Recovery Time Objective (RTO) ist der Zeitraum, innerhalb dessen ein Dienst wiederhergestellt werden muss, um inakzeptable Folgen zu vermeiden. Indem wir berechnen, wie lange die Wiederherstellung nach einem Datenbankausfall dauern kann, wissen wir, wie viel Vorbereitung erforderlich ist. Wenn die RTO wenige Minuten beträgt, sind erhebliche Investitionen in Failover erforderlich. Eine RTO von 36 Stunden erfordert eine deutlich geringere Investition. Hier kommt die Failover-Automatisierung ins Spiel.
In unseren vorherigen Blogs haben wir Failover für MongoDB, MySQL/MariaDB/Percona, PostgreSQL oder TimeScaleDB besprochen. Zusammenfassend lässt sich sagen:„Failover " ist die Fähigkeit eines Systems, auch bei einem Ausfall weiter zu funktionieren. Es deutet darauf hin, dass die Funktionen des Systems von sekundären Komponenten übernommen werden, wenn die primären Komponenten ausfallen. Failover ist ein natürlicher Bestandteil jedes Hochverfügbarkeitssystems, und in einigen Fällen , es muss sogar automatisiert werden. Manuelle Failover dauern einfach zu lange, aber es gibt Fälle, in denen die Automatisierung nicht gut funktioniert – zum Beispiel im Fall eines Split Brain, bei dem die Datenbankreplikation unterbrochen ist und die beiden „Hälften“ weiterhin effektiv Updates erhalten was zu abweichenden Datensätzen und Inkonsistenzen führt.
Wir haben bereits über die Leitprinzipien hinter den automatischen Failover-Verfahren von ClusterControl geschrieben. Wenn möglich, bietet automatisiertes Failover Effizienz, da es eine schnelle Wiederherstellung nach Ausfällen ermöglicht. In diesem Blog sehen wir uns an, wie Sie mit ClusterControl ein automatisches Failover in einer Master-Slave- (oder Primär-Standby-) Replikationseinrichtung erreichen.
Technologie-Stack-Anforderungen
Ein Stack kann aus Open-Source-Softwarekomponenten zusammengestellt werden, und es stehen eine Reihe von Optionen zur Verfügung – einige sind geeigneter als andere, abhängig von den Failover-Eigenschaften und dem verfügbaren Fachwissen für die Verwaltung und Wartung der Lösung. Hardware und Netzwerk sind ebenfalls wichtige Aspekte.
Software
Im Open-Source-Ökosystem stehen viele Optionen zur Verfügung, mit denen Sie Failover implementieren können. Für MySQL können Sie MHA, MMM, Maxscale/MRM, mysqlfailover oder Orchestrator nutzen. Dieser vorherige Blog vergleicht MaxScale mit MHA mit Maxscale/MRM. PostgreSQL hat repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II oder stolon. Diese verschiedenen Hochverfügbarkeitsoptionen wurden bereits behandelt. MongoDB verfügt über Replikatsätze mit Unterstützung für automatisiertes Failover.
ClusterControl bietet automatische Failover-Funktionalität für MySQL, MariaDB, PostgreSQL und MongoDB, die wir weiter unten behandeln werden. Erwähnenswert ist, dass es auch Funktionen zur automatischen Wiederherstellung defekter Knoten oder Cluster hat.
Hardware
Automatisches Failover wird normalerweise von einem separaten Daemon-Server durchgeführt, der auf seiner eigenen Hardware eingerichtet ist – getrennt von den Datenbankknoten. Es überwacht den Status der Datenbanken und verwendet die Informationen, um Entscheidungen zu treffen, wie im Fehlerfall reagiert werden soll.
Commodity-Server können gut funktionieren, es sei denn, der Server überwacht eine große Anzahl von Instanzen. Typischerweise sind Systemprüfungen und Zustandsanalysen in Bezug auf die Verarbeitung leichtgewichtig. Wenn Sie jedoch eine große Anzahl von Knoten zu überprüfen haben, ist eine große CPU und ein großer Arbeitsspeicher ein Muss, insbesondere wenn Überprüfungen in die Warteschlange gestellt werden müssen, da versucht wird, Informationen von Servern zu pingen und zu sammeln. Die überwachten und überwachten Knoten können manchmal aufgrund von Netzwerkproblemen, hoher Auslastung oder im schlimmsten Fall aufgrund eines Hardwarefehlers oder einer Beschädigung des VM-Hosts ausfallen. Der Server, der die Zustands- und Systemprüfungen durchführt, muss also in der Lage sein, solchen Verzögerungen standzuhalten, da die Wahrscheinlichkeit besteht, dass die Verarbeitung von Warteschlangen ansteigt, da die Antworten an jeden der überwachten Knoten einige Zeit dauern können, bis bestätigt wird, dass er nicht mehr verfügbar ist oder eine Zeitüberschreitung hat erreicht.
