Die Galera-Replikation ist relativ neu im Vergleich zur MySQL-Replikation, die seit MySQL v3.23 nativ unterstützt wird. Obwohl die MySQL-Replikation für die unidirektionale Master-Slave-Replikation konzipiert ist, kann sie als aktives Master-Master-Setup mit bidirektionaler Replikation konfiguriert werden. Obwohl es einfach einzurichten ist und einige Anwendungsfälle von diesem „Hack“ profitieren könnten, gibt es eine Reihe von Einschränkungen. Auf der anderen Seite ist der Galera-Cluster eine andere Art von Technologie, die es zu erlernen und zu verwalten gilt. Lohnt es sich?
In diesem Blogpost werden wir die Master-Master-Replikation mit dem Galera-Cluster vergleichen.
Replikationskonzepte
Bevor wir uns mit dem Vergleich befassen, wollen wir die grundlegenden Konzepte hinter diesen beiden Replikationsmechanismen erläutern.
Im Allgemeinen generiert jede Änderung an der MySQL-Datenbank ein Ereignis im Binärformat. Dieses Ereignis wird abhängig von der gewählten Replikationsmethode – MySQL-Replikation (nativ) oder Galera-Replikation (mit wsrep-API gepatcht) – zu den anderen Knoten transportiert.
MySQL-Replikation
Die folgenden Diagramme veranschaulichen den Datenfluss einer erfolgreichen Transaktion von einem Knoten zum anderen, wenn die MySQL-Replikation verwendet wird:
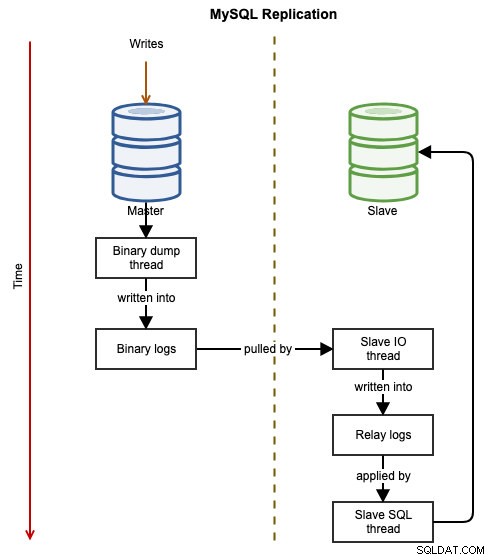
Das Binärereignis wird in das Binärlog des Masters geschrieben. Die Slaves über slave_IO_thread zieht die binären Ereignisse aus dem binären Log des Masters und repliziert sie in sein Relay-Log. Der slave_SQL_thread wendet dann das Ereignis aus dem Relaisprotokoll asynchron an. Aufgrund der asynchronen Natur der Replikation ist nicht garantiert, dass der Slave-Server über die Daten verfügt, wenn der Master die Änderung vornimmt.
Idealerweise wird bei der MySQL-Replikation der Slave als Nur-Lese-Server konfiguriert, indem read_only=ON oder super_read_only=ON gesetzt wird. Dies ist eine Vorsichtsmaßnahme, um den Slave vor versehentlichen Schreibvorgängen zu schützen, die zu Dateninkonsistenzen oder Fehlern während des Master-Failovers führen können (z. B. fehlerhafte Transaktionen). In einem Master-Master-Aktiv-Aktiv-Replikations-Setup muss Read-Only jedoch auf dem anderen Master deaktiviert werden, damit Schreibvorgänge gleichzeitig verarbeitet werden können. Der primäre Master muss so konfiguriert werden, dass er vom sekundären Master repliziert, indem die Anweisung CHANGE MASTER verwendet wird, um die zirkuläre Replikation zu aktivieren.
