In diesem Blogbeitrag werden wir 6 verschiedene Fehlerszenarien in Produktionsdatenbanksystemen analysieren, die von Problemen mit einem einzelnen Server bis hin zu Failover-Plänen für mehrere Rechenzentren reichen. Wir führen Sie durch die Wiederherstellungs- und Failover-Verfahren für das jeweilige Szenario. Hoffentlich vermittelt Ihnen dies ein gutes Verständnis der Risiken, denen Sie möglicherweise ausgesetzt sind, und der Dinge, die Sie beim Entwerfen Ihrer Infrastruktur berücksichtigen sollten.
Datenbankschema beschädigt
Beginnen wir mit der Single-Node-Installation – einem Datenbank-Setup in der einfachsten Form. Einfach zu implementieren, zu den niedrigsten Kosten. In diesem Szenario führen Sie mehrere Anwendungen auf einem einzelnen Server aus, wobei jedes der Datenbankschemas zu einer anderen Anwendung gehört. Der Ansatz zur Wiederherstellung eines einzelnen Schemas würde von mehreren Faktoren abhängen.
- Habe ich ein Backup?
- Habe ich ein Backup und wie schnell kann ich es wiederherstellen?
- Welche Art von Speichermodul wird verwendet?
- Habe ich ein PITR-kompatibles Backup (Point-in-Time-Recovery)?
Datenkorruption kann durch mysqlcheck identifiziert werden.
mysqlcheck -uroot -p <DATABASE>Ersetzen Sie DATABASE durch den Namen der Datenbank und TABLE durch den Namen der Tabelle, die Sie überprüfen möchten:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck überprüft die angegebene Datenbank und Tabellen. Wenn eine Tabelle die Prüfung besteht, zeigt mysqlcheck OK für die Tabelle an. Im folgenden Beispiel können wir sehen, dass die Tabelle Gehälter Wiederherstellung erforderlich.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKBei einer Einzelknoteninstallation ohne zusätzliche DR-Server wäre der primäre Ansatz, Daten aus einer Sicherung wiederherzustellen. Aber das ist nicht das einzige, was Sie beachten müssen. Mehrere Datenbankschemata unter derselben Instanz verursachen ein Problem, wenn Sie Ihren Server herunterfahren müssen, um Daten wiederherzustellen. Eine andere Frage ist, ob Sie es sich leisten können, alle Ihre Datenbanken auf das letzte Backup zurückzusetzen. In den meisten Fällen wäre das nicht möglich.
Hier gibt es einige Ausnahmen. Es ist möglich, eine einzelne Tabelle oder Datenbank aus der letzten Sicherung wiederherzustellen, wenn keine Point-in-Time-Wiederherstellung erforderlich ist. Ein solcher Prozess ist komplizierter. Wenn Sie mysqldump haben, können Sie Ihre Datenbank daraus extrahieren. Wenn Sie binäre Backups mit xtradbackup oder mariabackup ausführen und Tabelle pro Datei aktiviert haben, ist dies möglich.
So prüfen Sie, ob Sie die Option „Tabelle pro Datei“ aktiviert haben.
mysql> SET GLOBAL innodb_file_per_table=1; Wenn innodb_file_per_table aktiviert ist, können Sie InnoDB-Tabellen in einer tbl_name .ibd-Datei speichern. Im Gegensatz zur MyISAM-Speicher-Engine mit ihren separaten tbl_name .MYD- und tbl_name .MYI-Dateien für Indizes und Daten speichert InnoDB die Daten und die Indizes zusammen in einer einzigen .ibd-Datei. Um Ihre Speicher-Engine zu überprüfen, müssen Sie Folgendes ausführen:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';oder direkt von der Konsole aus:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Um Tabellen aus xtradbackup wiederherzustellen, müssen Sie einen Exportprozess durchlaufen. Die Sicherung muss vorbereitet werden, bevor sie wiederhergestellt werden kann. Der Export erfolgt in der Vorbereitungsphase. Sobald eine vollständige Sicherung erstellt ist, führen Sie die Standardvorbereitungsprozedur mit dem zusätzlichen Flag --export :
ausinnobackupex --apply-log --export /u01/backupDadurch werden zusätzliche Exportdateien erstellt, die Sie später in der Importphase verwenden. Um eine Tabelle auf einen anderen Server zu importieren, erstellen Sie zunächst eine neue Tabelle mit derselben Struktur wie diejenige, die auf diesem Server importiert wird:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;Verwerfen Sie den Tablespace:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Kopieren Sie dann die Dateien mytable.ibd und mytable.exp in das Home der Datenbank und importieren Sie ihren Tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Um dies jedoch kontrollierter zu tun, wäre die Empfehlung, ein Datenbank-Backup auf einer anderen Instanz/einem anderen Server wiederherzustellen und das, was benötigt wird, zurück auf das Hauptsystem zu kopieren. Dazu müssen Sie die Installation der mysql-Instanz ausführen. Dies könnte entweder auf demselben Computer erfolgen - erfordert jedoch mehr Aufwand, um so zu konfigurieren, dass beide Instanzen auf demselben Computer ausgeführt werden können - dies würde beispielsweise unterschiedliche Kommunikationseinstellungen erfordern.
Mit ClusterControl können Sie sowohl die Aufgabenwiederherstellung als auch die Installation kombinieren.
