Im vorherigen Artikel habe ich erklärt, wie wir Ubuntu 18.04 und SQL Server 2019 auf den virtuellen Maschinen installieren können. Bevor wir nun fortfahren, gehen wir die Konfiguration durch.
Wir haben drei virtuelle Maschinen erstellt und die Details sind wie folgt:
| Hostname | IP-Adresse | Rolle |
| LinuxSQL01 | 192.168.0.140 | Primäres Replikat |
| LinuxSQL02 | 192.168.0.141 | Synchrones sekundäres Replikat |
| LinuxSQL03 | 192.168.0.142 | Asynchrones sekundäres Replikat |
Aktualisieren Sie die Hostdatei.
In der Konfiguration verwenden wir keinen Domänenserver. Um den Hostnamen aufzulösen, müssen wir daher einen Eintrag in der Hostdatei hinzufügen.
Die Hostdatei befindet sich unter /etc Verzeichnis. Führen Sie den folgenden Befehl aus, um die Datei zu bearbeiten:
example@sqldat.com:/# vim /etc/hostsGeben Sie in der Hostdatei die Hostnamen und IP-Adressen aller virtuellen Maschinen ein:
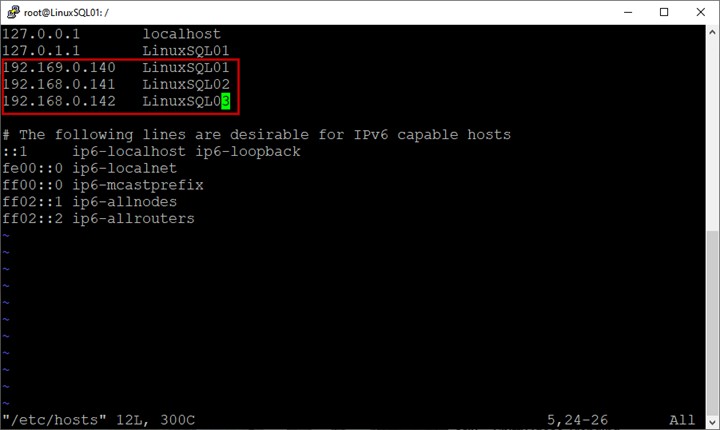
Speichern Sie die Hostdatei.
Führen Sie die gleichen Schritte auf allen virtuellen Maschinen durch.
SQL Server AlwaysOn-Verfügbarkeitsgruppen aktivieren
Vor der Bereitstellung von AlwaysOn müssen wir die Hochverfügbarkeitsfunktion in SQL Server aktivieren.
In Windows Server 2016 kann diese Option über den SQL Server-Konfigurationsmanager aktiviert werden, aber auf der Linux-Plattform müssen wir dies mit einem Bash-Befehl tun.
Stellen Sie mit Putty eine Verbindung zu LinuxSQL01 her und führen Sie den folgenden Befehl aus:
example@sqldat.com:~# sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Starten Sie die SQL Server-Dienste neu:
example@sqldat.com:~# service mssql-server restartFühren Sie die obigen Schritte auf allen virtuellen Maschinen aus.
Erstellen Sie die Zertifikate für die Authentifizierung
Im Gegensatz zu AlwaysOn auf dem Windows-Server ist für die Linux-Bereitstellung kein Domänencontroller erforderlich. Zur Authentifizierung und Kommunikation zwischen primären und sekundären Replikaten wird das Zertifikat verwendet.
Das folgende Skript erstellt ein Zertifikat und einen Hauptschlüssel. Dann sichert es das Zertifikat und sichert es mit einem Passwort.
Verbinden Sie sich mit LinuxSQL01 und führen Sie das folgende Skript aus:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE AG_Auth_Cert
TO FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.pvk',
ENCRYPTION BY PASSWORD = 'abcd!1234'
);
Sobald wir das Zertifikat und den Hauptschlüssel erstellt haben, kopieren wir sie auf sekundäre Replikate (LinuxSQL02 und LinuxSQL03), indem wir den folgenden Befehl ausführen.
Stellen Sie sicher, dass der Hauptschlüssel und der Speicherort des Zertifikats auf allen Replikaten gleich sind und über Lese- und Schreibberechtigungen verfügen.
