Der Galera-Cluster erzwingt eine starke Datenkonsistenz, bei der alle Knoten im Cluster eng gekoppelt sind. Obwohl die Netzwerksegmentierung unterstützt wird, ist die Replikationsleistung immer noch von zwei Faktoren abhängig:
-
Die Round Trip Time (RTT) zum am weitesten vom Ursprungsknoten entfernten Knoten im Cluster.
-
Die Größe eines Writesets, das übertragen und für Konflikte auf dem Empfängerknoten zertifiziert werden soll.
Während es Möglichkeiten gibt, die Leistung von Galera zu steigern, ist es nicht möglich, diese beiden einschränkenden Faktoren zu umgehen.
Glücklicherweise wurde Galera Cluster auf MySQL aufgebaut, das auch mit einer eingebauten Replikationsfunktion ausgestattet ist (duh!). Sowohl die Galera-Replikation als auch die MySQL-Replikation existieren unabhängig voneinander in derselben Serversoftware. Wir können diese Technologien nutzen, um zusammenzuarbeiten, wobei die gesamte Replikation innerhalb eines Rechenzentrums auf Galera erfolgt, während die Replikation zwischen Rechenzentren auf der Standard-MySQL-Replikation erfolgt. Die Slave-Site kann als Hot-Standby-Site fungieren und bereit sein, Daten bereitzustellen, sobald die Anwendungen auf die Backup-Site umgeleitet werden. Wir haben dies in einem früheren Blog über MySQL-Architekturen für die Notfallwiederherstellung behandelt.
Cluster-zu-Cluster-Replikation wurde in ClusterControl in Version 1.7.4 eingeführt. In diesem Blogbeitrag zeigen wir, wie einfach es ist, die Replikation zwischen zwei Galera-Clustern (PXC 8.0) einzurichten. Dann schauen wir uns den anspruchsvolleren Teil an:Behandeln von Fehlern sowohl auf Knoten- als auch auf Clusterebene mit Hilfe von ClusterControl; Failover- und Failback-Vorgänge sind entscheidend für die Wahrung der Datenintegrität im gesamten System.
