
Der typische MySQL-DBA ist möglicherweise im Rahmen seiner täglichen Routine mit der Arbeit und Verwaltung einer OLTP-Datenbank (Online Transaction Processing) vertraut. Möglicherweise sind Sie damit vertraut, wie es funktioniert und wie komplexe Vorgänge verwaltet werden. Obwohl die standardmäßige Speicher-Engine von MySQL gut genug für OLAP (Online Analytical Processing) ist, ist sie ziemlich simpel, besonders für diejenigen, die künstliche Intelligenz lernen möchten oder sich mit Prognosen, Data Mining und Datenanalysen befassen.
In diesem Blog werden wir den MariaDB ColumnStore besprechen. Der Inhalt wird auf den Nutzen des MySQL-DBA zugeschnitten, der möglicherweise weniger mit ColumnStore und seiner Anwendbarkeit für OLAP-Anwendungen (Online Analytical Processing) vertraut ist.
OLTP vs. OLAP
OLTP
Zugehörige Ressourcen Analytics with MariaDB AX – the Open Source Columnar Datastore An Introduction to Time Series Databases Hybrid OLTP/Analytics Database Workloads in Galera Cluster Using Asynchronous SlavesDie typische MySQL-DBA-Aktivität für den Umgang mit dieser Art von Daten ist die Verwendung von OLTP (Online Transaction Processing). OLTP zeichnet sich durch große Datenbanktransaktionen aus, die Einfügungen, Aktualisierungen oder Löschungen durchführen. OLTP-Datenbanken sind auf die schnelle Verarbeitung von Abfragen und die Aufrechterhaltung der Datenintegrität spezialisiert, während auf sie in mehreren Umgebungen zugegriffen wird. Seine Effektivität wird anhand der Anzahl der Transaktionen pro Sekunde (tps) gemessen. Es ist ziemlich üblich, dass die Eltern-Kind-Beziehungstabellen (nach der Implementierung des Normalisierungsformulars) redundante Daten in einer Tabelle reduzieren.
Datensätze in einer Tabelle werden üblicherweise zeilenorientiert verarbeitet und sequenziell gespeichert und sind mit eindeutigen Schlüsseln stark indiziert, um das Abrufen oder Schreiben von Daten zu optimieren. Dies ist auch bei MySQL üblich, insbesondere wenn es um große Einfügungen oder viele gleichzeitige Schreibvorgänge oder Masseneinfügungen geht. Die meisten Speicher-Engines, die MariaDB unterstützt, sind für OLTP-Anwendungen anwendbar – InnoDB (die Standard-Speicher-Engine seit 10.2), XtraDB, TokuDB, MyRocks oder MyISAM/Aria.
Anwendungen wie CMS, FinTech, Web-Apps verarbeiten oft viele Schreib- und Lesevorgänge und erfordern oft einen hohen Durchsatz. Um diese Anwendungen zum Laufen zu bringen, ist oft umfassendes Fachwissen in den Bereichen Hochverfügbarkeit, Redundanz, Belastbarkeit und Wiederherstellung erforderlich.
OLAP
OLAP bewältigt die gleichen Herausforderungen wie OLTP, verwendet jedoch einen anderen Ansatz (insbesondere beim Datenabruf). OLAP befasst sich mit größeren Datensätzen und wird häufig für Data Warehousing verwendet, das häufig für Business-Intelligence-Anwendungen verwendet wird. Es wird häufig für Business Performance Management, Planung, Budgetierung, Prognosen, Finanzberichte, Analysen, Simulationsmodelle, Wissensermittlung und Data Warehouse-Berichte verwendet.
In OLAP gespeicherte Daten sind in der Regel nicht so kritisch wie die in OLTP gespeicherten. Denn die meisten Daten können aus OLTP kommend simuliert und dann in Ihre OLAP-Datenbank eingespeist werden. Diese Daten werden in der Regel für das Massenladen verwendet, das häufig für Geschäftsanalysen benötigt wird, die schließlich in visuelle Diagramme gerendert werden. OLAP führt auch multidimensionale Analysen von Geschäftsdaten durch und liefert Ergebnisse, die für komplexe Berechnungen, Trendanalysen oder anspruchsvolle Datenmodellierung verwendet werden können.