Galera-Replikation
Die folgenden Diagramme veranschaulichen den Datenreplikationsfluss einer erfolgreichen Transaktion von einem Knoten zum anderen für Galera Cluster:
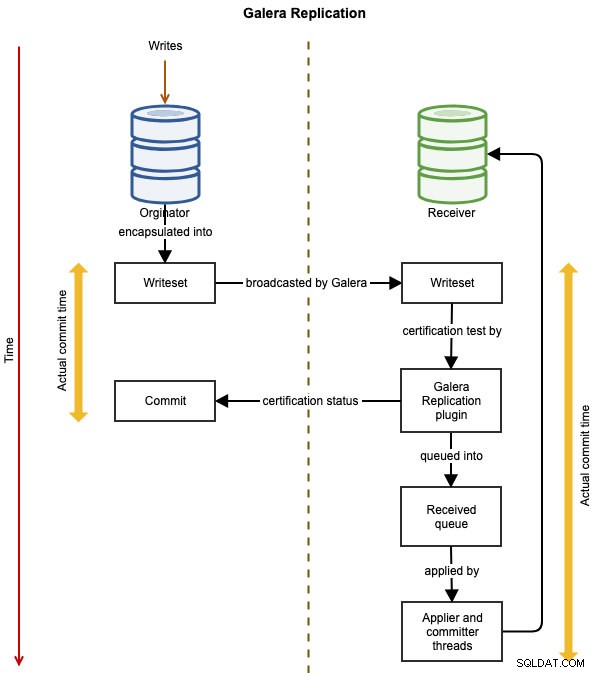
Das Ereignis wird in einem Writeset gekapselt und mithilfe der Galera-Replikation vom Ursprungsknoten an die anderen Knoten im Cluster gesendet. Das Writeset wird auf jedem Galera-Knoten einer Zertifizierung unterzogen, und wenn es bestanden wird, wenden die Applikator-Threads das Writeset asynchron an. Das bedeutet, dass der Slave-Server nach Zustimmung aller beteiligten Knoten in der globalen Gesamtordnung schließlich konsistent wird. Es ist logisch synchron, aber das eigentliche Schreiben und Festschreiben an den Tablespace erfolgt unabhängig und somit asynchron auf jedem Knoten mit einer Garantie, dass die Änderung auf allen Knoten propagiert wird.
Vermeiden von Primärschlüsselkollisionen
Um die MySQL-Replikation im Master-Master-Setup bereitzustellen, muss der Wert für die automatische Erhöhung angepasst werden, um eine Primärschlüsselkollision für INSERT zwischen zwei oder mehr replizierenden Mastern zu vermeiden. Dadurch können sich die Primärschlüsselwerte auf Mastern gegenseitig verschachteln und verhindern, dass dieselbe Autoinkrementnummer zweimal auf einem der Knoten verwendet wird. Dieses Verhalten muss je nach Anzahl der Master im Replikationssetup manuell konfiguriert werden. Der Wert von auto_increment_increment entspricht der Anzahl der replizierenden Master und dem auto_increment_offset müssen untereinander eindeutig sein. Beispielsweise sollten die folgenden Zeilen in der entsprechenden my.cnf vorhanden sein:
Meister1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Meister2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Ebenso verwendet Galera Cluster denselben Trick, um Primärschlüsselkollisionen zu vermeiden, indem der Auto-Increment-Wert und der Offset automatisch mit wsrep_auto_increment_control gesteuert werden Variable. Wenn auf 1 gesetzt (Standardeinstellung), wird auto_increment_increment automatisch angepasst und auto_increment_offset Variablen entsprechend der Größe des Clusters und wenn sich die Clustergröße ändert. Dies vermeidet Replikationskonflikte aufgrund von auto_increment. In einer Master-Slave-Umgebung kann diese Variable auf OFF gesetzt werden.
Die Folge dieser Konfiguration ist, dass der Auto-Increment-Wert nicht in sequenzieller Reihenfolge ist, wie in der folgenden Tabelle eines Galera-Clusters mit drei Knoten gezeigt:
| Knoten | auto_increment_increment | auto_increment_offset | Wert automatisch erhöhen |
|---|---|---|---|
| Knoten 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Knoten 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Knoten 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Wenn eine Anwendung Einfügevorgänge auf den folgenden Knoten in der folgenden Reihenfolge ausführt:
- Knoten1, Knoten3, Knoten2, Knoten3, Knoten3, Knoten1, Knoten3 ..
Dann lautet der Primärschlüsselwert, der in der Tabelle gespeichert wird:
- 1, 6, 8, 9, 12, 13, 15 ..
