Seit der Veröffentlichung von SQL Server 2017 für Linux hat Microsoft so ziemlich das gesamte Spiel verändert. Es eröffnete eine ganze Welt neuer Möglichkeiten für ihre berühmte relationale Datenbank und bot das, was bis dahin nur im Windows-Bereich verfügbar war.
Ich weiß, dass ein puristischer DBA mir sofort sagen würde, dass die sofort einsatzbereite Linux-Version von SQL Server 2019 in Bezug auf die Funktionen einige Unterschiede zu ihrem Windows-Pendant aufweist, wie zum Beispiel:
- Kein SQL Server-Agent
- Kein FileStream
- Keine erweiterten gespeicherten Systemprozeduren (z. B. xp_cmdshell)
Ich wurde jedoch neugierig genug, um zu denken:„Was wäre, wenn sie zumindest bis zu einem gewissen Grad mit Dingen verglichen werden könnten, die beide tun können?“ Also habe ich den Auslöser für ein paar VMs gedrückt, einige einfache Tests vorbereitet und Daten gesammelt, um sie Ihnen zu präsentieren. Mal sehen, wie sich die Dinge entwickeln!
Erste Überlegungen
Hier sind die Spezifikationen jeder VM:
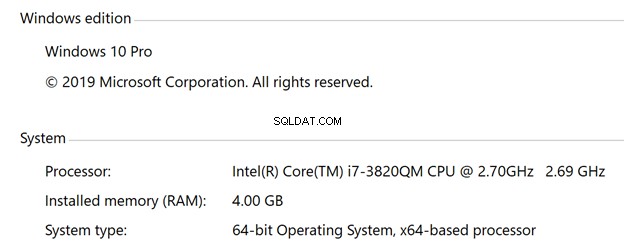
- Windows
- Windows 10-Betriebssystem
- 4 vCPUs
- 4 GB Arbeitsspeicher
- 30-GB-SSD
- Linux
- Ubuntu Server 20.04 LTS
- 4 vCPUs
- 4 GB Arbeitsspeicher
- 30-GB-SSD


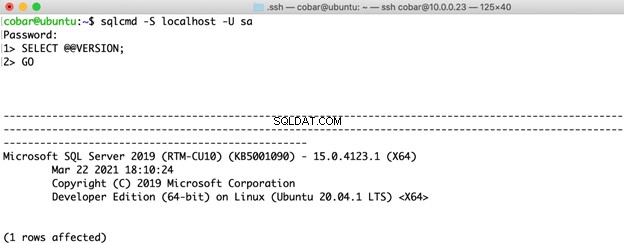
Für die SQL Server-Version habe ich die allerneueste Version für beide Betriebssysteme ausgewählt:SQL Server 2019 Developer Edition CU10
In jeder Bereitstellung war nur die sofortige Dateiinitialisierung aktiviert (standardmäßig aktiviert unter Linux, manuell aktiviert unter Windows). Ansonsten blieben die Standardwerte für die restlichen Einstellungen erhalten.
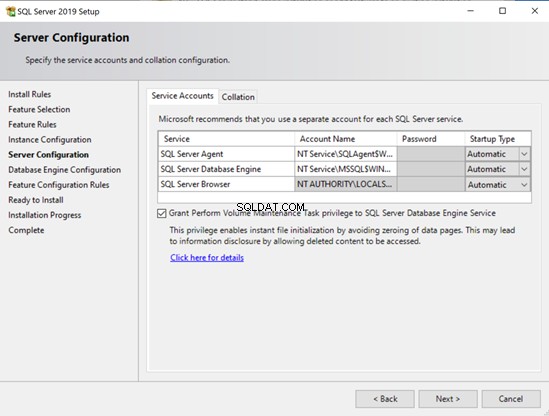
- Unter Windows können Sie die sofortige Dateiinitialisierung mit dem Installationsassistenten aktivieren.
Dieser Beitrag behandelt nicht die Besonderheiten der Instant File Initialization-Arbeit in Linux. Ich hinterlasse Ihnen jedoch einen Link zu dem speziellen Artikel, den Sie später lesen können (beachten Sie, dass es auf der technischen Seite etwas schwer wird).
Was beinhaltet der Test?
- In jeder SQL Server 2019-Instanz habe ich eine Testdatenbank bereitgestellt und eine Tabelle mit nur einem Feld erstellt (ein NVARCHAR(MAX)).
- Mit einer zufällig generierten Zeichenfolge von 1.000.000 Zeichen habe ich die folgenden Schritte ausgeführt:
- *Fügen Sie eine Anzahl von X Zeilen in die Testtabelle ein.