Cluster-Bereitstellung
Für unser Beispiel benötigen wir mindestens zwei Cluster und zwei Standorte – einen für den primären und einen für den sekundären. Es funktioniert ähnlich wie die traditionelle MySQL-Master-Slave-Replikation, jedoch in einem größeren Maßstab mit drei Datenbankknoten an jedem Standort. Mit ClusterControl würden Sie dies erreichen, indem Sie einen primären Cluster bereitstellen, gefolgt von der Bereitstellung des sekundären Clusters am Disaster-Recovery-Standort als Replikat-Cluster, repliziert durch eine bidirektionale asynchrone Replikation.
Das folgende Diagramm veranschaulicht unsere endgültige Architektur:

Wir haben insgesamt sechs Datenbankknoten, drei am primären Standort und einen weiteren drei auf der Disaster-Recovery-Site. Um die Knotendarstellung zu vereinfachen, verwenden wir die folgenden Notationen:
-
Primärer Standort:
-
galera1-P - 192.168.11.171 (Master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Disaster-Recovery-Site:
-
galera1-DR - 192.168.11.181 (Slave)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Stellen Sie zuerst einfach den ersten Cluster bereit, und wir nennen ihn PXC-Primary. Öffnen Sie ClusterControl UI → Deploy → MySQL Galera und geben Sie alle erforderlichen Details ein:
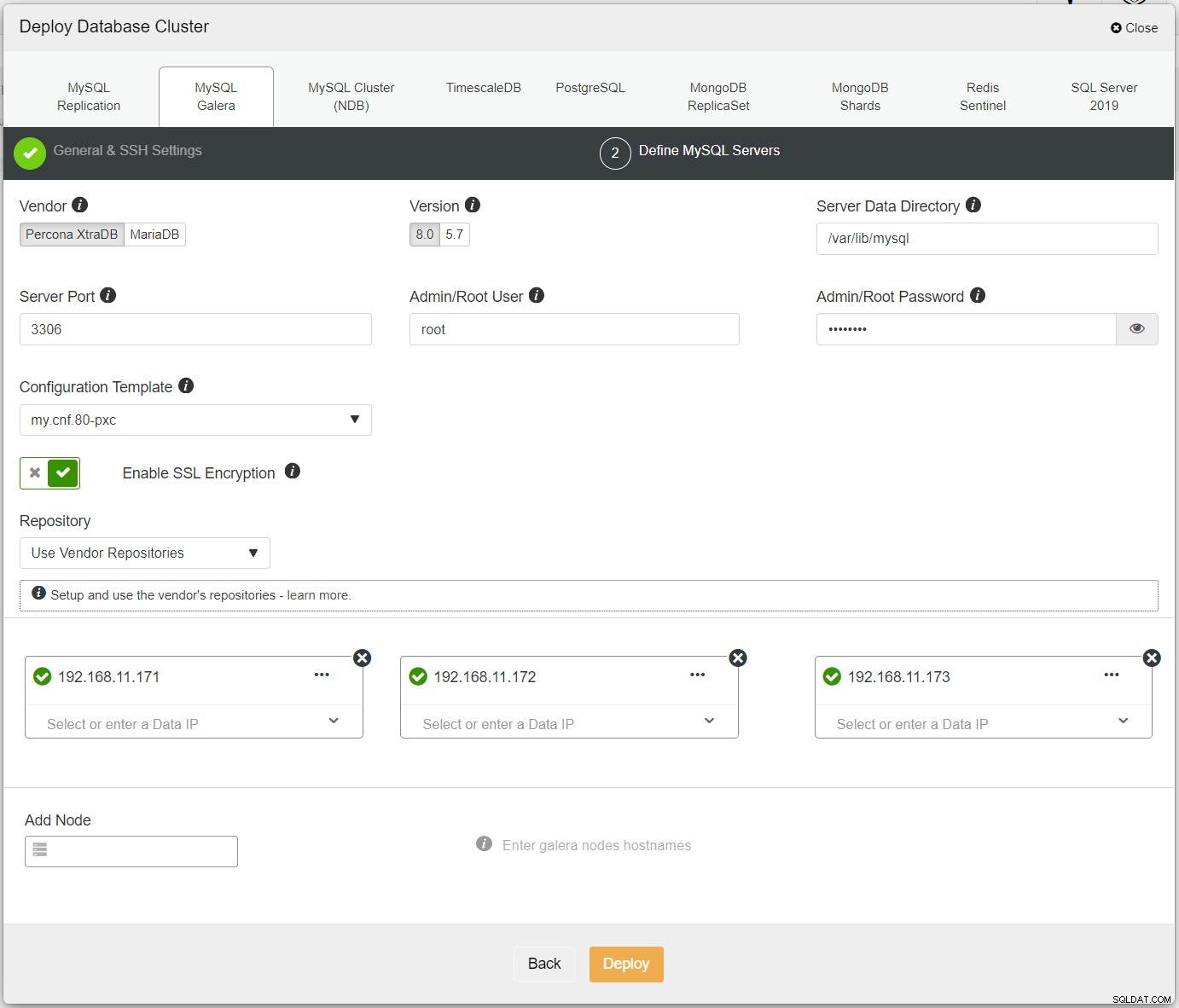
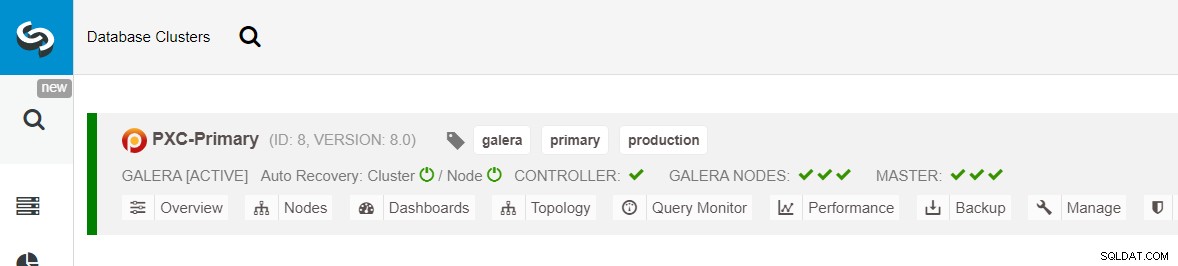
