Ein Single Point of Failure (SPOF) ist ein häufiger Grund, warum Unternehmen daran arbeiten, die Präsenz ihrer Datenbankumgebungen geografisch an einen anderen Ort zu verteilen. Es ist Teil der strategischen Pläne für Disaster Recovery und Business Continuity.
Disaster Recovery (DR)-Planung umfasst technische Verfahren, die die Vorbereitung auf unvorhergesehene Probleme wie Naturkatastrophen, Unfälle (z. B. menschliches Versagen) oder Zwischenfälle (z. B. kriminelle Handlungen) abdecken.
In den letzten zehn Jahren war die Verteilung Ihrer Datenbankumgebung auf mehrere geografische Standorte eine ziemlich übliche Einrichtung, da öffentliche Clouds viele Möglichkeiten bieten, damit umzugehen. Die Herausforderung liegt in der Einrichtung von Datenbankumgebungen. Es schafft Herausforderungen, wenn Sie versuchen, die Datenbank(en) zu verwalten, Ihre Daten an einen anderen geografischen Standort zu verschieben oder Sicherheit mit einem hohen Grad an Beobachtbarkeit anzuwenden.
In diesem Blog zeigen wir Ihnen, wie Sie dies mit MySQL Replication tun können. Wir werden behandeln, wie Sie Ihre Daten auf einen anderen Datenbankknoten kopieren können, der sich in einem anderen Land befindet, das von der aktuellen Geographie des MySQL-Clusters entfernt ist. In diesem Beispiel basiert unsere Zielregion auf „us-east“, während mein lokaler Standort in Asien auf den Philippinen liegt.
Warum brauche ich einen Datenbankcluster für Geostandorte?
Sogar Amazon AWS, der führende Anbieter öffentlicher Clouds, behauptet, dass sie unter Ausfallzeiten oder unbeabsichtigten Ausfällen leiden (wie dem, der 2017 passierte). Angenommen, Sie verwenden AWS neben Ihrem lokalen Rechenzentrum als sekundäres Rechenzentrum. Sie haben keinen internen Zugriff auf die zugrunde liegende Hardware oder auf die internen Netzwerke, die Ihre Rechenknoten verwalten. Dies sind vollständig verwaltete Dienste, für die Sie bezahlt haben, aber Sie können die Tatsache nicht vermeiden, dass es jederzeit zu einem Ausfall kommen kann. Wenn an einem solchen geografischen Standort ein Ausfall auftritt, kann es zu langen Ausfallzeiten kommen.
Diese Art von Problem muss bei Ihrer Geschäftskontinuitätsplanung berücksichtigt werden. Es muss auf der Grundlage dessen, was definiert wurde, analysiert und implementiert worden sein. Die Geschäftskontinuität Ihrer MySQL-Datenbanken sollte eine hohe Betriebszeit beinhalten. Einige Umgebungen führen Benchmarks durch und legen eine hohe Messlatte strenger Tests fest, einschließlich der schwachen Seite, um Schwachstellen aufzudecken, wie belastbar sie sein können und wie skalierbar Ihre Technologiearchitektur einschließlich Ihrer Datenbankinfrastruktur ist. Für Unternehmen, insbesondere solche mit hohen Transaktionszahlen, ist es unerlässlich sicherzustellen, dass Produktionsdatenbanken jederzeit für die Anwendungen verfügbar sind, selbst wenn eine Katastrophe eintritt. Andernfalls kann es zu Ausfallzeiten kommen, die Sie viel Geld kosten können.
Mit diesen identifizierten Szenarien beginnen Organisationen damit, ihre Infrastruktur auf verschiedene Cloud-Anbieter auszudehnen und Knoten an unterschiedlichen geografischen Standorten zu platzieren, um eine höhere Betriebszeit (wenn möglich bei 99,99999999999), einen niedrigeren RPO und keinen SPOF zu haben.
Um sicherzustellen, dass Produktionsdatenbanken einen Notfall überstehen, muss eine Disaster Recovery (DR)-Site konfiguriert werden. Produktions- und DR-Standorte müssen Teil zweier geografisch entfernter Rechenzentren sein. Das bedeutet, dass am DR-Standort für jede Produktionsdatenbank eine Standby-Datenbank konfiguriert werden muss, sodass die in der Produktionsdatenbank auftretenden Datenänderungen sofort über Transaktionsprotokolle mit der Standby-Datenbank synchronisiert werden. Einige Setups verwenden ihre DR-Knoten auch zum Verarbeiten von Lesevorgängen, um einen Lastausgleich zwischen Anwendung und Datenschicht bereitzustellen.
Der gewünschte architektonische Aufbau
In diesem Blog ist das gewünschte Setup eine einfache und doch heutzutage sehr verbreitete Umsetzung. Unten finden Sie die gewünschte Architekturkonfiguration für diesen Blog:
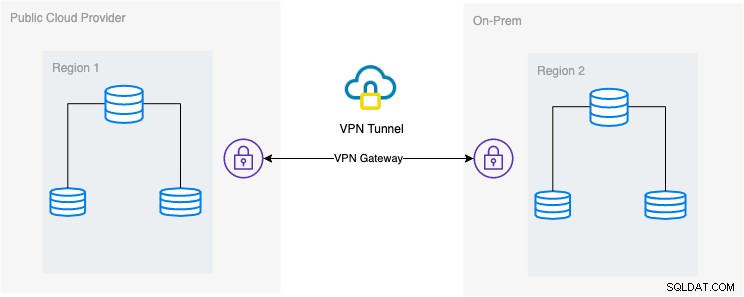
In diesem Blog wähle ich Google Cloud Platform (GCP) als öffentlich Cloud-Anbieter und die Verwendung meines lokalen Netzwerks als lokale Datenbankumgebung.
Es ist ein Muss, dass Sie bei der Verwendung dieser Art von Design immer sowohl eine Umgebung als auch eine Plattform benötigen, um auf sehr sichere Weise zu kommunizieren. VPN verwenden oder Alternativen wie AWS Direct Connect verwenden. Obwohl diese öffentlichen Clouds heutzutage verwaltete VPN-Dienste anbieten, die Sie verwenden können. Aber für dieses Setup verwenden wir OpenVPN, da ich für diesen Blog keine ausgefeilte Hardware oder Dienste benötige.