ClusterControl führt Sie durch die verfügbaren Sicherungen vor Ort oder in der Cloud, lässt Sie den genauen Zeitpunkt für eine Wiederherstellung oder die genaue Protokollposition auswählen und installiert bei Bedarf eine neue Datenbankinstanz.
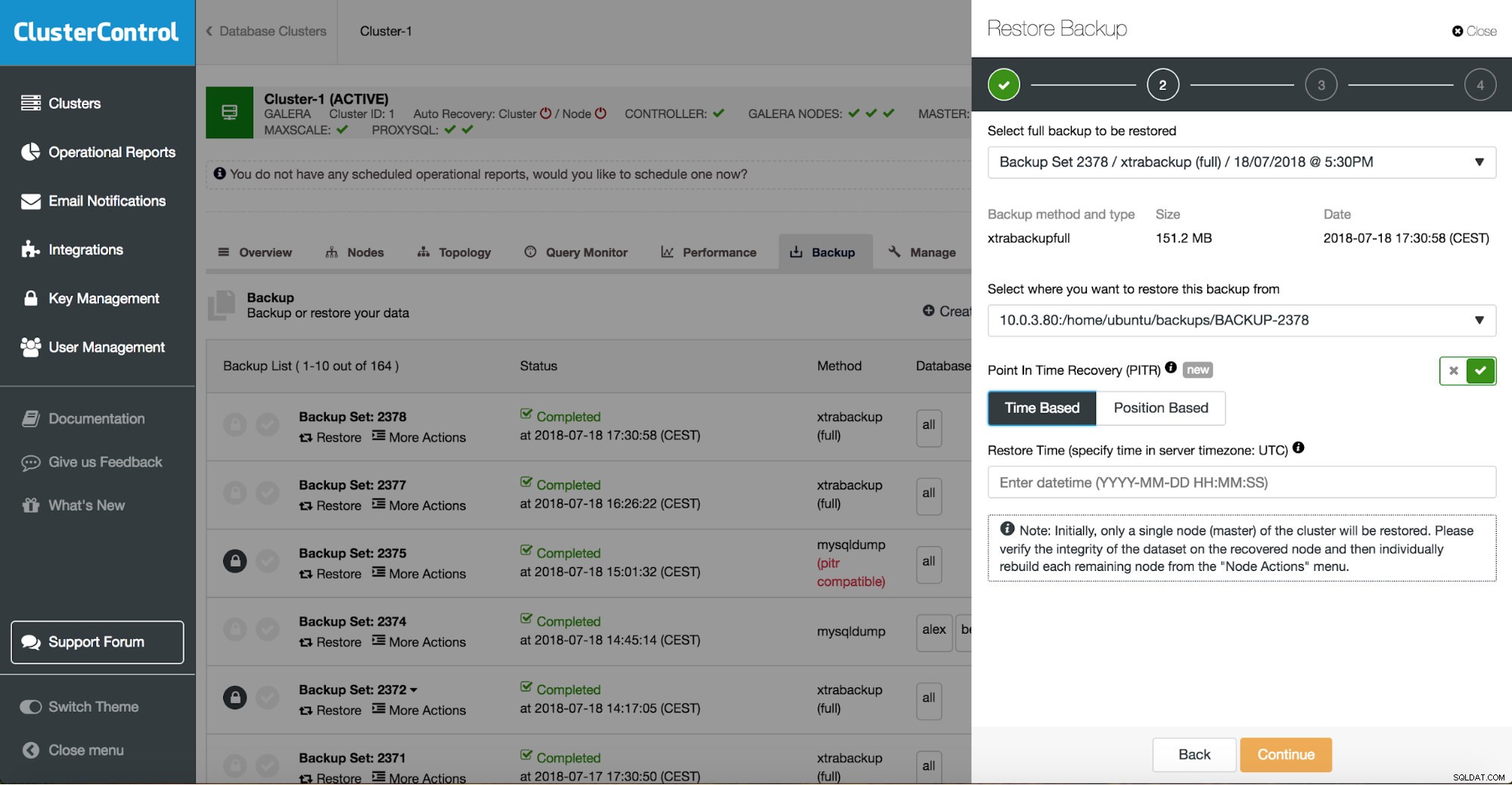 ClusterControl Point-in-Time-Wiederherstellung
ClusterControl Point-in-Time-Wiederherstellung 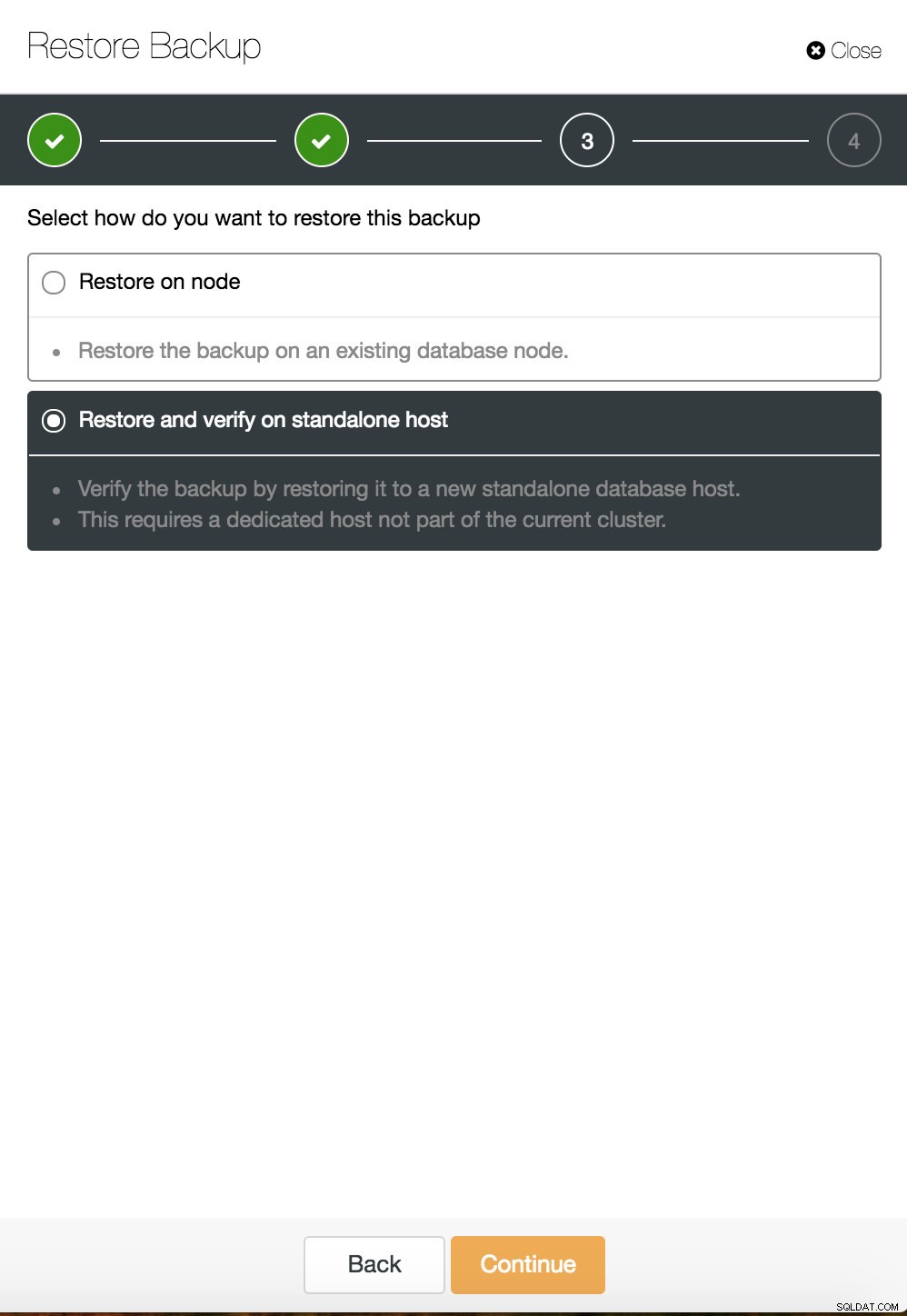 ClusterControl-Wiederherstellung und -Verifizierung auf einem eigenständigen Host
ClusterControl-Wiederherstellung und -Verifizierung auf einem eigenständigen Host 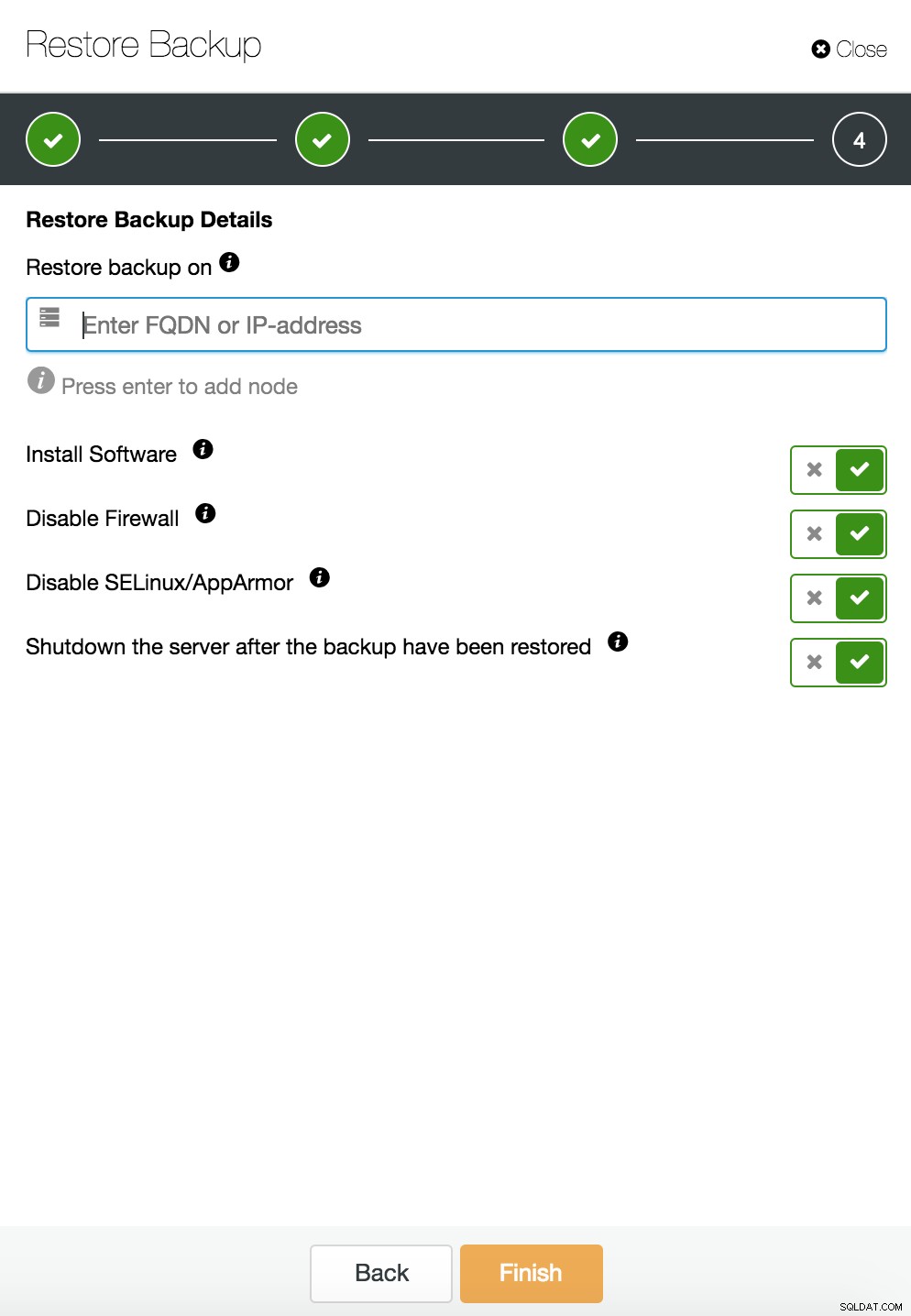 CusterControl-Wiederherstellung und -Verifizierung auf einem eigenständigen Host. Installationsoptionen.
CusterControl-Wiederherstellung und -Verifizierung auf einem eigenständigen Host. Installationsoptionen. Weitere Informationen zur Datenwiederherstellung finden Sie im Blog My MySQL Database is Corrupted... What Do I Do Now?
Datenbankinstanz auf dem dedizierten Server beschädigt