Stellen Sie sicher, dass neben jedem angegebenen Knoten ein grünes Häkchen angezeigt wird, das darauf hinweist, dass ClusterControl kann sich über passwortloses SSH mit dem Host verbinden. Klicken Sie auf Bereitstellen und warten Sie, bis die Bereitstellung abgeschlossen ist. Anschließend sollten Sie den folgenden Cluster auf der Cluster-Dashboard-Seite aufgelistet sehen:
Als Nächstes verwenden wir die ClusterControl-Funktion namens Create Replica Cluster, auf die über zugegriffen werden kann das Dropdown-Menü Cluster-Aktion:
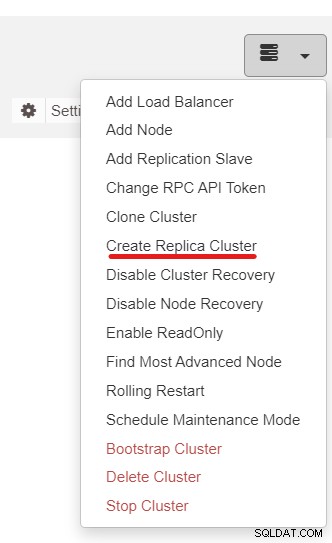
Das folgende Seitenleisten-Popup wird angezeigt:
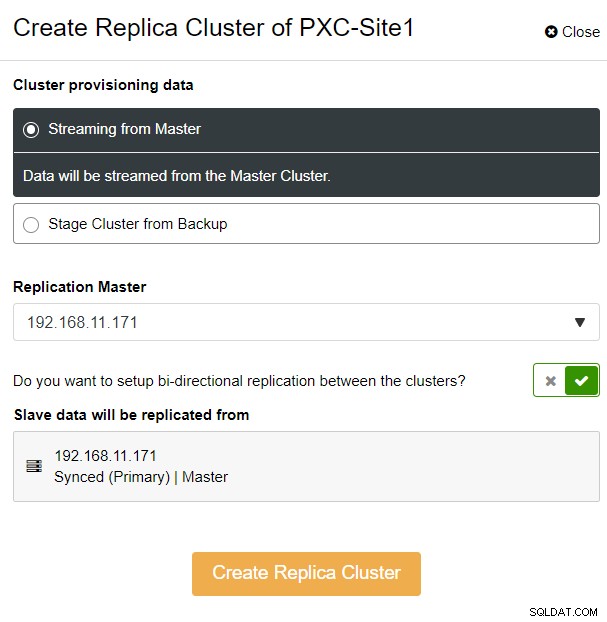
Wir haben die Option „Streaming from Master“ gewählt, wobei ClusterControl die ausgewählten Master, um den Replikat-Cluster zu synchronisieren und die Replikation zu konfigurieren. Achten Sie auf die bidirektionale Replikationsoption. Wenn aktiviert, richtet ClusterControl eine bidirektionale Replikation zwischen beiden Standorten ein (zirkuläre Replikation). Der ausgewählte Master repliziert vom ersten Master, der für den Replikat-Cluster definiert ist, und umgekehrt. Dieses Setup minimiert die Bereitstellungszeit, die bei der Wiederherstellung nach einem Failover oder Failback erforderlich ist. Klicken Sie auf „Create Replica Cluster“, wo ClusterControl einen neuen Bereitstellungsassistenten für den Replikat-Cluster öffnet, wie unten gezeigt:
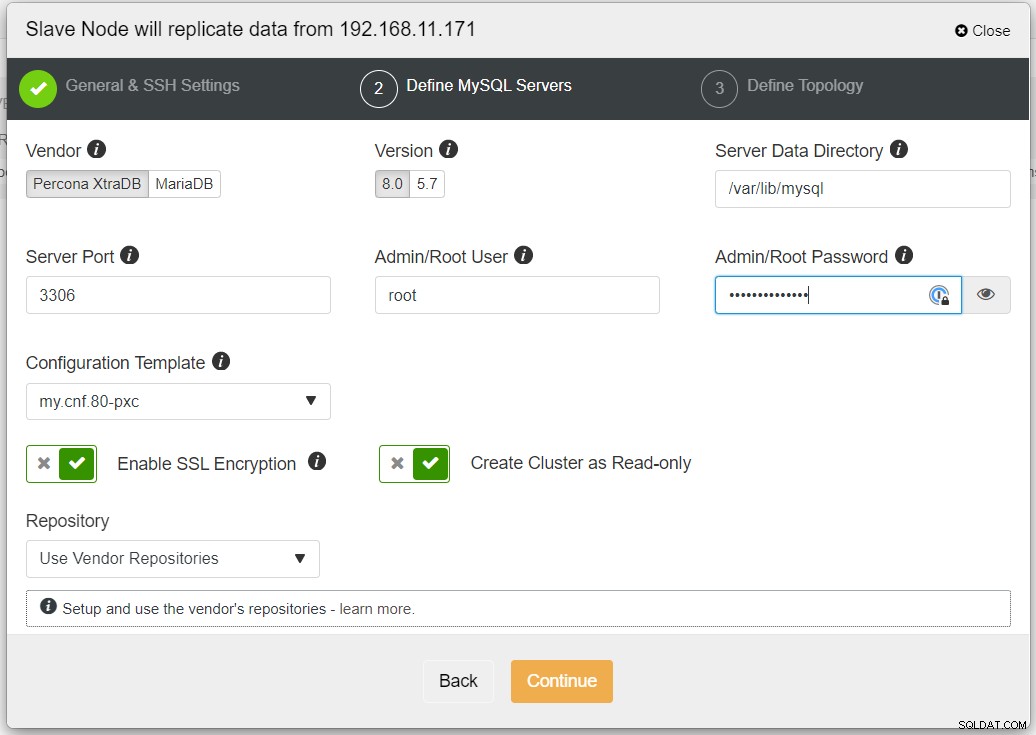
Es wird empfohlen, die SSL-Verschlüsselung zu aktivieren, wenn die Replikation nicht vertrauenswürdige Netzwerke wie WAN, nicht getunnelte Netzwerke oder das Internet. Stellen Sie außerdem sicher, dass „Cluster als schreibgeschützt erstellen“ aktiviert ist; Dies ist der Schutz vor versehentlichen Schreibvorgängen und ein guter Indikator, um leicht zwischen dem aktiven Cluster (Lese-Schreibzugriff) und dem passiven Cluster (Nur-Lesezugriff) zu unterscheiden.