OLAP speichert Daten normalerweise dauerhaft in einem Spaltenformat. In MariaDB ColumnStore werden die Datensätze jedoch anhand ihrer Spalten aufgeschlüsselt und separat in einer Datei gespeichert. Auf diese Weise ist der Datenabruf sehr effizient, da nur die relevante Spalte gescannt wird, auf die in Ihrer SELECT-Anweisungsabfrage verwiesen wird.
Stellen Sie sich das so vor:Die OLTP-Verarbeitung verarbeitet Ihre täglichen und wichtigen Datentransaktionen, die Ihre Geschäftsanwendung ausführen, während OLAP Ihnen hilft, Ihr Produkt zu verwalten, vorherzusagen, zu analysieren und besser zu vermarkten – die Bausteine einer Geschäftsanwendung.
Was ist MariaDB ColumnStore?
MariaDB ColumnStore ist eine austauschbare spaltenbasierte Speicher-Engine, die auf MariaDB Server ausgeführt wird. Es nutzt eine parallel verteilte Datenarchitektur und behält dabei dieselbe ANSI-SQL-Schnittstelle bei, die im gesamten MariaDB-Serverportfolio verwendet wird. Diese Speicher-Engine gibt es schon seit einiger Zeit, da sie ursprünglich von InfiniDB portiert wurde (ein inzwischen nicht mehr existierender Code, der immer noch auf Github verfügbar ist). -Zeitantwort auf Analyseabfragen. Es nutzt die I/O-Vorteile von Columnar Storage; Komprimierung, Just-in-Time-Projektion und horizontale und vertikale Partitionierung für eine enorme Leistung bei der Analyse großer Datensätze.
Schließlich ist MariaDB ColumnStore das Rückgrat ihres MariaDB AX-Produkts als Hauptspeicher-Engine, die von dieser Technologie verwendet wird.
Wie unterscheidet sich MariaDB ColumnStore von InnoDB?
InnoDB eignet sich für die OLTP-Verarbeitung, bei der Ihre Anwendung so schnell wie möglich reagieren muss. Es ist nützlich, wenn sich Ihre Anwendung mit dieser Art befasst. Andererseits ist MariaDB ColumnStore eine geeignete Wahl für die Verwaltung von Big-Data-Transaktionen oder großen Datensätzen, die komplexe Verknüpfungen, Aggregation auf verschiedenen Ebenen der Dimensionshierarchie, die Projektion einer Finanzsumme für eine Vielzahl von Jahren oder die Verwendung von Gleichheits- und Bereichsauswahlen beinhalten . Bei diesen Ansätzen mit ColumnStore müssen Sie diese Felder nicht indizieren, da sie ausreichend schneller ausgeführt werden können. InnoDB kann diese Art von Leistung nicht wirklich bewältigen, obwohl es Sie nicht davon abhält, dies zu versuchen, wie es mit InnoDB möglich ist, aber zu einem Preis. Dazu müssen Sie Indizes hinzufügen, wodurch große Datenmengen zu Ihrem Plattenspeicher hinzugefügt werden. Das bedeutet, dass es mehr Zeit in Anspruch nehmen kann, Ihre Abfrage zu beenden, und dass sie möglicherweise überhaupt nicht beendet wird, wenn sie in einer Zeitschleife gefangen ist.