Fehler in der zugrunde liegenden Plattform sind häufig die Ursache für Datenbankbeschädigungen. Ihre MySQL-Instanz ist auf eine Reihe von Dingen angewiesen, um Daten zu speichern und abzurufen – Festplattensubsystem, Controller, Kommunikationskanäle, Treiber und Firmware. Ein Absturz kann Teile Ihrer Daten, MySQL-Binärdateien oder sogar Sicherungsdateien betreffen, die Sie auf dem System speichern. Um verschiedene Anwendungen zu trennen, können Sie sie auf dedizierten Servern platzieren.
Unterschiedliche Anwendungsschemata auf separaten Systemen sind eine gute Idee, wenn Sie sie sich leisten können. Man könnte sagen, dass dies eine Verschwendung von Ressourcen ist, aber es besteht die Möglichkeit, dass die geschäftlichen Auswirkungen geringer sind, wenn nur einer von ihnen ausfällt. Aber selbst dann müssen Sie Ihre Datenbank vor Datenverlust schützen. Das Speichern von Backups auf demselben Server ist keine schlechte Idee, solange Sie eine Kopie an einem anderen Ort haben. Heutzutage ist Cloud-Storage eine hervorragende Alternative zur Bandsicherung.
ClusterControl ermöglicht es Ihnen, eine Kopie Ihres Backups in der Cloud aufzubewahren. Es unterstützt das Hochladen zu den Top-3-Cloud-Anbietern – Amazon AWS, Google Cloud und Microsoft Azure.
Wenn Sie Ihr vollständiges Backup wiederhergestellt haben, möchten Sie es möglicherweise zu einem bestimmten Zeitpunkt wiederherstellen. Die Point-in-Time-Wiederherstellung bringt den Server auf einen neueren Zeitpunkt als zu dem Zeitpunkt, zu dem die vollständige Sicherung erstellt wurde. Dazu müssen Sie Ihre Binärprotokolle aktiviert haben. Sie können verfügbare Binärlogs überprüfen mit:
mysql> SHOW BINARY LOGS;Und aktuelle Protokolldatei mit:
SHOW MASTER STATUS;Dann können Sie inkrementelle Daten erfassen, indem Sie Binärprotokolle an die SQL-Datei übergeben. Fehlende Operationen können dann erneut ausgeführt werden.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outDasselbe kann in ClusterControl gemacht werden.
