In unseren vorherigen Blogs haben wir begründet, warum Sie ein Datenbank-Failover benötigen, und erklärt, wie ein Failover-Mechanismus funktioniert. Ich teile dies, falls Sie Fragen dazu haben, warum Sie einen Failover-Mechanismus für Ihre MySQL-Datenbank einrichten sollten. Wenn ja, lesen Sie bitte unsere vorherigen Blog-Beiträge.
So richten Sie automatisches Failover ein
Der Vorteil bei der Verwendung von MySQL oder MariaDB zur automatischen Verwaltung Ihres Failover besteht darin, dass es verfügbare Tools gibt, die Sie in Ihrer Umgebung verwenden und implementieren können. Von Open-Source- bis hin zu Unternehmenslösungen. Die meisten Tools sind nicht nur Failover-fähig, es gibt auch andere Funktionen wie Switchover, Überwachung und erweiterte Funktionen, die mehr Verwaltungsfunktionen für Ihren MySQL-Datenbankcluster bieten können. Im Folgenden gehen wir auf die gebräuchlichsten ein, die Sie verwenden können.
MHA (Master High Availability) verwenden
Wir haben dieses Thema mit MHA mit den häufigsten Problemen und deren Behebung behandelt. Wir haben MHA auch mit MRM oder mit MaxScale verglichen.
Die Einrichtung mit MHA für hohe Verfügbarkeit ist vielleicht nicht einfach, aber es ist effizient in der Anwendung und flexibel, da es einstellbare Parameter gibt, die Sie definieren können, um Ihr Failover anzupassen. MHA wurde getestet und verwendet. Aber mit fortschreitender Technologie hinkt MHA hinterher, da es GTID für MariaDB nicht unterstützt und in den letzten 2 oder 3 Jahren keine Updates veröffentlicht hat.
Durch Ausführen des masterha_manager-Skripts
masterha_manager --conf=/etc/app1.cnfWobei ein Beispiel /etc/app1.cnf wie folgt aussehen soll,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parameter wie „no_master“ und „candidate_master“ sind von entscheidender Bedeutung, wenn Sie gewünschte Knoten als Ziel-Master und Knoten, die Sie nicht als Master haben möchten, auf die Whitelist setzen.
Sobald es eingestellt ist, sind Sie bereit für ein Failover für Ihre MySQL-Datenbank, falls ein Fehler auf der Primär- oder Master-Datenbank auftritt. Das Skript masterha_manager verwaltet das Failover (automatisch oder manuell), trifft Entscheidungen darüber, wann und wo ein Failover erfolgen soll, und verwaltet die Slave-Wiederherstellung während der Heraufstufung des Masterkandidaten zum Anwenden von Differential-Relay-Protokollen. Wenn die Master-Datenbank stirbt, koordiniert der MHA-Manager den MHA-Knotenagenten, da er differenzielle Relay-Protokolle auf die Slaves anwendet, die nicht über die neuesten Binlog-Ereignisse vom Master verfügen.
Schauen Sie sich an, was der MHA-Knotenagent tut und welche Skripte daran beteiligt sind. Im Grunde ist es das Skript, das der MHA-Manager aufruft, wenn ein Failover auftritt. Er wartet auf sein Mandat vom MHA-Manager, während er nach dem neuesten Slave sucht, der die binlog-Ereignisse enthält, und fehlende Ereignisse mithilfe von scp vom Slave kopiert und auf sich selbst anwendet. Wie bereits erwähnt, wendet es Relay-Logs an, löscht Relay-Logs oder speichert binäre Logs.
Wenn Sie mehr über einstellbare Parameter wissen möchten und wie Sie Ihr Failover-Management anpassen können, besuchen Sie die Parameter-Wiki-Seite für MHA.
Orchestrator verwenden
Orchestrator ist ein Hochverfügbarkeits- und Replikationsverwaltungstool für MySQL und MariaDB. Es wird von Shlomi Noach unter den Bedingungen der Apache-Lizenz, Version 2.0, veröffentlicht. Dies ist eine Open-Source-Software und übernimmt das automatische Failover, aber es gibt unzählige Dinge, die Sie anpassen oder tun können, um Ihre MySQL/MariaDB-Datenbank zu verwalten, abgesehen von der Wiederherstellung oder dem automatischen Failover.
