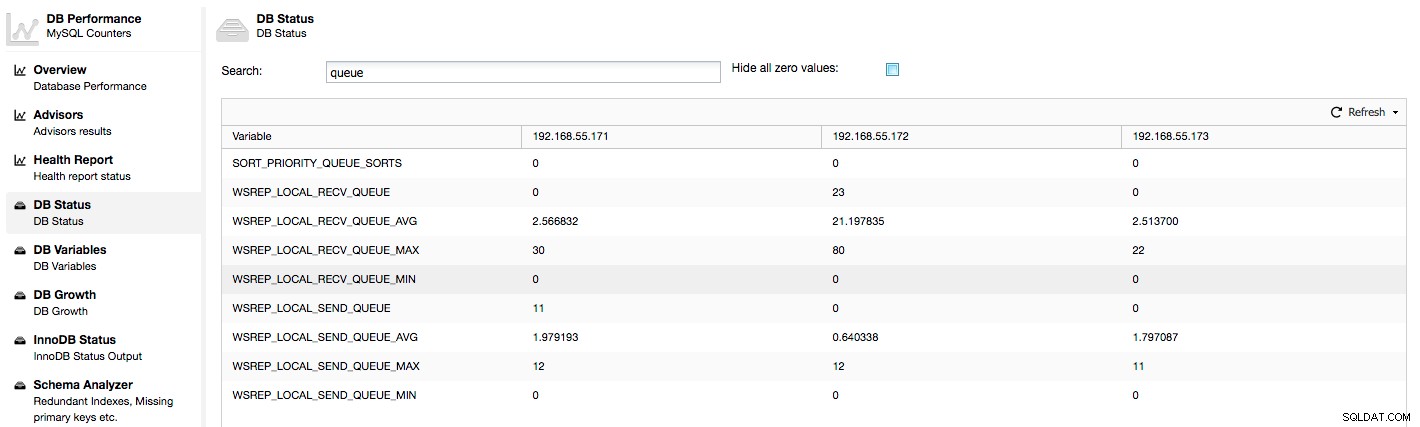
ClusterControl zeigt „Jetzt“- und „Durchschnitts“-Zähler an, da sie als einzelne Zahl am aussagekräftigsten sind (Sie können auch benutzerdefinierte Diagramme erstellen, die auf Variablen basieren, die den aktuellen Status der Warteschlangen beschreiben). Wenn wir sehen, dass eine der Warteschlangen steigt, bedeutet dies, dass der Knoten nicht mit der Replikation Schritt halten kann und andere Knoten langsamer werden müssen, damit er aufholen kann. Wir empfehlen, eine Arbeitslast dieses bestimmten Knotens zu untersuchen – überprüfen Sie die Prozessliste auf einige lang laufende Abfragen, überprüfen Sie Betriebssystemstatistiken wie CPU-Auslastung und E/A-Arbeitslast. Vielleicht ist es auch möglich, einen Teil des Datenverkehrs von diesem Knoten auf den Rest des Clusters umzuverteilen.