MariaDB ColumnStore-Architektur
Sehen wir uns unten die Architektur von MariaDB ColumStore an:
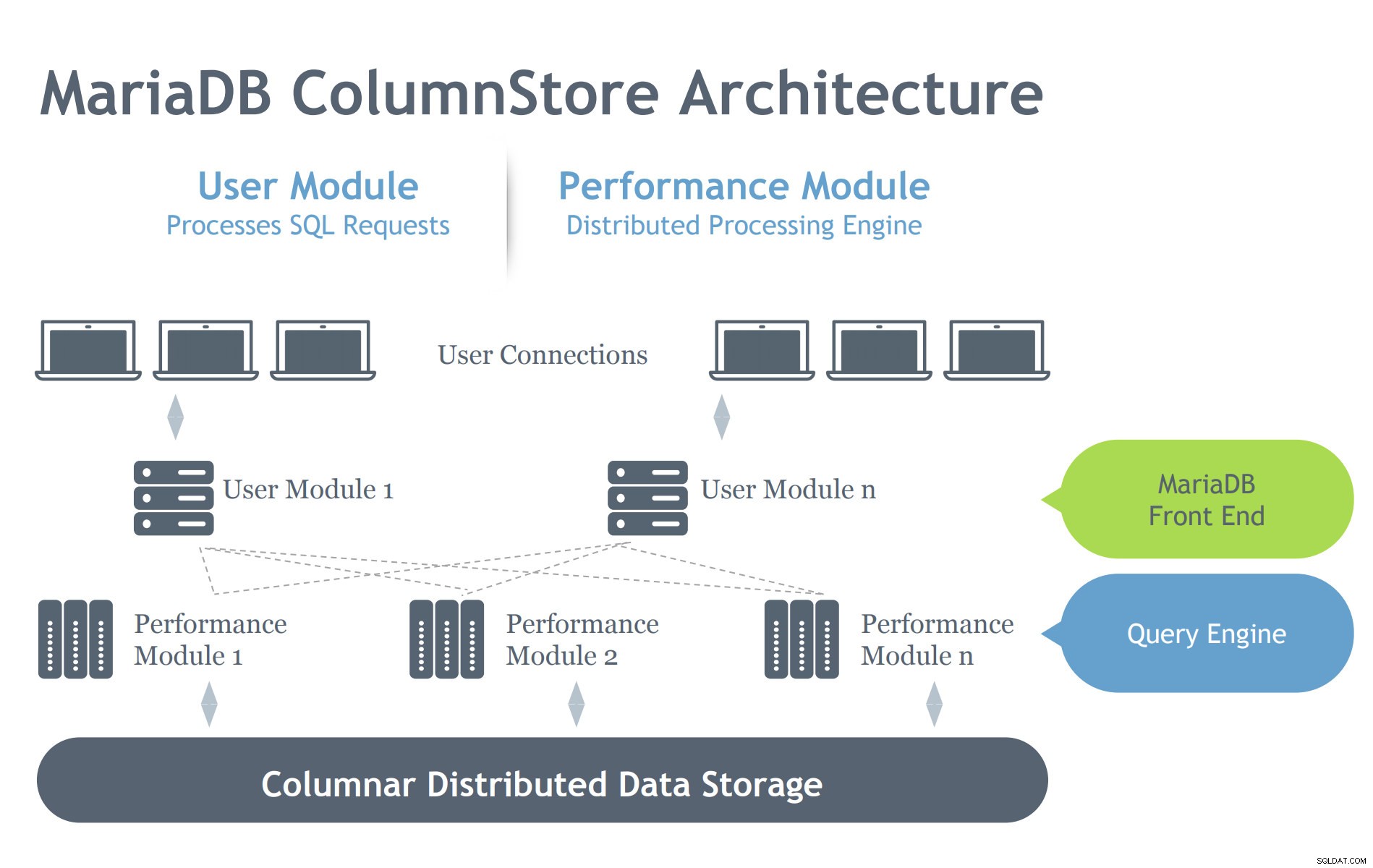 Bild mit freundlicher Genehmigung der MariaDB ColumnStore-Präsentation
Bild mit freundlicher Genehmigung der MariaDB ColumnStore-Präsentation Im Gegensatz zur InnoDB-Architektur enthält der ColumnStore zwei Module, was darauf hinweist, dass er effizient in einer verteilten Architekturumgebung arbeiten soll. InnoDB soll auf einem Server skaliert werden, erstreckt sich jedoch je nach Cluster-Setup auf mehrere miteinander verbundene Knoten. Daher verfügt ColumnStore über mehrere Ebenen von Komponenten, die sich um die vom MariaDB-Server angeforderten Prozesse kümmern. Lassen Sie uns unten auf diese Komponenten eingehen:
- Benutzermodul (UM):Das UM ist verantwortlich für das Parsen der SQL-Anforderungen in einen optimierten Satz primitiver Jobschritte, die von einem oder mehreren PM-Servern ausgeführt werden. Der UM ist somit für die Abfrageoptimierung und Orchestrierung der Abfrageausführung durch die PM-Server verantwortlich. Während mehrere UM-Instanzen in einer Bereitstellung mit mehreren Servern bereitgestellt werden können, ist ein einziger UM für jede einzelne Abfrage verantwortlich. Ein Datenbank-Load-Balancer wie MariaDB MaxScale kann bereitgestellt werden, um externe Anforderungen angemessen auf einzelne UM-Server auszugleichen.
