Die Zeiten, in denen eine Datenbank als einzelner Knoten oder Instanz bereitgestellt wurde, sind lange vorbei – ein leistungsstarker, eigenständiger Server, der die Aufgabe hatte, alle Anfragen an die Datenbank zu verarbeiten. Vertikale Skalierung war der richtige Weg – ersetzen Sie den Server durch einen anderen, noch leistungsfähigeren. In diesen Zeiten musste man sich nicht wirklich um die Netzwerkleistung kümmern. Solange die Anfragen eingingen, war alles gut.
Heutzutage werden Datenbanken jedoch als Cluster mit Knoten aufgebaut, die über ein Netzwerk miteinander verbunden sind. Es ist nicht immer ein schnelles, lokales Netzwerk. Da Unternehmen eine globale Reichweite erreichen, muss sich auch die Datenbankinfrastruktur über den ganzen Globus erstrecken, um nah am Kunden zu bleiben und Latenzzeiten zu reduzieren. Dies bringt zusätzliche Herausforderungen mit sich, denen wir uns beim Entwurf einer hochverfügbaren Datenbankumgebung stellen müssen. In diesem Blog-Beitrag werden wir uns die Netzwerkprobleme ansehen, mit denen Sie möglicherweise konfrontiert sind, und einige Vorschläge machen, wie Sie damit umgehen können.
Zwei Hauptoptionen für MySQL oder MariaDB HA
Wir haben dieses spezielle Thema in einem der Whitepaper ziemlich ausführlich behandelt, aber schauen wir uns die beiden Hauptmethoden zum Aufbau von Hochverfügbarkeit für MySQL und MariaDB an.
Galera-Cluster
Galera Cluster ist eine Shared-Nothing, praktisch synchrone Cluster-Technologie für MySQL. Es ermöglicht den Aufbau von Multi-Writer-Setups, die sich über die ganze Welt erstrecken können. Galera gedeiht in Umgebungen mit geringer Latenz, kann aber auch so konfiguriert werden, dass es mit langen WAN-Verbindungen funktioniert. Galera verfügt über einen eingebauten Quorum-Mechanismus, der sicherstellt, dass Daten im Falle der Netzwerkpartitionierung einiger Knoten nicht gefährdet werden.
MySQL-Replikation
Die MySQL-Replikation kann entweder asynchron oder halbsynchron sein. Beide sind darauf ausgelegt, große Replikationscluster zu erstellen. Wie bei jedem anderen Master-Slave- oder Primär-Sekundär-Replikationssetup kann es nur einen Writer geben, den Master. Andere Knoten, Slaves, werden für Failover-Zwecke verwendet, da sie die Kopie des Datensatzes vom Maser enthalten. Slaves können auch zum Lesen der Daten und zum Abladen eines Teils der Arbeitslast vom Master verwendet werden.
Beide Lösungen haben ihre eigenen Grenzen und Merkmale, beide leiden unter unterschiedlichen Problemen. Beide können durch instabile Netzwerkverbindungen beeinträchtigt werden. Werfen wir einen Blick auf diese Einschränkungen und wie wir die Umgebung gestalten können, um die Auswirkungen einer instabilen Netzwerkinfrastruktur zu minimieren.
Galera-Cluster - Netzwerkprobleme
Werfen wir zunächst einen Blick auf Galera Cluster. Wie wir besprochen haben, funktioniert es am besten in einer Umgebung mit geringer Latenz. Eines der größten latenzbezogenen Probleme in Galera ist die Art und Weise, wie Galera mit den Schreibvorgängen umgeht. Wir werden in diesem Blog nicht auf alle Details eingehen, aber in unserem Galera Cluster for MySQL Tutorial weiterlesen. Das Fazit ist, dass aufgrund des Zertifizierungsprozesses für Schreibvorgänge, bei dem sich alle Knoten im Cluster darauf einigen müssen, ob der Schreibvorgang angewendet werden kann oder nicht, Ihre Schreibleistung für einzelne Zeilen streng durch die Netzwerk-Roundtrip-Zeit zwischen den Schreibern begrenzt ist Knoten und dem am weitesten entfernten Knoten. Solange die Latenz akzeptabel ist und Sie nicht zu viele Hotspots in Ihren Daten haben, können WAN-Setups problemlos funktionieren. Das Problem beginnt, wenn die Netzwerklatenz von Zeit zu Zeit ansteigt. Schreibvorgänge dauern dann 3- oder 4-mal länger als üblich, und infolgedessen können Datenbanken mit lang andauernden Schreibvorgängen überlastet werden.