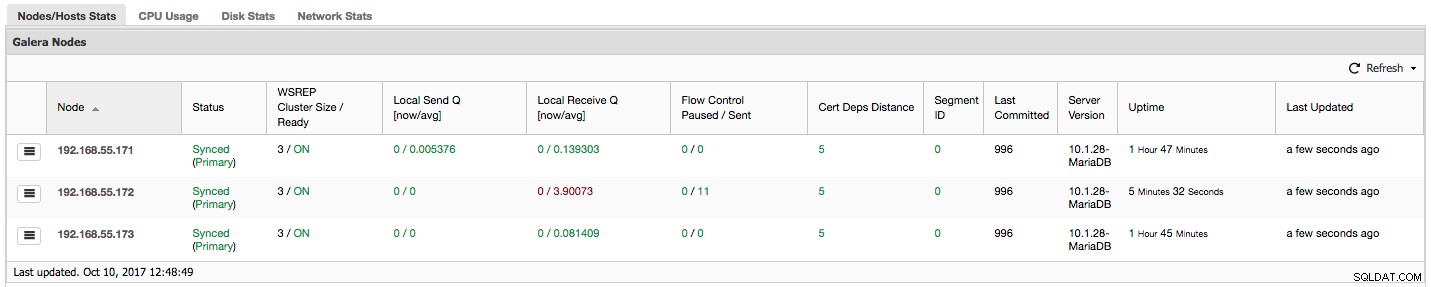
"Flusskontrolle angehalten" zeigt Informationen über den Prozentsatz der Zeit an, die ein bestimmter Knoten hatte, um seine Replikation wegen zu hoher Last anzuhalten. Wenn ein Knoten mit der Arbeitslast nicht Schritt halten kann, sendet er Flow Control-Pakete an andere Knoten und informiert sie, dass sie das Senden von Writesets drosseln sollten. In unserem Screenshot haben wir den Wert „0,30“ für den Knoten 192.168.55.172. Das bedeutet, dass dieser Knoten in fast 30 % der Fälle die Replikation anhalten musste, weil er nicht mit der von anderen Knoten geforderten Writeset-Zertifizierungsrate mithalten konnte (oder einfacher, weil zu viele Schreibvorgänge darauf trafen!). Wie wir sehen können, weist uns auch „Local Receive Q [avg]“ auf diese Tatsache hin.
Die nächste Spalte „Flow Control Sent“ gibt uns Informationen darüber, wie viele Flow Control-Pakete ein bestimmter Knoten an den Cluster gesendet hat. Auch hier sehen wir, dass es der Knoten 192.168.55.172 ist, der den Cluster verlangsamt.