- Leistungsmodul (PM):Das PM führt granulare Jobschritte aus, die von einem UM in einer Multithread-Weise empfangen werden. ColumnStore ermöglicht die Verteilung der Arbeit auf viele Leistungsmodule. Das UM besteht aus dem MariaDB mysqld-Prozess und dem ExeMgr-Prozess.
- Extent Maps:ColumnStore verwaltet Metadaten zu jeder Spalte in einem gemeinsam genutzten verteilten Objekt, das als Extent Map bezeichnet wird. Der UM-Server verweist auf die Extent Map, um beim Generieren der richtigen primitiven Auftragsschritte zu helfen. Der PM-Server referenziert die Extent Map, um die richtigen zu lesenden Plattenblöcke zu identifizieren. Jede Spalte besteht aus einer oder mehreren Dateien und jede Datei kann mehrere Extents enthalten. Das System versucht so weit wie möglich, zusammenhängenden physischen Speicher zuzuweisen, um die Leseleistung zu verbessern.
- Speicher:ColumnStore kann entweder lokalen Speicher oder gemeinsam genutzten Speicher (z. B. SAN oder EBS) zum Speichern von Daten verwenden. Durch die Verwendung von gemeinsam genutztem Speicher kann die Datenverarbeitung automatisch auf einen anderen Knoten umgeschaltet werden, falls ein PM-Server ausfällt.
Unten sehen Sie, wie MariaDB ColumnStore die Abfrage verarbeitet,
- Clients senden eine Anfrage an den MariaDB-Server, der auf dem Benutzermodul läuft. Der Server führt eine Tabellenoperation für alle Tabellen durch, die zum Erfüllen der Anforderung erforderlich sind, und erhält den anfänglichen Abfrageausführungsplan.
- Unter Verwendung der MariaDB-Speicher-Engine-Schnittstelle konvertiert ColumnStore das Servertabellenobjekt in ColumnStore-Objekte. Diese Objekte werden dann an die Benutzermodulprozesse gesendet.
- Das Benutzermodul konvertiert den MariaDB-Ausführungsplan und optimiert die angegebenen Objekte in einen ColumnStore-Ausführungsplan. Anschließend bestimmt es die Schritte, die zum Ausführen der Abfrage erforderlich sind, und die Reihenfolge, in der sie ausgeführt werden müssen.
- Das Benutzermodul konsultiert dann die Extent Map, um zu bestimmen, welche Leistungsmodule für die benötigten Daten konsultiert werden sollen, führt dann eine Extent-Eliminierung durch und eliminiert alle Leistungsmodule aus der Liste, die nur Daten außerhalb des für die Abfrage erforderlichen Bereichs enthalten.
- Das Benutzermodul sendet dann Befehle an ein oder mehrere Performance-Module, um Block-I/O-Operationen auszuführen.
- Das Leistungsmodul oder die Leistungsmodule führen Prädikatenfilterung, Join-Verarbeitung, anfängliche Aggregation von Daten aus lokalen oder externen Speichern durch und senden die Daten dann zurück an das Benutzermodul.
- Das Benutzermodul führt die endgültige Aggregation der Ergebnismenge durch und stellt die Ergebnismenge für die Abfrage zusammen.