Die Installation von Orchestrator kann einfach oder unkompliziert sein. Nachdem Sie die spezifischen Pakete heruntergeladen haben, die für Ihre Zielumgebung erforderlich sind, können Sie Ihren Cluster und Ihre Knoten für die Überwachung durch Orchestrator registrieren. Es bietet eine Benutzeroberfläche, die sehr einfach zu verwalten ist, aber viele einstellbare Parameter oder Befehlssätze enthält, die Sie verwenden können, um Ihr Failover-Management zu erreichen.
Nehmen wir an, dass Sie den Cluster endlich eingerichtet und registriert haben, indem Sie unseren primären oder Master-Knoten mit dem folgenden Befehl hinzufügen,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Jetzt haben wir unseren Cluster hinzugefügt.
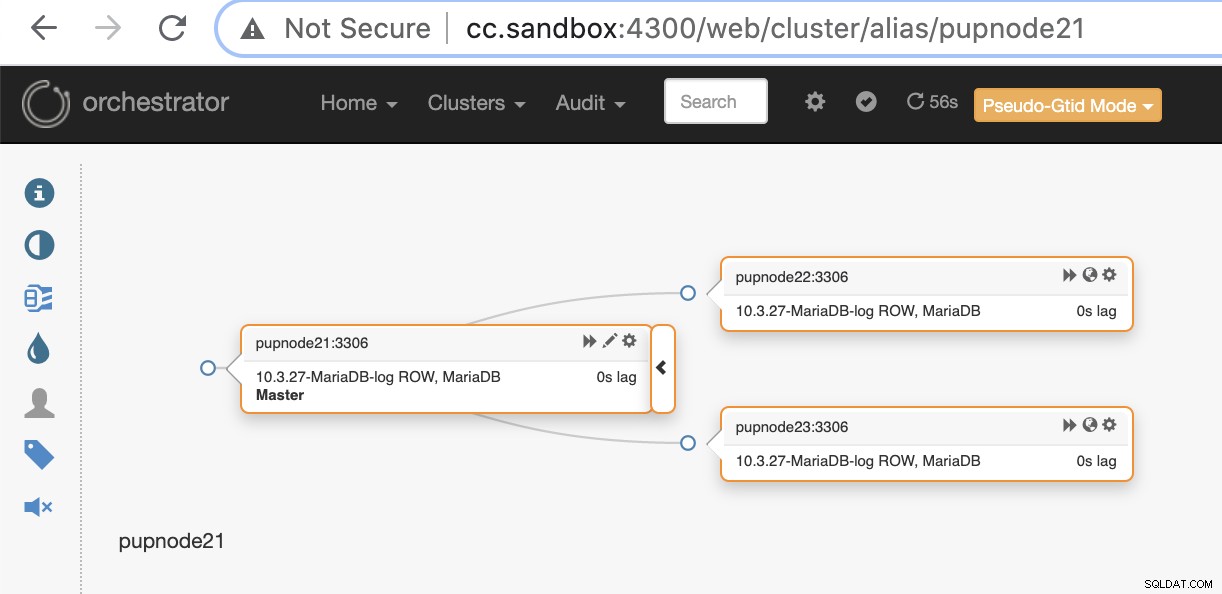
Wenn ein primärer Knoten ausfällt (Hardwarefehler oder Absturz), wird Orchestrator dies tun erkennen und finden Sie den am weitesten fortgeschrittenen Knoten, der als primärer oder Master-Knoten heraufgestuft werden soll.