Eines der großartigen Merkmale von Galera Cluster ist seine Fähigkeit, den Cluster-Status zu erkennen und auf die Netzwerkpartitionierung zu reagieren. Wenn ein Knoten des Clusters nicht erreicht werden kann, wird er aus dem Cluster entfernt und kann keine Schreibvorgänge ausführen. Dies ist entscheidend, um die Integrität der Daten während der Zeit aufrechtzuerhalten, in der der Cluster geteilt wird – nur der Großteil des Clusters akzeptiert Schreibvorgänge. Minderheit wird sich beschweren. Um dies zu bewältigen, führt Galera eine Vielzahl von Überprüfungen und konfigurierbaren Zeitüberschreitungen ein, um Fehlalarme bei sehr vorübergehenden Netzwerkproblemen zu vermeiden. Wenn das Netzwerk unzuverlässig ist, kann der Galera-Cluster leider nicht richtig funktionieren - die Knoten beginnen, den Cluster zu verlassen und ihm später beizutreten. Dies wird besonders problematisch, wenn sich Galera-Cluster über das WAN erstrecken – getrennte Teile des Clusters können zufällig verschwinden, wenn das Verbindungsnetzwerk nicht ordnungsgemäß funktioniert.
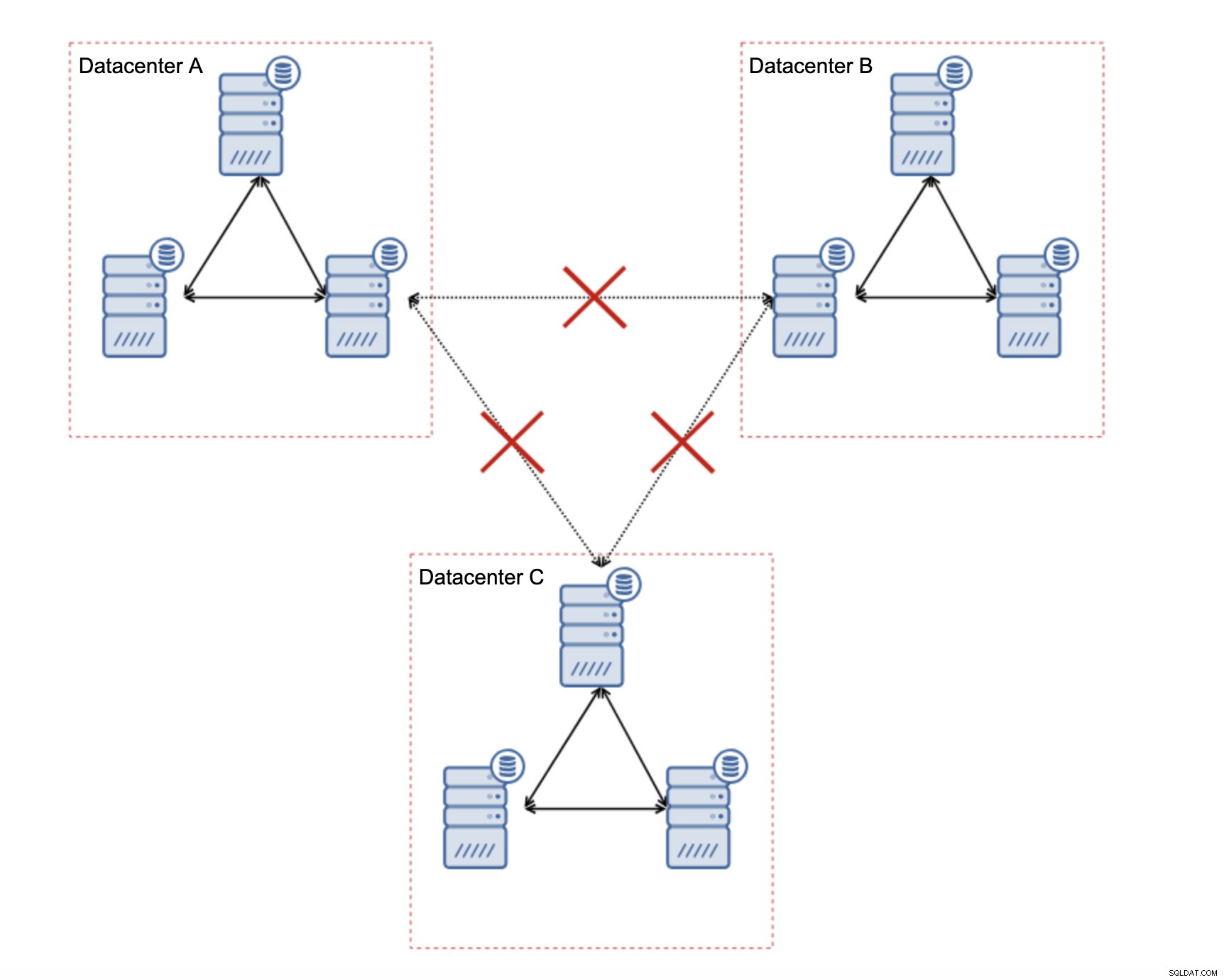
Wie entwirft man Galera-Cluster für ein instabiles Netzwerk?
Das Wichtigste zuerst:Wenn Sie Netzwerkprobleme innerhalb des einzelnen Rechenzentrums haben, können Sie nicht viel tun, es sei denn, Sie können diese Probleme irgendwie lösen. Ein unzuverlässiges lokales Netzwerk ist für Galera Cluster ein No-Go, Sie müssen die Verwendung einer anderen Lösung überdenken (obwohl, um ehrlich zu sein, ein unzuverlässiges Netzwerk immer ein Problem sein wird). Wenn die Probleme andererseits nur mit WAN-Verbindungen zusammenhängen (und dies ist einer der typischsten Fälle), ist es möglicherweise möglich, WAN-Galera-Links durch reguläre asynchrone Replikation zu ersetzen (wenn das Galera-WAN-Tuning nicht geholfen hat).