Der beste und effizienteste Weg
Für MySQL/Percona/MariaDB-Datenbankumgebungen besteht der beste und effizienteste Weg darin, eine Sicherungskopie Ihrer Datenbank zu erstellen und an den Zielknoten zu senden, um bereitgestellt oder instanziiert zu werden. Es gibt verschiedene Möglichkeiten, diesen Ansatz zu verwenden, entweder Sie können mysqldump, mydumper, rsync oder Percona XtraBackup/Mariabackup verwenden und die Daten zu Ihrem Zielknoten streamen.
Verwendung von mysqldump
mysqldump erstellt ein logisches Backup Ihrer gesamten Datenbank oder Sie können selektiv eine Liste von Datenbanken, Tabellen oder sogar bestimmten Datensätzen auswählen, die Sie sichern möchten.
Ein einfacher Befehl, den Sie verwenden können, um eine vollständige Sicherung zu erstellen, kann sein,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsMit diesem einfachen Befehl werden die MySQL-Anweisungen direkt zum Zieldatenbankknoten ausgeführt, beispielsweise zu Ihrem Zieldatenbankknoten auf einer Google Compute Engine. Dies kann effizient sein, wenn die Daten kleiner sind oder Sie eine schnelle Bandbreite haben. Andernfalls kann es Ihre Option sein, Ihre Datenbank in eine Datei zu packen und sie dann an den Zielknoten zu senden.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathFühren Sie dann mysqldump zum Zieldatenbankknoten als solchem aus
zcat mydata.db | mysqlDer Nachteil bei der Verwendung von logischem Backup mit mysqldump ist, dass es langsamer ist und Speicherplatz verbraucht. Es verwendet auch einen einzelnen Thread, sodass Sie diesen nicht parallel ausführen können. Optional können Sie mydumper verwenden, insbesondere wenn Ihre Datenmenge zu groß ist. mydumper kann parallel ausgeführt werden, ist aber im Vergleich zu mysqldump nicht so flexibel.
Xtrabackup verwenden
xtrabackup ist ein physisches Backup, bei dem Sie die Streams oder Binärdateien an den Zielknoten senden können. Dies ist sehr effizient und wird meistens verwendet, wenn ein Backup über das Netzwerk gestreamt wird, insbesondere wenn sich der Zielknoten in einer anderen Geographie oder Region befindet. ClusterControl verwendet xtrabackup, wenn ein neuer Slave bereitgestellt oder instanziiert wird, unabhängig davon, wo er sich befindet, solange der Zugriff und die Berechtigung vor der Aktion eingerichtet wurden.
Wenn Sie xtrabackup verwenden, um es manuell auszuführen, können Sie den Befehl als solchen ausführen
## Zielknoten
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Quellknoten
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Um diese beiden Befehle auszuarbeiten, muss der erste Befehl ausgeführt werden oder zuerst auf dem Zielknoten ausgeführt werden. Der Zielknotenbefehl hört auf Port 9999 und schreibt jeden Stream, der von Port 9999 empfangen wird, in den Zielknoten. Es ist abhängig von den Befehlen socat und xbstream, was bedeutet, dass Sie sicherstellen müssen, dass Sie diese Pakete installiert haben.
Auf dem Quellknoten führt es das Perl-Skript innobackupex aus, das xtrabackup im Hintergrund aufruft und xbstream verwendet, um die Daten zu streamen, die über das Netzwerk gesendet werden. Der Befehl socat öffnet den Port 9999 und sendet seine Daten an den gewünschten Host, in diesem Beispiel 192.168.10.70. Stellen Sie dennoch sicher, dass Sie socat und xbstream installiert haben, wenn Sie diesen Befehl verwenden. Eine alternative Möglichkeit zur Verwendung von socat ist nc, aber socat bietet im Vergleich zu nc erweiterte Funktionen, z. B. Serialisierung, da mehrere Clients auf einem Port lauschen können.
ClusterControl verwendet diesen Befehl, wenn ein Slave neu erstellt oder ein neuer Slave erstellt wird. Es ist schnell und garantiert, dass die exakte Kopie Ihrer Quelldaten auf Ihren Zielknoten kopiert wird. Wenn Sie eine neue Datenbank an einem separaten geografischen Standort bereitstellen, bietet dieser Ansatz mehr Effizienz und bietet Ihnen mehr Geschwindigkeit, um den Job zu erledigen. Obwohl es Vor- und Nachteile geben kann, wenn logische oder binäre Sicherungen verwendet werden, wenn sie über die Leitung gestreamt werden. Die Verwendung dieser Methode ist ein sehr gängiger Ansatz, wenn Sie einen neuen Geolokalisierungs-Datenbankcluster in einer anderen Region einrichten und eine exakte Kopie Ihrer Datenbankumgebung erstellen.