- Das Benutzermodul / ExeMgr implementiert alle Fensterfunktionsberechnungen sowie alle notwendigen Sortierungen der Ergebnismenge. Es gibt dann die Ergebnismenge an den Server zurück.
- Der MariaDB-Server führt alle Auswahllistenfunktionen, ORDER BY- und LIMIT-Operationen auf der Ergebnismenge aus.
- Der MariaDB-Server gibt die Ergebnismenge an den Client zurück.
Abfrageausführungsparadigmen
Sehen wir uns ein bisschen genauer an, wie ColumnStore die Abfrage ausführt und wann sie sich auswirkt.
ColumnStore unterscheidet sich von den standardmäßigen MySQL/MariaDB-Speicher-Engines wie InnoDB, da ColumnStore an Leistung gewinnt, indem es nur die erforderlichen Spalten scannt, vom System verwaltete Partitionierung verwendet und mehrere Threads und Server verwendet, um die Antwortzeit für Abfragen zu skalieren. Die Leistung wird verbessert, wenn Sie nur Spalten einbeziehen, die für Ihren Datenabruf erforderlich sind. Das bedeutet, dass das gierige Sternchen (*) in Ihrer Auswahlabfrage im Vergleich zu SELECT
Genau wie bei InnoDB und anderen Speicher-Engines hat der Datentyp auch eine Bedeutung für die Leistung in Bezug auf das, was Sie verwendet haben. Wenn Sie beispielsweise eine Spalte haben, die nur Werte von 0 bis 100 haben kann, dann deklarieren Sie dies als Tinyint, da dies mit 1 Byte anstelle von 4 Bytes für int dargestellt wird. Dadurch werden die E/A-Kosten um das Vierfache reduziert. Für String-Typen ist char(9) und varchar(8) oder größer ein wichtiger Schwellenwert. Jede Spaltenspeicherdatei verwendet eine feste Anzahl von Bytes pro Wert. Dies ermöglicht eine schnelle Positionssuche nach anderen Spalten, um die Zeile zu bilden. Derzeit liegt die Obergrenze für die spaltenweise Datenspeicherung bei 8 Bytes. Für längere Zeichenfolgen verwaltet das System also einen zusätzlichen „Wörterbuch“-Extent, in dem die Werte gespeichert werden. Die spaltenförmige Erweiterungsdatei speichert dann einen Zeiger in das Wörterbuch. Daher ist es beispielsweise teurer, eine varchar(8)-Spalte zu lesen und zu verarbeiten als eine char(8)-Spalte. Wenn Sie also kürzere Zeichenfolgen verwenden können, erzielen Sie nach Möglichkeit eine bessere Leistung, insbesondere wenn Sie die Wörterbuchsuche vermeiden. Alle TEXT/BLOB-Datentypen ab 1.1 verwenden ein Wörterbuch und führen bei Bedarf eine 8-KB-Mehrfachblocksuche durch, um diese Daten abzurufen. Je länger die Daten, desto mehr Blöcke werden abgerufen und desto größer ist die potenzielle Auswirkung auf die Leistung.
In einem zeilenbasierten System trägt das Hinzufügen redundanter Spalten zu den Gesamtabfragekosten bei, aber in einem spaltenbasierten System entstehen Kosten nur, wenn auf die Spalte verwiesen wird. Daher sollten zusätzliche Spalten erstellt werden, um unterschiedliche Zugriffspfade zu unterstützen. Speichern Sie beispielsweise einen führenden Teil eines Felds in einer Spalte, um eine schnellere Suche zu ermöglichen, aber speichern Sie zusätzlich den Langformwert als eine andere Spalte. Scans auf einer kürzeren Code- oder führenden Teilspalte werden schneller sein.
Abfrage-Joins sind optimiert, bereit für große Joins und vermeiden die Notwendigkeit von Indizes und den Overhead der Nested-Loop-Verarbeitung. ColumnStore verwaltet Tabellenstatistiken, um die optimale Join-Reihenfolge zu bestimmen. Ähnliche Ansätze gibt es bei InnoDB, wenn der Join zu groß für den UM-Speicher ist, wird ein festplattenbasierter Join verwendet, um die Abfrage zu vervollständigen.