Für Cloud-basierte Umgebungen gibt es Dienste, die automatisches Failover bieten. Beispielsweise verwendet Amazon RDS DRBD, um Speicher auf einen Standby-Knoten zu replizieren. Oder wenn Sie Ihre Volumes in EBS speichern, werden diese in mehreren Zonen repliziert.
Netzwerk
Automatisierte Failover-Software stützt sich häufig auf Agenten, die auf den Datenbankknoten eingerichtet werden. Der Agent sammelt Informationen lokal von der Datenbankinstanz und sendet sie auf Anfrage an den Server.
Stellen Sie in Bezug auf die Netzwerkanforderungen sicher, dass Sie über eine gute Bandbreite und eine stabile Netzwerkverbindung verfügen. Überprüfungen müssen häufig durchgeführt werden, und fehlende Heartbeats aufgrund eines instabilen Netzwerks können dazu führen, dass die Failover-Software (fälschlicherweise) davon ausgeht, dass ein Knoten ausgefallen ist.
ClusterControl erfordert keine Installation eines Agenten auf den Datenbankknoten, da es in regelmäßigen Abständen eine SSH-Verbindung zu jedem Datenbankknoten herstellt und eine Reihe von Prüfungen durchführt.
Automatisiertes Failover mit ClusterControl
ClusterControl bietet die Möglichkeit, sowohl manuelle als auch automatisierte Failover durchzuführen. Mal sehen, wie das gemacht werden kann.
Failover in ClusterControl kann automatisch konfiguriert werden oder nicht. Wenn Sie das Failover lieber manuell durchführen möchten, können Sie die automatische Clusterwiederherstellung deaktivieren. Wenn Sie ein manuelles Failover durchführen, können Sie zu Cluster → Topologie gehen im ClusterControl. Siehe Screenshot unten:
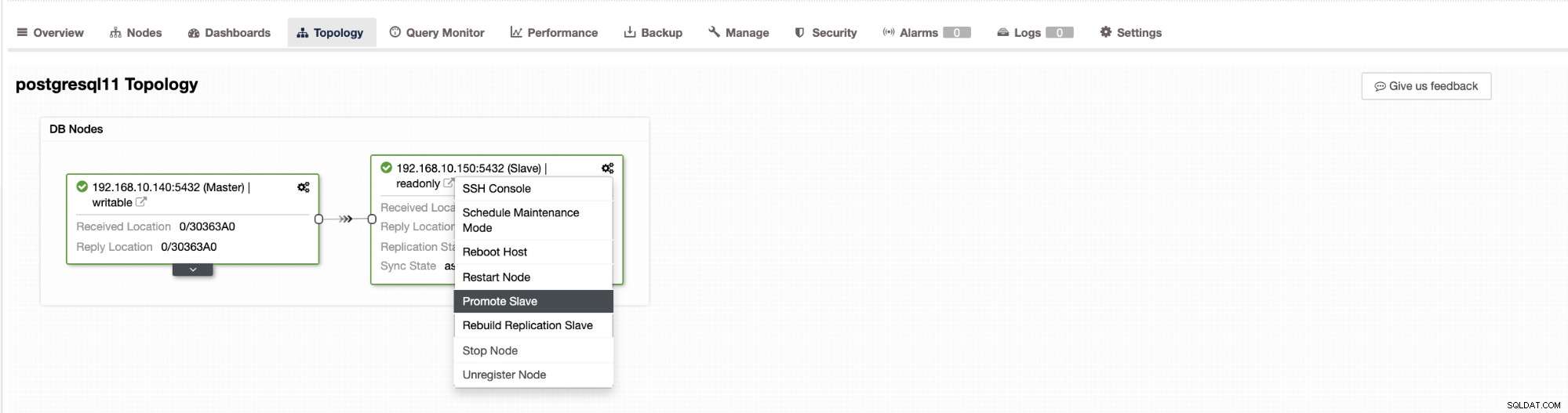
Standardmäßig ist die Clusterwiederherstellung aktiviert und es wird ein automatisches Failover verwendet. Sobald Sie Änderungen in der Benutzeroberfläche vornehmen, wird die Laufzeitkonfiguration geändert. Wenn Sie möchten, dass die Einstellung einen Neustart des Controllers überlebt, stellen Sie sicher, dass Sie die Änderung auch in der cmon-Konfiguration vornehmen, d. h. /etc/cmon.d/cmon_

Auf dem MySQL/MariaDB/Percona-Server wird ein automatisches Failover von ClusterControl initiiert, wenn es erkennt, dass es keinen Host mit read_only gibt Flagge deaktiviert. Dies kann passieren, weil master (der read_only hat auf 0 gesetzt) ist nicht verfügbar oder kann durch einen Benutzer oder eine externe Software ausgelöst werden, die dieses Flag auf dem Master geändert hat. Wenn Sie manuelle Änderungen an den Datenbankknoten vornehmen oder Software haben, die mit den Read_only-Einstellungen herumspielt, sollten Sie das automatische Failover deaktivieren. Das automatische Failover von ClusterControl wird nur einmal versucht, daher folgt auf ein fehlgeschlagenes Failover kein weiteres Failover - nicht bis cmon neu gestartet wird.