Effizienz, Beobachtbarkeit und Geschwindigkeit
Fragen, die von den meisten Leuten hinterlassen werden, die mit diesem Ansatz nicht vertraut sind, betreffen immer die "WIE, WAS, WO"-Probleme. In diesem Abschnitt behandeln wir, wie Sie Ihre Geolokalisierungsdatenbank effizient und mit weniger Aufwand einrichten können, und mit Beobachtbarkeit, warum sie fehlschlägt. Die Verwendung von ClusterControl ist sehr effizient. In diesem aktuellen Setup habe ich die folgende Umgebung wie ursprünglich implementiert:
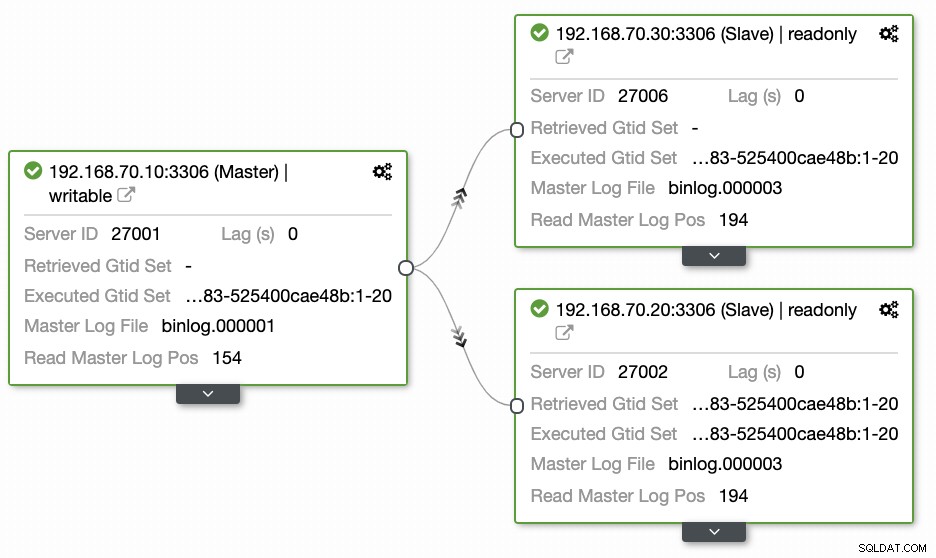
Knoten auf GCP erweitern
Beginnen Sie mit der Einrichtung Ihres Geo-Standortdatenbank-Clusters, um Ihren Cluster zu erweitern und eine Snapshot-Kopie Ihres Clusters zu erstellen, können Sie einen neuen Slave hinzufügen. Wie bereits erwähnt, verwendet ClusterControl xtrabackup (Mariabackup für MariaDB 10.2 und höher) und stellt einen neuen Knoten in Ihrem Cluster bereit. Bevor Sie Ihre GCP-Rechenknoten als Ihre Zielknoten registrieren können, müssen Sie zuerst den entsprechenden Systembenutzer einrichten, der mit dem Systembenutzer identisch ist, den Sie in ClusterControl registriert haben. Sie können dies in Ihrer /etc/cmon.d/cmon_X.cnf überprüfen, wobei X die cluster_id ist. Siehe beispielsweise unten:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (in diesem Beispiel) muss in Ihren GCP-Rechenknoten vorhanden sein. Der Nutzer in Ihren GCP-Knoten muss über die Berechtigungen „sudo“ oder „Super Admin“ verfügen. Es muss auch mit einem passwortlosen SSH-Zugang eingerichtet werden. Bitte lesen Sie unsere Dokumentation mehr über den Systembenutzer und seine erforderlichen Berechtigungen.
Sehen Sie unten eine Beispielliste von Servern (aus der GCP-Konsole:Compute Engine-Dashboard):
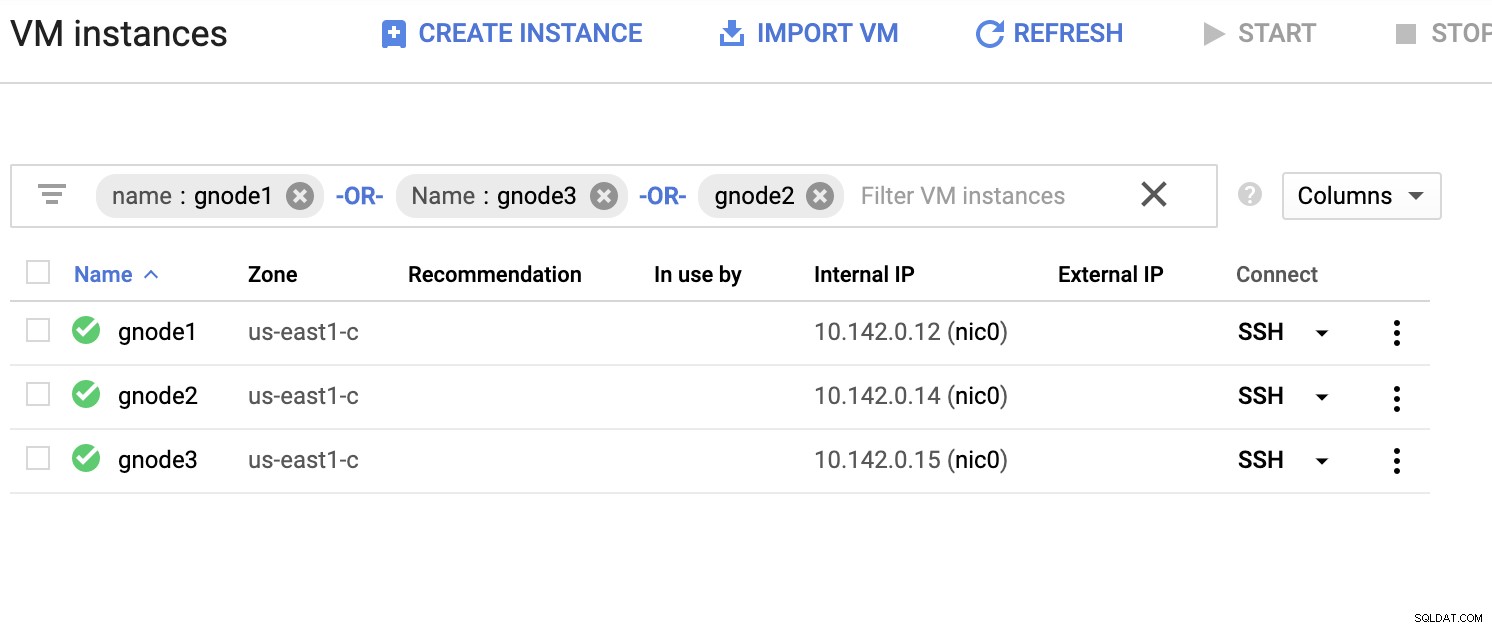
Im obigen Screenshot basiert unsere Zielregion auf dem Osten der USA Region. Wie bereits erwähnt, wird mein lokales Netzwerk über eine sichere Ebene eingerichtet, die GCP (umgekehrt) mit OpenVPN durchläuft. Daher wird die Kommunikation von der GCP zu meinem lokalen Netzwerk auch über den VPN-Tunnel gekapselt.