Einfach gesagt, wenn Sie die Master-Master-Replikation (MySQL-Replikation oder Galera) verwenden, muss Ihre Anwendung in der Lage sein, nicht sequentielle Autoinkrement-Werte in ihrem Datensatz zu tolerieren.
Beachten Sie für ClusterControl-Benutzer, dass es die Bereitstellung der MySQL-Master-Master-Replikation mit einem Limit von zwei Mastern pro Replikationscluster nur für die Aktiv-Passiv-Einrichtung unterstützt. Daher konfiguriert ClusterControl die Master nicht bewusst mit auto_increment_increment und auto_increment_offset Variablen.
Datenkonsistenz
Galera Cluster verfügt über einen Flow-Control-Mechanismus, bei dem jeder Knoten im Cluster bei der Replikation mithalten muss, andernfalls müssen alle anderen Knoten langsamer werden, damit der langsamste Knoten aufholen kann. Dies minimiert im Grunde die Wahrscheinlichkeit von Slave-Lag, obwohl es immer noch vorkommen kann, aber nicht so signifikant wie bei der MySQL-Replikation. Standardmäßig erlaubt Galera, dass Knoten mindestens 16 Transaktionen hinter der Anwendung durch die Variable gcs.fc_limit liegen . Wenn Sie kritische Lesevorgänge durchführen möchten (ein SELECT, das die aktuellsten Informationen zurückgeben muss), möchten Sie wahrscheinlich die Sitzungsvariable wsrep_sync_wait verwenden .
Galera Cluster hingegen verfügt über einen Schutz vor Dateninkonsistenz, wodurch ein Knoten aus dem Cluster entfernt wird, wenn er aus welchen Gründen auch immer kein Writeset anwendet. Wenn beispielsweise ein Galera-Knoten aufgrund eines internen Fehlers der zugrunde liegenden Speicher-Engine (MySQL/MariaDB) Writeset nicht anwenden kann, zieht sich der Knoten mit dem folgenden Fehler aus dem Cluster zurück:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..Um die Datenkonsistenz zu beheben, muss der störende Knoten erneut synchronisiert werden, bevor er dem Cluster beitreten darf. Dies kann manuell oder durch Löschen des Datenverzeichnisses erfolgen, um eine Snapshot-Statusübertragung auszulösen (vollständige Synchronisierung von einem Spender).
Die MySQL-Master-Master-Replikation erzwingt keinen Datenkonsistenzschutz, und ein Slave darf abweichen, z. B. eine Teilmenge von Daten replizieren oder hinterherhinken, wodurch der Slave inkonsistent mit dem Master wird. Es wurde entwickelt, um Daten in einem Fluss zu replizieren – vom Master bis zu den Slaves. Datenkonsistenzprüfungen müssen manuell oder über externe Tools wie Percona Toolkit pt-table-checksum oder mysql-replication-check durchgeführt werden.
Konfliktlösung
Im Allgemeinen ermöglicht die Master-Master- (oder Multi-Master- oder bidirektionale) Replikation mehr als einem Mitglied im Cluster, Schreibvorgänge zu verarbeiten. Bei der MySQL-Replikation beendet der SQL-Thread des Slaves im Falle eines Replikationskonflikts einfach die Anwendung der nächsten Abfrage, bis der Konflikt gelöst ist, entweder durch manuelles Überspringen des Replikationsereignisses, durch Beheben der fehlerhaften Zeilen oder durch erneutes Synchronisieren des Slaves. Einfach gesagt, es gibt keine automatische Konfliktlösungsunterstützung für die MySQL-Replikation.
Galera Cluster bietet eine bessere Alternative, indem die fehlerhafte Transaktion während der Replikation wiederholt wird. Durch die Verwendung von wsrep_retry_autocommit -Variable kann man Galera anweisen, eine fehlgeschlagene Transaktion aufgrund von clusterweiten Konflikten automatisch erneut zu versuchen, bevor ein Fehler an den Client zurückgegeben wird. Wenn der Wert 0 ist, werden keine Wiederholungen versucht, während ein Wert von 1 (Standard) oder mehr die Anzahl der versuchten Wiederholungen angibt. Dies kann nützlich sein, um Anwendungen zu unterstützen, die Autocommit verwenden, um Deadlocks zu vermeiden.