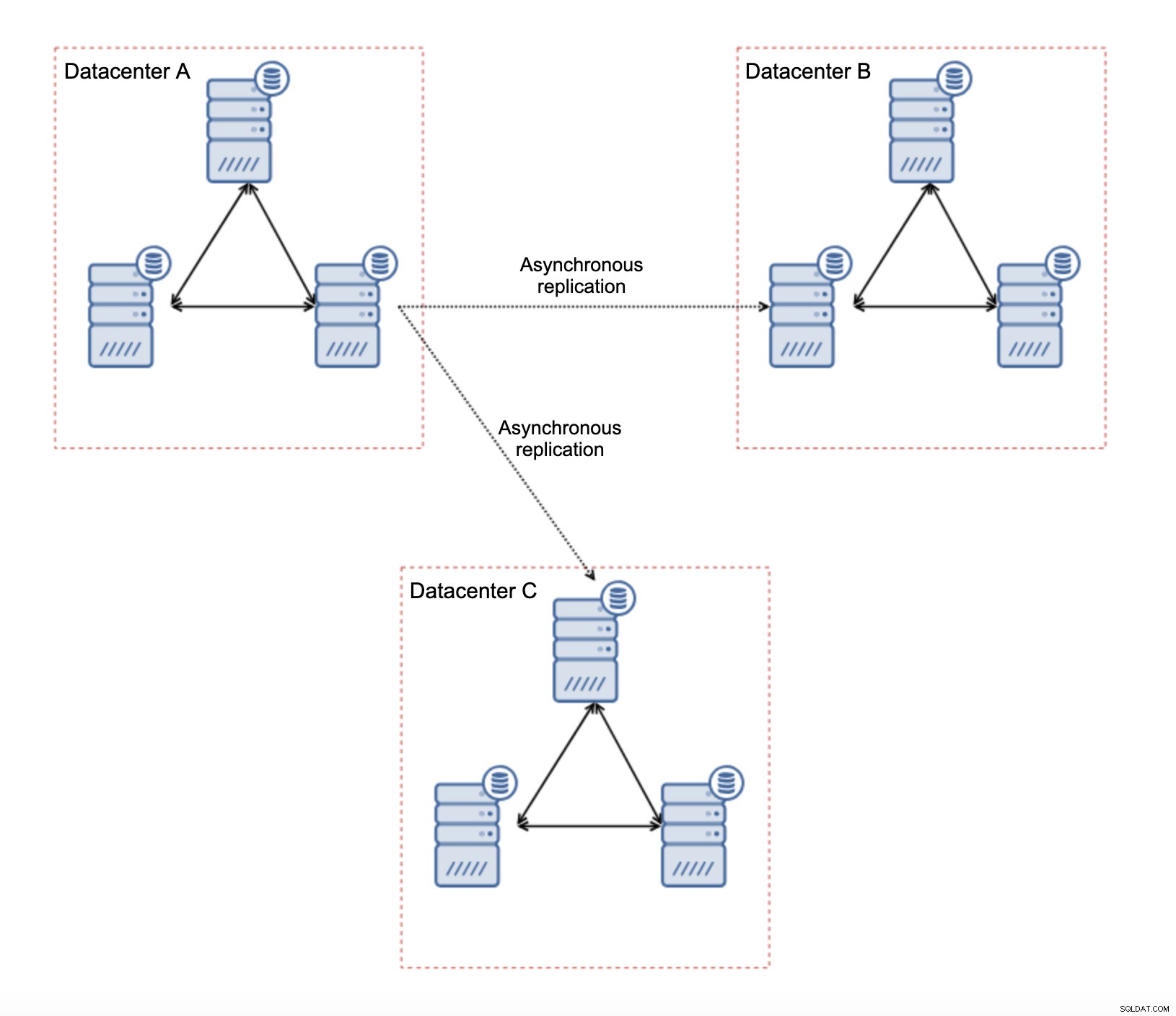
Es gibt mehrere inhärente Einschränkungen bei diesem Setup – das Hauptproblem besteht darin, dass die Schreibvorgänge früher lokal erfolgten. Jetzt müssen alle Schreibvorgänge zum „Master“-Rechenzentrum (DC A in unserem Fall) geleitet werden. Das ist nicht so schlimm, wie es klingt. Bitte beachten Sie, dass in einer All-Galera-Umgebung Schreibvorgänge durch die Latenz zwischen Knoten in verschiedenen Rechenzentren verlangsamt werden. Sogar lokale Schreibvorgänge sind betroffen. Es ist mehr oder weniger die gleiche Verlangsamung wie bei einer asynchronen Einrichtung, bei der Sie die Schreibvorgänge über das WAN an das „Master“-Rechenzentrum senden würden.
