Wir haben kürzlich mehrere Blogs darüber geschrieben, wie verschiedene Cloud-Anbieter mit Datenbank-Failover umgehen. Wir haben die Failover-Leistung in Amazon Aurora, Amazon RDS und ClusterControl verglichen, das Failover-Verhalten in Amazon RDS und auch auf der Google Cloud Platform getestet. Obwohl diese Dienste großartige Optionen für Failover bieten, sind sie möglicherweise nicht für jede Anwendung geeignet.
In diesem Blogbeitrag werden wir ein wenig Zeit damit verbringen, die Vor- und Nachteile der Verwendung von DBaaS-Lösungen im Vergleich zum manuellen Entwerfen einer Umgebung oder der Verwendung einer Datenbankverwaltungsplattform wie ClusterControl zu analysieren.
Implementieren von Hochverfügbarkeitsdatenbanken mit verwalteten Lösungen
Der Hauptgrund für die Verwendung vorhandener Lösungen ist die Benutzerfreundlichkeit. Sie können mit nur wenigen Klicks eine hochverfügbare Lösung mit automatischem Failover bereitstellen. Es ist nicht erforderlich, verschiedene Tools miteinander zu kombinieren, die Datenbanken manuell zu verwalten, Tools bereitzustellen, Skripts zu schreiben, die Überwachung zu entwerfen oder andere Datenbankverwaltungsvorgänge durchzuführen. Alles ist bereits vorhanden. Dies kann die Lernkurve erheblich verkürzen und erfordert weniger Erfahrung, um eine hochverfügbare Umgebung für die Datenbanken einzurichten; so dass im Grunde jeder solche Setups bereitstellen kann.
In den meisten Fällen wird bei diesen Lösungen der Failover-Prozess innerhalb einer angemessenen Zeit ausgeführt. Es kann blitzschnell sein wie bei Amazon Aurora oder etwas langsamer wie bei Google Cloud Platform SQL-Knoten. In den meisten Fällen sind diese Arten von Ergebnissen akzeptabel.
Das Endergebnis. Wenn Sie eine Ausfallzeit von 30 bis 60 Sekunden akzeptieren können, sollten Sie mit der Verwendung einer der DBaaS-Plattformen einverstanden sein.
Der Nachteil der Verwendung einer verwalteten Lösung für HA
Während DBaaS-Lösungen einfach zu verwenden sind, haben sie auch einige schwerwiegende Nachteile. Zunächst einmal ist immer eine Vendor-Lock-in-Komponente zu berücksichtigen. Sobald Sie einen Cluster in Amazon Web Services bereitgestellt haben, ist es ziemlich schwierig, von diesem Anbieter zu migrieren. Es gibt keine einfachen Methoden, um den vollständigen Datensatz über eine physische Sicherung herunterzuladen. Bei den meisten Anbietern stehen nur manuell ausgeführte logische Backups zur Verfügung. Sicher, es gibt immer Möglichkeiten, dies zu erreichen, aber es ist normalerweise ein komplexer, zeitaufwändiger Prozess, der dennoch einige Ausfallzeiten erfordern kann.
Die Nutzung eines Anbieters wie Amazon RDS ist ebenfalls mit Einschränkungen verbunden. Einige Aktionen können nicht einfach durchgeführt werden, was in vollständig benutzergesteuerten Umgebungen (z. B. AWS EC2) sehr einfach zu bewerkstelligen wäre. Einige dieser Einschränkungen wurden bereits in anderen Blogs behandelt, aber zusammenfassend lässt sich sagen, dass Ihnen kein DBaaS-Dienst das gleiche Maß an Flexibilität bietet wie die reguläre MySQL-GTID-basierte Replikation. Sie können jeden Slave befördern, Sie können jeden Knoten von jedem anderen erneut sklaven ... praktisch jede Aktion ist möglich. Mit Tools wie RDS sind Sie mit designbedingten Einschränkungen konfrontiert, die Sie nicht umgehen können.
Das Problem liegt auch in der Fähigkeit, Leistungsdetails zu verstehen. Wenn Sie Ihr eigenes hochverfügbares Setup entwerfen, werden Sie über potenzielle Leistungsprobleme informiert, die auftreten können. Andererseits sind RDS und ähnliche Umgebungen so ziemlich „Black Boxes“. Ja, wir haben erfahren, dass Amazon RDS DRBD verwendet, um eine Schattenkopie des Masters zu erstellen, wir wissen, dass Aurora gemeinsam genutzten, replizierten Speicher verwendet, um sehr schnelle Failover zu implementieren. Das ist nur Allgemeinwissen. Wir können nicht sagen, welche Auswirkungen diese Lösungen auf die Leistung haben, außer was wir beiläufig bemerken. Welche gemeinsamen Probleme sind damit verbunden? Wie stabil sind diese Lösungen? Nur die Entwickler hinter der Lösung wissen es genau.
Was ist die Alternative zu DBaaS-Lösungen?