Knotenkonsens und Failover
Galera verwendet das Group Communication System (GCS), um den Knotenkonsens und die Verfügbarkeit zwischen den Clustermitgliedern zu überprüfen. Wenn ein Knoten fehlerhaft ist, wird er nach gmcast.peer_timeout automatisch aus dem Cluster entfernt Wert, standardmäßig 3 Sekunden. Ein fehlerfreier Galera-Knoten im „Synced“-Zustand wird als zuverlässiger Knoten für Lese- und Schreibvorgänge angesehen, während andere dies nicht sind. Dieses Design vereinfacht Zustandsprüfungsverfahren von den oberen Ebenen (Load Balancer oder Anwendung) erheblich.
Bei der MySQL-Replikation kümmert sich ein Master nicht um seine Slaves, während ein Slave nur über den slave_IO_thread einen Konsens mit seinem einzigen Master hat Prozess beim Replizieren der binären Ereignisse aus dem Binärlog des Masters. Wenn ein Master ausfällt, unterbricht dies die Replikation und es wird bei jedem slave_net_timeout versucht, die Verbindung wiederherzustellen (standardmäßig 60 Sekunden). Aus Sicht der Anwendung oder des Load Balancers müssen die Zustandsprüfungsverfahren für Replikations-Slaves mindestens die Überprüfung des folgenden Zustands beinhalten:
- Seconds_Behind_Master
- Slave_IO_Running
- Slave_SQL_Running
- schreibgeschützte Variable
- super_read_only-Variable (MySQL 5.7.8 und höher)
In Bezug auf Failover sind Master-Master-Replikation und Galera-Knoten im Allgemeinen gleich. Sie enthalten denselben Datensatz (obwohl Sie eine Teilmenge von Daten in der MySQL-Replikation replizieren können, dies ist jedoch für Master-Master ungewöhnlich) und teilen dieselbe Rolle wie Master, die Lese- und Schreibvorgänge gleichzeitig verarbeiten können. Daher gibt es aufgrund dieses Gleichgewichts aus Datenbanksicht eigentlich kein Failover. Nur von der Anwendungsseite, die ein Failover erfordern würde, um die nicht betriebsbereiten Knoten zu überspringen. Denken Sie daran, dass aufgrund der asynchronen MySQL-Replikation möglicherweise nicht alle auf dem Master vorgenommenen Änderungen an den anderen Master weitergegeben wurden.
Knotenbereitstellung
Der Prozess, einen Knoten mit dem Cluster zu synchronisieren, bevor die Replikation beginnt, wird als Bereitstellung bezeichnet. Bei der MySQL-Replikation ist die Bereitstellung eines neuen Knotens ein manueller Prozess. Man muss eine Sicherungskopie des Masters erstellen und sie auf dem neuen Knoten wiederherstellen, bevor die Replikationsverbindung eingerichtet wird. Wenn für einen vorhandenen Replikationsknoten die Binärprotokolle des Masters rotiert wurden (basierend auf expire_logs_days , der Standardwert 0 bedeutet keine automatische Entfernung), müssen Sie den Knoten möglicherweise mit diesem Verfahren erneut bereitstellen. Es gibt auch externe Tools wie Percona Toolkit pt-table-sync und ClusterControl, die Ihnen dabei helfen. ClusterControl unterstützt die Resynchronisierung eines Slaves mit nur zwei Klicks. Sie haben Optionen zur Resynchronisierung, indem Sie ein Backup vom aktiven Master oder ein vorhandenes Backup erstellen.
In Galera gibt es zwei Möglichkeiten, dies zu tun - Incremental State Transfer (IST) oder State Snapshot Transfer (SST). Der IST-Prozess ist die bevorzugte Methode, bei der nur die fehlenden Transaktionen aus dem Cache eines Spenders übertragen werden. Der SST-Prozess ähnelt dem Erstellen eines vollständigen Backups vom Spender, er ist normalerweise ziemlich ressourcenintensiv. Galera bestimmt automatisch, welcher Synchronisierungsprozess basierend auf dem Status des Joiners ausgelöst werden soll. Wenn ein Knoten einem Cluster nicht beitreten kann, löschen Sie in den meisten Fällen einfach das MySQL-Datenverzeichnis des problematischen Knotens und starten Sie den MySQL-Dienst. Der Galera-Bereitstellungsprozess ist viel einfacher, er ist sehr praktisch, wenn Sie Ihren Cluster skalieren oder einen problematischen Knoten wieder in den Cluster einführen.