Fügen Sie der GCP einen Slave-Knoten hinzu
Der Screenshot unten zeigt, wie Sie dies tun können. Siehe Bilder unten:
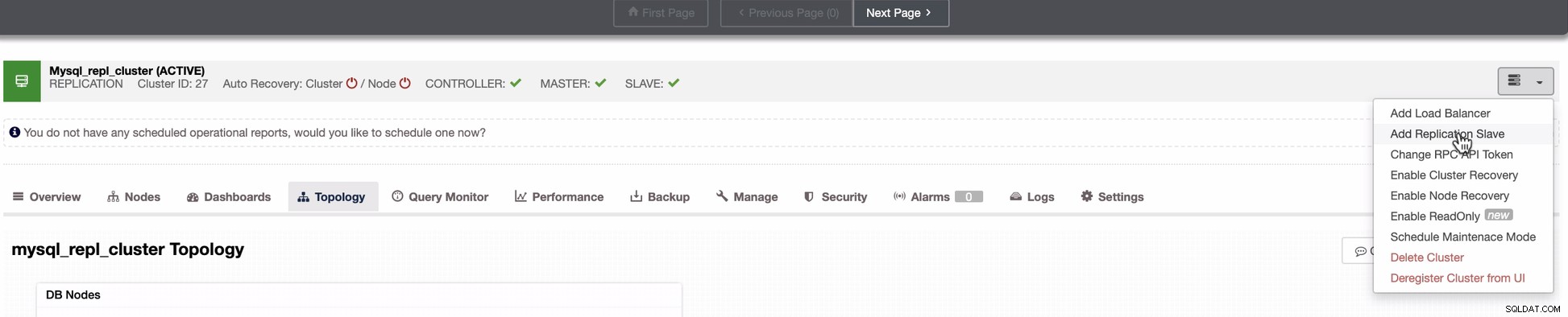
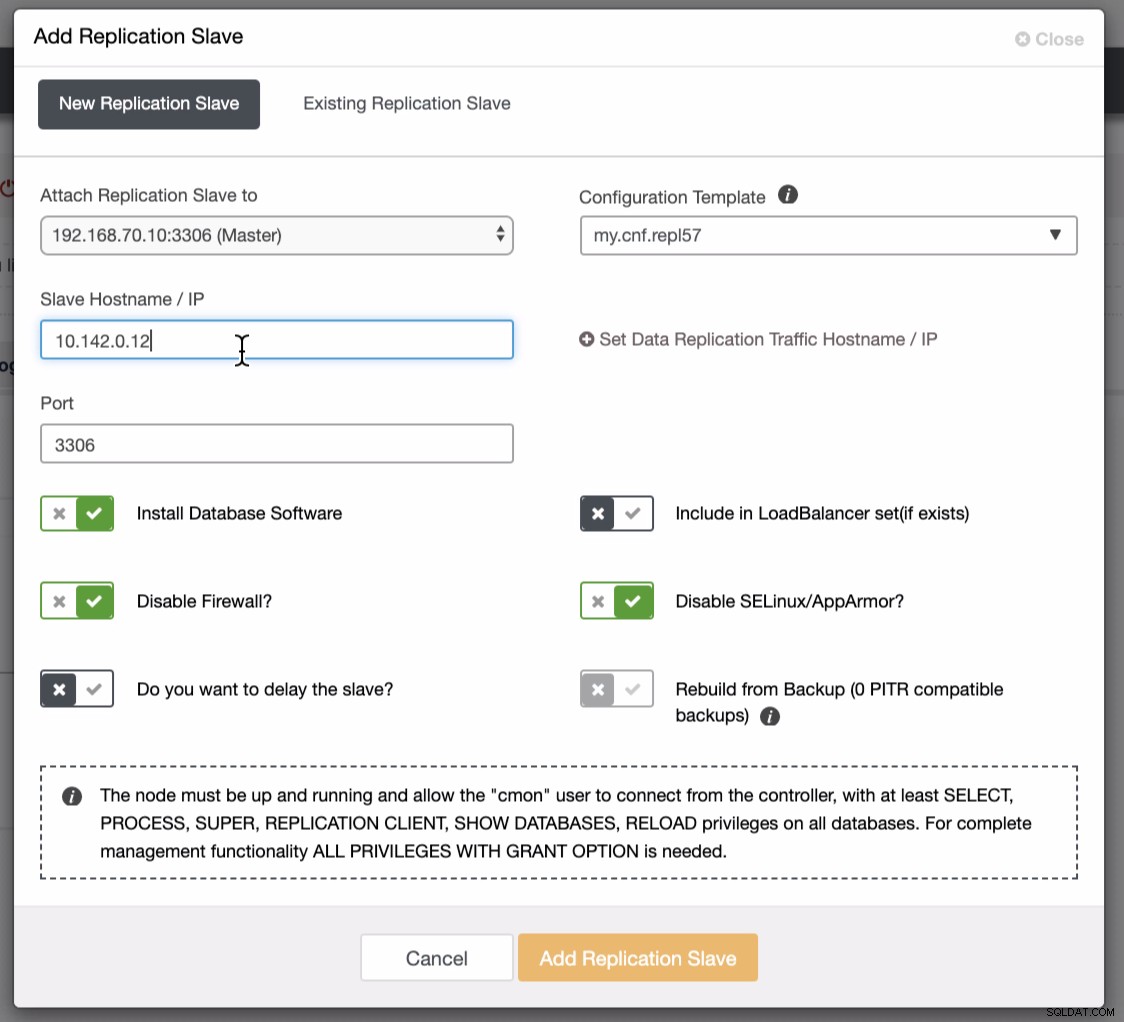
Wie im zweiten Screenshot zu sehen, zielen wir auf den Knoten 10.142.0.12 ab und sein Quellmaster ist 192.168.70.10. ClusterControl ist