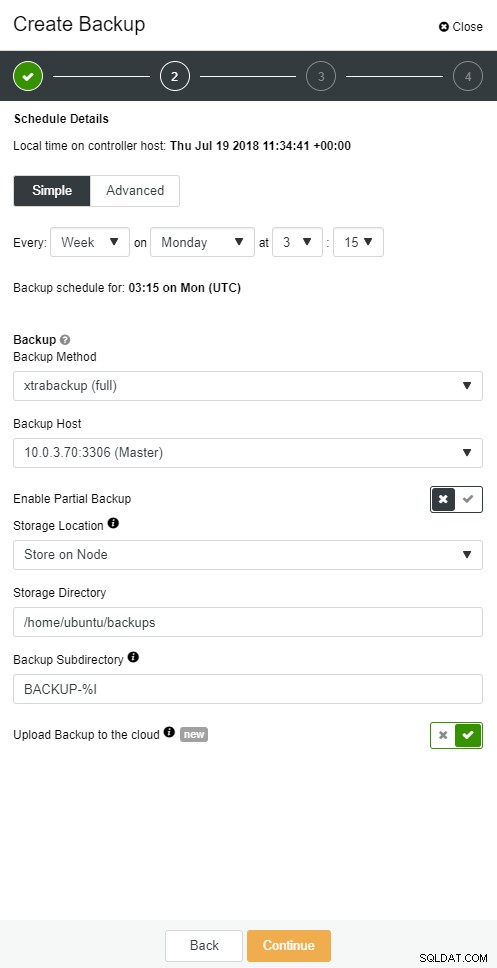 ClusterControl-Cloudsicherung
ClusterControl-Cloudsicherung 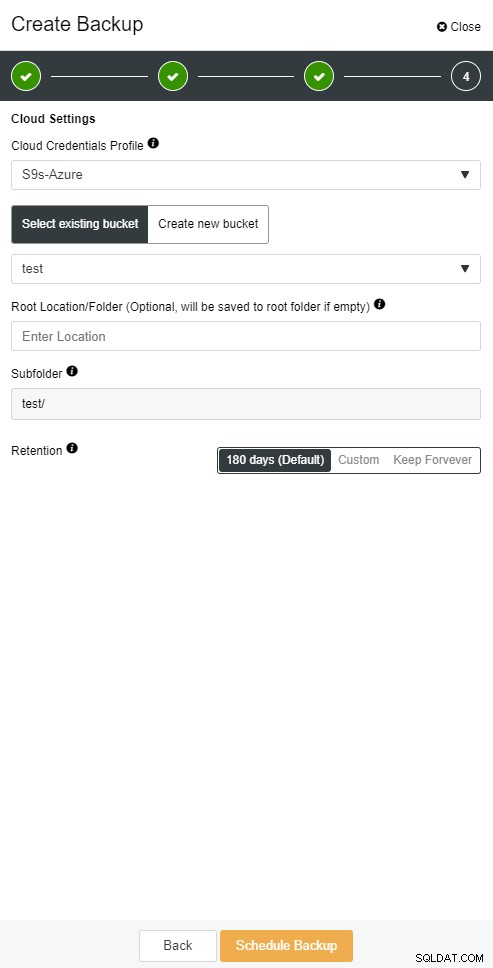 ClusterControl-Cloudsicherung
ClusterControl-Cloudsicherung Datenbank-Slave fällt aus
Ok, Sie haben also Ihre Datenbank auf einem dedizierten Server ausgeführt. Sie haben einen ausgeklügelten Backup-Zeitplan mit einer Kombination aus vollständigen und inkrementellen Backups erstellt, diese in die Cloud hochgeladen und das neueste Backup für eine schnelle Wiederherstellung auf lokalen Festplatten gespeichert. Sie haben unterschiedliche Backup-Aufbewahrungsrichtlinien – kürzer für Backups, die auf lokalen Festplattentreibern gespeichert sind, und erweitert für Ihre Cloud-Backups.
Es klingt, als wären Sie gut auf ein Katastrophenszenario vorbereitet. Aber wenn es um die Wiederherstellungszeit geht, erfüllt sie möglicherweise nicht Ihre geschäftlichen Anforderungen.
Sie benötigen eine schnelle Failover-Funktion. Ein Server, der betriebsbereit ist und Binärprotokolle vom Master anwendet, auf dem Schreibvorgänge stattfinden. Die Master/Slave-Replikation beginnt ein neues Kapitel im Failover-Szenario. Es ist eine schnelle Methode, um Ihre Anwendung wieder zum Leben zu erwecken, wenn Ihr Master ausfällt.
Im Failover-Szenario sind jedoch einige Dinge zu beachten. Eine besteht darin, einen Slave mit verzögerter Replikation einzurichten, damit Sie auf Fat-Finger-Befehle reagieren können, die auf dem Master-Server ausgelöst wurden. Ein Slave-Server kann dem Master um mindestens eine bestimmte Zeitspanne hinterherhinken. Die Standardverzögerung beträgt 0 Sekunden. Verwenden Sie die Option MASTER_DELAY für CHANGE MASTER TO, um die Verzögerung auf N Sekunden einzustellen:
CHANGE MASTER TO MASTER_DELAY = N;Zweitens müssen Sie das automatische Failover aktivieren. Es gibt viele automatisierte Failover-Lösungen auf dem Markt. Sie können automatisches Failover mit Befehlszeilentools wie MHA, MRM, mysqlfailover oder GUI Orchestrator und ClusterControl einrichten. Wenn es richtig eingerichtet ist, kann es Ihre Ausfallzeiten erheblich reduzieren.
ClusterControl unterstützt automatisiertes Failover für MySQL-, PostgreSQL- und MongoDB-Replikationen sowie Multi-Master-Cluster-Lösungen Galera und NDB.