Was können wir mit diesen Informationen tun? Meistens sollten wir untersuchen, was im langsamen Knoten vor sich geht. Überprüfen Sie die CPU-Auslastung, die E/A-Leistung und die Netzwerkstatistiken. Dieser erste Schritt hilft bei der Einschätzung, mit welcher Art von Problem wir konfrontiert sind.
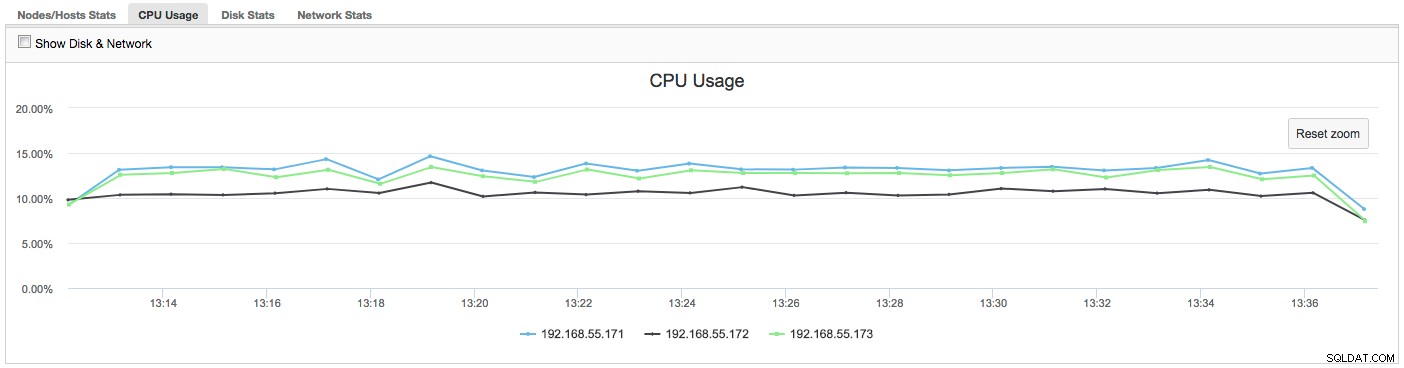
In diesem Fall wird beim Wechseln zur Registerkarte „CPU-Auslastung“ deutlich, dass eine übermäßige CPU-Auslastung unsere Probleme verursacht. Der nächste Schritt wäre, den Übeltäter zu identifizieren, indem Sie in PROCESSLIST (Query Monitor -> Running Queries -> filter by 192.168.55.172) nach fehlerhaften Anfragen suchen:
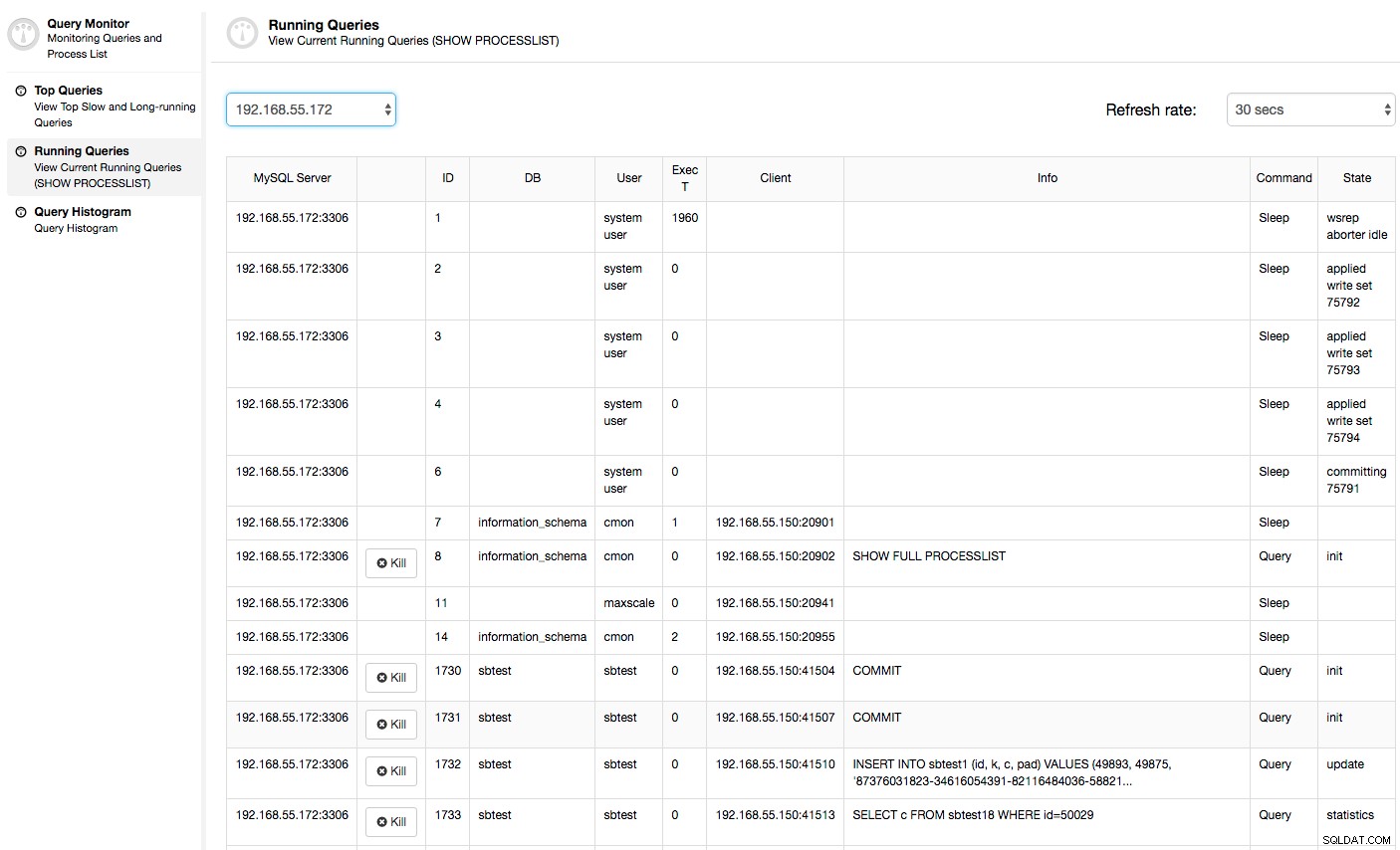
Oder überprüfen Sie Prozesse auf dem Knoten von der Seite des Betriebssystems (Knoten -> 192.168.55.172 -> Top), um zu sehen, ob die Last nicht durch etwas außerhalb von Galera/MySQL verursacht wird.