Sie fragen sich vielleicht, gibt es eine Alternative zu DBaaS? Schließlich ist es so bequem, den verwalteten Dienst auszuführen, bei dem Sie über die Benutzeroberfläche auf die meisten typischen Aktionen zugreifen können. Sie können Backups erstellen und wiederherstellen, Failover wird automatisch für Sie gehandhabt. Die Umgebung ist benutzerfreundlich, was für Unternehmen überzeugend sein kann, die nicht über engagierte und erfahrene Mitarbeiter für den Umgang mit Datenbanken verfügen.
ClusterControl bietet eine großartige Alternative zu Cloud-basierten DBaaS-Diensten. Es bietet Ihnen eine grafische Benutzeroberfläche, die zum Bereitstellen, Verwalten und Überwachen von Open-Source-Datenbanken verwendet werden kann.
Mit wenigen Klicks können Sie ganz einfach einen hochverfügbaren Datenbank-Cluster bereitstellen, mit automatischem Failover (schneller als die meisten DBaaS-Angebote), Sicherungsverwaltung, erweiterte Überwachung und andere Funktionen wie die Integration mit externen Tools (z. B. Slack oder PagerDuty) oder Upgrade-Management. All dies unter vollständiger Vermeidung von Vendor Lock-in.
ClusterControl ist es egal, wo sich Ihre Datenbanken befinden, solange es sich per SSH mit ihnen verbinden kann. Sie können Setups in der Cloud, lokal oder in einer gemischten Umgebung mit mehreren Cloud-Anbietern haben. Solange die Konnektivität besteht, kann ClusterControl die Umgebung verwalten. Indem Sie die gewünschten Lösungen verwenden (und nicht die, die Sie nicht kennen oder kennen), können Sie jederzeit die volle Kontrolle über die Umgebung übernehmen.