Für PostgreSQL wählt ClusterControl den fortschrittlichsten Slave aus und verwendet zu diesem Zweck je nach Version unserer Datenbank pg_current_xlog_location (PostgreSQL 9+) oder pg_current_wal_lsn (PostgreSQL 10+). ClusterControl führt auch mehrere Überprüfungen des Failover-Prozesses durch, um einige häufige Fehler zu vermeiden. Ein Beispiel ist, dass, wenn wir es schaffen, unseren alten ausgefallenen Master wiederherzustellen, er "nicht " automatisch wieder in den Cluster eingeführt werden, weder als Master noch als Slave. Wir müssen dies manuell tun. Dadurch wird die Möglichkeit eines Datenverlusts oder einer Inkonsistenz vermieden, falls unser Slave (den wir befördert haben) zu diesem Zeitpunkt verzögert war des Fehlers. Möglicherweise möchten wir das Problem auch im Detail analysieren, bevor wir es erneut in die Replikationskonfiguration einführen, daher möchten wir Diagnoseinformationen aufbewahren.
Wenn das Failover fehlschlägt, werden keine weiteren Versuche unternommen (dies gilt sowohl für PostgreSQL- als auch für MySQL-basierte Cluster), es ist ein manueller Eingriff erforderlich, um das Problem zu analysieren und die entsprechenden Maßnahmen durchzuführen. Dadurch soll verhindert werden, dass ClusterControl, das das automatische Failover handhabt, versucht, den nächsten Slave und den nächsten hochzustufen. Möglicherweise liegt ein Problem vor, und wir möchten die Situation nicht verschlimmern, indem wir mehrere Failover versuchen.
ClusterControl bietet Whitelisting und Blacklisting einer Reihe von Servern, die Sie am Failover teilnehmen oder als Kandidaten ausschließen möchten.
Für Cluster vom Typ MySQL erstellt ClusterControl eine Liste von Slaves, die zum Master befördert werden können. Meistens enthält es alle Slaves in der Topologie, aber der Benutzer hat eine zusätzliche Kontrolle darüber. Es gibt zwei Variablen, die Sie in der cmon-Konfiguration setzen können:
replication_failover_whitelistund
replication_failover_blacklistFür die Konfigurationsvariable replication_failover_whitelist enthält sie eine Liste von IPs oder Hostnamen von Slaves, die als potenzielle Master-Kandidaten verwendet werden sollten. Wenn diese Variable gesetzt ist, werden nur diese Hosts berücksichtigt. Die Variable replication_failover_blacklist enthält eine Liste von Hosts, die niemals als Masterkandidat betrachtet werden. Sie können damit Slaves auflisten, die für Backups oder analytische Abfragen verwendet werden. Wenn die Hardware zwischen den Slaves variiert, möchten Sie vielleicht die Slaves einfügen, die langsamere Hardware verwenden.
replication_failover_whitelist hat Vorrang, was bedeutet, dass replication_failover_blacklist ignoriert wird, wenn replication_failover_whitelist gesetzt ist.