Die Verwendung der asynchronen Replikation bringt alle für die asynchrone Replikation typischen Probleme mit sich. Die Replikationsverzögerung kann zu einem Problem werden – nicht, dass Galera leistungsfähiger wäre, es ist nur so, dass Galera den Datenverkehr über die Flusskontrolle verlangsamen würde, während die Replikation keinen Mechanismus hat, um den Datenverkehr auf dem Master zu drosseln.
Ein weiteres Problem ist das Failover:Wenn der „Master“-Galera-Knoten (derjenige, der als Master für die Slaves in anderen Rechenzentren fungiert) ausfallen würde, muss ein Mechanismus geschaffen werden, um Slaves auf einen anderen, funktionierenden Master-Knoten umzuleiten. Es könnte sich um eine Art Skript handeln, es ist auch möglich, etwas mit VIP zu versuchen, bei dem der „Slave“-Galera-Cluster die virtuelle IP abarbeitet, die immer dem aktiven Galera-Knoten im „Master“-Cluster zugewiesen wird.
Der Hauptvorteil einer solchen Einrichtung besteht darin, dass wir die WAN-Galera-Verbindung entfernen, was bedeutet, dass unser „Master“-Cluster nicht durch die Tatsache verlangsamt wird, dass einige der Knoten geografisch getrennt sind. Wie wir bereits erwähnt haben, verlieren wir die Fähigkeit, in alle Rechenzentren zu schreiben, aber das latenzmäßige Schreiben über das WAN ist dasselbe wie das lokale Schreiben in den Galera-Cluster, der sich über das WAN erstreckt. Als Ergebnis sollte sich die Gesamtlatenz verbessern. Die asynchrone Replikation ist auch weniger anfällig für instabile Netzwerke. Im schlimmsten Fall wird die Replikationsverbindung unterbrochen und neu erstellt, wenn die Netzwerke zusammenlaufen.
Wie gestaltet man die MySQL-Replikation für ein instabiles Netzwerk?
Im vorherigen Abschnitt haben wir den Galera-Cluster behandelt, und eine Lösung bestand darin, die asynchrone Replikation zu verwenden. Wie sieht es in einem einfachen asynchronen Replikations-Setup aus? Sehen wir uns an, wie ein instabiles Netzwerk die größten Störungen im Replikations-Setup verursachen kann.
Zunächst einmal die Latenz – einer der Hauptschmerzpunkte für Galera Cluster. Im Falle einer Replikation ist dies fast kein Problem. Es sei denn, Sie verwenden die halbsynchrone Replikation – in diesem Fall verlangsamt eine erhöhte Latenz die Schreibvorgänge. Bei der asynchronen Replikation hat die Latenz keine Auswirkung auf die Schreibleistung. Es kann sich jedoch auf die Replikationsverzögerung auswirken. Es ist nicht so wichtig wie bei Galera, aber Sie können mehr Verzögerungsspitzen und eine insgesamt weniger stabile Replikationsleistung erwarten, wenn das Netzwerk zwischen den Knoten unter hoher Latenz leidet. Dies liegt hauptsächlich an der Tatsache, dass der Master auch mehrere Schreibvorgänge ausführen kann, bevor die Datenübertragung an den Slave in einem Netzwerk mit hoher Latenz initiiert werden kann.
Die Netzwerkinstabilität kann sich definitiv auf die Replikationsverbindungen auswirken, ist aber wiederum nicht so kritisch. MySQL-Slaves versuchen, sich wieder mit ihren Mastern zu verbinden, und die Replikation beginnt.
Das Hauptproblem bei der MySQL-Replikation ist tatsächlich etwas, das Galera Cluster intern löst – die Netzwerkpartitionierung. Wir sprechen von der Netzwerkpartitionierung als dem Zustand, in dem Segmente des Netzwerks voneinander getrennt werden. Die MySQL-Replikation verwendet einen einzigen Writer-Knoten – den Master. Unabhängig davon, wie Sie Ihre Umgebung gestalten, müssen Sie Ihre Schreibvorgänge an den Master senden. Wenn der Master nicht verfügbar ist (aus welchen Gründen auch immer), kann die Anwendung ihre Aufgabe nicht erfüllen, es sei denn, sie läuft in einer Art Nur-Lese-Modus. Daher ist es notwendig, den neuen Meister so schnell wie möglich auszuwählen. Hier zeigen sich die Probleme.
Erstens, wie man erkennt, welcher Host ein Master ist und welcher nicht. Eine der üblichen Möglichkeiten besteht darin, die „read_only“-Variable zu verwenden, um Slaves vom Master zu unterscheiden. Wenn der Knoten read_only aktiviert hat (read_only =1 setzen), ist er ein Slave (da Slaves keine direkten Schreibvorgänge verarbeiten sollten). Wenn der Knoten read_only deaktiviert hat (read_only =0 setzen), ist er ein Master. Um die Dinge sicherer zu machen, ist ein gängiger Ansatz, read_only=1 in der MySQL-Konfiguration zu setzen - im Falle eines Neustarts ist es sicherer, wenn der Knoten als Slave angezeigt wird. Eine solche „Sprache“ kann von Proxys wie ProxySQL oder MaxScale verstanden werden.