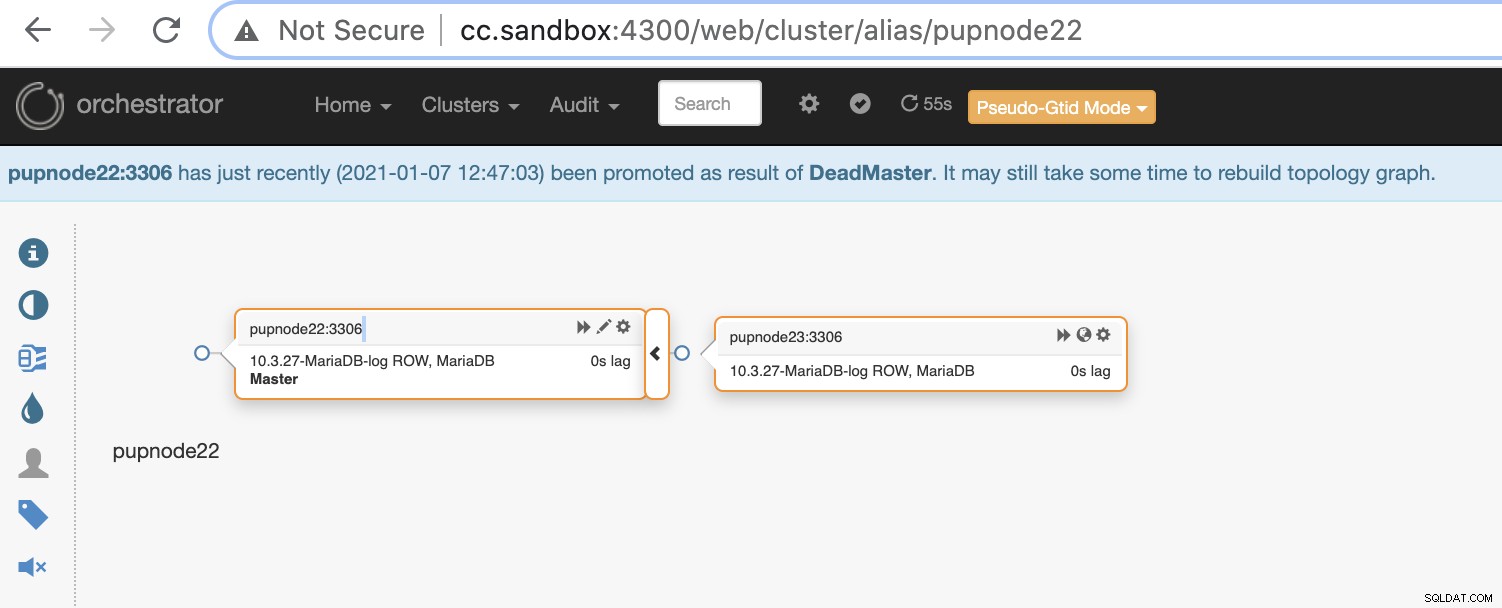
Jetzt verbleiben zwei Knoten im Cluster, während der primäre ausgefallen ist .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]MaxScale verwenden
MariaDB MaxScale wurde als Datenbank-Load-Balancer unterstützt. Im Laufe der Jahre ist MaxScale gewachsen und gereift und wurde um mehrere reichhaltige Funktionen erweitert, darunter automatisches Failover. Seit der Veröffentlichung von MariaDB MaxScale 2.2 wurden mehrere neue Funktionen eingeführt, darunter die Failover-Verwaltung für Replikationscluster. Sie können unseren vorherigen Blog zum MaxScale-Failover-Mechanismus lesen.
Die Verwendung von MaxScale ist unter BSL, obwohl die Software frei verfügbar ist, aber erfordert, dass Sie zumindest Service mit MariaDB kaufen. Es ist möglicherweise nicht geeignet, aber falls Sie MariaDB-Unternehmensdienste erworben haben, kann dies ein großer Vorteil sein, wenn Sie die Failover-Verwaltung und ihre anderen Funktionen benötigen.
Die Installation von MaxScale ist einfach, aber das Einrichten der erforderlichen Konfiguration und das Definieren ihrer Parameter ist es nicht und erfordert, dass Sie die Software verstehen. Sie können sich auf deren Konfigurationsanleitung beziehen.
Für eine schnelle Bereitstellung können Sie ClusterControl verwenden, um MaxScale für Sie in Ihrer bestehenden MySQL/MariaDB-Umgebung zu installieren.