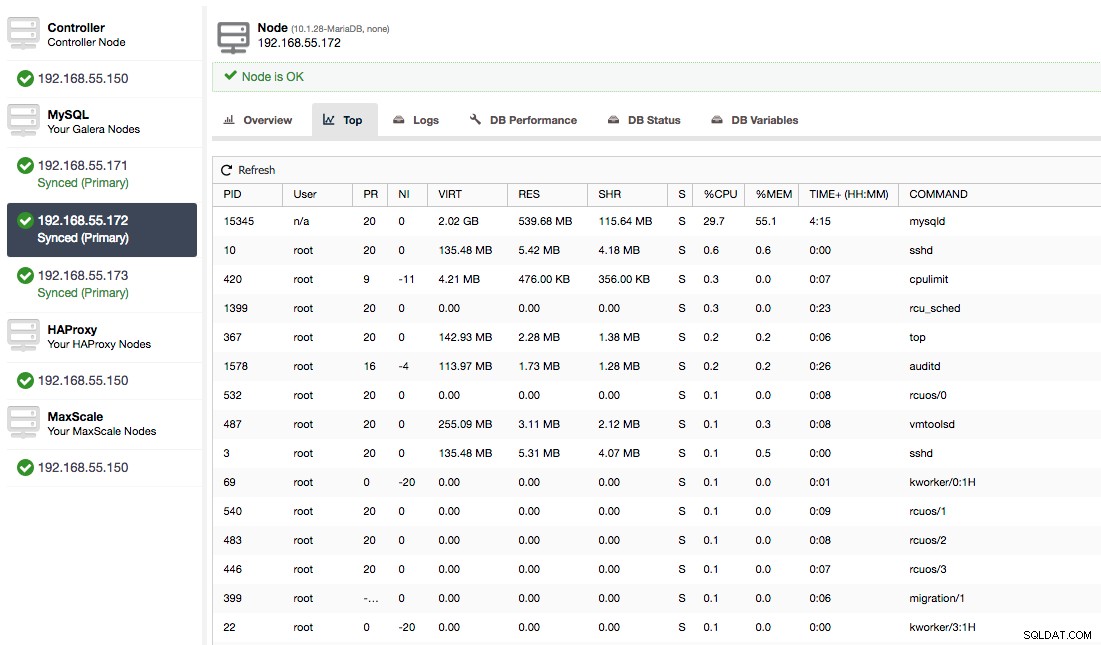
In diesem Fall haben wir den mysqld-Befehl über cpulimit ausgeführt, um eine langsame CPU-Auslastung speziell für den mysqld-Prozess zu simulieren, indem wir ihn auf 30 % von 400 % verfügbarer CPU beschränken (der Server hat 4 Kerne).
Die Spalte "Cert Deps Distance" gibt uns Auskunft darüber, wie viele Writesets im Durchschnitt parallel angewendet werden können. Writesets können manchmal gleichzeitig ausgeführt werden - Galera macht sich dies zunutze, indem es mehrere wsrep_slave_threads verwendet Writesets anwenden. Diese Spalte gibt Ihnen eine Vorstellung davon, wie viele Slave-Threads Sie für Ihre Arbeitslast verwenden könnten. Es ist erwähnenswert, dass es keinen Sinn macht, wsrep_slave_threads einzurichten Variable auf höhere Werte als in dieser Spalte oder in wsrep_cert_deps_distance angezeigt Statusvariable, auf der die Spalte "Cert Deps Distance" basiert. Noch ein wichtiger Hinweis - es hat auch keinen Sinn, wsrep_slave_threads zu setzen variabel auf mehr als die Anzahl der Kerne, die Ihre CPU hat.