Sehen wir uns ein Beispiel an.
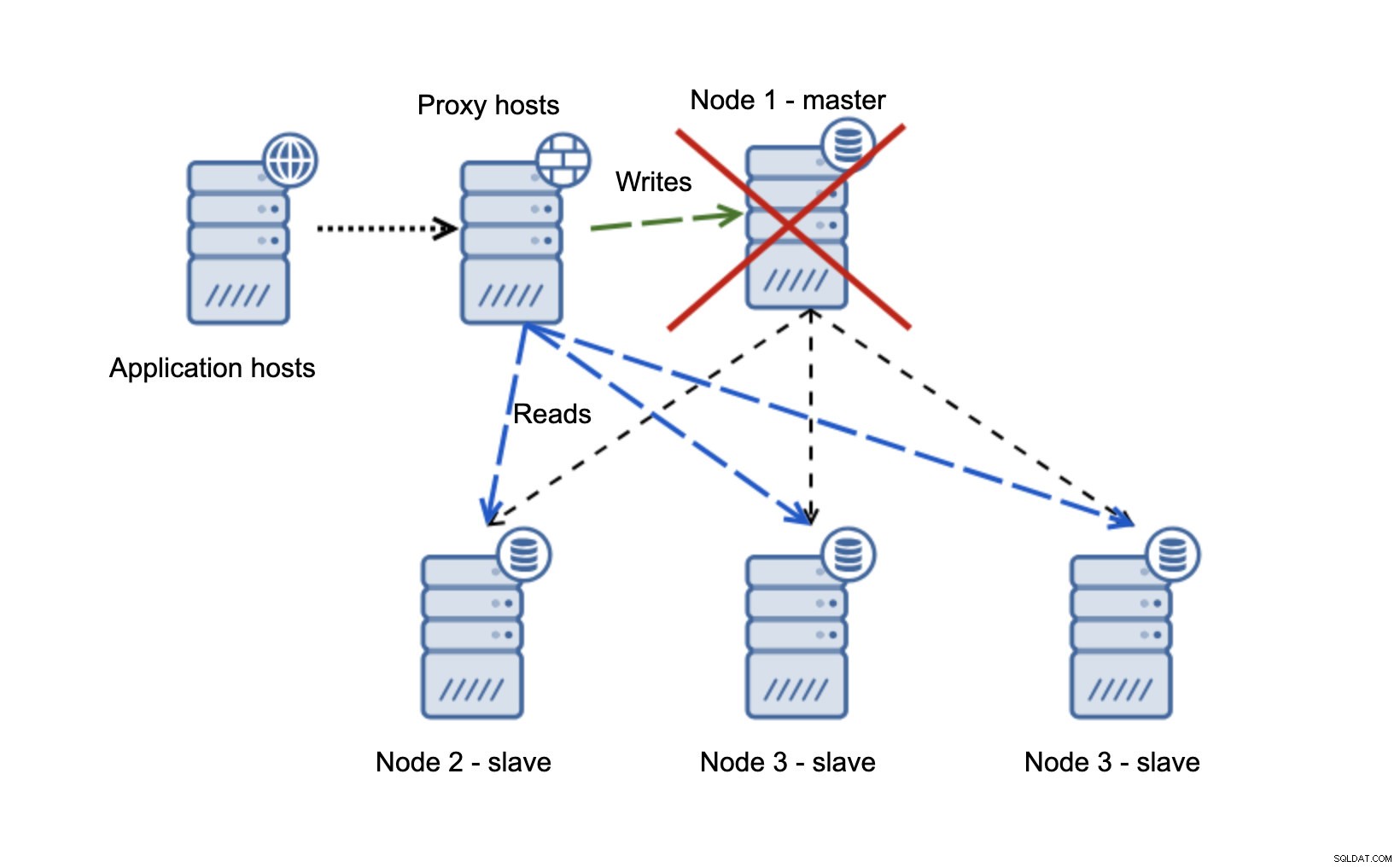
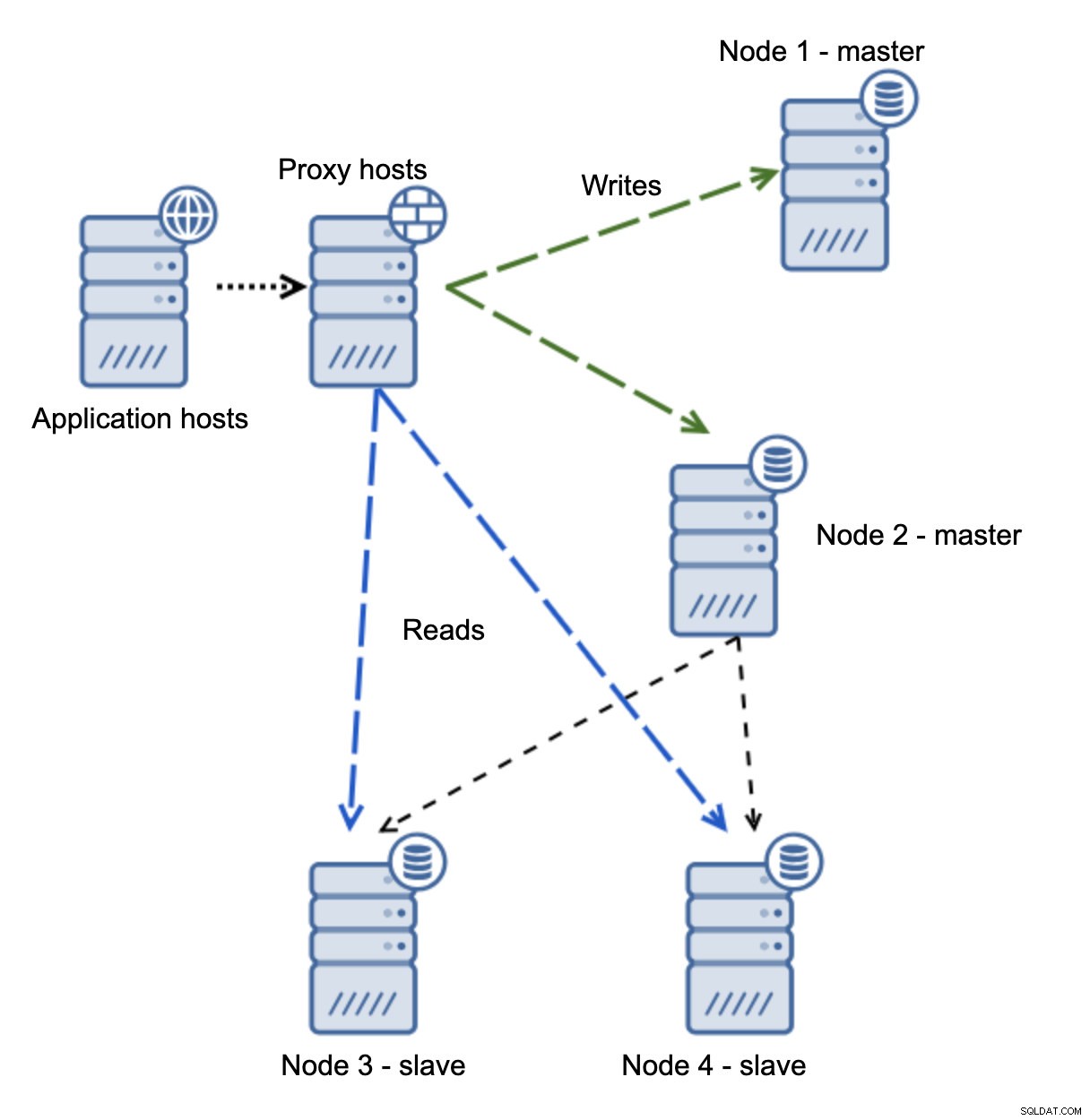
Wir haben Anwendungshosts, die sich mit der Proxy-Schicht verbinden. Proxys führen die Lese-/Schreibaufteilung durch, indem sie SELECTs an Slaves und Schreibvorgänge an den Master senden. Wenn der Master ausgefallen ist, wird ein Failover durchgeführt, ein neuer Master heraufgestuft, die Proxy-Schicht erkennt dies und beginnt, Schreibvorgänge an einen anderen Knoten zu senden.
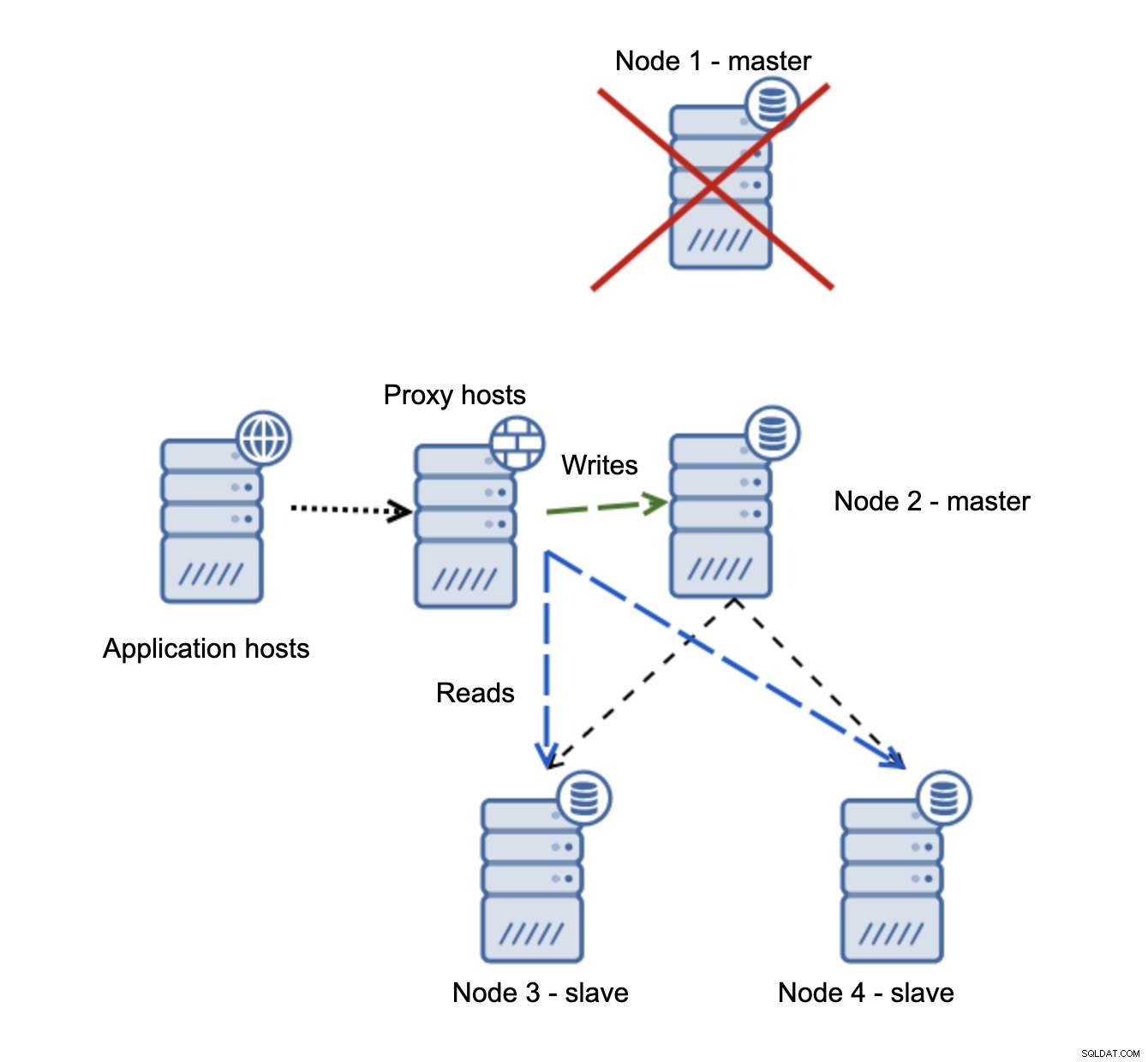
Wenn Knoten1 neu startet, wird er mit read_only=1 angezeigt und als Slave erkannt. Es ist nicht ideal, da es nicht repliziert, aber es ist akzeptabel. Im Idealfall sollte der alte Meister überhaupt nicht auftauchen, bis er wieder aufgebaut und vom neuen Meister abgesklavt wurde.
Eine viel problematischere Situation ist, wenn wir uns mit der Netzwerkpartitionierung befassen müssen. Betrachten wir dasselbe Setup:Anwendungsebene, Proxyebene und Datenbanken.
