Gruppierte Verkettung ist ein häufiges Problem in SQL Server, ohne direkte und absichtliche Funktionen, die es unterstützen (wie XMLAGG in Oracle, STRING_AGG oder ARRAY_TO_STRING(ARRAY_AGG()) in PostgreSQL und GROUP_CONCAT in MySQL). Es wurde angefordert, aber noch kein Erfolg, wie aus diesen Connect-Elementen hervorgeht:
- Connect #247118 :SQL benötigt Version der MySQL-Funktion group_Concat (verschoben)
- Connect #728969 :Ordered Set Functions – WITHIN GROUP Clause (Closed as Won't Fix)
** UPDATE Januar 2017 ** :STRING_AGG() wird in SQL Server 2017 enthalten sein; Lesen Sie darüber hier, hier und hier.
Was ist gruppierte Verkettung?
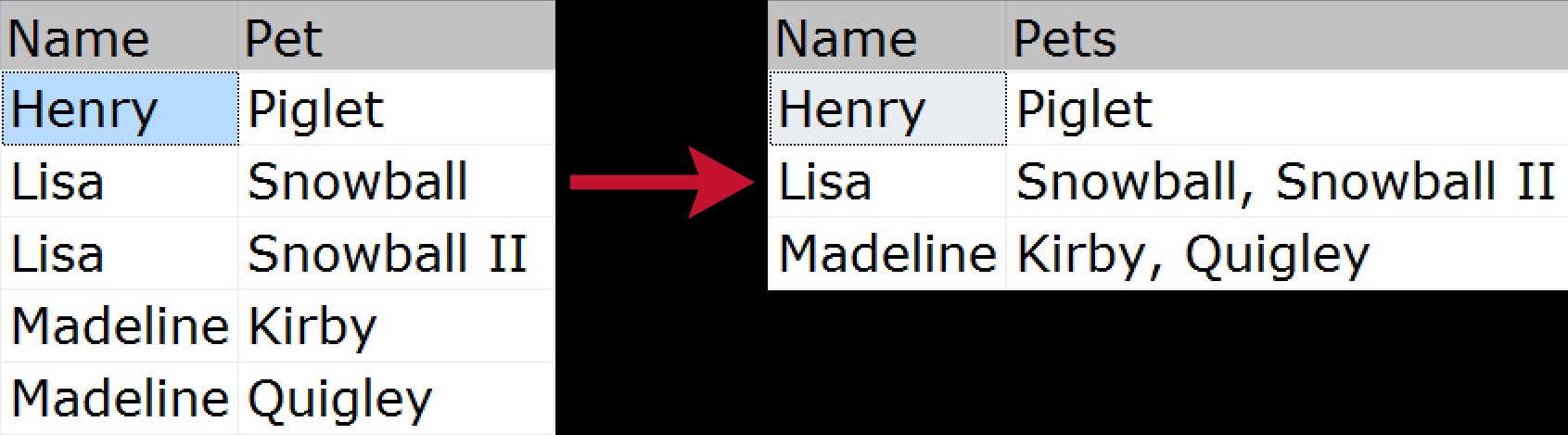
Für die nicht initiierte, gruppierte Verkettung ist es, wenn Sie mehrere Datenzeilen nehmen und sie in eine einzige Zeichenfolge komprimieren möchten (normalerweise mit Trennzeichen wie Kommas, Tabulatoren oder Leerzeichen). Einige nennen dies vielleicht einen „horizontalen Join“. Ein schnelles visuelles Beispiel, das demonstriert, wie wir eine Liste von Haustieren komprimieren würden, die jedem Familienmitglied gehören, von der normalisierten Quelle zur "abgeflachten" Ausgabe:
Im Laufe der Jahre gab es viele Möglichkeiten, dieses Problem zu lösen; Hier sind nur einige, basierend auf den folgenden Beispieldaten:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Ich werde keine erschöpfende Liste aller gruppierten Verkettungsansätze demonstrieren, die jemals konzipiert wurden, da ich mich auf einige Aspekte meines empfohlenen Ansatzes konzentrieren möchte, aber ich möchte auf einige der gebräuchlicheren hinweisen:
Skalare UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Hinweis:Es gibt einen Grund, warum wir dies nicht tun:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Mit DISTINCT , die Funktion wird für jede einzelne Zeile ausgeführt, dann werden Duplikate entfernt; mit GROUP BY , die Duplikate werden zuerst entfernt.