Nach der Installation können Sie Ihre Moodle-Datenbank einrichten, indem Sie Ihren Host auf die MaxScale-IP oder den Hostnamen und den Lese-Schreib-Port verweisen. Zum Beispiel
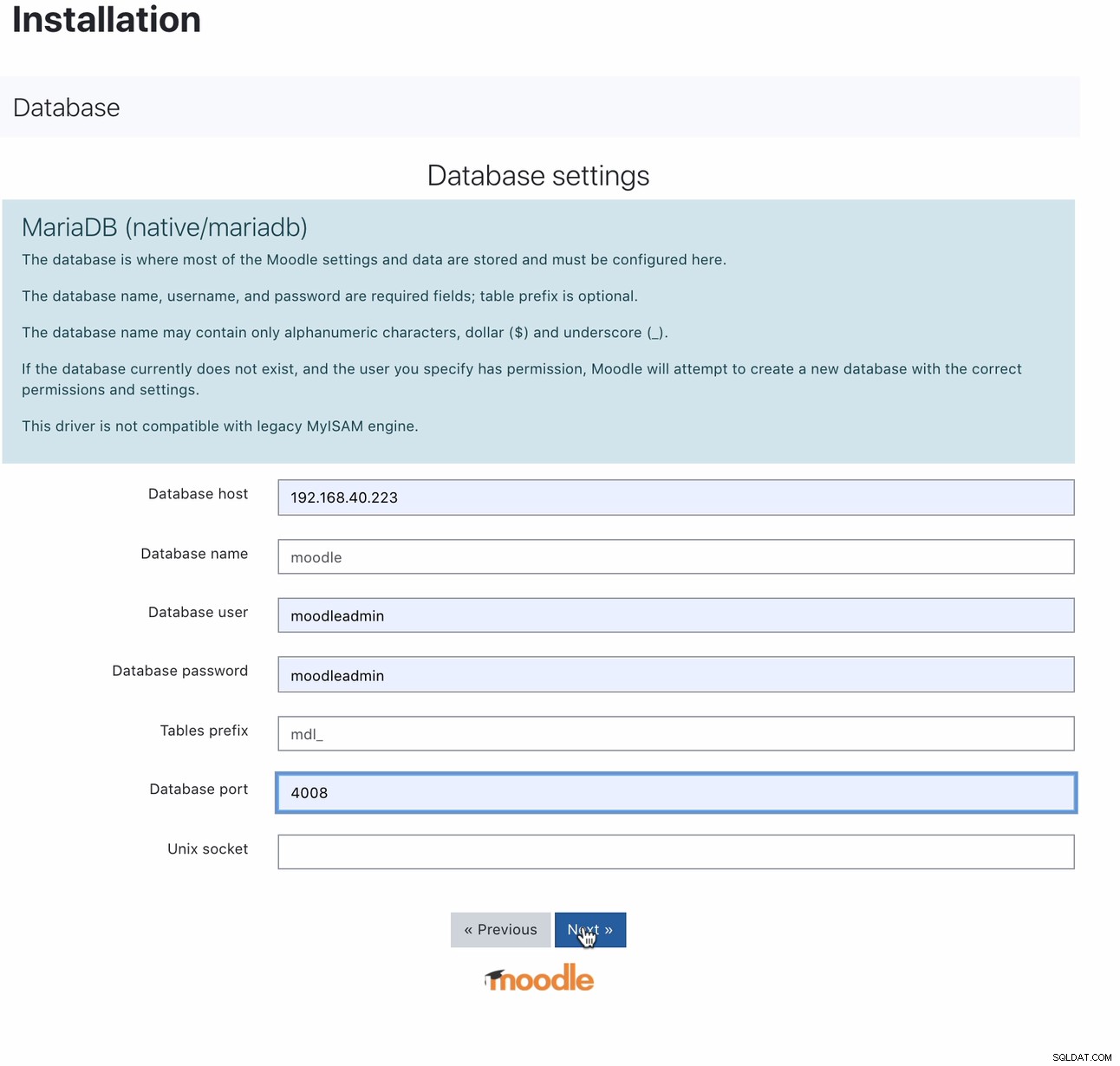
Für welchen Port 4008 ist Ihr Lese-/Schreibzugriff für Ihren Service-Listener. Hier ist zum Beispiel die folgende Service- und Listener-Konfiguration für meine MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseWährend Sie sich in Ihrer Monitorkonfiguration befinden, dürfen Sie nicht vergessen, das automatische Failover zu aktivieren oder auch die automatische Wiederverbindung zu aktivieren, wenn Sie möchten, dass der vorherige Master nicht automatisch wieder verbunden wird, wenn er wieder online geht. Es geht so,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Beachten Sie, dass die von mir angegebenen Variablen nicht für die Verwendung in der Produktion gedacht sind, sondern nur für diesen Blogbeitrag und Testzwecke. Das Gute an MaxScale ist, dass MaxScale, sobald der Primary oder Master ausfällt, schlau genug ist, den idealen oder besten Kandidaten für die Rolle des Masters zu befördern. Daher müssen Sie Ihre IP und Ihren Port nicht ändern, da wir den Host/IP unseres MaxScale-Knotens und seinen Port als unseren Endpunkt verwendet haben, sobald der Master ausfällt. Zum Beispiel
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Knoten DB_123, der auf 192.168.40.221 zeigt, ist der aktuelle Master. Das Beenden des Knotens DB_123 soll MaxScale veranlassen, ein Failover durchzuführen, und es sollte so aussehen:
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Während unsere Moodle-Datenbank immer noch aktiv ist und läuft, da unsere MaxScale auf den neuesten Master verweist, der befördert wurde.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)ClusterControl verwenden
ClusterControl kann kostenlos heruntergeladen werden und bietet Lizenzen für Community, Advance und Enterprise. Das automatische Failover ist nur auf Advance und Enterprise verfügbar. Automatisches Failover wird von unserer Auto-Recovery-Funktion abgedeckt, die versucht, einen ausgefallenen Cluster oder einen ausgefallenen Knoten wiederherzustellen. Wenn