/*Copy certificate and the key to LinuxSQL02*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
/*Copy certificate and the key to LinuxSQL03*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
Führen Sie den folgenden Befehl auf sekundären Knoten aus, um Lese- und Schreibberechtigungen für das Zertifikat und den privaten Schlüssel zu erteilen:
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
Sobald die Berechtigung zugewiesen wurde, erstellen wir das Zertifikat und den Hauptschlüssel mithilfe der Sicherung des Zertifikats und des Hauptschlüssels, die auf LinuxSQL01 erstellt wurden.
Führen Sie dazu den folgenden Befehl auf beiden sekundären Replikaten aus:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert
FROM FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.pvk',
DECRYPTION BY PASSWORD = 'abcd!1234'
);
Nachdem wir das Zertifikat und den Hauptschlüssel erstellt haben, konfigurieren wir die Datenbankspiegelungspunkte.
Erstellen Sie die Spiegelungsendpunkte
Zur Kommunikation zwischen den primären und sekundären Replikaten verwendet SQL Server Spiegelungsendpunkte.
Ein Spiegelungsendpunkt verwendet das TCP/IP-Protokoll zum Senden und Empfangen von Nachrichten von primären und sekundären Replikaten und überwacht einen eindeutigen TCP/IP-Port.
Führen Sie das folgende Skript aus, um einen Endpunkt auf primären und sekundären Knoten zu erstellen:
/*Run this script on LinuxSQL01*/
CREATE ENDPOINT [AG_LinuxSQL01]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL01] STATE = STARTED;
/*Run this script on LinuxSQL02*/
CREATE ENDPOINT [AG_LinuxSQL02]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL02] STATE = STARTED;
/*Run this script on LinuxSQL03*/
CREATE ENDPOINT [AG_LinuxSQL03]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL03] STATE = STARTED;
Nachdem die Spiegelungspunkte erstellt wurden, erstellen wir eine Verfügbarkeitsgruppe.
Verfügbarkeitsgruppe erstellen
Wir werden AlwaysON mit SQL Server Management Studio konfigurieren.
Starten Sie es zuerst und verbinden Sie sich mit sa mit der LinuxSQL01-Instanz Referenzen. Sobald Sie mit der SQL Server-Instanz verbunden sind, klicken Sie mit der rechten Maustaste auf Immer auf Hochverfügbarkeit und wählen Sie den Assistenten für neue Verfügbarkeitsgruppen aus .
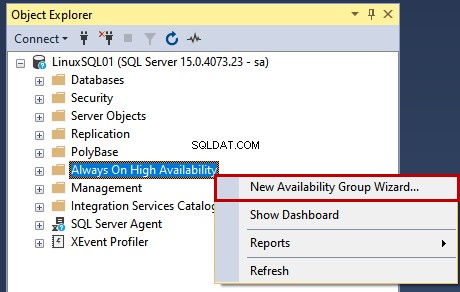
Der Assistent für Verfügbarkeitsgruppen beginnt.
1. Einführung
In einer Einführung sehen Sie sich die Aufgabenliste an, die vom Verfügbarkeitsgruppen-Assistenten ausgeführt wird. Klicken Sie auf Weiter.
2. Geben Sie die Verfügbarkeitsgruppenoption an
Geben Sie auf dem Bildschirm „Option für Verfügbarkeitsgruppe angeben“ den gewünschten Namen für die Verfügbarkeitsgruppe ein und wählen Sie EXTERN aus vom Clustertyp Dropdown-Menü.
Setzen Sie außerdem ein Häkchen bei Integritätserkennung auf Datenbankebene Kontrollkästchen. Es aktiviert die erweiterte Ereignissitzung für die Verfügbarkeit der Gruppengesundheit.