Welches Setup Sie auch immer mit ClusterControl bereitgestellt haben, Sie können es ganz einfach auf traditionellere, manuelle oder skriptbasierte Weise verwalten. ClusterControl bietet Ihnen sogar eine Befehlszeilenschnittstelle, mit der Sie von ClusterControl ausgeführte Aufgaben in Ihre Shell-Skripte integrieren können. Sie haben die volle Kontrolle, die Sie wollen – nichts ist eine Blackbox, jeder Teil der Umgebung würde mithilfe von Open-Source-Lösungen erstellt, die miteinander kombiniert und von ClusterControl bereitgestellt werden.
Lassen Sie uns einen Blick darauf werfen, wie einfach Sie einen MySQL-Replikationscluster mit ClusterControl bereitstellen können. Nehmen wir an, Sie haben die Umgebung vorbereitet, indem ClusterControl auf einer Instanz installiert ist und alle anderen Knoten über SSH vom ClusterControl-Host aus zugänglich sind.
Wir beginnen mit der Auswahl des „Bereitstellungs“-Assistenten.
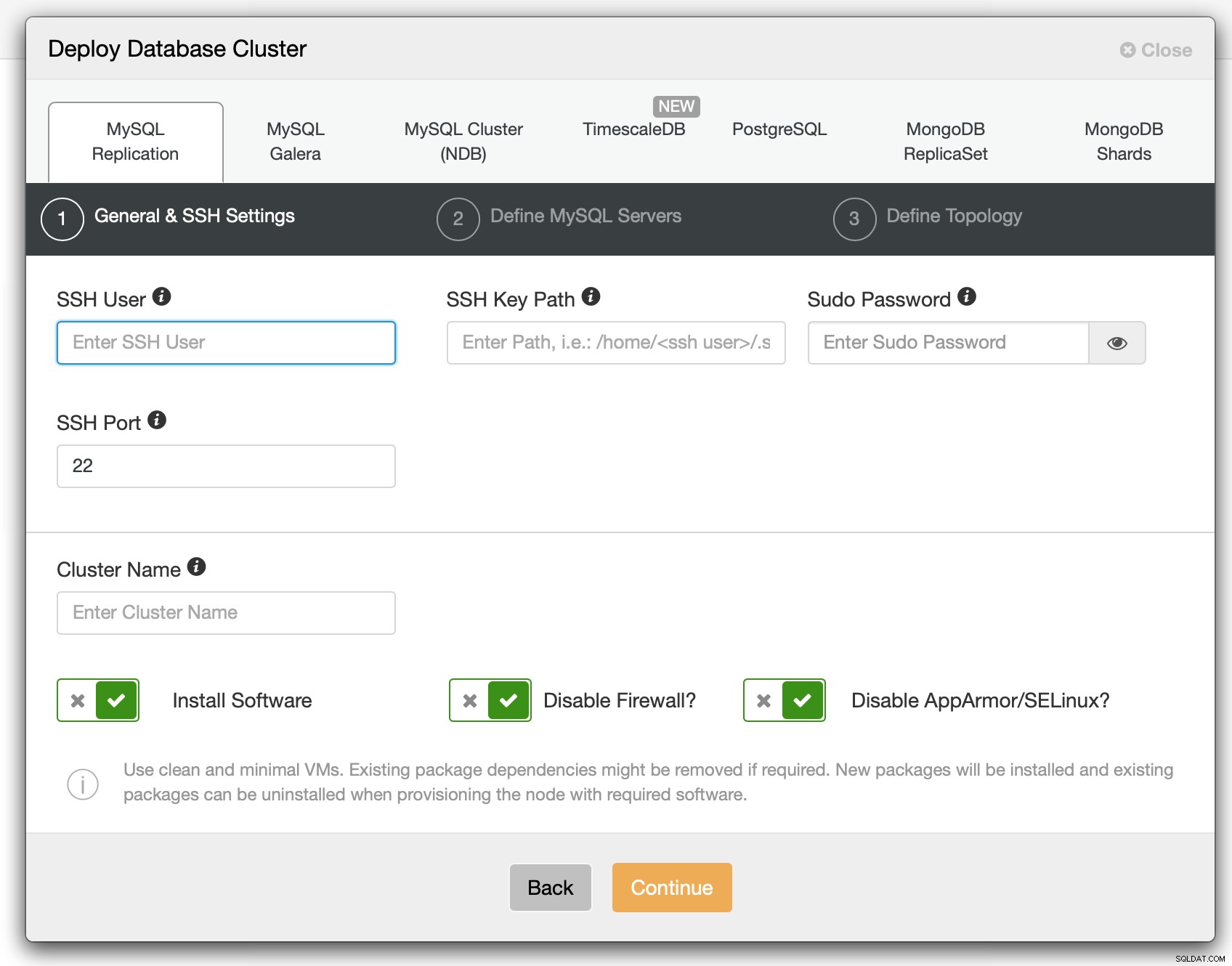
Im ersten Schritt müssen wir definieren, wie sich ClusterControl mit den Knoten verbinden soll auf welchen Datenbanken bereitgestellt werden sollen. Sowohl Root-Zugriff als auch sudo (mit oder ohne Passwort) werden unterstützt.
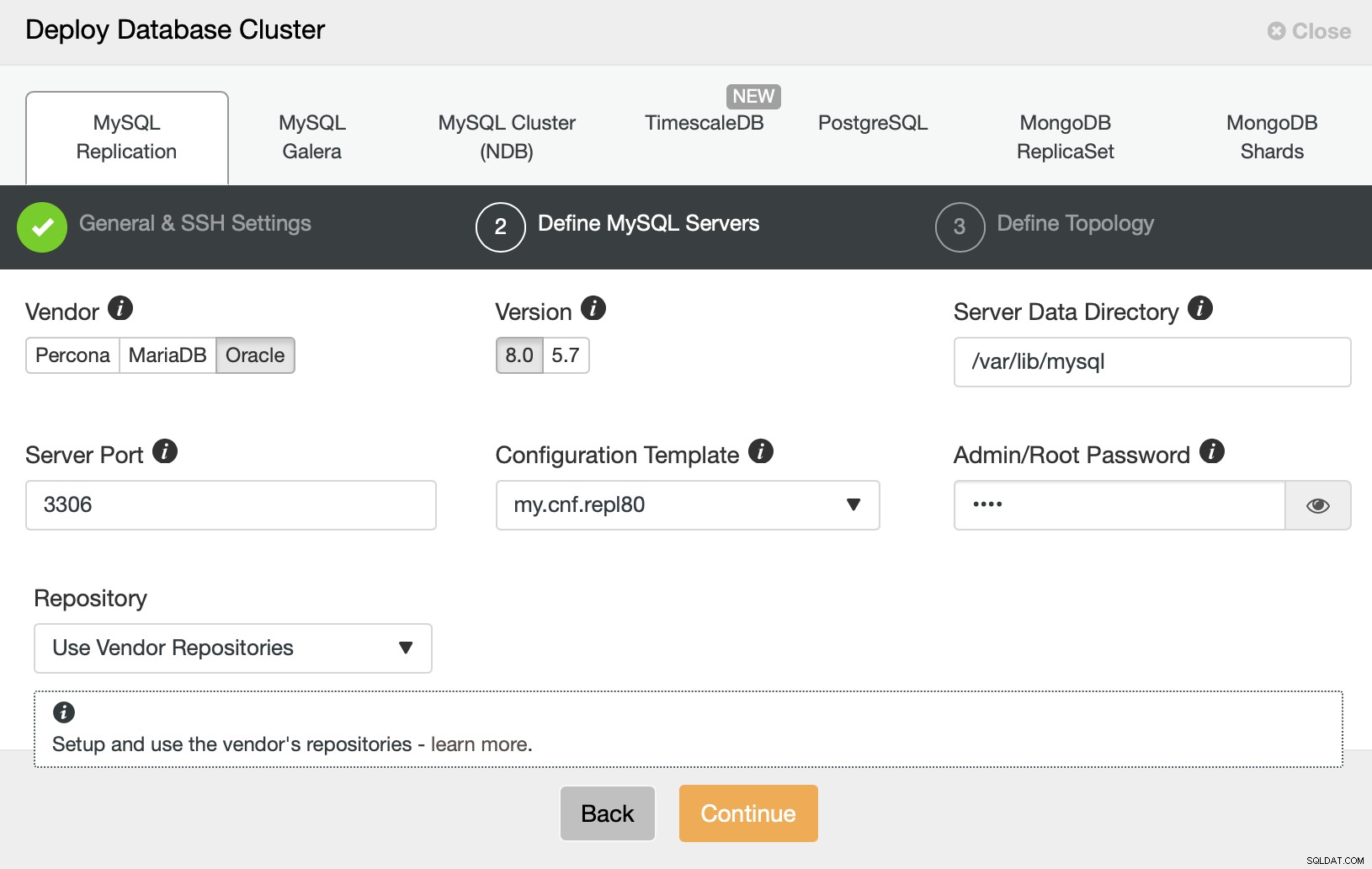
Dann möchten wir einen Anbieter und eine Version auswählen und das Passwort dafür übergeben der administrative Benutzer in unserer MySQL-Datenbank.
