Sobald Sie mit dem Betrieb eines Datenbankservers beginnen und Ihre Nutzung zunimmt, sind Sie vielen Arten von technischen Problemen, Leistungseinbußen und Datenbankfehlfunktionen ausgesetzt. All dies könnte zu viel größeren Problemen führen, wie z. B. einem katastrophalen Ausfall oder Datenverlust. Es ist wie eine Kettenreaktion, bei der eins zum anderen führen kann und immer mehr Probleme verursacht. Es müssen proaktive Gegenmaßnahmen ergriffen werden, damit Sie so lange wie möglich ein stabiles Umfeld haben.
In diesem Blogbeitrag werden wir uns eine Reihe cooler Funktionen von ClusterControl ansehen, die uns bei der Fehlerbehebung und Behebung unserer MySQL-Datenbankprobleme sehr helfen können, wenn sie auftreten.
Datenbankalarme und Benachrichtigungen
Für alle unerwünschten Ereignisse protokolliert ClusterControl alles unter Alarme, zugänglich über die Aktivität (oberes Menü) der ClusterControl-Seite. Dies ist normalerweise der erste Schritt, um mit der Fehlerbehebung zu beginnen, wenn etwas schief geht. Auf dieser Seite können wir uns ein Bild davon machen, was eigentlich mit unserem Datenbank-Cluster los ist:
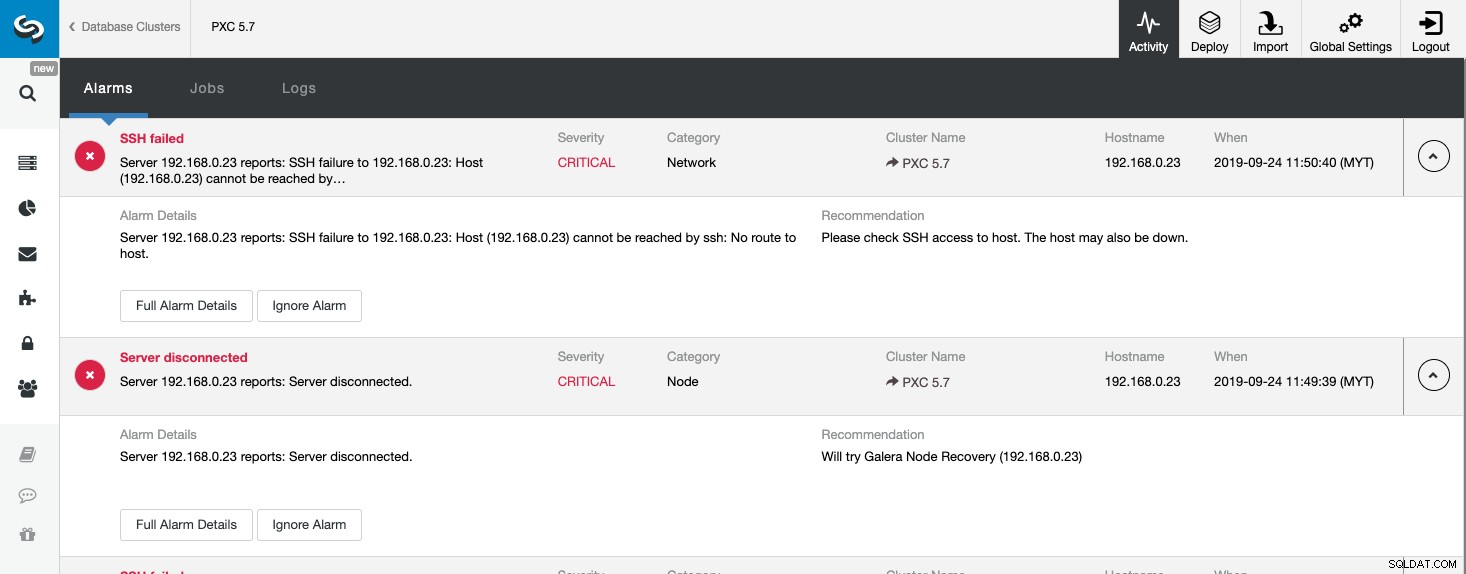
Der obige Screenshot zeigt ein Beispiel für ein Ereignis „Server nicht erreichbar“ mit Schweregrad KRITISCH , erkannt von zwei Komponenten, Network und Node. Wenn Sie die Einstellung für E-Mail-Benachrichtigungen konfiguriert haben, sollten Sie eine Kopie dieser Alarme in Ihrem Postfach erhalten.