Nachdem Sie alle erforderlichen Informationen ausgefüllt haben, sollten Sie die folgende Phase erreichen, um die Replica-Cluster-Topologie zu definieren:
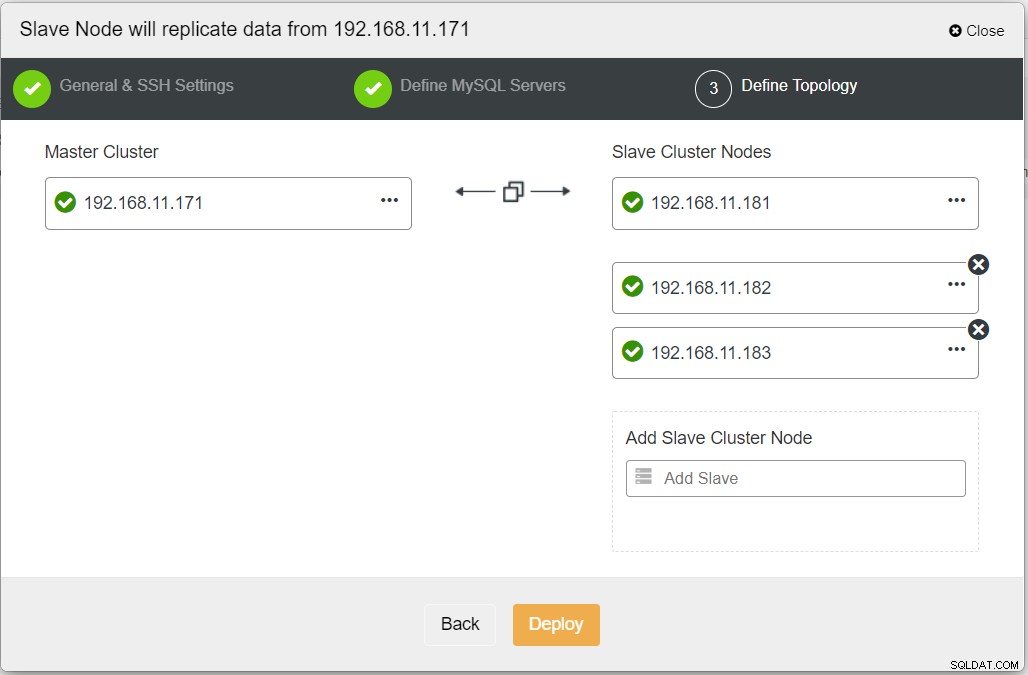
Wenn die Bereitstellung abgeschlossen ist, sollten Sie im ClusterControl-Dashboard die Datei „ Die DR-Site hat einen bidirektionalen Pfeil, der mit der primären Site verbunden ist:
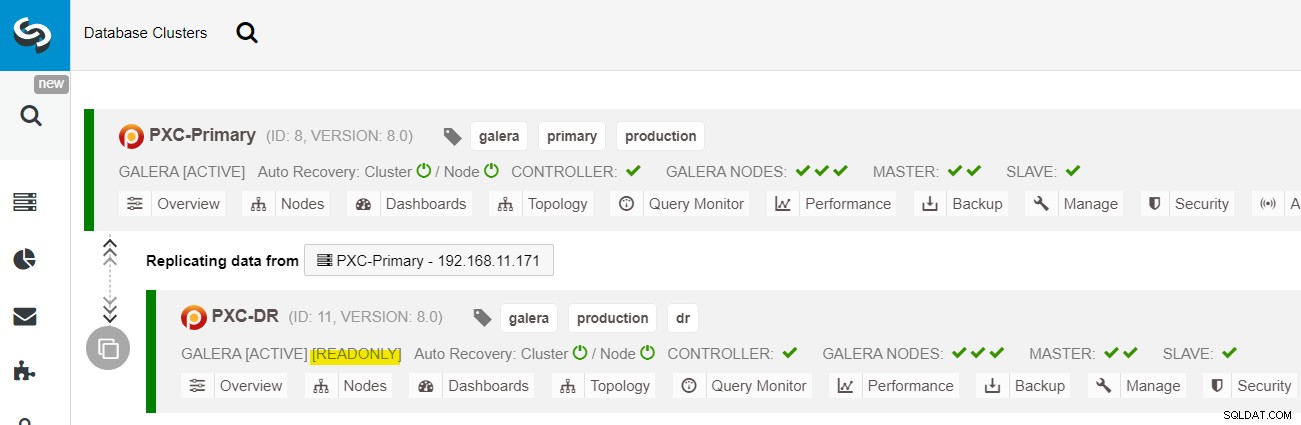
Die Bereitstellung ist jetzt abgeschlossen. Anwendungen sollten Schreibvorgänge nur an den primären Standort senden, da dies der aktive Standort ist und der DR-Standort für schreibgeschützt konfiguriert ist (gelb hervorgehoben). Lesevorgänge können an beide Standorte gesendet werden, obwohl der DR-Standort aufgrund der asynchronen Replikation möglicherweise hinterherhinkt. Durch dieses Setup werden der primäre Standort und der Standort für die Notfallwiederherstellung voneinander unabhängig und durch die asynchrone Replikation lose verbunden. Einer der Galera-Knoten am DR-Standort ist ein Slave, der von einem der Galera-Knoten (Master) am primären Standort repliziert.
Wir haben jetzt ein System, bei dem ein Cluster-Ausfall am primären Standort keinen Einfluss auf den Backup-Standort hat. In Bezug auf die Leistung wirkt sich die WAN-Latenz nicht auf Aktualisierungen im aktiven Cluster aus. Diese werden asynchron an die Backup-Site gesendet.