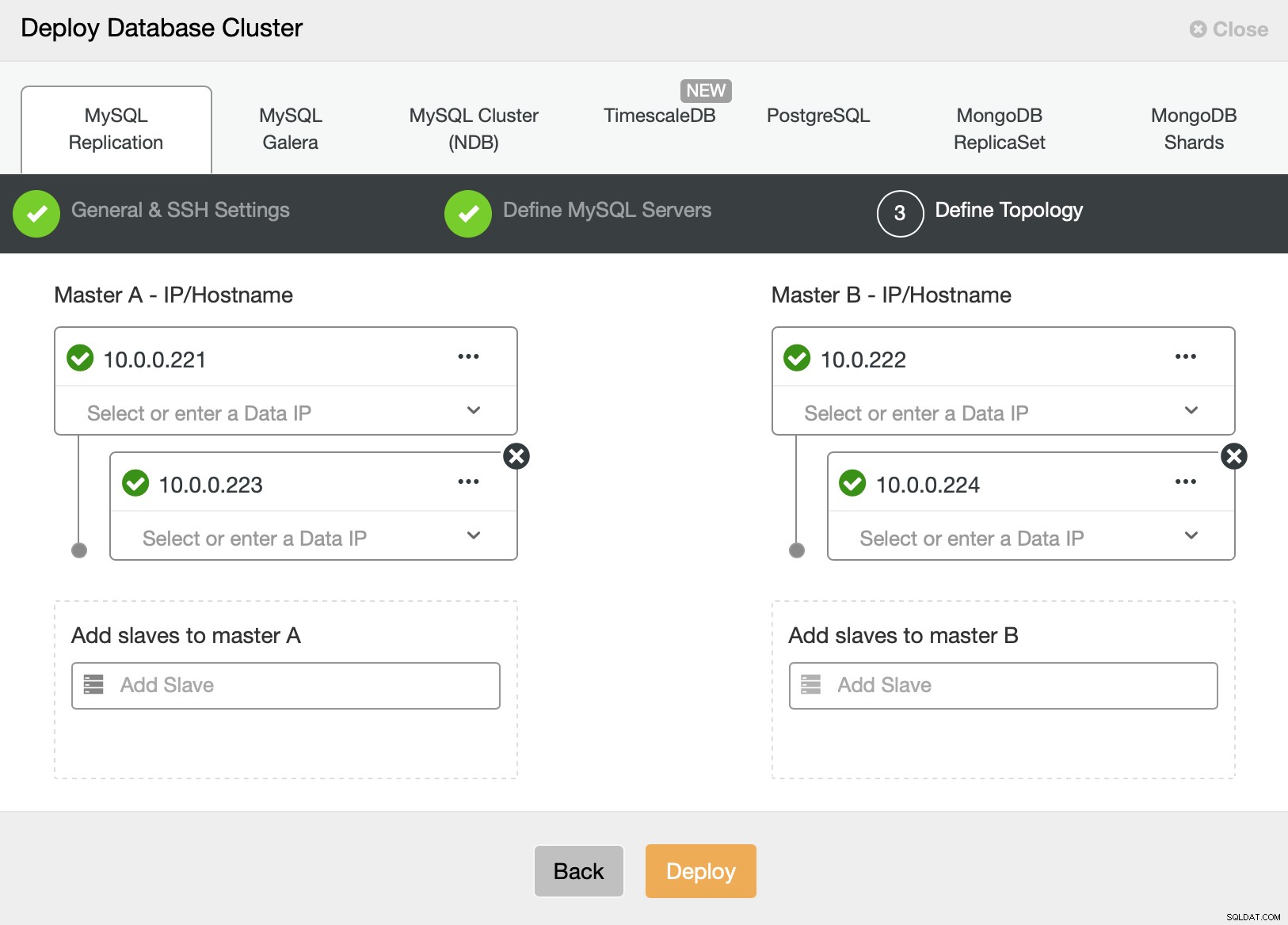
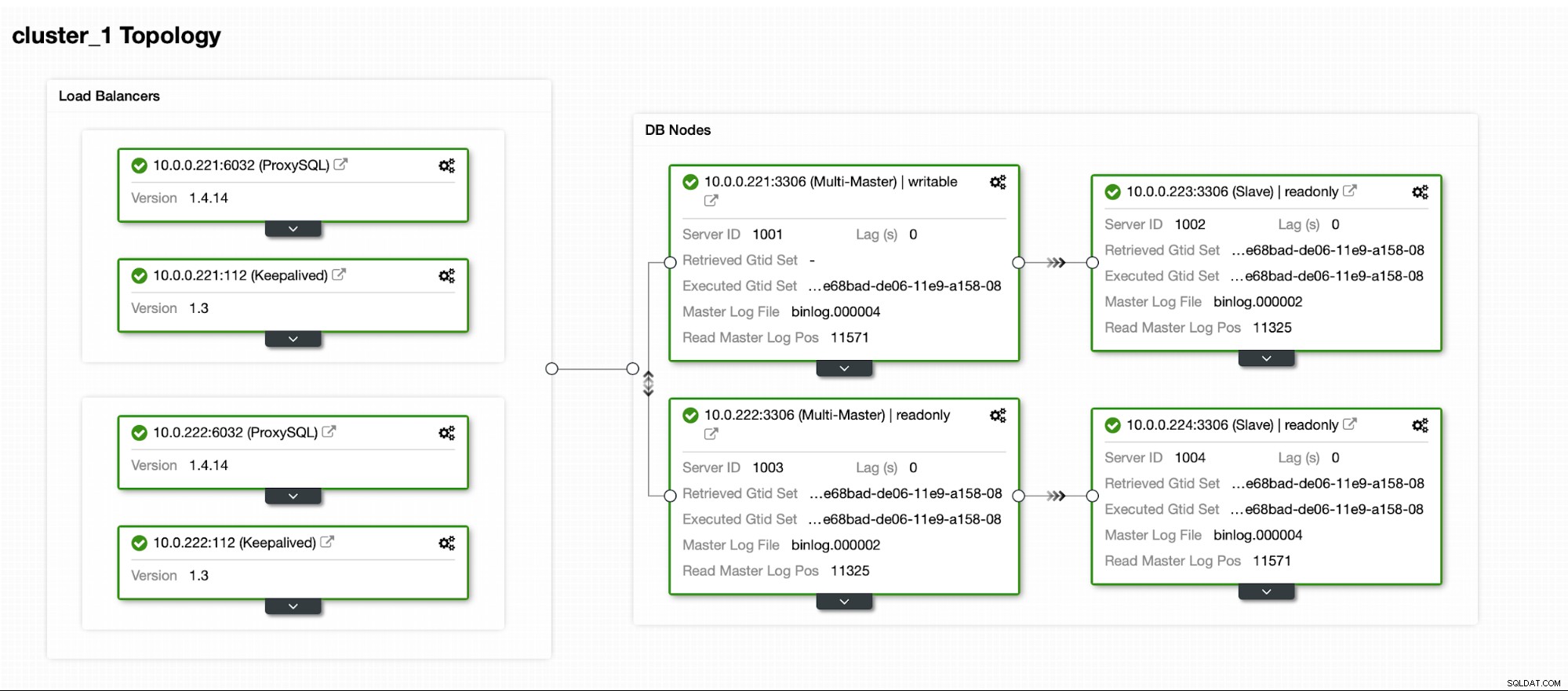
Schließlich wollen wir die Topologie für unseren neuen Cluster definieren. Wie Sie sehen können, ist dies bereits eine ziemlich komplexe Einrichtung, im Gegensatz zu etwas, das Sie mit AWS RDS oder GCP SQL-Knoten bereitstellen können.