Wenn Sie auf „Vollständige Alarmdetails“ klicken, erhalten Sie die wichtigen Details des Alarms wie Hostname, Zeitstempel, Clustername und so weiter. Es enthält auch den nächsten empfohlenen Schritt. Sie können diesen Alarm auch als E-Mail an andere Empfänger senden, die in den E-Mail-Benachrichtigungseinstellungen konfiguriert sind.
Sie können einen Alarm auch stumm schalten, indem Sie auf die Schaltfläche „Alarm ignorieren“ klicken und er wird dann nicht mehr in der Liste angezeigt. Das Ignorieren eines Alarms kann nützlich sein, wenn Sie einen Alarm mit niedrigem Schweregrad haben und wissen, wie Sie ihn handhaben oder umgehen können. Zum Beispiel, wenn ClusterControl einen doppelten Index in Ihrer Datenbank erkennt, der in einigen Fällen von Ihren Legacy-Anwendungen benötigt wird.
Wenn wir uns diese Seite ansehen, können wir sofort verstehen, was mit unserem Datenbank-Cluster los ist und was der nächste Schritt zur Lösung des Problems ist. Wie in diesem Fall fiel einer der Datenbankknoten aus und wurde über SSH vom ClusterControl-Host aus nicht erreichbar. Selbst ein Anfänger-SysAdmin würde jetzt wissen, was als nächstes zu tun ist, wenn dieser Alarm erscheint.
Protokolldateien der zentralen Datenbank
Hier können wir aufschlüsseln, was mit unserem Datenbankserver falsch war. Unter ClusterControl -> Logs -> System Logs sehen Sie alle Logdateien zum Datenbank-Cluster. Was MySQL-basierte Datenbank-Cluster betrifft, zieht ClusterControl das ProxySQL-Protokoll, das MySQL-Fehlerprotokoll und die Sicherungsprotokolle:
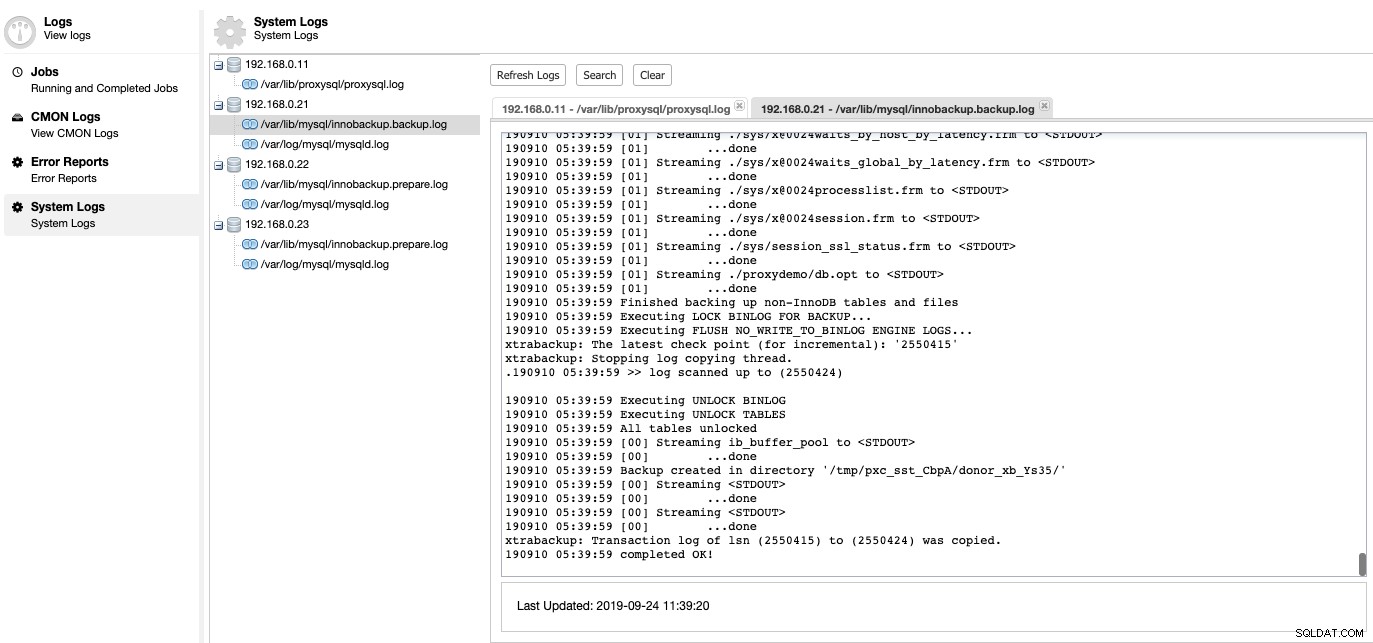
Klicken Sie auf "Protokoll aktualisieren", um das neueste Protokoll von allen Hosts abzurufen, die zu diesem bestimmten Zeitpunkt erreichbar sind. Wenn ein Knoten nicht erreichbar ist, zeigt ClusterControl immer noch die veraltete Anmeldung an, da diese Informationen in der CMON-Datenbank gespeichert sind. Standardmäßig ruft ClusterControl die Systemprotokolle alle 10 Minuten ab, konfigurierbar unter Einstellungen -> Protokollintervall.