Als Nebenbemerkung ist es auch möglich, eine dedizierte Slave-Instanz als Replikationsrelais zu haben, anstatt einen der Galera-Knoten als Slave zu verwenden.
Galera-Knoten-Failover-Verfahren
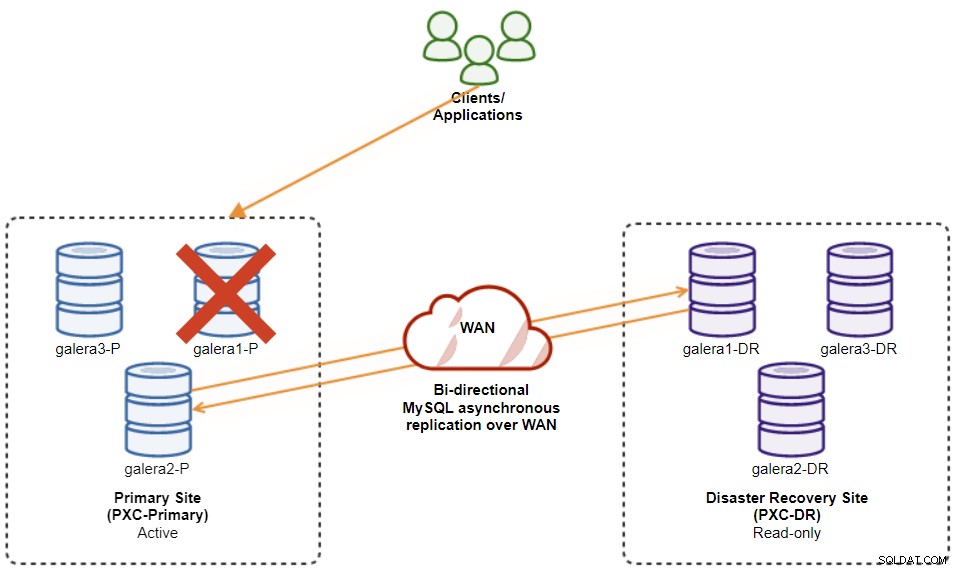
Falls der aktuelle Master (galera1-P) ausfällt und die verbleibenden Knoten am primären Standort noch aktiv sind, sollte der Slave am Disaster-Recovery-Standort (galera1-DR) an alle verfügbaren Master geleitet werden auf der primären Site, wie im folgenden Diagramm gezeigt:
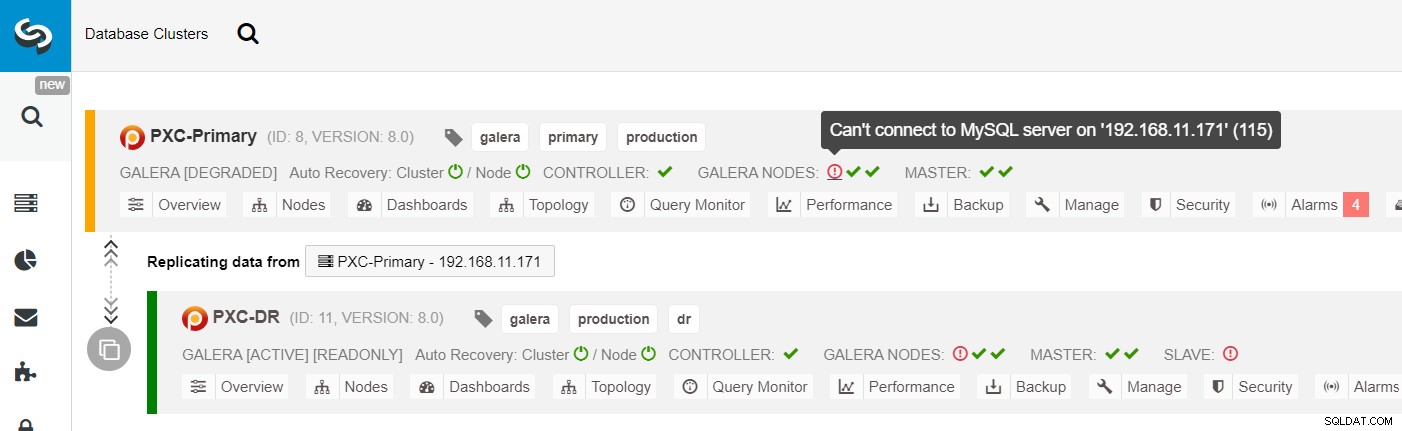
Aus der ClusterControl-Clusterliste können Sie sehen, dass der Clusterstatus heruntergestuft ist , und wenn Sie über das Ausrufezeichen-Symbol fahren, können Sie den Fehler für diesen bestimmten Knoten sehen (galera1-P):
Mit ClusterControl können Sie einfach zu PXC-DR-Cluster → Nodes → galera1-DR auswählen → Node Actions → Rebuild Replication Slave gehen, und Ihnen wird der folgende Konfigurationsdialog angezeigt:
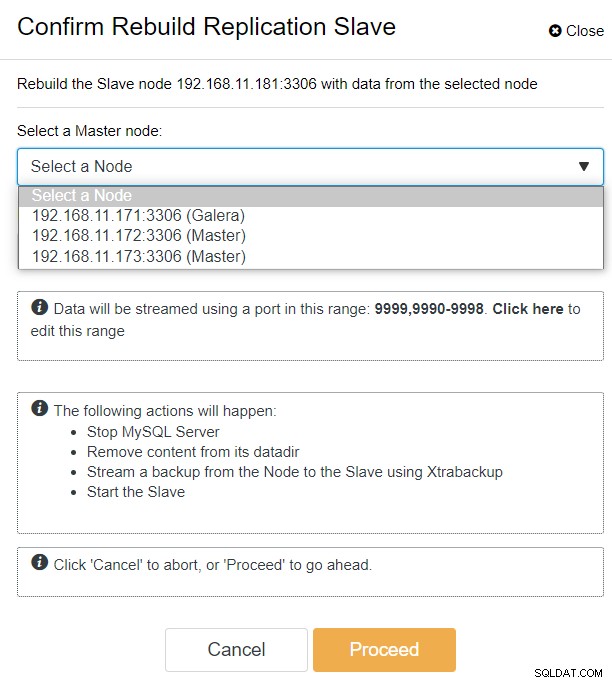
Wir können alle Galera-Knoten am Primärstandort (192.168.11.17x ) aus der Dropdown-Liste. Wählen Sie den sekundären Knoten 192.168.11.172 (galera2-P) aus und klicken Sie auf Fortfahren. ClusterControl konfiguriert dann die Replikationstopologie so, wie sie sein sollte, und richtet die bidirektionale Replikation von galera2-P nach galera1-DR ein. Sie können dies auf der Cluster-Dashboard-Seite (gelb hervorgehoben) bestätigen:
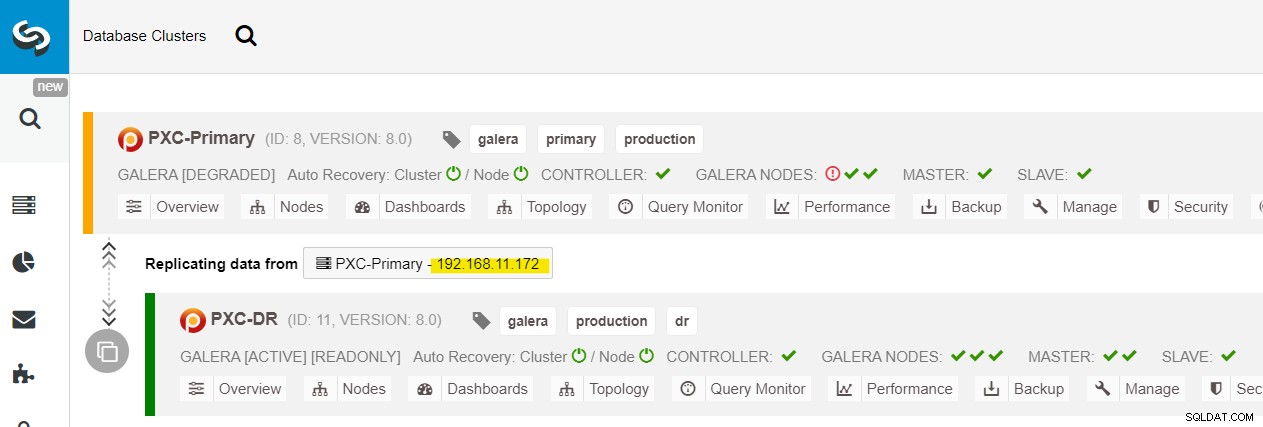
Zu diesem Zeitpunkt wird der primäre Cluster (PXC-Primary) noch bereitgestellt als aktives Cluster für diese Topologie. Es sollte sich nicht auf die Betriebszeit des Datenbankdienstes des primären Clusters auswirken.