Sobald die Liste der Slaves, die zum Master befördert werden können, fertig ist, beginnt ClusterControl, ihren Status zu vergleichen und nach dem aktuellsten Slave zu suchen. Hier unterscheidet sich die Handhabung von MariaDB- und MySQL-basierten Setups. Für MariaDB-Setups wählt ClusterControl einen Slave aus, der die niedrigste Replikationsverzögerung aller verfügbaren Slaves aufweist. Bei MySQL-Setups wählt ClusterControl ebenfalls einen solchen Slave aus, prüft dann aber auf zusätzliche, fehlende Transaktionen, die auf einigen der verbleibenden Slaves ausgeführt worden sein könnten. Wenn eine solche Transaktion gefunden wird, lagert ClusterControl den Master-Kandidaten von diesem Host aus, um alle fehlenden Transaktionen abzurufen. Sie können diesen Prozess überspringen und einfach den fortschrittlichsten Slave verwenden, indem Sie die Variable replication_skip_apply_missing_txs in Ihrer CMON-Konfiguration setzen:
z. B.
replication_skip_apply_missing_txs=1Weitere Informationen zu Variablen finden Sie hier in unserer Dokumentation.
Eine Einschränkung ist, dass Sie dies nur festlegen müssen, wenn Sie wissen, was Sie tun, da es zu fehlerhaften Transaktionen kommen kann. Diese können dazu führen, dass die Replikation unterbrochen wird, sowie Dateninkonsistenzen im gesamten Cluster. Wenn die fehlerhafte Transaktion in der Vergangenheit stattgefunden hat, ist sie möglicherweise nicht mehr in den Binärprotokollen verfügbar. In diesem Fall wird die Replikation unterbrochen, da Slaves die fehlenden Daten nicht abrufen können. Daher prüft ClusterControl standardmäßig auf fehlerhafte Transaktionen, bevor es einen Master-Kandidaten zum Master befördert. Wenn ein solches Problem erkannt wird, wird der Master-Switch abgebrochen und ClusterControl lässt den Benutzer das Problem manuell beheben.
Wenn Sie zu 100 % sicher sein möchten, dass ClusterControl einen neuen Master heraufstufen wird, selbst wenn einige Probleme erkannt werden, können Sie dies mit der Variable replication_stop_on_error tun. Siehe unten:
z. B.
replication_stop_on_error=0Legen Sie diese Variable in Ihrer cmon-Konfigurationsdatei fest. Wie bereits erwähnt, kann dies zu Problemen bei der Replikation führen, da Slaves möglicherweise nach einem Binärprotokollereignis fragen, das nicht mehr verfügbar ist. Um solche Fälle zu handhaben, haben wir experimentelle Unterstützung für den Wiederaufbau von Sklaven hinzugefügt. Wenn Sie die Variable
setzenreplication_auto_rebuild_slave=1in der cmon-Konfiguration und wenn Ihr Slave mit dem folgenden Fehler in MySQL als ausgefallen markiert ist:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl wird versuchen, den Slave mithilfe der Daten des Masters neu aufzubauen. Eine solche Einstellung ist möglicherweise nicht immer geeignet, da der Wiederherstellungsprozess eine erhöhte Last auf dem Master verursacht. Es kann auch sein, dass Ihr Datensatz sehr groß ist und ein regelmäßiger Neuaufbau nicht möglich ist - deshalb ist dieses Verhalten standardmäßig deaktiviert.
Sobald wir sichergestellt haben, dass keine fehlerhafte Transaktion existiert und wir loslegen können, gibt es noch ein weiteres Problem, das wir irgendwie lösen müssen – es kann passieren, dass alle Slaves hinter dem Master zurückbleiben.
Wie Sie wahrscheinlich wissen, funktioniert die Replikation in MySQL recht einfach. Der Master speichert in Binärlogs. Der E/A-Thread des Slaves verbindet sich mit dem Master und ruft alle fehlenden Binärprotokollereignisse ab. Es speichert sie dann in Form von Relaisprotokollen. Der SQL-Thread analysiert sie und wendet Ereignisse an. Die Slave-Verzögerung ist ein Zustand, in dem der SQL-Thread (oder die Threads) die Anzahl der Ereignisse nicht bewältigen kann und sie nicht anwenden kann, sobald sie vom E/A-Thread vom Master gezogen werden. Eine solche Situation kann unabhängig davon auftreten, welche Art von Replikation Sie verwenden. Selbst wenn Sie die halbsynchrone Replikation verwenden, kann sie nur garantieren, dass alle Ereignisse vom Master auf einem der Slaves im Relay-Protokoll gespeichert werden. Es sagt nichts darüber aus, diese Ereignisse auf einen Slave anzuwenden.