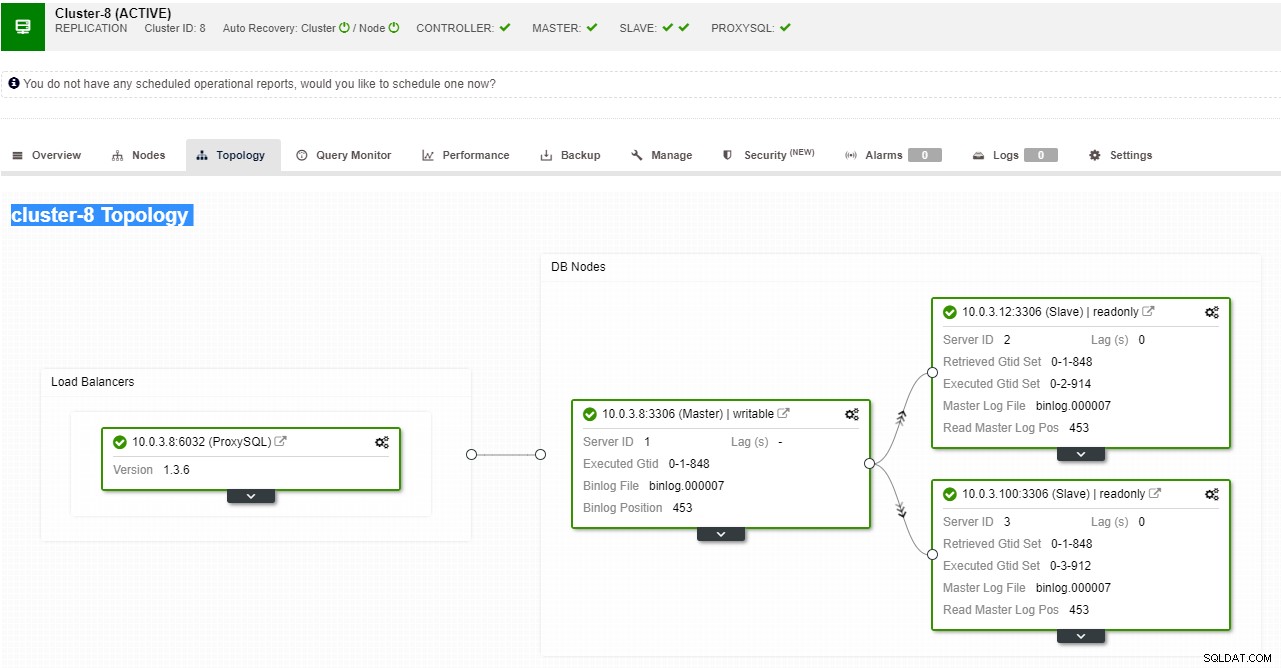 ClusterControl-Replikationstopologieansicht
ClusterControl-Replikationstopologieansicht Wenn ein Slave-Knoten abstürzt und der Server stark hinterherhinkt, möchten Sie möglicherweise Ihren Slave-Server neu erstellen. Der Slave-Wiederherstellungsprozess ähnelt der Wiederherstellung aus einer Sicherung.
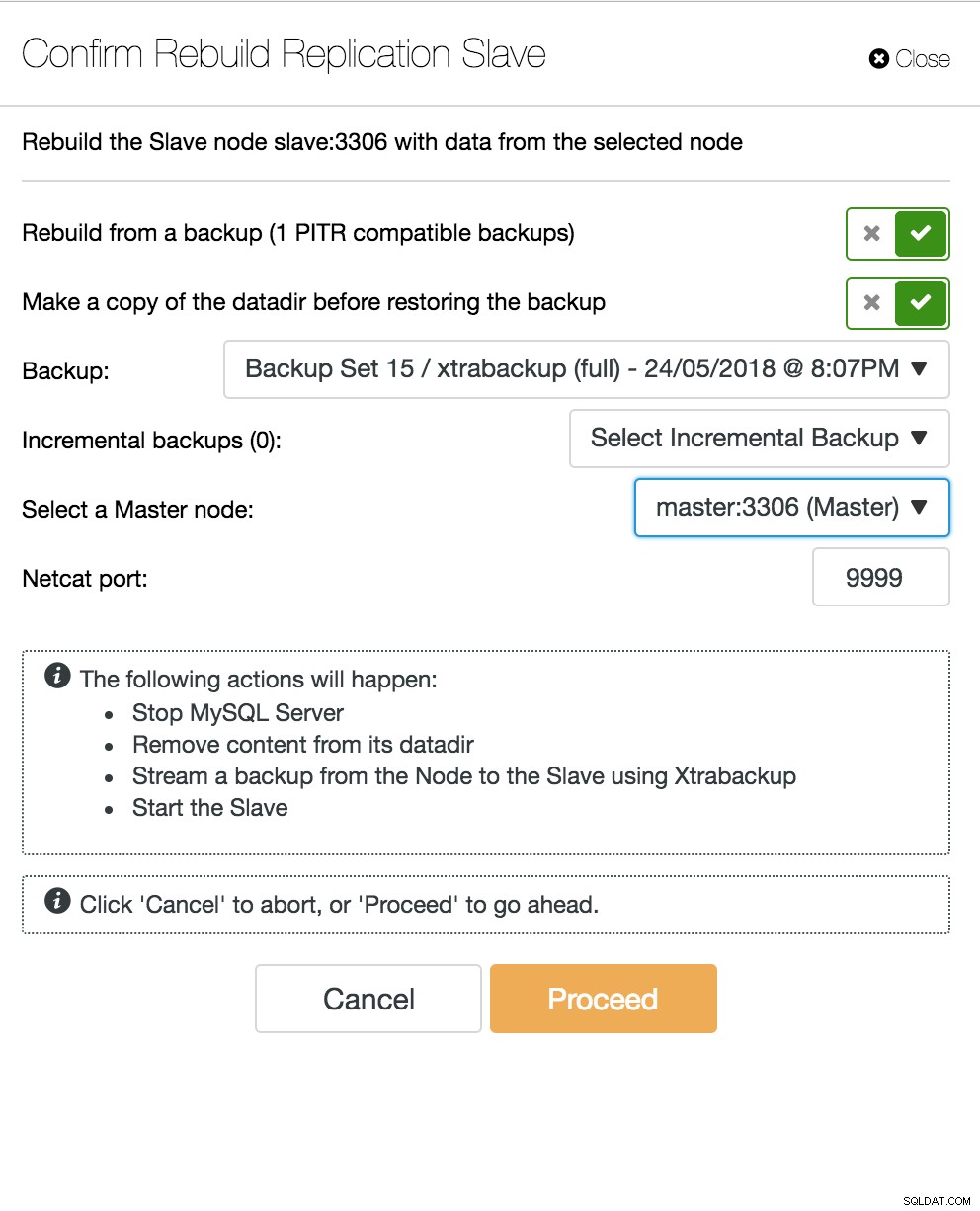 ClusterControl-Neuaufbau-Slave
ClusterControl-Neuaufbau-Slave Datenbank-Multi-Master-Server fällt aus
Wenn Sie jetzt einen Slave-Server haben, der als DR-Knoten fungiert, und Ihr Failover-Prozess gut automatisiert und getestet ist, wird Ihr DBA-Leben bequemer. Das stimmt, aber es gibt noch ein paar Rätsel zu lösen. Rechenleistung ist nicht kostenlos, und Ihr Geschäftsteam bittet Sie möglicherweise, Ihre Hardware besser zu nutzen, Sie möchten Ihren Slave-Server möglicherweise nicht nur als passiven Server verwenden, sondern auch für Schreibvorgänge.
Sie können dann eine Multi-Master-Replikationslösung untersuchen. Galera Cluster ist zu einer Mainstream-Option für hochverfügbares MySQL und MariaDB geworden. Und obwohl es jetzt als glaubwürdiger Ersatz für traditionelle MySQL-Master-Slave-Architekturen bekannt ist, ist es kein Drop-in-Ersatz.
Der Galera-Cluster hat eine Shared-Nothing-Architektur. Anstelle gemeinsam genutzter Festplatten verwendet Galera eine zertifizierungsbasierte Replikation mit Gruppenkommunikation und Transaktionsreihenfolge, um eine synchrone Replikation zu erreichen. Ein Datenbank-Cluster sollte in der Lage sein, den Verlust eines Knotens zu überstehen, obwohl dies auf unterschiedliche Weise erreicht wird. Im Fall von Galera ist der entscheidende Aspekt die Anzahl der Knoten. Galera benötigt ein Quorum, um betriebsfähig zu bleiben. Ein Cluster mit drei Knoten kann den Absturz eines Knotens überleben. Mit mehr Knoten in Ihrem Cluster können Sie mehr Ausfälle überstehen.