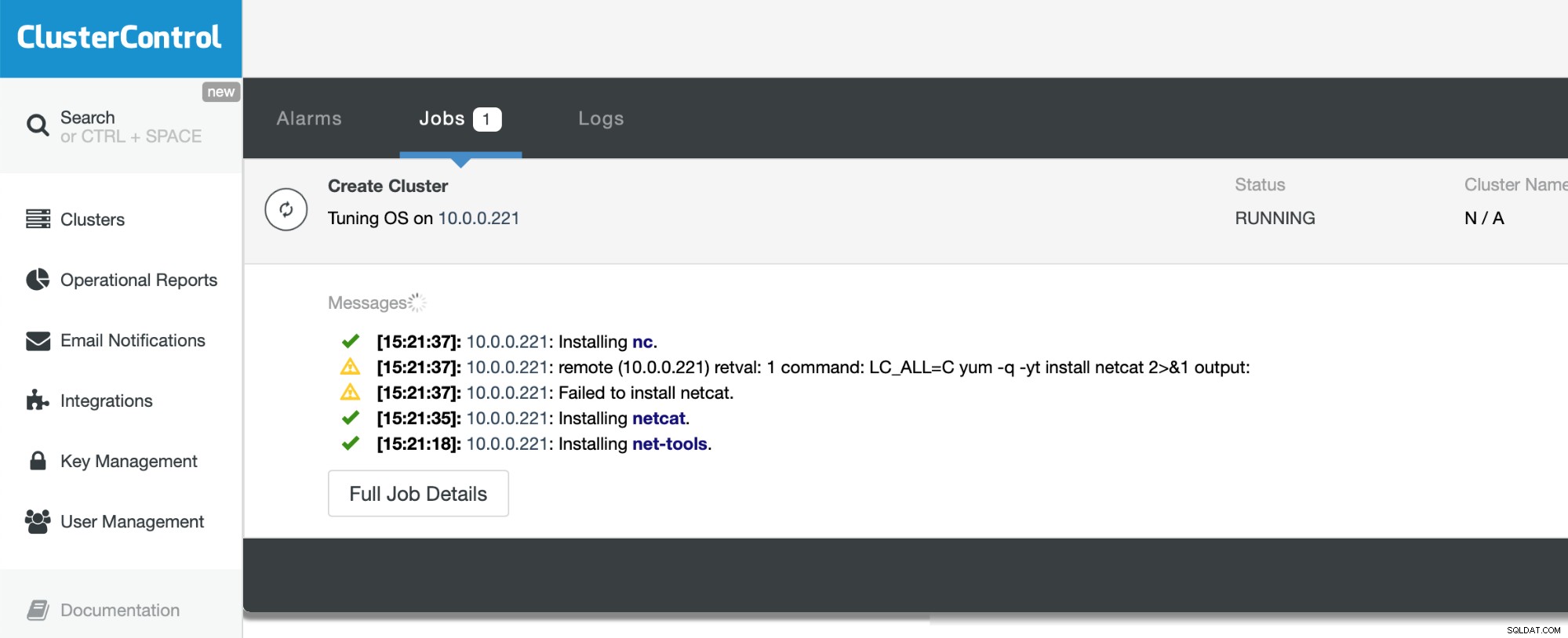
Jetzt müssen wir nur noch warten, bis der Vorgang abgeschlossen ist. ClusterControl wird sein Bestes tun, um die Umgebung zu verstehen, in der es bereitgestellt wird, und die erforderlichen Pakete, einschließlich der Datenbank selbst, zu installieren.