Sie weitere Einzelheiten dazu wünschen, lesen Sie unseren vorherigen Beitrag How ClusterControl Performs Automatic Database Recovery and Failover. Es bietet abstimmbare Parameter, die sehr bequem und einfach zu bedienen sind. Bitte lesen Sie auch unseren vorherigen Beitrag zum Automatisieren des Datenbank-Failovers mit ClusterControl.
Die Verwaltung Ihres automatischen Failover für Ihre Moodle-Datenbank muss mindestens eine virtuelle IP (VIP) als Ihren Endpunkt für Ihren Moodle-Anwendungsclient erfordern, der mit Ihrem Datenbank-Backend verbunden ist. Dazu können Sie Keepalived mit HAProxy (oder ProxySQL – abhängig von Ihrer Wahl des Load-Balancers) darüber hinaus bereitstellen. In diesem Fall muss Ihr Endpunkt der Moodle-Datenbank auf die virtuelle IP verweisen, die grundsätzlich von Keepalived zugewiesen wird, sobald Sie sie bereitgestellt haben, so wie wir es Ihnen zuvor bei der Einrichtung von MaxScale gezeigt haben. Sie können auch in diesem Blog nachsehen, wie es geht.
Wie oben erwähnt, sind einstellbare Parameter verfügbar, die Sie einfach über Ihre /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl ist sehr flexibel bei der Verwaltung des Failover, sodass Sie einige Aufgaben vor oder nach dem Failover erledigen können.
Fazit
Es gibt noch andere großartige Möglichkeiten, wenn Sie Ihr Failover für Ihre MySQL-Datenbank für Moodle einrichten und automatisch verwalten. Es hängt von Ihrem Budget ab und wofür Sie wahrscheinlich Geld ausgeben müssen. Die Verwendung von Open Source erfordert Fachwissen und erfordert mehrere Tests, um sich vertraut zu machen, da es außer der Community keinen Support gibt, den Sie ausführen können, wenn Sie Hilfe benötigen. Bei Unternehmenslösungen ist dies mit einem Preis verbunden, bietet Ihnen jedoch Unterstützung und Erleichterung, da die zeitaufwändige Arbeit verringert werden kann. Beachten Sie, dass ein versehentlich verwendetes Failover Ihrer Datenbank Schaden zufügen kann, wenn es nicht ordnungsgemäß gehandhabt und verwaltet wird. Konzentrieren Sie sich darauf, was wichtiger ist und wie Sie die Lösungen beherrschen, die Sie für die Verwaltung Ihres Moodle-Datenbank-Failovers verwenden.