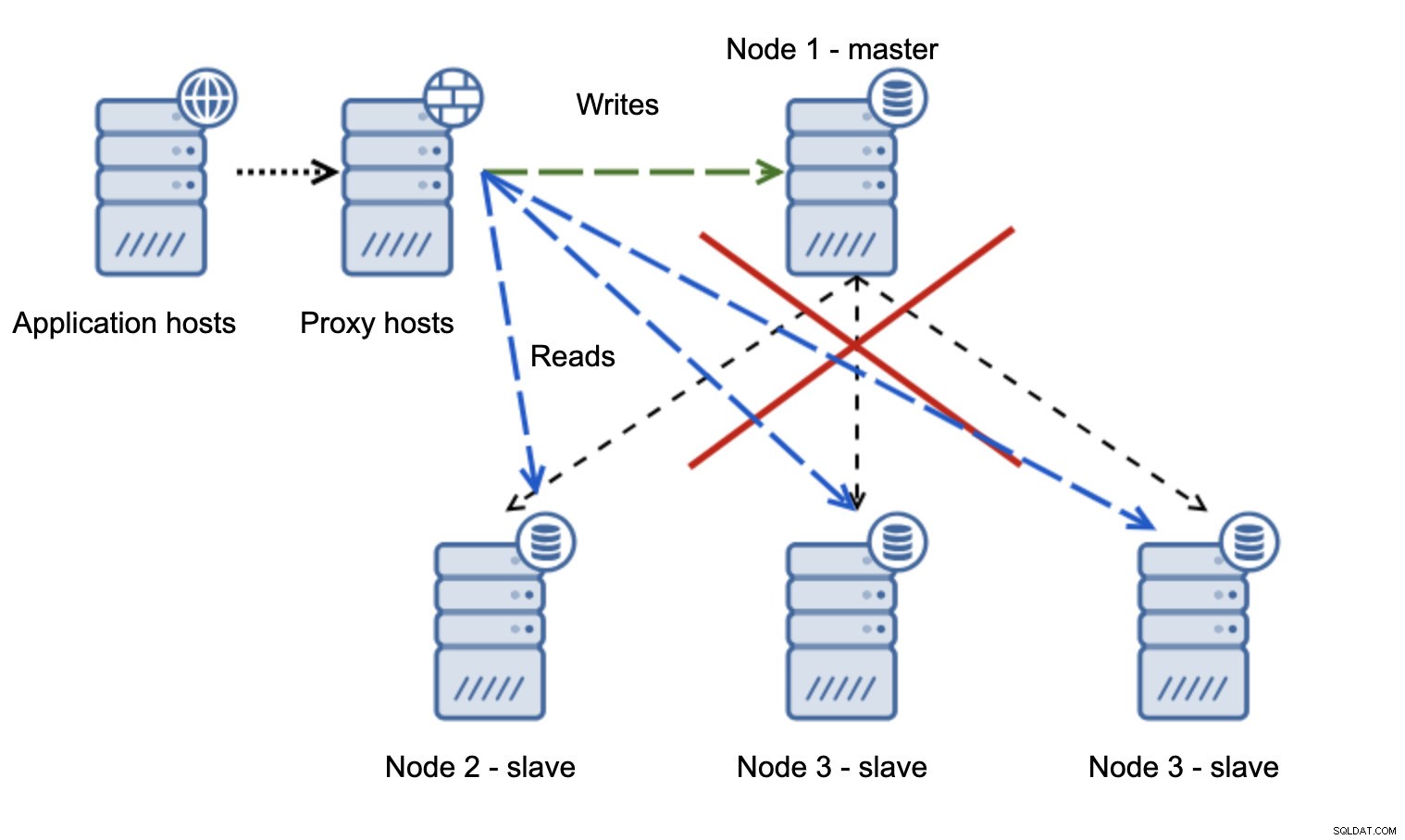
Wenn das Netzwerk den Master nicht erreichbar macht, kann die Anwendung nicht verwendet werden, da keine Schreibvorgänge ihr Ziel erreichen. Der neue Master wird heraufgestuft, Schreibvorgänge werden dorthin umgeleitet. Was passiert dann, wenn die Netzwerkprobleme aufhören und der alte Master erreichbar wird? Es wurde nicht gestoppt, daher verwendet es immer noch read_only=0:
Sie sind jetzt in einem Split Brain gelandet, als Schreibvorgänge an zwei Knoten geleitet wurden. Diese Situation ist ziemlich schlimm, da das Zusammenführen unterschiedlicher Datensätze eine Weile dauern kann und ein ziemlich komplexer Prozess ist.
Was kann getan werden, um dieses Problem zu vermeiden? Es gibt keine Wunderwaffe, aber einige Maßnahmen können ergriffen werden, um die Wahrscheinlichkeit einer Gehirnspaltung zu minimieren.
Erstens können Sie den Status des Masters intelligenter erkennen. Wie sehen das die Sklaven? Können sie daraus replizieren? Vielleicht können sich einige der Slaves