Sobald der Cluster betriebsbereit ist, können Sie mit der Bereitstellung fortfahren die Proxy-Schicht (die Ihrer Anwendung einen einzigen Einstiegspunkt in die Datenbankschicht bietet). Dies geschieht mehr oder weniger hinter den Kulissen von DBaaS, wo Sie auch Endpunkte haben, um sich mit dem Datenbankcluster zu verbinden. Es ist durchaus üblich, einen einzelnen Endpunkt für Schreibvorgänge und mehrere Endpunkte zum Erreichen bestimmter Replikate zu verwenden.
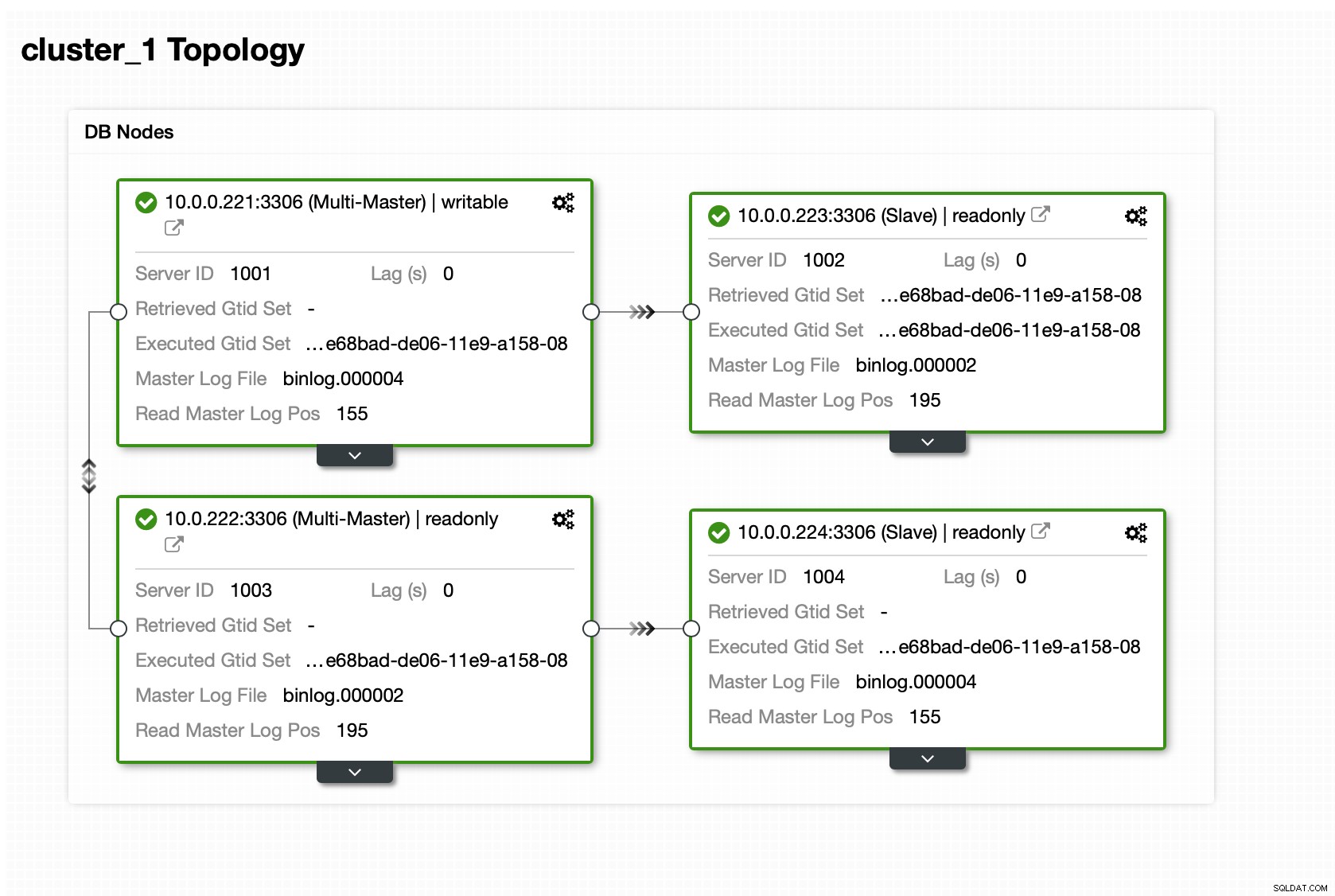
Hier verwenden wir ProxySQL, das die Drecksarbeit für uns erledigt - Es versteht die Topologie, sendet Schreibvorgänge nur an den Master und verteilt schreibgeschützte Abfragen über alle Replikate, die wir haben.