Galera-Cluster-Failover-Verfahren
Falls der primäre Cluster ausfällt, abstürzt oder einfach die Konnektivität aus Sicht der Anwendung verliert, kann die Anwendung fast sofort an die DR-Site geleitet werden. Der SysAdmin muss lediglich den Schreibschutz auf allen Galera-Knoten auf der Disaster-Recovery-Site deaktivieren, indem er die folgende Anweisung verwendet:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRFür Benutzer von ClusterControl können Sie ClusterControl UI → Nodes → DB-Node auswählen → Node Actions → Disable Read-only verwenden. Die ClusterControl-Befehlszeilenschnittstelle ist ebenfalls verfügbar, indem Sie die folgenden Befehle auf dem ClusterControl-Knoten ausführen:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeDas Failover zum DR-Standort ist jetzt abgeschlossen und die Anwendungen können damit beginnen, Schreibvorgänge an den PXC-DR-Cluster zu senden. Auf der ClusterControl-Benutzeroberfläche sollten Sie etwa Folgendes sehen:
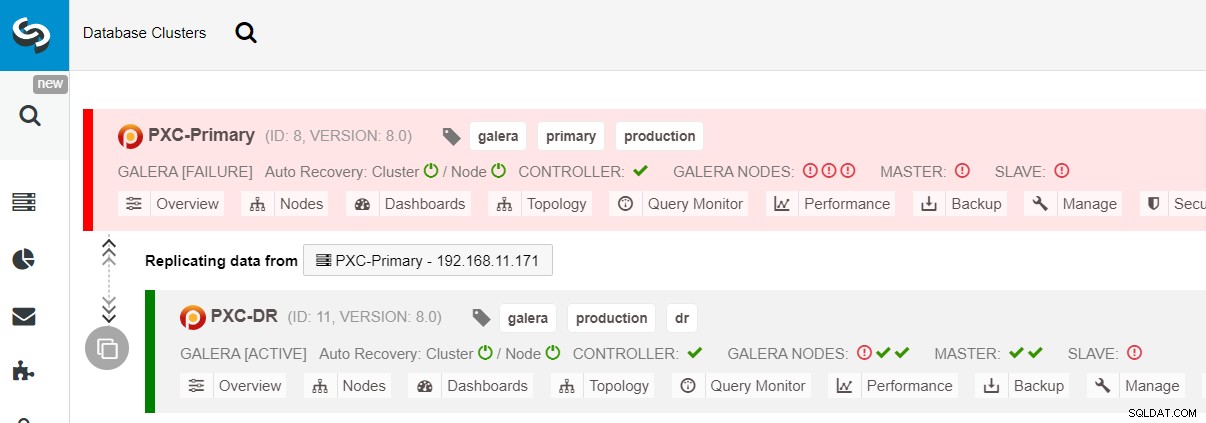
Das folgende Diagramm zeigt unsere Architektur nach dem Failover der Anwendung auf die DR-Site :
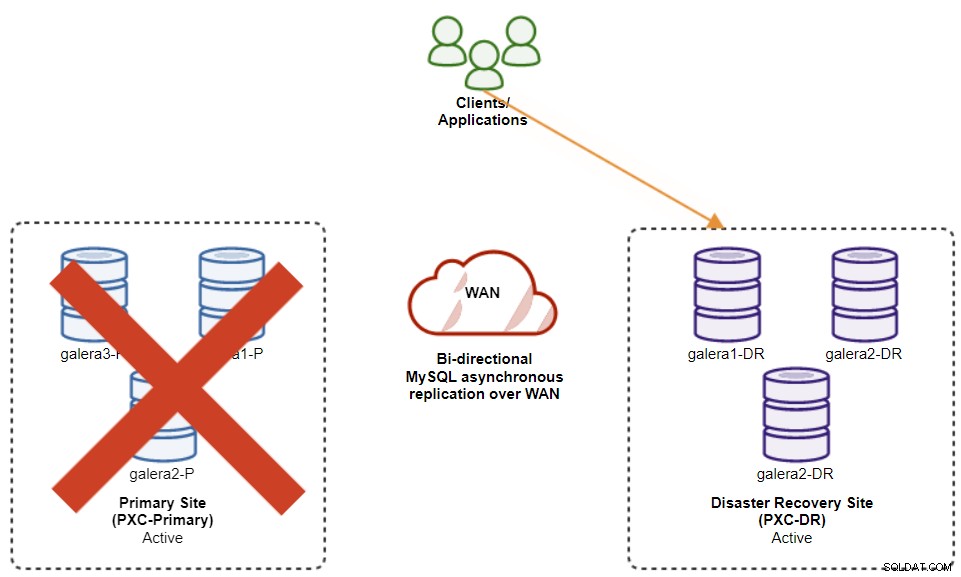
Angenommen, die primäre Site ist immer noch ausgefallen, gibt es zu diesem Zeitpunkt keine Replikation zwischen Standorten, bis der primäre Standort wieder verfügbar ist.