immer noch mit dem Master verbinden, was bedeutet, dass der Master betriebsbereit ist oder es zumindest möglich macht, ihn zu stoppen, falls dies erforderlich sein sollte. Was ist mit der Proxy-Schicht? Sehen alle Proxy-Knoten den Master als nicht verfügbar an? Wenn einige noch eine Verbindung herstellen können, können Sie versuchen, diese Knoten zu verwenden, um per SSH in den Master zu gelangen und ihn vor dem Failover zu stoppen?
Die Failover-Verwaltungssoftware kann auch den Status des Netzwerks intelligenter erkennen. Möglicherweise verwendet es RAFT oder ein anderes Clustering-Protokoll, um einen Quorum-fähigen Cluster zu erstellen. Wenn eine Failover-Verwaltungssoftware das Split Brain erkennen kann, kann sie auch einige darauf basierende Maßnahmen ergreifen, wie zum Beispiel alle Knoten im partitionierten Segment auf read_only setzen, um sicherzustellen, dass der alte Master nicht als beschreibbar angezeigt wird, wenn die Netzwerke zusammenlaufen.
Sie können auch Tools wie Consul oder Etcd einbinden, um den Zustand des Clusters zu speichern. Die Proxy-Schicht kann so konfiguriert werden, dass sie Daten von Consul verwendet, nicht den Status der Read_only-Variable. Es liegt dann an der Failover-Verwaltungssoftware, die notwendigen Änderungen in Consul vorzunehmen, damit alle Proxys den Datenverkehr an einen korrekten, neuen Master senden.
Einige dieser Hinweise können sogar miteinander kombiniert werden, um die Fehlererkennung noch zuverlässiger zu machen. Alles in allem ist es möglich, die Wahrscheinlichkeit zu minimieren, dass der Replikationscluster unter unzuverlässigen Netzwerken leidet.
Wie Sie sehen, können instabile Netzwerke zu einem ernsthaften Problem werden, egal ob es sich um Galera oder die MySQL-Replikation handelt. Auf der anderen Seite, wenn Sie die Umgebung richtig entwerfen, können Sie sie trotzdem zum Laufen bringen. Wir hoffen, dass dieser Blogbeitrag Ihnen hilft, Umgebungen zu erstellen, die auch dann stabil funktionieren, wenn die Netzwerke es nicht sind.