intelligent genug, um Firewalls, Sicherheitsmodule, Pakete, Konfigurationen und Einstellungen zu bestimmen, die durchgeführt werden müssen. Unten sehen Sie ein Beispiel für ein Auftragsaktivitätsprotokoll:
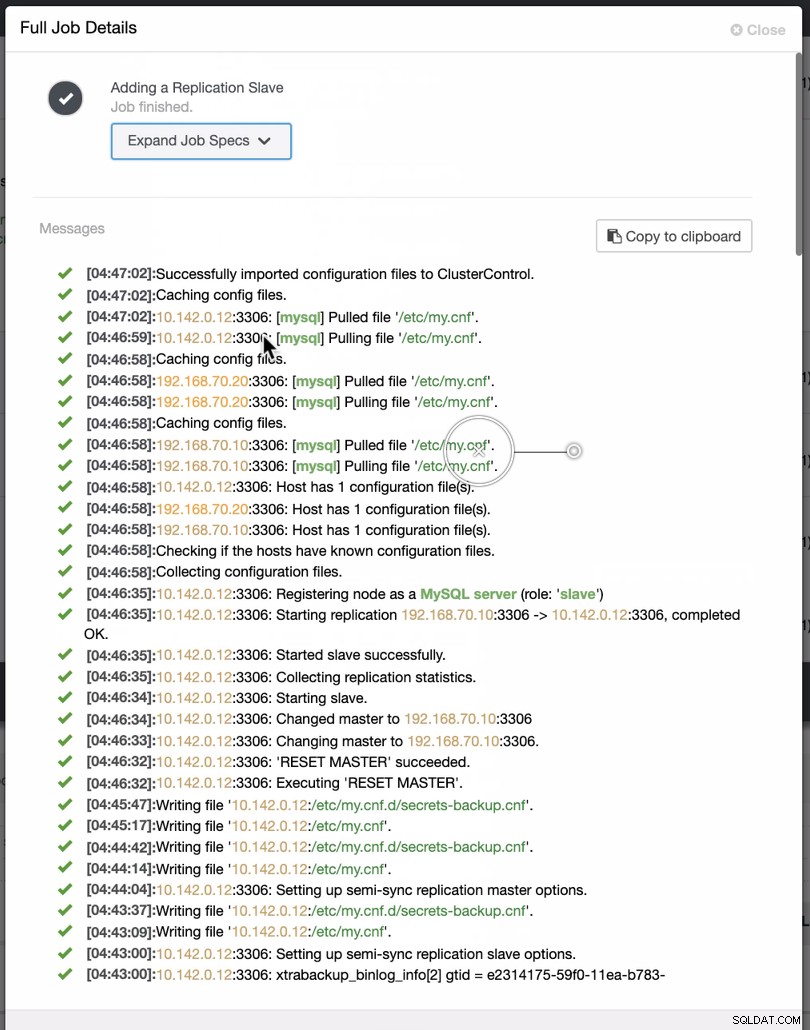
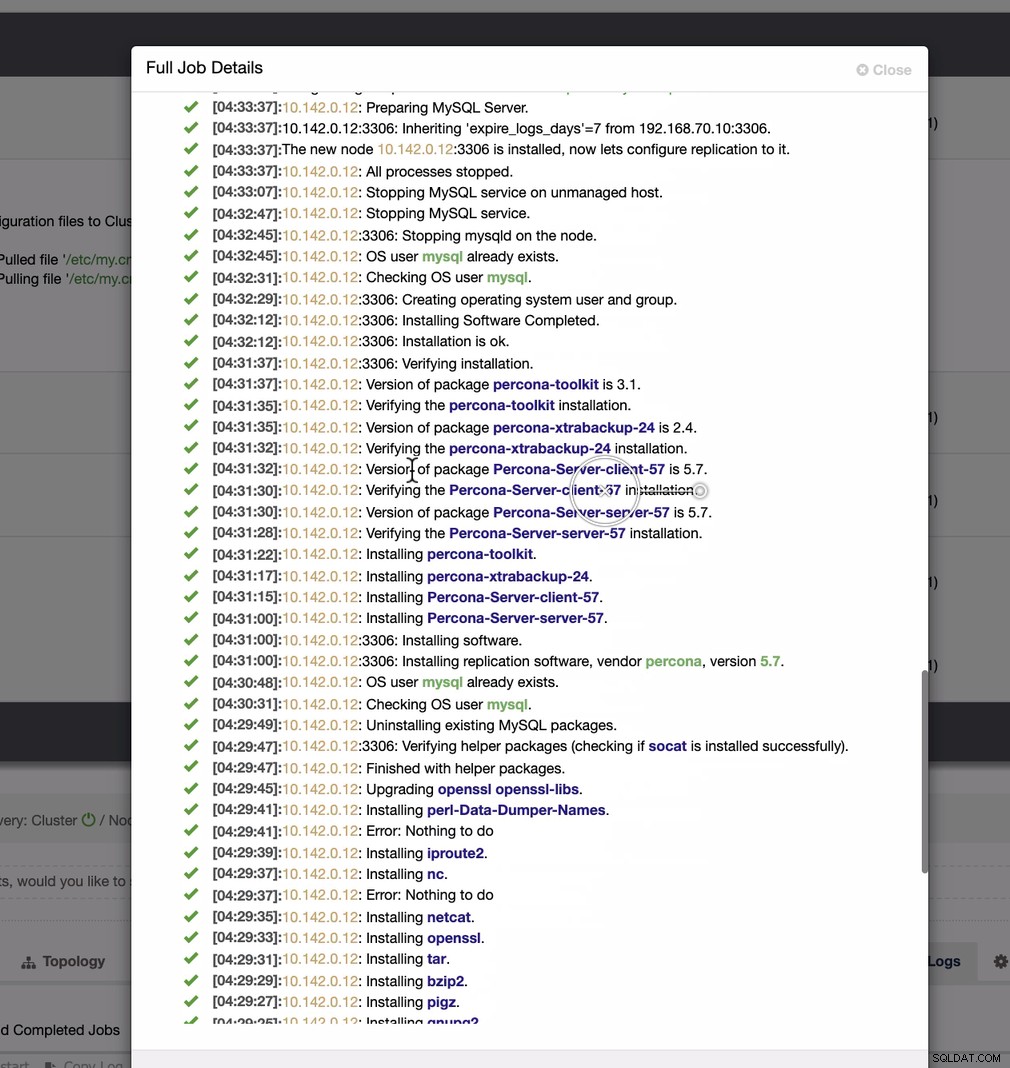
Eine ziemlich einfache Aufgabe, nicht wahr?