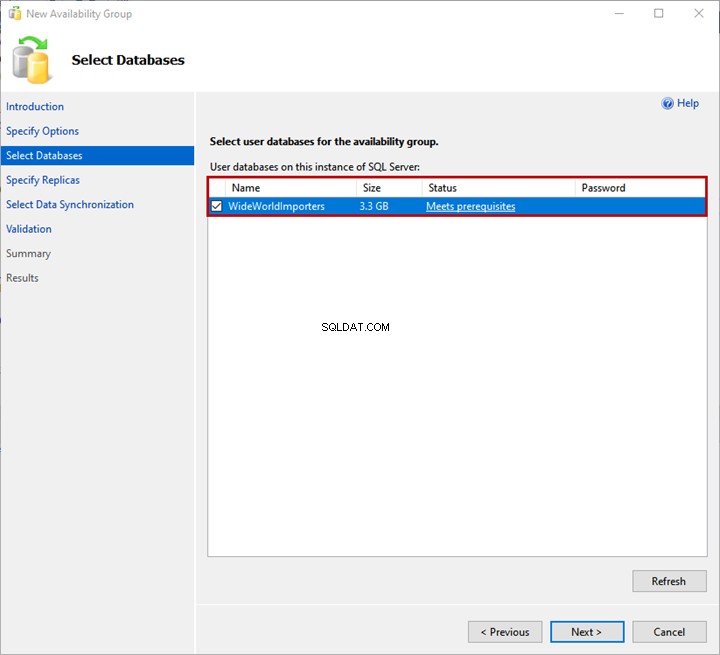
3. Datenbanken auswählen
Unter Datenbanken auswählen können Sie die Datenbank auswählen, die der Verfügbarkeitsgruppe hinzugefügt werden soll Bildschirm. Hinweis:Die Datenbank muss die folgenden Voraussetzungen erfüllen:
- Die Datenbank muss sich im FULL-Wiederherstellungsmodell befinden.
- Eine VOLLSTÄNDIGE Sicherung der Datenbank muss erstellt werden.
Ich habe ein Backup der WideWorldImportors wiederhergestellt Datenbank auf dem primären Replikat. Die Datenbank ist VOLL Wiederherstellungsmodell, und es wurde eine vollständige Sicherung erstellt.
Wählen Sie die WideWorldImportors aus Datenbank aus der Liste und klicken Sie auf Weiter .
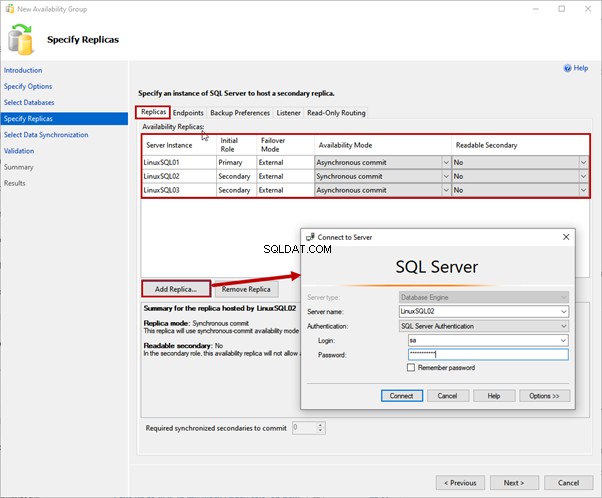
4. Replikate angeben
Klicken Sie auf Replikate angeben Bildschirm haben wir mehrere Registerkarten, um verschiedene Optionen zu konfigurieren. Sehen wir sie uns alle an.
Replikate-Registerkarte
Hier geben wir die primären und sekundären Replikate, den Verfügbarkeitsmodus und die Failover-Modi an.
Wir verwenden LinuxSQL01 als primäres Replikat. LinuxSQL02 und LinuxSQL03 sind ein sekundäres Replikat.
Der Verfügbarkeitsmodus für LinuxSQL02 wird Synchroner Commit sein und für LinuxSQL03 wird Asynchroner Commit sein .