Der Wiederherstellungsprozess ist automatisiert, sodass Sie keine Failover-Vorgänge durchführen müssen. Die gute Praxis wäre jedoch, Knoten zu töten und zu sehen, wie schnell Sie sie zurückbringen können. Um diesen Vorgang effizienter zu gestalten, können Sie die Galera-Cache-Größe ändern. Wenn die Größe des Galera-Cache nicht richtig geplant ist, muss Ihr nächster bootender Knoten ein vollständiges Backup erstellen, anstatt nur Schreibsätze im Cache zu vermissen.
Das Failover-Szenario ist einfach wie das Starten der Instanz. Basierend auf den Daten im Galera-Cache führt der Boot-Knoten SST (Wiederherstellung aus vollständiger Sicherung) oder IST (Fehlende Schreibsätze anwenden) durch. Dies ist jedoch häufig mit menschlichem Eingreifen verbunden. Wenn Sie den gesamten Failover-Prozess automatisieren möchten, können Sie die automatische Wiederherstellungsfunktion von ClusterControl (Knoten- und Clusterebene) verwenden.
 ClusterControl-Cluster-Autowiederherstellung
ClusterControl-Cluster-Autowiederherstellung Geschätzte Galera-Cache-Größe:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Um das Failover konsistenter zu machen, sollten Sie gcache.recover=yes in mycnf aktivieren. Diese Option wird den Galera-Cache beim Neustart wiederbeleben. Dies bedeutet, dass der Knoten als GEBER agieren und fehlende Write-Sets bedienen kann (was IST erleichtert, anstatt SST zu verwenden).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Proxy-SQL-Knoten fällt aus
Wenn Sie ein virtuelles IP-Setup haben, müssen Sie Ihre Anwendung nur auf die virtuelle IP-Adresse verweisen, und alles sollte verbindungstechnisch korrekt sein. Es reicht nicht aus, dass sich Ihre Datenbankinstanzen über mehrere Rechenzentren erstrecken, Sie benötigen immer noch Ihre Anwendungen, um darauf zuzugreifen. Angenommen, Sie haben die Anzahl der Lesereplikate hochskaliert, möchten Sie möglicherweise aus Wartungs- oder Verfügbarkeitsgründen auch virtuelle IPs für jedes dieser Lesereplikate implementieren. Es kann zu einem umständlichen Pool virtueller IPs werden, die Sie verwalten müssen. Wenn eines dieser Lesereplikate abstürzt, müssen Sie die virtuelle IP dem anderen Host neu zuweisen, sonst verbindet sich Ihre Anwendung entweder mit einem ausgefallenen Host oder im schlimmsten Fall mit einem verzögerten Server mit veralteten Daten.