Schließen Sie den GCP-MySQL-Cluster ab
Wir müssen dem GCP-Cluster zwei weitere Knoten hinzufügen, um eine ausgewogene Topologie zu haben, wie wir sie im lokalen Netzwerk hatten. Stellen Sie beim zweiten und dritten Knoten sicher, dass der Master auf Ihren GCP-Knoten zeigen muss. In diesem Beispiel ist der Master 10.142.0.12. Siehe unten, wie das geht,
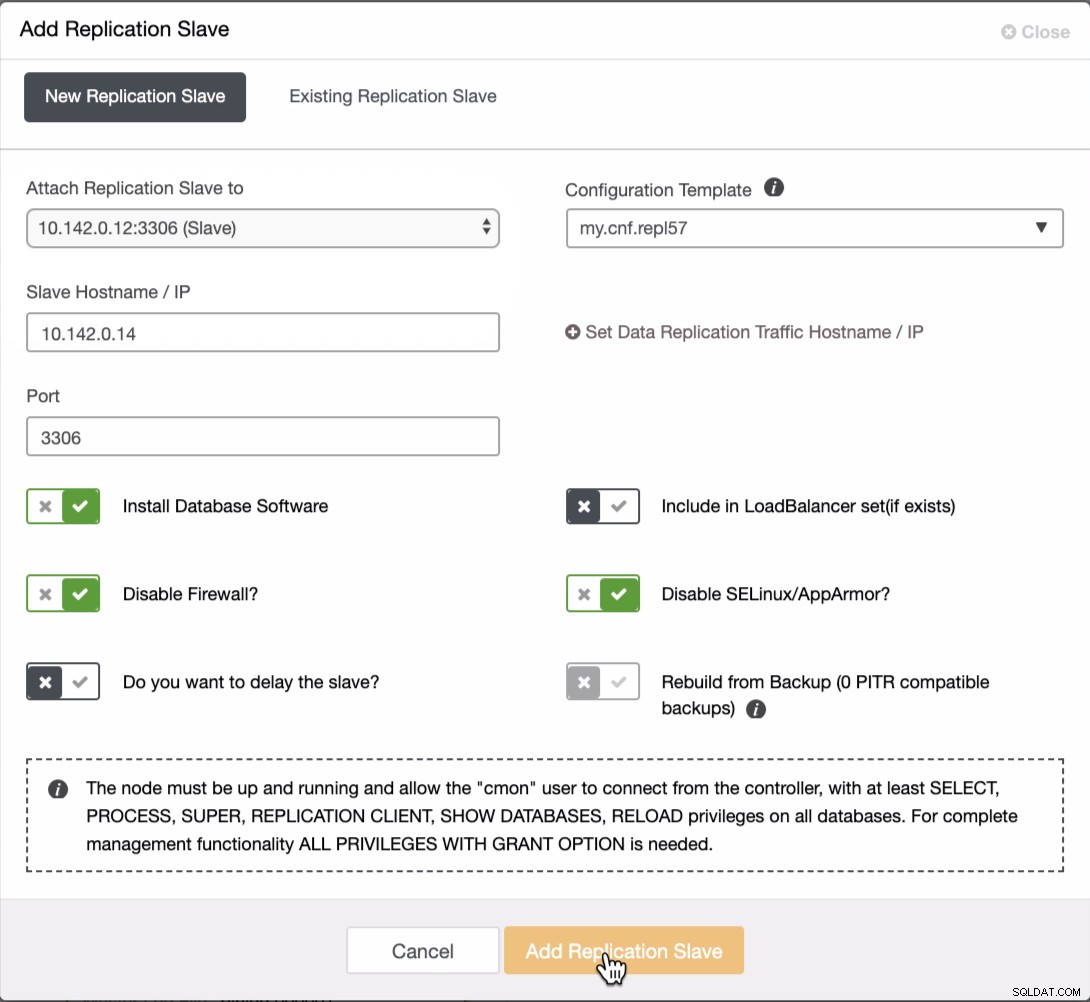
Wie im obigen Screenshot zu sehen, habe ich 10.142.0.12 (slave ), das ist der erste Knoten, den wir dem Cluster hinzugefügt haben. Das vollständige Ergebnis sieht wie folgt aus,
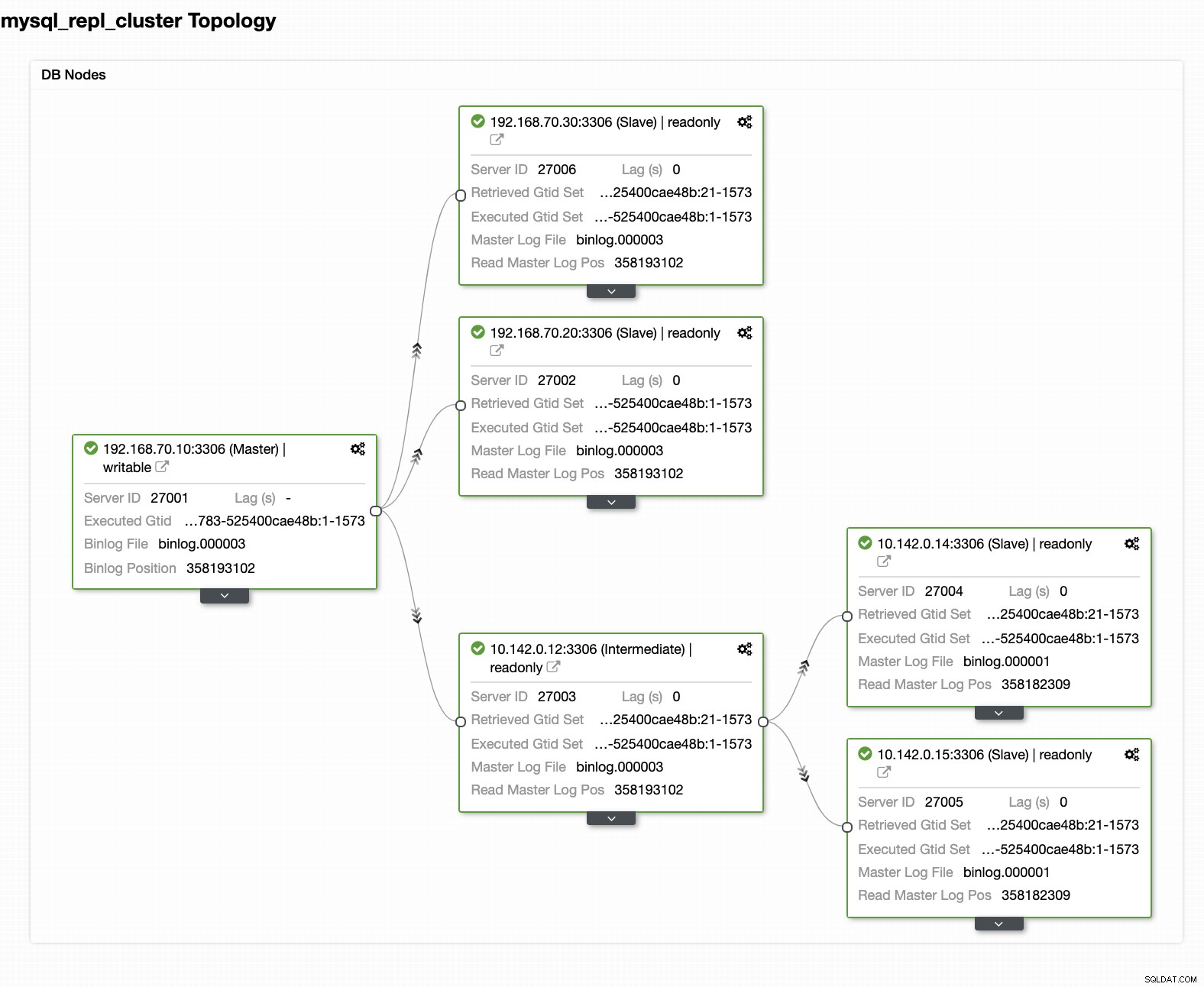
Ihre endgültige Einrichtung des Geolokalisierungs-Datenbank-Clusters