Um das Replikat hinzuzufügen, klicken Sie auf Replikat hinzufügen . Dann auf Mit dem Server verbinden Dialogfeld Geben Sie den Servernamen und die SQL-Anmeldedetails an um sich mit der Instanz zu verbinden:
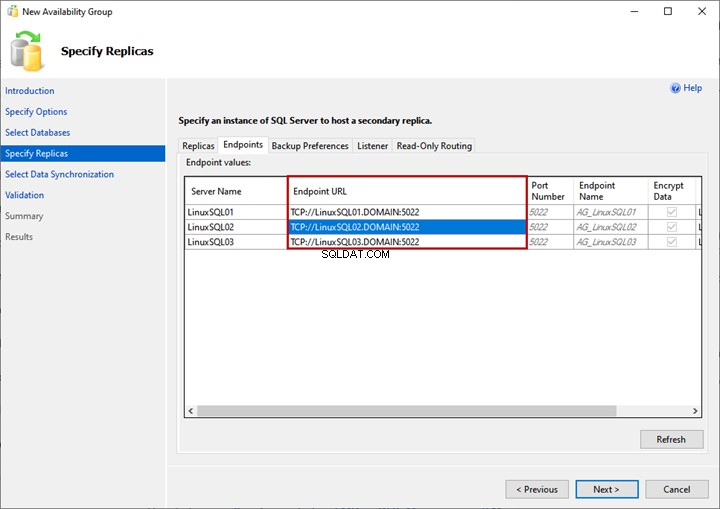
Registerkarte "Endpunkte"
Hier können wir die Liste der Replikate und ihrer Spiegelungsendpunkte mit den entsprechenden Portnummern und Namen anzeigen:
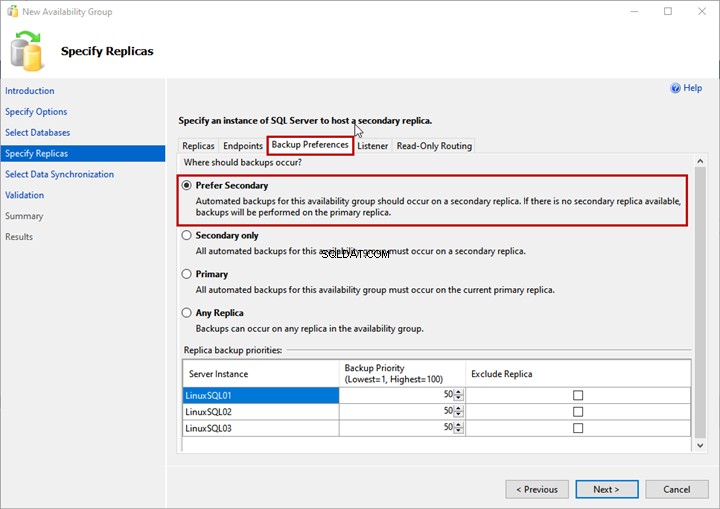
Sicherungseinstellungen
Hier geben Sie das Replikat an, das Sie zum Generieren der Sicherung verwenden möchten. Diese Option ist nützlich, wenn Sie den SQL-Datenbanksicherungsprozess innerhalb der Verfügbarkeitsgruppe auslagern möchten.
Sie können eine der folgenden Optionen wählen:
- Sekundär bevorzugen:Die Sicherung wird auf dem sekundären Replikat generiert. Wenn das sekundäre Replikat nicht verfügbar ist, wird die Sicherung auf dem primären Replikat erstellt.
- Nur sekundär:Alle Sicherungen werden auf dem sekundären Replikat generiert.
- Primär:Sicherungen werden auf dem primären Replikat erstellt.
- Jedes Replikat:Die Sicherung wird von jedem der Replikate erstellt.
Wir verwenden Secondary bevorzugen Möglichkeit:
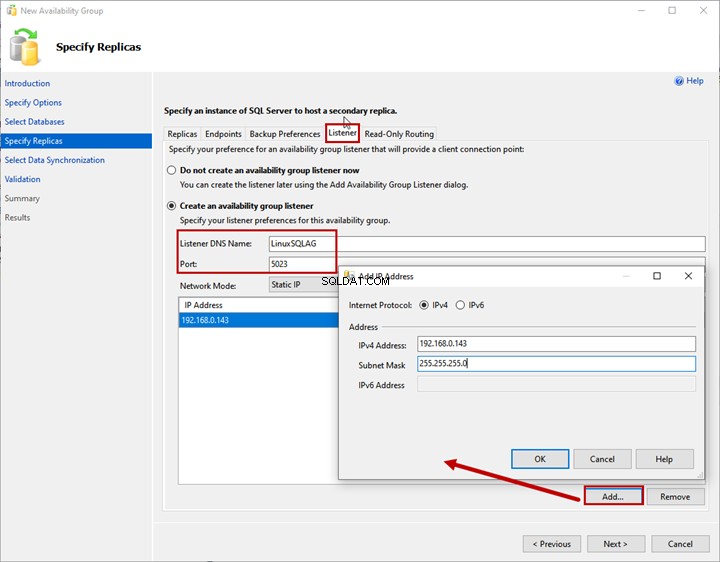
Zuhörer
Der Verfügbarkeitsgruppenlistener ist ein virtueller Name, der von einer Anwendung zum Herstellen einer Verbindung mit den Verfügbarkeitsgruppendatenbanken verwendet wird. Geben Sie den Listener-DNS-Namen und seinen Port in Listener-DNS-Name an undPort Textfelder.