Das Problem dabei ist, dass, wenn ein Slave zum Master befördert wird, die Relay-Logs gelöscht werden. Wenn ein Slave hinterherhinkt und nicht alle Transaktionen angewendet hat, verliert er Daten – Ereignisse, die noch nicht aus Relay-Protokollen angewendet wurden, gehen für immer verloren.
Es gibt keinen einheitlichen Lösungsweg für diese Situation. ClusterControl gibt Benutzern die Kontrolle darüber, wie es gemacht werden soll, und behält sichere Standardeinstellungen bei. Dies geschieht in der cmon-Konfiguration mit der folgenden Einstellung:
replication_failover_wait_to_apply_timeout=-1Standardmäßig nimmt es einen Wert von „-1“ an, was bedeutet, dass ein Failover nicht sofort erfolgt, wenn ein Masterkandidat verzögert wird, sodass es so eingestellt ist, dass es ewig wartet, bis der Kandidat aufgeholt hat. ClusterControl wartet auf unbestimmte Zeit darauf, alle fehlenden Transaktionen aus seinen Relay-Protokollen anzuwenden. Dies ist sicher, aber wenn der aktuellste Slave aus irgendeinem Grund stark hinterherhinkt, kann das Failover Stunden dauern, bis es abgeschlossen ist. Auf der anderen Seite des Spektrums wird es auf „0“ gesetzt – das bedeutet, dass das Failover sofort erfolgt, unabhängig davon, ob der Master-Kandidat verzögert oder nicht. Sie können auch den Mittelweg gehen und ihn auf einen Wert setzen. Dadurch wird eine Zeit in Sekunden eingestellt, zum Beispiel 30 Sekunden, also setzen Sie die Variable auf,
replication_failover_wait_to_apply_timeout=30Wenn der Wert auf> 0 gesetzt ist, wartet ClusterControl darauf, dass ein Master-Kandidat fehlende Transaktionen aus seinen Relay-Protokollen anwendet, bis der Wert erreicht ist (was im Beispiel 30 Sekunden sind). Das Failover erfolgt nach der definierten Zeit oder wenn der Masterkandidat die Replikation nachholt, je nachdem, was zuerst eintritt. Dies kann eine gute Wahl sein, wenn Ihre Anwendung bestimmte Anforderungen an die Ausfallzeit stellt und Sie innerhalb eines kurzen Zeitfensters einen neuen Master wählen müssen.
Weitere Einzelheiten zur Funktionsweise von ClusterControl mit automatischem Failover in PostgreSQL und MySQL finden Sie in unseren vorherigen Blogs mit den Titeln „Failover for PostgreSQL Replication 101“ und „Automatic failover of MySQL Replication – New in ClusterControl 1.4“.
Schlussfolgerung
Automatisiertes Failover ist eine wertvolle Funktion, insbesondere für Unternehmen, die einen 24/7-Betrieb mit minimalen Ausfallzeiten benötigen. Das Unternehmen muss definieren, wie viel Kontrolle bei ungeplanten Ausfällen an den Automatisierungsprozess abgegeben wird. Eine Hochverfügbarkeitslösung wie ClusterControl bietet eine anpassbare Interaktionsebene bei der Failover-Verarbeitung. Für einige Organisationen ist ein automatisiertes Failover möglicherweise keine Option, auch wenn die Benutzerinteraktion während des Failovers Zeit in Anspruch nehmen und sich auf die RTO auswirken kann. Die Annahme ist, dass es zu riskant ist, falls das automatische Failover nicht richtig funktioniert oder, noch schlimmer, dazu führt, dass Daten durcheinander gebracht werden und teilweise fehlen (obwohl man argumentieren könnte, dass auch ein Mensch katastrophale Fehler machen kann, die zu ähnlichen Folgen führen). Diejenigen, die es vorziehen, eine genaue Kontrolle über ihre Datenbank zu behalten, können das automatische Failover überspringen und stattdessen einen manuellen Prozess verwenden. Ein solcher Prozess nimmt mehr Zeit in Anspruch, ermöglicht es einem erfahrenen Administrator jedoch, den Zustand eines Systems zu beurteilen und basierend auf dem, was passiert ist, Korrekturmaßnahmen zu ergreifen.