Um ProxySQL bereitzustellen, gehen wir zu Manage -> Load Balancers.
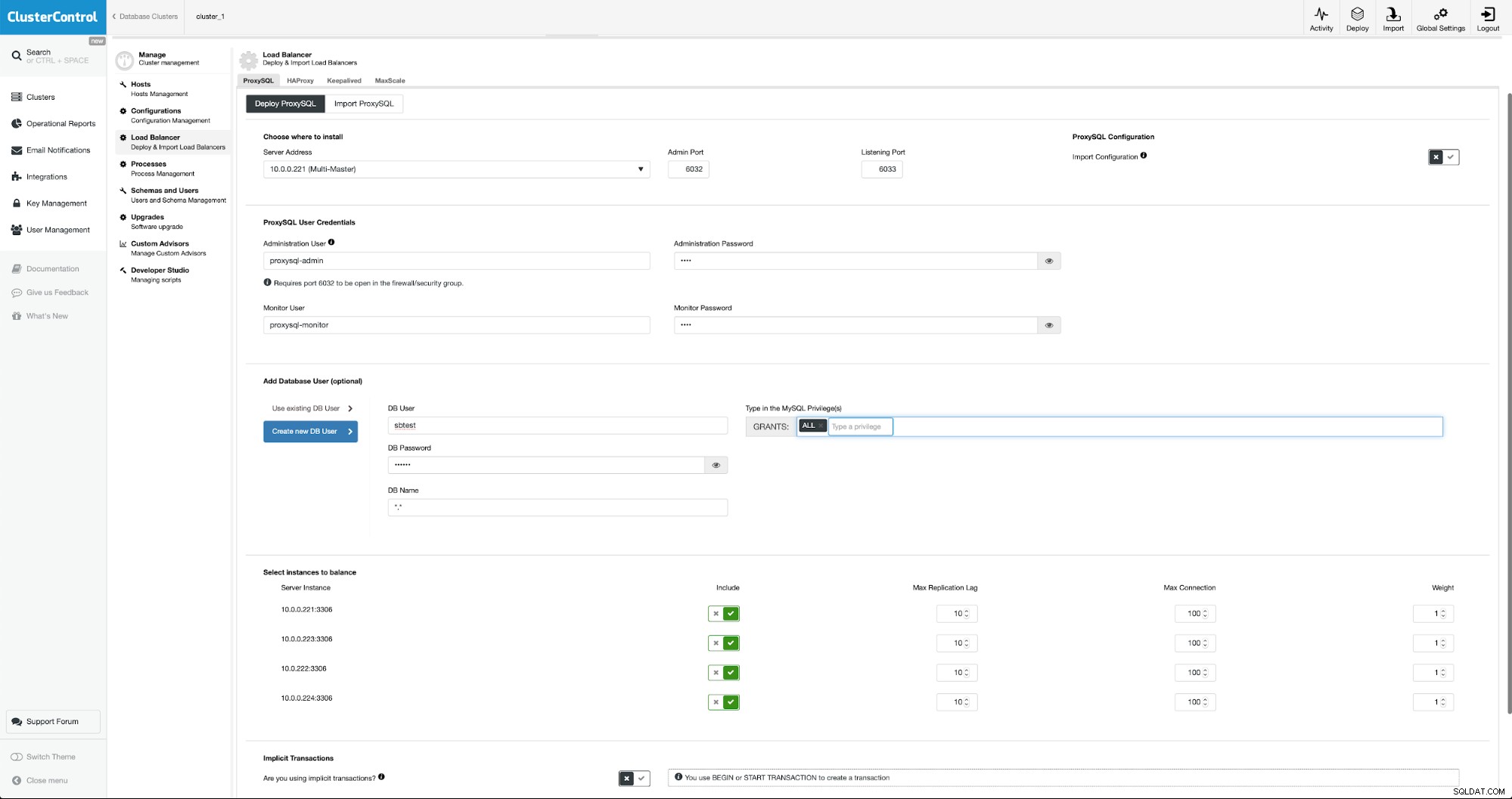
Wir müssen alle erforderlichen Felder ausfüllen:Hosts für die Bereitstellung, Anmeldeinformationen für der administrative und überwachende Benutzer, wir können bestehende Benutzer aus MySQL in ProxySQL importieren oder einen neuen erstellen. Alle Details zu ProxySQL finden Sie leicht in mehreren Blogs in unserem Blog-Bereich.