Galera-Cluster-Failback-Verfahren
Nachdem der primäre Standort aufgerufen wurde, ist es wichtig zu beachten, dass der primäre Cluster schreibgeschützt sein muss, damit wir wissen, dass der aktive Cluster derjenige am Standort für die Notfallwiederherstellung ist. Gehen Sie in ClusterControl zum Drop-down-Menü des Clusters und wählen Sie „Enable Read-only“ (Schreibgeschützt aktivieren), wodurch der Schreibschutz auf allen Knoten im primären Cluster aktiviert und die aktuelle Topologie wie folgt zusammengefasst wird:
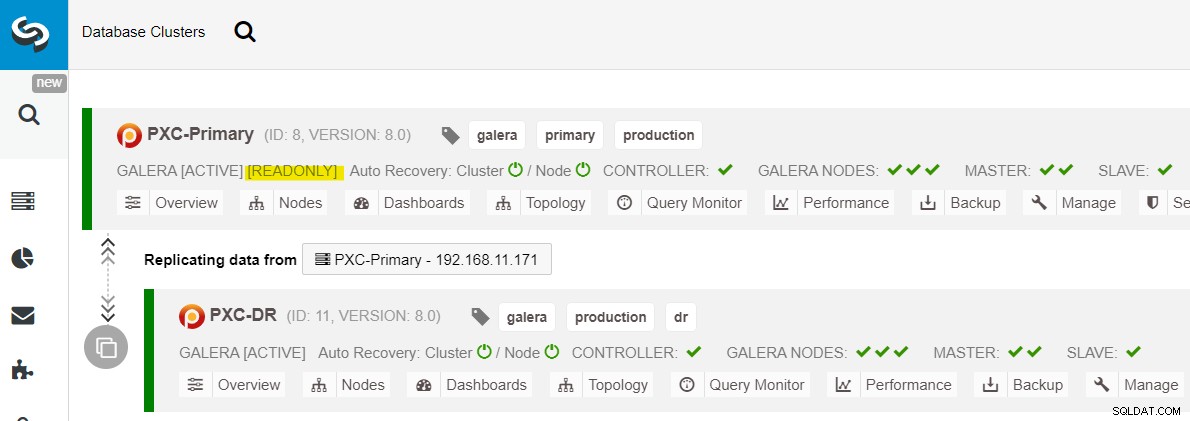
Stellen Sie sicher, dass alles grün ist, bevor Sie planen, das Cluster-Failback-Verfahren zu starten (grün bedeutet, dass alle Knoten aktiv und miteinander synchronisiert sind). Wenn sich beispielsweise ein Knoten in einem herabsetzenden Status befindet, der replizierende Knoten immer noch hinterherhinkt oder nur einige der Knoten im primären Cluster erreichbar waren, warten Sie, bis der Cluster vollständig wiederhergestellt ist, indem Sie entweder auf die automatischen Wiederherstellungsverfahren von ClusterControl warten zu vervollständigen oder manuell einzugreifen.
Zu diesem Zeitpunkt ist der aktive Cluster immer noch der Cluster des DR und der primäre Cluster fungiert als sekundärer Cluster. Das folgende Diagramm veranschaulicht die aktuelle Architektur:
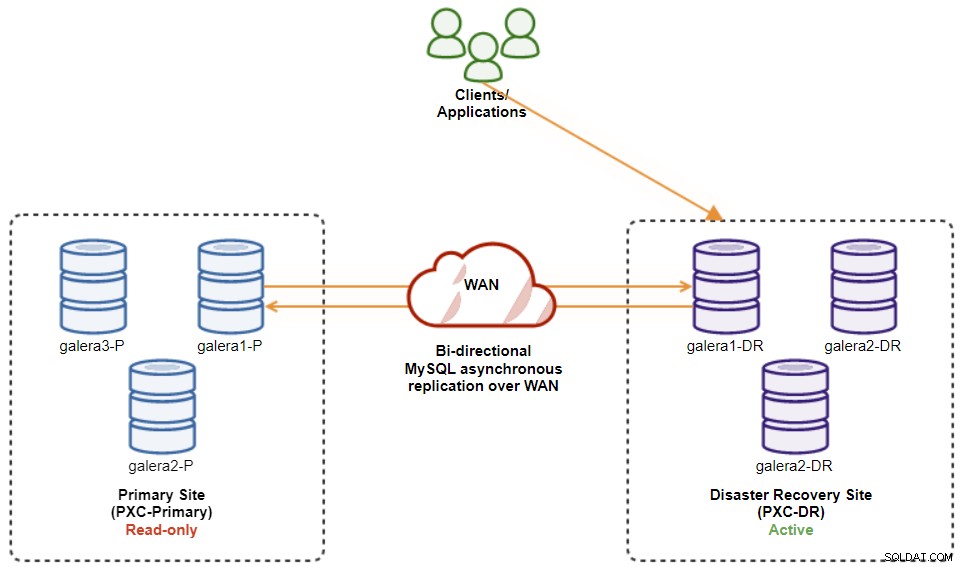
Die sicherste Methode für ein Failback zum primären Standort ist die Einstellung „schreibgeschützt“. auf dem Cluster des DR, gefolgt von der Deaktivierung des schreibgeschützten Zugriffs auf dem primären Standort. Gehen Sie zu ClusterControl UI → PXC-DR (Dropdown-Menü) → Schreibgeschützt aktivieren. Dadurch wird ein Job ausgelöst, um auf allen Knoten im DR-Cluster den Schreibschutz festzulegen. Gehen Sie dann zu ClusterControl UI → PXC-Primary → Nodes und deaktivieren Sie den Schreibschutz auf allen Datenbankknoten im primären Cluster.