Common Language Runtime (CLR)
Dies verwendet den GROUP_CONCAT_S Funktion finden Sie unter https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Rekursiver CTE
Es gibt mehrere Variationen dieser Rekursion; Dieser zieht eine Reihe eindeutiger Namen als Anker heraus:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Cursor
Hier gibt es nicht viel zu sagen; Cursor sind normalerweise nicht der optimale Ansatz, aber dies kann Ihre einzige Wahl sein, wenn Sie auf SQL Server 2000 festsitzen:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Skurriles Update
Manche Leute *lieben* diesen Ansatz; Ich verstehe die Anziehungskraft überhaupt nicht.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; FÜR XML-PFAD
Ziemlich leicht meine bevorzugte Methode, zumindest teilweise, weil es die einzige Möglichkeit ist, eine Bestellung zu *garantieren*, ohne einen Cursor oder CLR zu verwenden. Das heißt, dies ist eine sehr rohe Version, die einige andere inhärente Probleme nicht anspricht, auf die ich weiter unten eingehen werde:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Ich habe viele Leute gesehen, die fälschlicherweise angenommen haben, dass das neue CONCAT() Die in SQL Server 2012 eingeführte Funktion war die Antwort auf diese Funktionsanforderungen. Diese Funktion soll nur mit Spalten oder Variablen in einer einzelnen Zeile arbeiten; Es kann nicht verwendet werden, um Werte über Zeilen hinweg zu verketten.
Mehr zu FOR XML PATH
FOR XML PATH('') allein ist nicht gut genug – es hat bekannte Probleme mit der XML-Entitierung. Wenn Sie beispielsweise einen der Kosenamen so aktualisieren, dass er eine HTML-Klammer oder ein kaufmännisches Und enthält:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Diese werden irgendwann unterwegs in XML-sichere Einheiten übersetzt:
Qui>gle&y
Also verwende ich immer PATH, TYPE).value() , wie folgt:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Ich verwende auch immer NVARCHAR , da Sie nie wissen, wann eine zugrunde liegende Spalte Unicode enthält (oder später dahingehend geändert wird).
Sie können die folgenden Varianten in .value() sehen , oder sogar andere:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Diese sind austauschbar und stellen letztendlich alle dieselbe Saite dar; die Leistungsunterschiede zwischen ihnen (mehr unten) waren vernachlässigbar und möglicherweise völlig nicht deterministisch.
Ein weiteres Problem, auf das Sie möglicherweise stoßen, sind bestimmte ASCII-Zeichen, die in XML nicht dargestellt werden können. B. wenn der String das Zeichen 0x001A enthält (CHAR(26) ), erhalten Sie diese Fehlermeldung:
FOR XML konnte die Daten für Knoten „NoName“ nicht serialisieren, da sie ein Zeichen (0x001A) enthalten, das in XML nicht zulässig ist. Um diese Daten mit FOR XML abzurufen, konvertieren Sie sie in den Datentyp Binär, Varbinary oder Bild und verwenden Sie die Direktive BINARY BASE64.
Das scheint mir ziemlich kompliziert zu sein, aber hoffentlich müssen Sie sich darüber keine Sorgen machen, weil Sie keine Daten wie diese speichern oder zumindest nicht versuchen, sie in gruppierter Verkettung zu verwenden. Wenn dies der Fall ist, müssen Sie möglicherweise auf einen der anderen Ansätze zurückgreifen.