Bei Aggregationen verteilt ColumnStore die aggregierte Auswertung so weit wie möglich. Dies bedeutet, dass es über UM und PM verteilt ist, um insbesondere Abfragen oder eine sehr große Anzahl von Werten in der/den aggregierten Spalte(n) zu verarbeiten. Select count(*) ist intern optimiert, um die geringste Anzahl von Bytespeicher in einer Tabelle auszuwählen. Dies bedeutet, dass die CHAR(1)-Spalte (verwendet 1 Byte) über der INT-Spalte ausgewählt wird, die 4 Bytes benötigt. Die Implementierung berücksichtigt nach wie vor die ANSI-Semantik, da select count(*) Nullen in die Gesamtzahl einschließt, im Gegensatz zu einem expliziten select(COL-N), das Nullen in der Zählung ausschließt.
Order by und Limit werden derzeit ganz am Ende vom mariadb-Serverprozess in der temporären Ergebnissatztabelle implementiert. Dies wurde in Schritt 9 zur Verarbeitung der Abfrage durch ColumnStore erwähnt. Technisch gesehen werden die Ergebnisse zum Sortieren der Daten an MariaDB Server übergeben.
Für komplexe Abfragen, die Unterabfragen verwenden, ist es im Grunde der gleiche Ansatz, bei dem sie nacheinander ausgeführt und von UM verwaltet werden, genauso wie bei Windows-Funktionen, die von UM verarbeitet werden, aber es verwendet einen dedizierten schnelleren Sortierprozess, also ist es im Grunde schneller.
Die Partitionierung Ihrer Daten wird von ColumnStore bereitgestellt, das Extent Maps verwendet, das die Min/Max-Werte der Spaltendaten beibehält und einen logischen Bereich für die Partitionierung bereitstellt und die Notwendigkeit einer Indizierung beseitigt. Extent Maps bietet auch manuelle Tabellenpartitionierung, materialisierte Ansichten, Übersichtstabellen und andere Strukturen und Objekte, die zeilenbasierte Datenbanken für die Abfrageleistung implementieren müssen. Es gibt bestimmte Vorteile für Spaltenwerte, wenn sie geordnet oder halbgeordnet sind, da dies eine sehr effektive Datenpartitionierung ermöglicht. Bei Min- und Max-Werten werden ganze Ausdehnungskarten nach dem Filter und Ausschluss eliminiert. Siehe diese Seite in ihrem Handbuch über Extent Elimination. Dies funktioniert im Allgemeinen besonders gut für Zeitreihendaten oder ähnliche Werte, die im Laufe der Zeit ansteigen.
Installieren des MariaDB ColumnStore
Die Installation des MariaDB ColumnStore kann einfach und unkompliziert sein. MariaDB hat hier eine Reihe von Notizen, auf die Sie sich beziehen können. Für diesen Blog ist unsere Installationszielumgebung CentOS 7. Sie können zu diesem Link https://downloads.mariadb.com/ColumnStore/1.2.4/ gehen und die Pakete basierend auf Ihrer Betriebssystemumgebung auschecken. Sehen Sie sich die detaillierten Schritte unten an, um Ihnen dabei zu helfen, schneller zu werden:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Anschließend müssen Sie postConfigure ausführen Befehl, um Ihren MariaDB ColumnStore endgültig zu installieren und einzurichten. In dieser Beispielinstallation gibt es zwei Knoten, die ich eingerichtet habe und die auf einem vagabundierenden Computer ausgeführt werden:
csnode1:192.168.2.10
csnode2:192.168.2.20
Diese beiden Knoten sind in ihren jeweiligen /etc/hosts definiert und beide Knoten sind so eingestellt, dass ihre Benutzer- und Leistungsmodule in beiden Hosts kombiniert werden. Die Installation ist zunächst etwas trivial. Daher teilen wir Ihnen mit, wie Sie es konfigurieren können, damit Sie eine Grundlage haben. Sehen Sie sich die Details unten für den beispielhaften Installationsprozess an:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Sobald die Installation und Einrichtung abgeschlossen ist, erstellt MariaDB dafür ein Master/Slave-Setup, sodass alles, was wir von csnode1 geladen haben, auf csnode2 repliziert wird.