„Segment-ID“ – diese Spalte bedarf einer weiteren Erläuterung. Segmente sind eine neue Funktion, die in Galera 3.0 hinzugefügt wurde. Vor dieser Version wurden Writesets zwischen allen Knoten ausgetauscht. Nehmen wir an, wir haben zwei Rechenzentren:
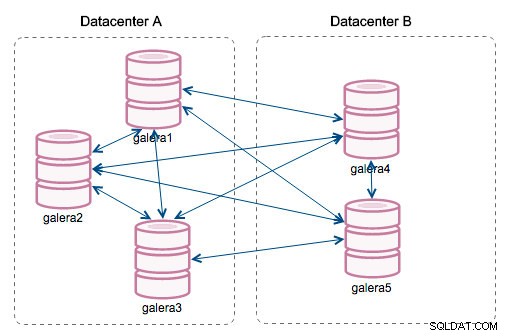
Diese Art von Chatter funktioniert in lokalen Netzwerken gut, aber WAN ist eine andere Geschichte - die Zertifizierung verlangsamt sich aufgrund erhöhter Latenz, zusätzliche Kosten entstehen aufgrund der Netzwerkbandbreite, die für die Übertragung von Writesets zwischen jedem Mitglied des Clusters verwendet wird.
Mit der Einführung von „Segmenten“ änderten sich die Dinge. Sie können einem Segment einen Knoten zuweisen, indem Sie wsrep_provider_options ändern -Variable und fügen ihr "gmcast.segment=x" (0, 1, 2) hinzu. Knoten mit derselben Segmentnummer werden so behandelt, als ob sie sich im selben Rechenzentrum befinden und über ein lokales Netzwerk verbunden sind. Unser Diagramm wird dann anders:
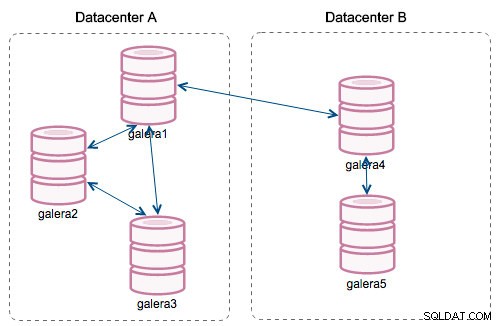
Der Hauptunterschied besteht darin, dass es keine Jeder-zu-Jeder-Kommunikation mehr gibt. Innerhalb jedes Segments, ja – es ist immer noch derselbe Mechanismus, aber beide Segmente kommunizieren nur über eine einzige Verbindung zwischen zwei ausgewählten Knoten. Im Falle eines Ausfalls wird diese Verbindung automatisch umgeschaltet. Infolgedessen kommt es zu weniger Netzwerkgeplapper und weniger Bandbreitennutzung zwischen entfernten Rechenzentren. Im Grunde sagt uns die Spalte "Segment-ID", welchem Segment ein Knoten zugewiesen ist.
Die Spalte "Last Committed" gibt uns Informationen über die Sequenznummer des Writesets, das zuletzt auf einem bestimmten Knoten ausgeführt wurde. Es kann nützlich sein, um festzustellen, welcher Knoten der aktuellste ist, wenn ein Bootstrap des Clusters erforderlich ist.
Die restlichen Spalten sind selbsterklärend:Serverversion, Betriebszeit eines Knotens und wann der Status aktualisiert wurde.
Wie Sie sehen können, gibt Ihnen der Abschnitt „Galera Nodes“ der „Nodes/Hosts Stats“ auf der Registerkarte „Overview“ einen ziemlich guten Überblick über den Zustand des Clusters – ob er eine „primäre“ Komponente bildet, wie viele Nodes fehlerfrei sind , gibt es Leistungsprobleme bei einigen Knoten und wenn ja, welcher Knoten verlangsamt den Cluster.
Dieser Datensatz ist sehr praktisch, wenn Sie Ihren Galera-Cluster betreiben, also hoffentlich kein Blindflug mehr :-)