Leistung
Die obigen Beispieldaten machen es einfach zu beweisen, dass diese Methoden alle das tun, was wir erwarten, aber es ist schwierig, sie sinnvoll zu vergleichen. Also habe ich die Tabelle mit einem viel größeren Satz gefüllt:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Für mich waren das 575 Objekte mit insgesamt 7.080 Zeilen; Das breiteste Objekt hatte 142 Spalten. Auch hier habe ich zugegebenermaßen nicht versucht, jeden einzelnen Ansatz zu vergleichen, der in der Geschichte von SQL Server entwickelt wurde; nur die paar Highlights, die ich oben gepostet habe. Hier waren die Ergebnisse:
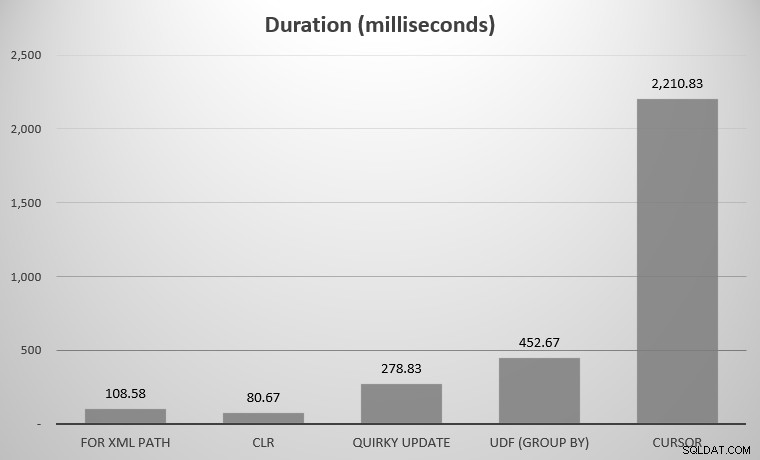
Sie werden vielleicht bemerken, dass ein paar Konkurrenten fehlen; die UDF mit DISTINCT und der rekursive CTE lagen so außerhalb der Charts, dass sie die Skala verzerren würden. Hier die Ergebnisse aller sieben Ansätze in tabellarischer Form:
| Ansatz | Dauer (Millisekunden) |
|---|---|
| FÜR XML-PFAD | 108,58 |
| CLR | 80,67 |
| Skurriles Update | 278,83 |
| UDF (GRUPPE NACH) | 452,67 |
| UDF (DISTINCT) | 5.893,67 |
| Cursor | 2.210,83 |
| Rekursiver CTE | 70.240,58 |
Durchschnittliche Dauer in Millisekunden für alle Ansätze
Beachten Sie auch, dass die Variationen von FOR XML PATH wurden unabhängig getestet, zeigten aber sehr geringe Unterschiede, also habe ich sie nur für den Durchschnitt kombiniert. Wenn Sie es wirklich wissen wollen, der .[1] Notation hat in meinen Tests am schnellsten geklappt; YMMV.
Schlussfolgerung
Wenn Sie nicht in einem Geschäft sind, in dem CLR in irgendeiner Weise eine Straßensperre darstellt, und insbesondere wenn Sie es nicht nur mit einfachen Namen oder anderen Zeichenfolgen zu tun haben, sollten Sie das CodePlex-Projekt unbedingt in Betracht ziehen. Versuchen Sie nicht, das Rad neu zu erfinden, versuchen Sie keine unintuitiven Tricks und Hacks, um CROSS APPLY zu machen oder andere Konstrukte arbeiten nur ein wenig schneller als die oben genannten Nicht-CLR-Ansätze. Nehmen Sie einfach, was funktioniert, und schließen Sie es an. Und zum Teufel, da Sie auch den Quellcode erhalten, können Sie ihn verbessern oder erweitern, wenn Sie möchten.
Wenn CLR ein Problem ist, dann FOR XML PATH ist wahrscheinlich die beste Option, aber Sie müssen trotzdem auf knifflige Charaktere achten. Wenn Sie auf SQL Server 2000 feststecken, ist Ihre einzig mögliche Option die UDF (oder ähnlicher Code, der nicht in eine UDF eingeschlossen ist).
Nächstes Mal
Ein paar Dinge, die ich in einem Folgebeitrag untersuchen möchte:Entfernen von Duplikaten aus der Liste, Sortieren der Liste nach etwas anderem als dem Wert selbst, Fälle, in denen das Einfügen eines dieser Ansätze in eine UDF schmerzhaft sein kann, und praktische Anwendungsfälle für diese Funktionalität.