Aus dem letzten Screenshot geht hervor, dass diese Art von Topologie möglicherweise nicht Ihr ideales Setup ist. Meistens muss es sich um ein Multi-Master-Setup handeln, bei dem Ihr DR-Cluster als Standby-Cluster dient, während Ihr On-Prem-Cluster als primärer aktiver Cluster dient. Das geht ganz einfach in ClusterControl. Sehen Sie sich die folgenden Screenshots an, um dieses Ziel zu erreichen.
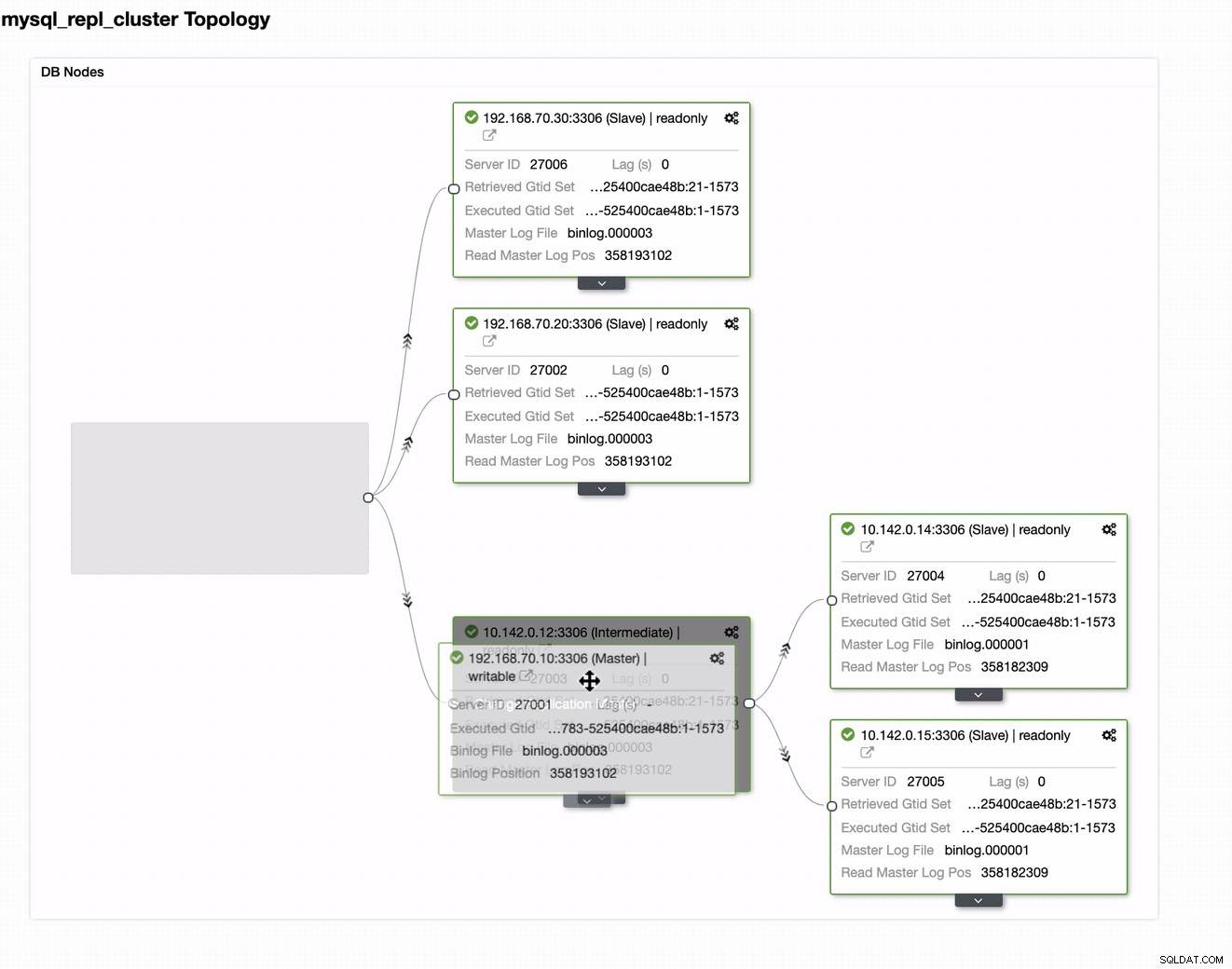
Sie können einfach Ihren aktuellen Master auf den gewünschten Ziel-Master ziehen Richten Sie sich als primärer Standby-Autor ein, nur für den Fall, dass Sie vor Ort Schaden erleiden. In diesem Beispiel ziehen wir Zielhost 10.142.0.12 (GCP-Rechenknoten). Das Endergebnis wird unten angezeigt:
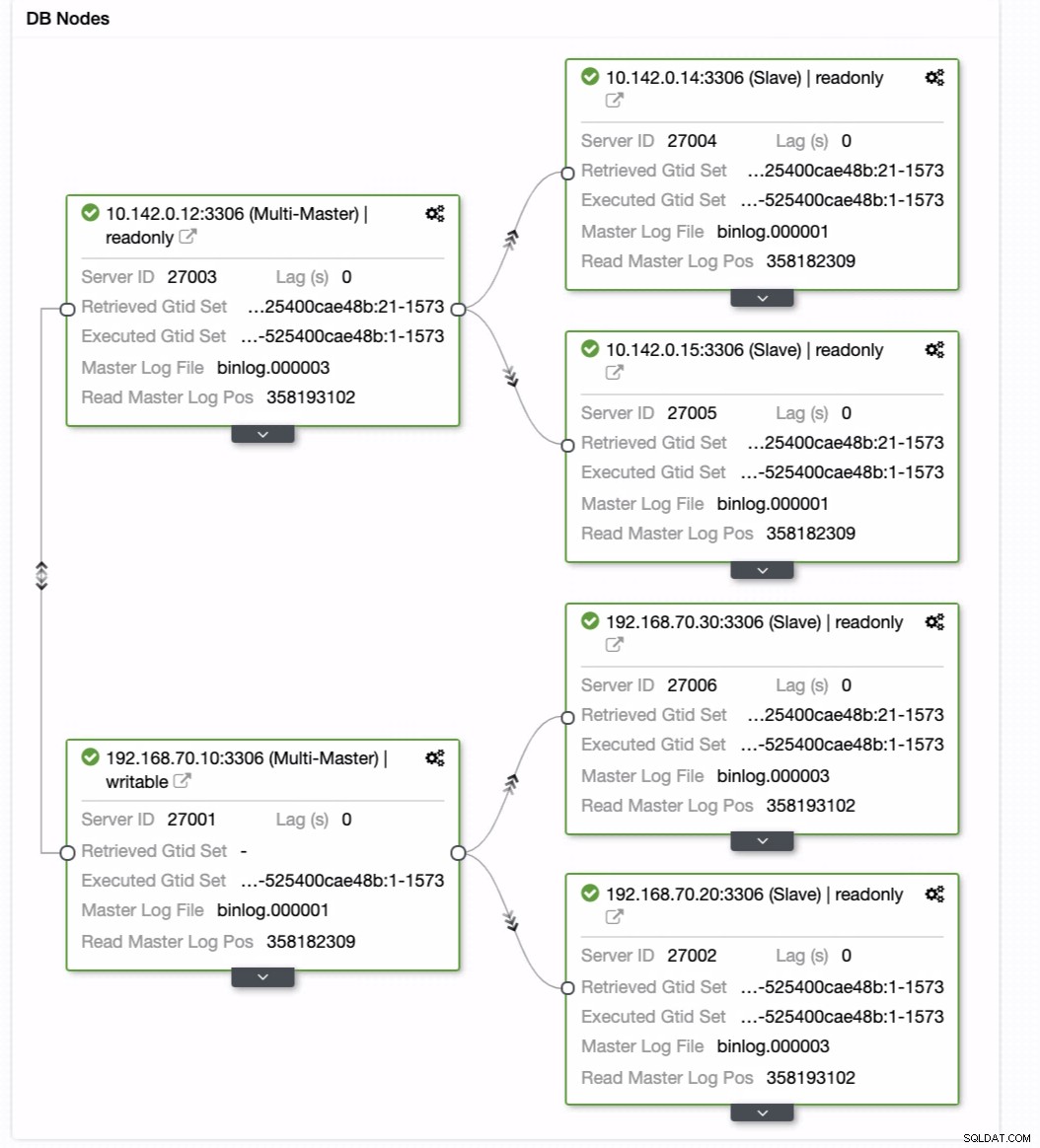
Dann wird das gewünschte Ergebnis erzielt. Einfaches und sehr schnelles Spawnen Ihres Geo-Location-Datenbank-Clusters mit MySQL-Replikation.
Fazit
Ein Geolokalisierungsdatenbank-Cluster zu haben ist nicht neu. Es war ein gewünschtes Setup für Unternehmen und Organisationen, die SPOF vermeiden und Resilienz und ein niedrigeres RPO wünschen.
Die wichtigsten Punkte für dieses Setup sind Sicherheit, Redundanz und Ausfallsicherheit. Außerdem wird behandelt, wie praktikabel und effizient Sie Ihren neuen Cluster in einer anderen geografischen Region bereitstellen können. Obwohl ClusterControl dies anbieten kann, können wir davon ausgehen, dass wir dies früher verbessern können, wo Sie effizient aus einem Backup erstellen und Ihren neuen, anderen Cluster in ClusterControl erzeugen können, also bleiben Sie dran.