Speichern Sie Ihre Big Data
Nach der Installation haben Sie möglicherweise keine Beispieldaten zum Ausprobieren. IMDB hat Beispieldaten geteilt, die Sie auf ihrer Website https://www.imdb.com/interfaces/ herunterladen können. Für diesen Blog habe ich ein Skript erstellt, das alles für Sie erledigt. Schauen Sie es sich hier an https://github.com/paulnamuag/columnstore-imdb-data-load. Machen Sie es einfach ausführbar und führen Sie dann das Skript aus. Es erledigt alles für Sie, indem es die Dateien herunterlädt, das Schema erstellt und dann Daten in die Datenbank lädt. So einfach ist das.
Ausführen Ihrer Beispielabfragen
Lassen Sie uns nun versuchen, einige Beispielabfragen auszuführen.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Im Grunde geht es schneller und schneller. Es gibt Abfragen, die Sie nicht so verarbeiten können, wie Sie sie mit anderen Speicher-Engines wie InnoDB ausführen. Zum Beispiel habe ich versucht, herumzuspielen und ein paar dumme Abfragen zu machen und zu sehen, wie es reagiert und zu Folgendem führt:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Daher habe ich MCOL-1620 und MCOL-131 gefunden und es zeigt auf das Setzen der Variablen infinidb_vtable_mode. Siehe unten:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Aber das Setzen von infinidb_vtable_mode=0 , Dies bedeutet, dass die Abfrage als generischer und hochkompatibler zeilenweiser Verarbeitungsmodus behandelt wird. Einige Komponenten der WHERE-Klausel können von ColumnStore verarbeitet werden, Joins werden jedoch vollständig von mysqld unter Verwendung eines Nested-Loop-Join-Mechanismus verarbeitet. Siehe unten:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Es hat jedoch einige Zeit gedauert, da es erklärt, dass es vollständig von mysqld verarbeitet wurde. Dennoch ist das Optimieren und Schreiben guter Abfragen immer noch der beste Ansatz und delegieren nicht alles an ColumnStore.
Außerdem haben Sie Hilfe beim Analysieren Ihrer Abfragen, indem Sie Befehle wie SELECT calSetTrace(1); ausführen oder SELECT calGetStats(); . Sie können diesen Befehlssatz verwenden, um beispielsweise die niedrigen und schlechten Abfragen zu optimieren oder den Abfrageplan anzuzeigen. Weitere Einzelheiten zur Analyse der Abfragen finden Sie hier.
ColumnStore verwalten
Sobald Sie MariaDB ColumnStore vollständig eingerichtet haben, wird es mit seinem Tool namens mcsadmin ausgeliefert, mit dem Sie einige administrative Aufgaben erledigen können. Sie können dieses Tool auch verwenden, um ein weiteres Modul hinzuzufügen, DBroots zuzuweisen oder von PM zu PM zu verschieben usw. Sehen Sie sich das Handbuch zu diesem Tool an.
Grundsätzlich können Sie zum Beispiel die Systeminformationen prüfen:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Schlussfolgerung
MariaDB ColumnStore ist eine sehr leistungsfähige Speicher-Engine für Ihre OLAP- und Big-Data-Verarbeitung. Dies ist vollständig Open Source, was sehr vorteilhaft ist, anstatt proprietäre und teure OLAP-Datenbanken zu verwenden, die auf dem Markt erhältlich sind. Es gibt jedoch andere Alternativen, die Sie ausprobieren können, wie ClickHouse, Apache HBase oder cstore_fdw von Citus Data. Keines davon verwendet jedoch MySQL/MariaDB, daher ist es möglicherweise nicht Ihre praktikable Option, wenn Sie sich dafür entscheiden, die MySQL/MariaDB-Varianten beizubehalten.