Wir möchten, dass mindestens zwei ProxySQL-Knoten bereitgestellt werden, um Hochverfügbarkeit zu gewährleisten. Sobald sie bereitgestellt sind, werden wir Keepalived zusätzlich zu ProxySQL bereitstellen. Dadurch wird sichergestellt, dass die virtuelle IP konfiguriert wird und auf eine der ProxySQL-Instanzen verweist, solange mindestens ein fehlerfreier Knoten vorhanden ist.
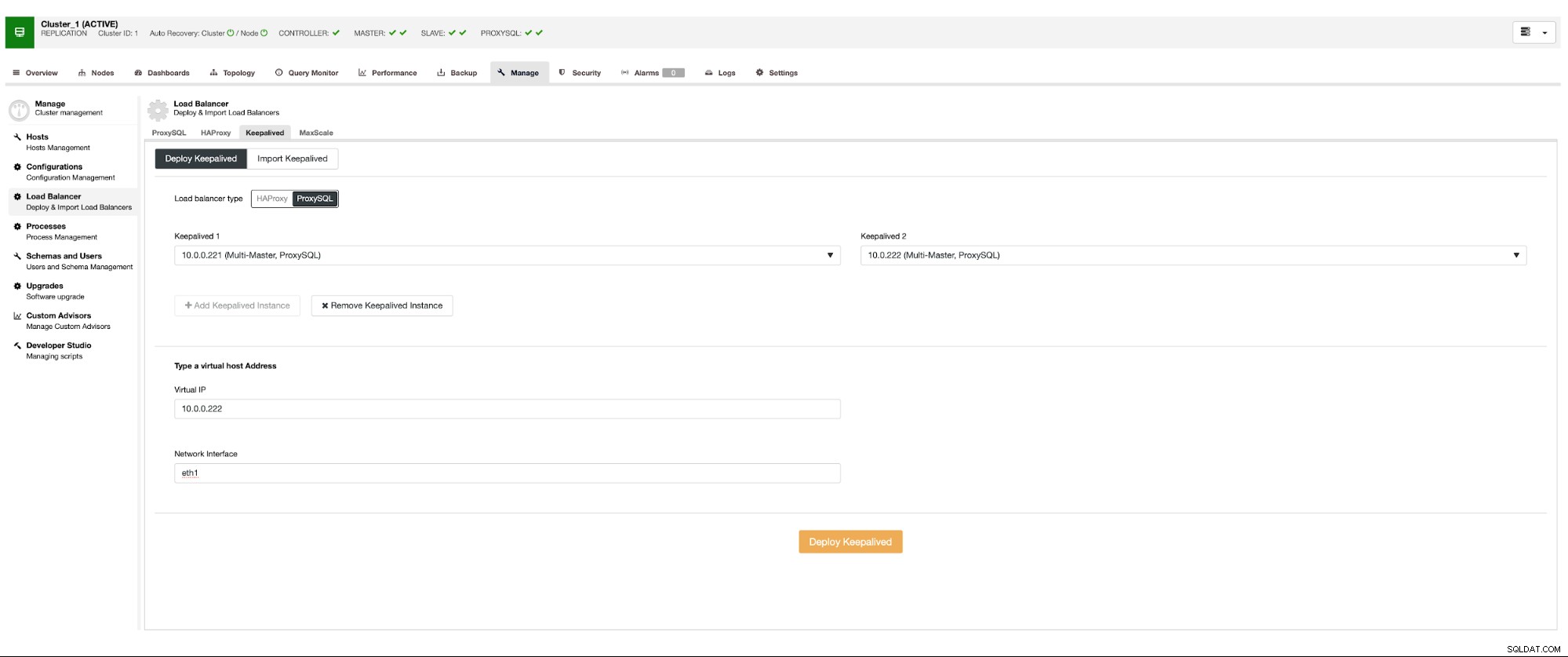
Hier ist das einzige potenzielle Problem, wenn Sie sich für Cloud-Umgebungen entscheiden, in denen das Routing funktioniert in einer Weise, dass Sie nicht einfach eine Netzwerkschnittstelle aufrufen können. In einem solchen Fall müssen Sie die Konfiguration von Keepalived ändern, das Skript „notify_master“ einführen und ein Skript verwenden, das die erforderlichen IP-Änderungen vornimmt – im Fall von EC2 müsste es Elastic IP von einem Host trennen und an den anhängen anderer Wirt.
Es gibt viele Anleitungen dazu, wie man dies mit weithin getesteter Open-Source-Software in von ClusterControl bereitgestellten Setups macht. Sie können leicht zusätzliche Informationen, Tipps und Anleitungen finden, die für Ihre spezielle Umgebung relevant sind.
Schlussfolgerung
Wir hoffen, Sie fanden diesen Blogbeitrag aufschlussreich. Wenn Sie ClusterControl testen möchten, erhalten Sie eine 30-tägige Enterprise-Testversion, in der Ihnen alle Funktionen zur Verfügung stehen. Sie können es kostenlos herunterladen und testen, ob es in Ihre Umgebung passt.