ClusterControl löst den Job aus, um das neueste Protokoll von jedem Server abzurufen, wie im folgenden "Collect Logs"-Job gezeigt:
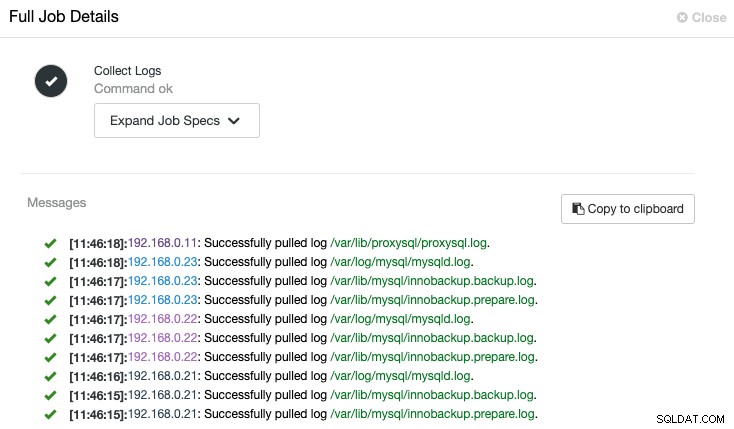
Eine zentralisierte Ansicht der Protokolldatei ermöglicht es uns, schneller zu verstehen, was passiert ist falsch. Für einen Datenbank-Cluster, der üblicherweise mehrere Knoten und Schichten umfasst, wird diese Funktion das Lesen von Protokollen erheblich verbessern, da ein SysAdmin diese Protokolle nebeneinander vergleichen und kritische Ereignisse lokalisieren kann, wodurch die Gesamtzeit für die Fehlerbehebung verkürzt wird.
Web-SSH-Konsole
ClusterControl bietet eine webbasierte SSH-Konsole, sodass Sie direkt über die ClusterControl-Benutzeroberfläche auf den DB-Server zugreifen können (da der SSH-Benutzer so konfiguriert ist, dass er sich mit den Datenbank-Hosts verbindet). Von hier aus können wir viel mehr Informationen sammeln, mit denen wir das Problem noch schneller beheben können. Jeder weiß, wenn ein Datenbankproblem das Produktionssystem trifft, jede Sekunde Ausfallzeit zählt.
Um über das Web auf die SSH-Konsole zuzugreifen, wählen Sie einfach die Knoten unter Knoten -> Knotenaktionen -> SSH-Konsole aus oder klicken Sie einfach auf das Zahnradsymbol für eine Verknüpfung:
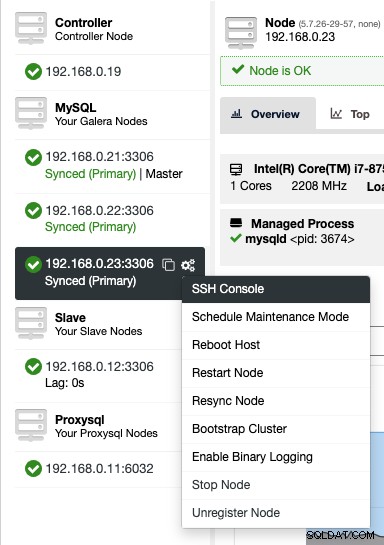
Aufgrund von Sicherheitsbedenken, die mit dieser Funktion verbunden sein könnten, insbesondere für Multi -user- oder Multi-Tenant-Umgebung, kann man sie deaktivieren, indem man auf dem ClusterControl-Server zu /var/www/html/clustercontrol/bootstrap.php geht und die folgende Konstante auf „false“ setzt:
define('SSH_ENABLED', false);Aktualisieren Sie die ClusterControl-UI-Seite, um die neuen Änderungen zu laden.
Probleme mit der Datenbankleistung
Neben Überwachungs- und Trendfunktionen sendet Ihnen ClusterControl proaktiv verschiedene Alarme und Hinweise zur Datenbankleistung, zum Beispiel:
- Übermäßige Nutzung – Ressource, die bestimmte Schwellenwerte wie CPU, Arbeitsspeicher, Swap-Nutzung und Speicherplatz überschreitet.