Wählen Sie Statische IP aus aus dem Netzwerkmodus Dropdown-Menü.
Um die IP-Adresse für den Verfügbarkeitsgruppen-Listener hinzuzufügen, klicken Sie auf Hinzufügen >Geben Sie IP-Adresse ein und Subnetzmaske .
Nur-Lese-Routing
Hier können Sie die schreibgeschützte Routing-URL angeben und Schreibgeschützte Weiterleitungsliste für primäre und sekundäre Replikate.
Wir werden in unserer Demonstration kein schreibgeschütztes Routing konfigurieren. Klicken Sie daher auf Weiter. Weitere Informationen zum schreibgeschützten Routing finden Sie unter Read-only Routing for an Always On.
Kommen wir nun zurück zum Hauptprozess, an dem wir arbeiten.
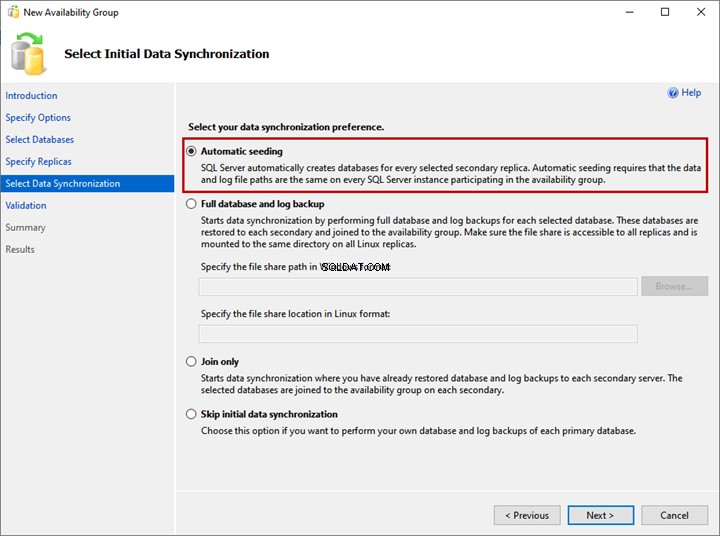
5. Wählen Sie Initiale Datensynchronisierung aus
Klicken Sie auf Anfängliche Datensynchronisierung auswählen Legen Sie auf dem Bildschirm Ihre Einstellungen für die anfängliche Datensynchronisierung fest. Einzelheiten zu jeder Option werden auf dem Bildschirm des Assistenten bereitgestellt, und Sie können eine davon auswählen:
- Automatisches Seeding.
- Vollständige Datenbank- und Protokollsicherung.
- Nur beitreten.
- Erste Datensynchronisierung überspringen.
Ich habe die WideWorldImportors nicht erstellt Datenbank auf dem LinuxSQL02- und LinuxSQL03-Replikat, indem Sie Automatisches Seeding auswählen Möglichkeit. Es erstellt die Datenbank auf beiden Replikaten und startet die Datensynchronisierung. Klicken Sie auf Weiter.
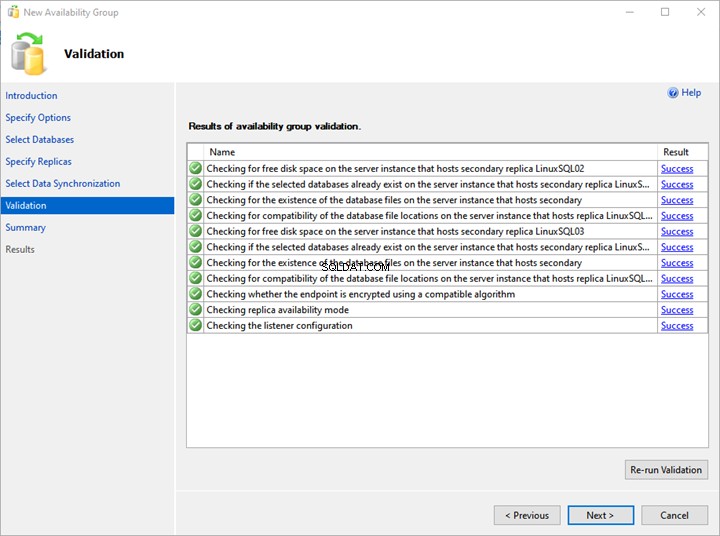
6. Validierung und Zusammenfassung
Auf der Validierung Bildschirm bestätigt der Assistent alle Konfigurationen.