Sie können die obigen Verfahren auch mit der ClusterControl CLI vereinfachen. Führen Sie alternativ die folgenden Befehle auf dem ClusterControl-Host aus:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeSobald dies erledigt ist, kehrt die Replikationsrichtung zu ihrer ursprünglichen Konfiguration zurück, wobei PXC-Primary der aktive Cluster und PXC-DR der Standby-Cluster ist. Das folgende Diagramm veranschaulicht die endgültige Architektur nach dem Cluster-Failback-Vorgang:
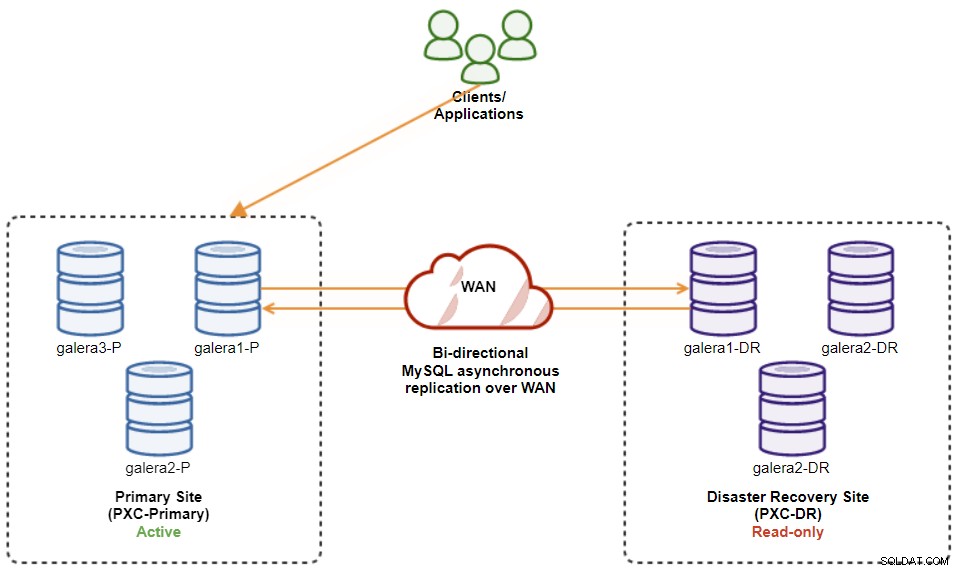
An diesem Punkt ist es jetzt sicher, die zu schreibenden Anwendungen umzuleiten der primäre Standort.
Vorteile der asynchronen Cluster-zu-Cluster-Replikation
Cluster-zu-Cluster mit asynchroner Replikation bietet eine Reihe von Vorteilen:
-
Minimale Ausfallzeit während eines Datenbank-Failover-Vorgangs. Grundsätzlich können Sie den Schreibvorgang fast sofort auf die Slave-Site umleiten, nur wenn Sie Schreibvorgänge so schützen können, dass sie die Master-Site nicht erreichen (da diese Schreibvorgänge nicht repliziert werden und wahrscheinlich bei einer erneuten Synchronisierung von der DR-Site überschrieben werden).
-
Keine Auswirkung auf die Leistung auf der primären Site, da sie unabhängig von der Backup-Site (DR) ist. Die Replikation vom Master zum Slave erfolgt asynchron. Die Master-Site generiert Binärprotokolle, die Slave-Site repliziert die Ereignisse und wendet die Ereignisse zu einem späteren Zeitpunkt an.
-
Disaster-Recovery-Sites können für andere Zwecke verwendet werden, z. B. Datenbanksicherung, Sicherung von Binärprotokollen und Berichterstellung, oder schwere analytische Abfragen (OLAP). Beide Sites können gleichzeitig verwendet werden, mit Ausnahme der Replikationsverzögerung und der Nur-Lese-Operationen auf der Slave-Seite.
-
Der DR-Cluster könnte möglicherweise auf kleineren Instanzen in einer öffentlichen Cloud-Umgebung ausgeführt werden, solange sie mithalten können mit dem primären Cluster. Sie können die Instanzen bei Bedarf aktualisieren. In bestimmten Szenarien können Sie dadurch einige Kosten sparen.
-
Sie benötigen nur einen zusätzlichen Standort für die Notfallwiederherstellung im Vergleich zum Aktiv-Aktiv-Replikations-Setup von Galera mit mehreren Standorten, das erfordert mindestens drei aktive Sites, um korrekt zu funktionieren.
Nachteile der asynchronen Cluster-zu-Cluster-Replikation
Dieses Setup hat auch Nachteile, je nachdem, ob Sie bidirektionale oder unidirektionale Replikation verwenden:
-
Es besteht die Möglichkeit, dass einige Daten während des Failovers fehlen, wenn der Slave im Rückstand war, da die Replikation asynchron ist. Dies könnte durch halbsynchrone und Multi-Threaded-Slave-Replikation verbessert werden, obwohl noch weitere Herausforderungen auf uns warten (Netzwerk-Overhead, Replikationslücke usw.).
-
Bei der unidirektionalen Replikation können die Failback-Verfahren schwierig und anfällig für Menschen sein, obwohl die Failover-Verfahren ziemlich einfach sind Error. Es erfordert einige Erfahrung beim Wechseln der Master/Slave-Rolle zurück zum primären Standort. Es wird empfohlen, die Verfahren zu dokumentieren, den Failover-/Failback-Vorgang regelmäßig zu proben und genaue Berichts- und Überwachungstools zu verwenden.
-
Es kann ziemlich kostspielig sein, da Sie eine ähnliche Anzahl von Knoten auf der Disaster-Recovery-Site einrichten müssen . Dies ist nicht schwarz auf weiß, da die Kostenbegründung in der Regel aus den Anforderungen Ihres Unternehmens stammt. Mit etwas Planung ist es möglich, die Nutzung der Datenbankressourcen an beiden Standorten unabhängig von den Datenbankrollen zu maximieren.
Abschluss
Das Einrichten einer asynchronen Replikation für Ihre MySQL Galera-Cluster kann ein relativ unkomplizierter Prozess sein – solange Sie verstehen, wie Sie mit Fehlern sowohl auf Knoten- als auch auf Clusterebene richtig umgehen. Letztendlich sind Failover- und Failback-Vorgänge entscheidend für die Gewährleistung der Datenintegrität.
Weitere Tipps zum Entwerfen Ihrer Galera-Cluster unter Berücksichtigung von Failover- und Failback-Strategien finden Sie in diesem Beitrag zu MySQL-Architekturen für die Notfallwiederherstellung. Wenn Sie Hilfe bei der Automatisierung dieser Vorgänge suchen, testen Sie ClusterControl 30 Tage lang kostenlos und befolgen Sie die Schritte in diesem Beitrag.
Vergessen Sie nicht, uns auf Twitter oder LinkedIn zu folgen und unseren Newsletter zu abonnieren, bleiben Sie über die neuesten Nachrichten und Best Practices für die Verwaltung Ihrer Open-Source-Datenbankinfrastrukturen auf dem Laufenden.