- Cluster-Verschlechterung – Cluster- und Netzwerkpartitionierung.
- Systemzeitdrift – Zeitunterschied zwischen allen Knoten im Cluster (einschließlich ClusterControl-Knoten).
- Verschiedene andere MySQL-bezogene Ratgeber:
- Replikation – Replikationsverzögerung, Binlog-Ablauf, Standort und Wachstum
- Galera - SST-Methode, GRA-Logdatei scannen, Cluster-Adressprüfer
- Schema-Prüfung - Nicht transaktionale Tabellenexistenz auf Galera Cluster.
- Verbindungen - Verhältnis der verbundenen Threads
- InnoDB – Dirty Pages Ratio, Wachstum der InnoDB-Protokolldatei
- Langsame Abfragen - Standardmäßig löst ClusterControl einen Alarm aus, wenn eine Abfrage gefunden wird, die länger als 30 Sekunden läuft. Dies ist natürlich konfigurierbar unter Einstellungen -> Laufzeitkonfiguration -> Lange Abfrage.
- Deadlocks – InnoDB-Transaktions-Deadlock und Galera-Deadlock.
- Indizes - Doppelte Schlüssel, Tabelle ohne Primärschlüssel.
Sehen Sie sich die Advisors-Seite unter Performance -> Advisors an, um Details zu Dingen zu erhalten, die wie von ClusterControl vorgeschlagen verbessert werden können. Für jeden Advisor werden Begründungen und Ratschläge bereitgestellt, wie im folgenden Beispiel für den Advisor „Checking Disk Space Usage“ gezeigt:
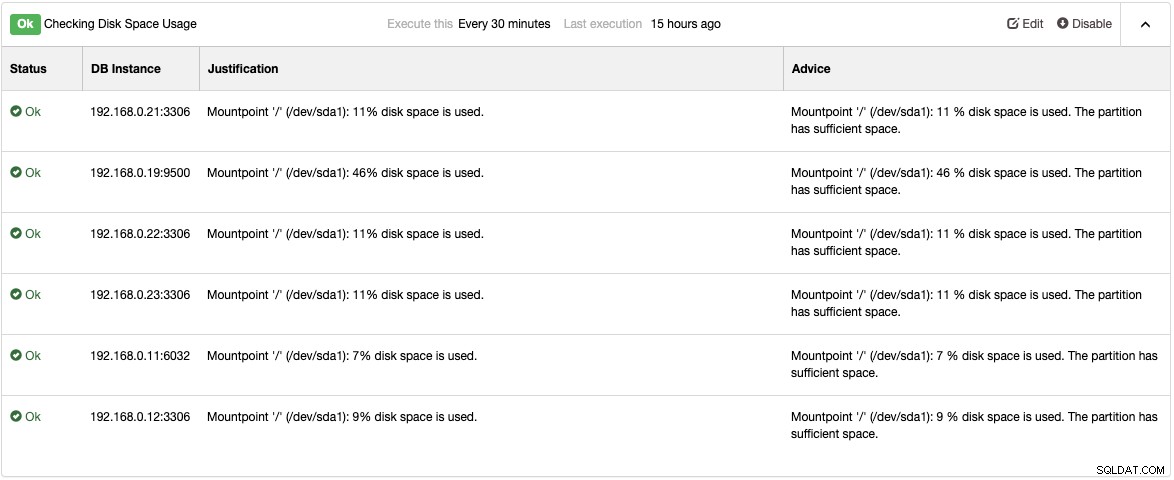
Wenn ein Leistungsproblem auftritt, erhalten Sie eine „Warnung“ (gelb) oder Status „Kritisch“ (rot) bei diesen Beratern. Üblicherweise ist eine weitere Abstimmung erforderlich, um das Problem zu lösen. Berater lösen Alarme aus, was bedeutet, dass Benutzer eine Kopie dieser Alarme in der Mailbox erhalten, wenn E-Mail-Benachrichtigungen entsprechend konfiguriert sind. Für jeden Alarm, der von ClusterControl oder seinen Beratern ausgelöst wird, erhalten Benutzer auch eine E-Mail, wenn der Alarm gelöscht wurde. Diese sind innerhalb von ClusterControl vorkonfiguriert und erfordern keine Erstkonfiguration. Weitere Anpassungen sind jederzeit unter Verwalten -> Developer Studio möglich. In diesem Blogbeitrag erfahren Sie, wie Sie Ihren eigenen Ratgeber schreiben.