Los gekoppelt vs. eng gekoppelt
Die MySQL-Replikation funktioniert auch über langsamere Verbindungen und mit Verbindungen, die nicht kontinuierlich sind, sehr gut. Es kann auch über verschiedene Hardware, Umgebungen und Betriebssysteme hinweg verwendet werden. Die meisten Speicher-Engines unterstützen es, einschließlich MyISAM, Aria, MEMORY und ARCHIVE. Dieses lose gekoppelte Setup ermöglicht es der MySQL-Master-Master-Replikation, in einer gemischten Umgebung mit weniger Einschränkungen gut zu funktionieren.
Galera-Knoten sind eng gekoppelt, wobei die Replikationsleistung so schnell ist wie die des langsamsten Knotens. Galera verwendet einen Flusssteuerungsmechanismus, um den Replikationsfluss zwischen den Mitgliedern zu steuern und jegliche Slave-Verzögerung zu beseitigen. Die Replikation kann auf jedem Knoten ganz schnell oder ganz langsam sein und wird automatisch von Galera angepasst. Daher wird empfohlen, einheitliche Hardwarespezifikationen für alle Galera-Knoten zu verwenden, insbesondere in Bezug auf CPU, RAM, Festplattensubsystem, Netzwerkschnittstellenkarte und Netzwerklatenz zwischen Knoten im Cluster.
Schlussfolgerungen
Zusammenfassend ist Galera Cluster im Vergleich zur MySQL-Master-Master-Replikation aufgrund seiner synchronen Replikationsunterstützung mit starker Konsistenz sowie erweiterten Funktionen wie automatischer Mitgliedschaftskontrolle, automatischer Knotenbereitstellung und Multithread-Slaves überlegen. Letztendlich hängt dies davon ab, wie die Anwendung mit dem Datenbankserver interagiert. Einige Legacy-Anwendungen, die für einen eigenständigen Datenbankserver erstellt wurden, funktionieren möglicherweise nicht gut in einem Cluster-Setup.
Um unsere obigen Punkte zu vereinfachen, rechtfertigen die folgenden Gründe, wann die MySQL-Master-Master-Replikation verwendet werden sollte:
- Dinge, die von Galera nicht unterstützt werden:
- Replikation für Nicht-InnoDB/XtraDB-Tabellen wie MyISAM, Aria, MEMORY oder ARCHIVE.
- XA-Transaktionen.
- Anweisungsbasierte Replikation zwischen Mastern (z. B. wenn die Bandbreite sehr teuer ist).
- Verlassen auf explizites Sperren wie die Anweisung LOCK TABLES.
- Das allgemeine Abfrageprotokoll und das Protokoll für langsame Abfragen müssen an eine Tabelle und nicht an eine Datei geleitet werden.
- Los gekoppeltes Setup, bei dem die Hardwarespezifikationen, die Softwareversion und die Verbindungsgeschwindigkeit auf jedem Master erheblich unterschiedlich sind.
- Wenn Sie bereits eine MySQL-Replikationskette haben und einen weiteren aktiven/Backup-Master für Redundanz hinzufügen möchten, um die Failover- und Wiederherstellungszeit zu beschleunigen, falls einer der Master nicht verfügbar ist.
- Wenn Ihre Anwendung nicht modifiziert werden kann, um Galera-Cluster-Einschränkungen zu umgehen, und ein MySQL-fähiger Load Balancer wie ProxySQL oder MaxScale keine Option ist.
Gründe, Galera Cluster der MySQL-Master-Master-Replikation vorzuziehen:
- Fähigkeit, sicher auf mehrere Master zu schreiben.
- Datenkonsistenz automatisch verwaltet (und garantiert) über Datenbanken hinweg.
- Neue Datenbankknoten einfach eingeführt und synchronisiert.
- Fehler oder Inkonsistenzen werden automatisch erkannt.
- Im Allgemeinen fortschrittlichere und robustere Hochverfügbarkeitsfunktionen.