Um die AlwaysOn-Verfügbarkeitsgruppe erfolgreich bereitzustellen, müssen alle Validierungen erfolgreich sein. Wenn ein Fehler auftritt, müssen Sie ihn beheben.
Auf der Zusammenfassung Bildschirm können Sie die Liste der Konfigurationen sehen, die zum Bereitstellen der Verfügbarkeitsgruppe ausgewählt wurden.
Überprüfen Sie die Details noch einmal und klicken Sie auf Fertig stellen – Es startet den Bereitstellungsprozess.
Wenn Sie das Skript des Bereitstellungsprozesses generieren möchten, klicken Sie auf Skript .
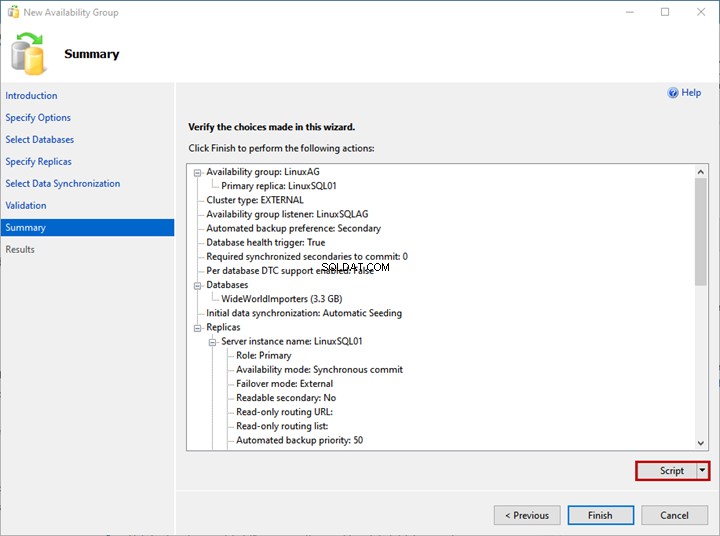
Wie wir sehen, beginnt der AlwaysOn-Bereitstellungsprozess. Klicken Sie nach erfolgreichem Abschluss auf Schließen um den Assistenten zu beenden.
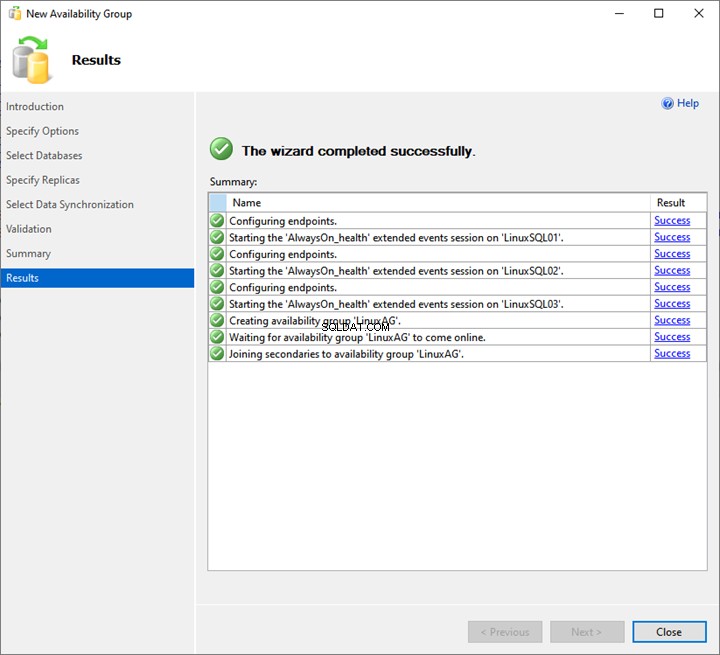
Damit ist die Bereitstellung der AlwaysOn-Verfügbarkeitsgruppe auf SQL Server 2019 abgeschlossen.
Zusammenfassung
Dieser Artikel hilft uns, den schrittweisen Bereitstellungsprozess der SQL Server AlwaysOn-Verfügbarkeitsgruppe unter Linux zu verstehen.
Im nächsten Artikel wird erläutert, wie wir den Verfügbarkeitsgruppenlistener konfigurieren und ein manuelles Failover mit SQL Server Management Studio durchführen können. Bleiben Sie dran!