ClusterControl bietet auch eine spezielle Seite in Bezug auf die Datenbankleistung unter ClusterControl -> Leistung. Es bietet alle Arten von Datenbankeinblicken nach den Best Practices wie zentralisierte Ansicht von DB-Status, Variablen, InnoDB-Status, Schema-Analysator, Transaktionsprotokollen. Diese sind ziemlich selbsterklärend und einfach zu verstehen.
Für die Abfrageleistung können Sie Top-Abfragen und Abfrageausreißer untersuchen, wobei ClusterControl Abfragen hervorhebt, deren Leistung erheblich von ihrer durchschnittlichen Abfrage abweicht. Wir haben dieses Thema in diesem Blog-Beitrag, MySQL Query Performance Tuning, ausführlich behandelt.
Datenbankfehlerberichte
ClusterControl wird mit einem Fehlerbericht-Generator-Tool geliefert, um Debugging-Informationen über Ihren Datenbank-Cluster zu sammeln, um die aktuelle Situation und den aktuellen Status zu verstehen. Um einen Fehlerbericht zu erstellen, gehen Sie einfach zu ClusterControl -> Protokolle -> Fehlerberichte -> Fehlerbericht erstellen:
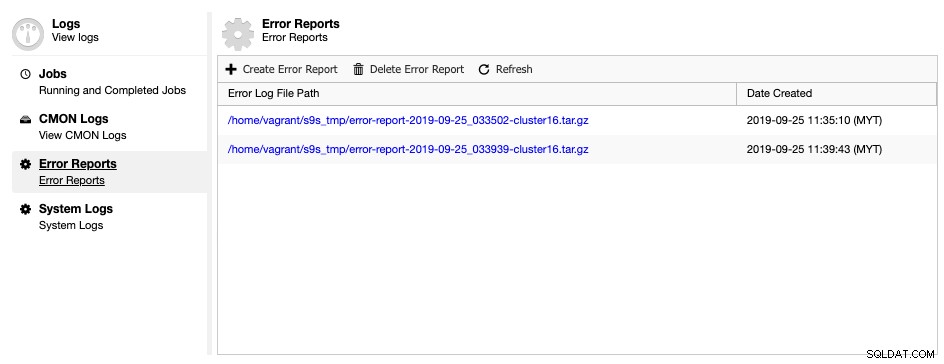
Der generierte Fehlerbericht kann von dieser Seite heruntergeladen werden, sobald er fertig ist. Dieser generierte Bericht liegt im TAR-Ball-Format (tar.gz) vor und Sie können ihn an eine Support-Anfrage anhängen. Da die Dateigröße des Support-Tickets auf 10 MB begrenzt ist, könnten Sie, wenn die Tarball-Größe größer ist, sie in ein Cloud-Laufwerk hochladen und den Download-Link nur mit der entsprechenden Erlaubnis mit uns teilen. Sie können es später entfernen, sobald wir die Datei bereits erhalten haben. Sie können den Fehlerbericht auch über die Befehlszeile generieren, wie auf der Fehlerbericht-Dokumentationsseite beschrieben.
Im Falle eines Ausfalls empfehlen wir Ihnen dringend, während und direkt nach dem Ausfall mehrere Fehlerberichte zu erstellen. Diese Berichte sind sehr nützlich, um zu versuchen, zu verstehen, was schief gelaufen ist, die Folgen des Ausfalls, und um zu überprüfen, ob der Cluster nach einem katastrophalen Ereignis tatsächlich wieder in den Betriebsstatus zurückgekehrt ist.
Fazit
Die proaktive Überwachung von ClusterControl bietet zusammen mit einer Reihe von Fehlerbehebungsfunktionen eine effiziente Plattform für Benutzer, um alle Arten von MySQL-Datenbankproblemen zu beheben. Längst vorbei ist die herkömmliche Art der Fehlersuche, bei der man mehrere SSH-Sitzungen öffnen muss, um auf mehrere Hosts zuzugreifen und mehrere Befehle wiederholt auszuführen, um die eigentliche Ursache zu lokalisieren.
Wenn die oben genannten Funktionen Ihnen nicht bei der Lösung des Problems oder der Fehlerbehebung des Datenbankproblems helfen, wenden Sie sich immer an das Support-Team von Multiplenines, um Sie zu unterstützen. Unsere 24/7/365 engagierten technischen Experten stehen Ihnen jederzeit für Ihre Anfrage zur Verfügung. Unsere durchschnittliche Zeit bis zur ersten Antwort beträgt normalerweise weniger als 30 Minuten.