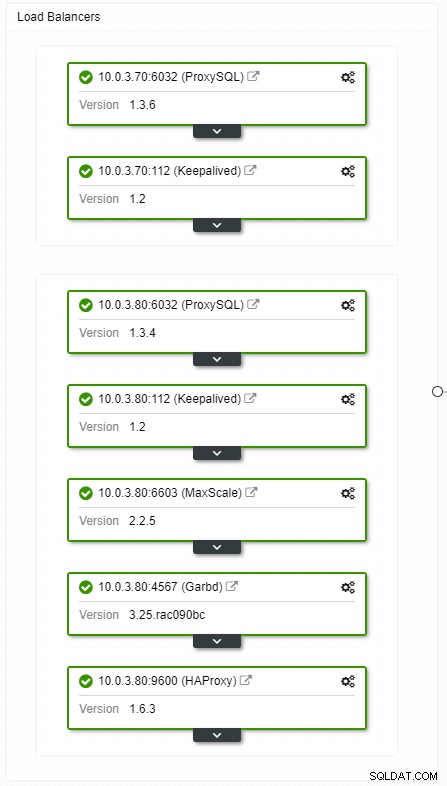 ClusterControl HA-Load-Balancer-Topologieansicht
ClusterControl HA-Load-Balancer-Topologieansicht Abstürze sind nicht häufig, aber wahrscheinlicher als Serverausfälle. Wenn aus irgendeinem Grund ein Slave ausfällt, leitet etwas wie ProxySQL den gesamten Datenverkehr an den Master um, mit dem Risiko, dass er überlastet wird. Wenn sich der Slave erholt, wird der Datenverkehr an ihn zurückgeleitet. Normalerweise sollte eine solche Ausfallzeit nicht länger als ein paar Minuten dauern, sodass der Gesamtschweregrad mittel ist, obwohl die Wahrscheinlichkeit ebenfalls mittel ist.
Um Ihre Load-Balancer-Komponenten redundant zu machen, können Sie keepalived verwenden.
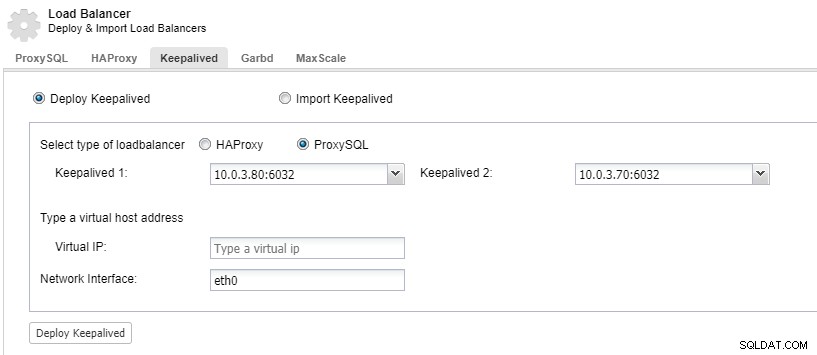 ClusterControl:Keepalived für ProxySQL-Load-Balancer bereitstellen
ClusterControl:Keepalived für ProxySQL-Load-Balancer bereitstellen Rechenzentrum fällt aus
Das Hauptproblem bei der Replikation besteht darin, dass es keinen Mehrheitsmechanismus gibt, um einen Rechenzentrumsausfall zu erkennen und einen neuen Master zu bedienen. Eine der Auflösungen ist die Verwendung von Orchestrator/Raft. Orchestrator ist ein Topologie-Supervisor, der Failover steuern kann. Bei Verwendung zusammen mit Raft wird Orchestrator Quorum-fähig. Eine der Orchestrator-Instanzen wird als Leader gewählt und führt Wiederherstellungsaufgaben aus. Die Verbindung zwischen Orchestrator-Knoten korreliert nicht mit transaktionalen Datenbank-Commits und ist spärlich.
Orchestrator/Raft kann zusätzliche Instanzen verwenden, die die Überwachung der Topologie durchführen. Im Fall der Netzwerkpartitionierung werden die partitionierten Orchestrator-Instanzen keine Maßnahmen ergreifen. Der Teil des Orchestrator-Clusters, der über das Quorum verfügt, wählt einen neuen Master und nimmt die erforderlichen Topologieänderungen vor.
ClusterControl wird für die Verwaltung, Skalierung und, was am wichtigsten ist, die Knotenwiederherstellung verwendet – Orchestrator würde Failover handhaben, aber wenn ein Slave abstürzen würde, stellt ClusterControl sicher, dass er wiederhergestellt wird. Orchestrator und ClusterControl befinden sich in derselben Verfügbarkeitszone, getrennt von den MySQL-Knoten, um sicherzustellen, dass ihre Aktivität nicht durch Netzwerkaufteilungen zwischen Verfügbarkeitszonen im Rechenzentrum beeinträchtigt wird.