- Messen Sie, wie viel Zeit es gedauert hat, die INSERT-Anweisung abzuschließen.
- Messen Sie die Größe der MDF- und LDF-Dateien.
- Alle Zeilen in der Testtabelle löschen.
- **Messen Sie, wie viel Zeit es gedauert hat, die DELETE-Anweisung abzuschließen.
- Messen Sie die Größe der LDF-Datei.
- Löschen Sie die Testdatenbank.
- Erstellen Sie die Testdatenbank erneut.
- Wiederholen Sie denselben Zyklus.
*X wurde für 1.000, 5.000, 10.000, 25.000 und 50.000 Zeilen durchgeführt.
**Ich weiß, dass eine TRUNCATE-Anweisung die Arbeit viel effizienter erledigt, aber hier möchte ich beweisen, wie gut jedes Transaktionsprotokoll für den Löschvorgang in jedem Betriebssystem verwaltet wird.
Sie können zu der Website weitergehen, die ich verwendet habe, um die Zufallszeichenfolge zu generieren, wenn Sie tiefer graben möchten.
Hier sind die Abschnitte des TSQL-Codes, den ich für Tests in jedem Betriebssystem verwendet habe:
Linux TSQL-Codes
Datenbank- und Tabellenerstellung
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
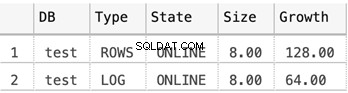
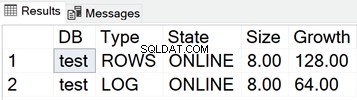
Größe der MDF- und LDF-Dateien für die Testdatenbank
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Der folgende Screenshot zeigt die Größe der Datendateien, wenn nichts in der Datenbank gespeichert ist:
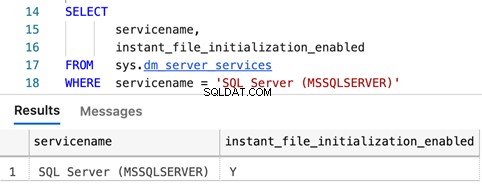
Abfragen, um festzustellen, ob die sofortige Dateiinitialisierung aktiviert ist
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Windows TSQL-Codes
Datenbank- und Tabellenerstellung
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
Größe der MDF- und LDF-Dateien für die Testdatenbank
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Der folgende Screenshot zeigt die Größe der Datendateien, wenn nichts in der Datenbank gespeichert ist:
Abfrage, ob Instant File Initialization aktiviert ist
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Skript zum Ausführen der INSERT-Anweisung:
@limit -> hier habe ich die Anzahl der Zeilen angegeben, die in die Testtabelle eingefügt werden sollen
Da ich das Skript unter Linux mit SQLCMD ausgeführt habe, habe ich die DATEDIFF-Funktion ganz am Ende eingefügt. Es lässt mich wissen, wie viele Sekunden die gesamte Ausführung dauert (für die Windows-Variante hätte ich einfach einen Blick auf den Timer in SQL Server Management Studio werfen können).
Die ganze Zeichenfolge von 1.000.000 Zeichen wird anstelle von „XXXX“ angezeigt. Ich sage es nur so, um es in diesem Beitrag schön darzustellen.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Skript zum Ausführen der DELETE-Anweisung
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Die erzielten Ergebnisse
Alle Größen werden in MB ausgedrückt. Alle Zeitmessungen werden in Sekunden ausgedrückt.
| ZEIT EINFÜGEN | 1.000 Datensätze | 5.000 Datensätze | 10.000 Datensätze | 25.000 Datensätze | 50.000 Datensätze |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Windows | 4 | 28 | 172 | 531 | 186 |
| Größe (MDF) | 1.000 Datensätze | 5.000 Datensätze | 10.000 Datensätze | 25.000 Datensätze | 50.000 Datensätze |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Windows | 264 | 1032 | 2056 | 5128 | 10248 |
| Größe (LDF) | 1.000 Datensätze | 5.000 Datensätze | 10.000 Datensätze | 25.000 Datensätze | 50.000 Datensätze |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Windows | 136 | 328 | 392 | 456 | 584 |
| Zeit löschen | 1.000 Datensätze | 5.000 Datensätze | 10.000 Datensätze | 25.000 Datensätze | 50.000 Datensätze |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Windows | 1 | 63 | 126 | 357 | 396 |
| Größe LÖSCHEN (LDF) | 1.000 Datensätze | 5.000 Datensätze | 10.000 Datensätze | 25.000 Datensätze | 50.000 Datensätze |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Windows | 200 | 328 | 392 | 456 | 712 |
Wichtige Erkenntnisse
- Die Größe des MDF war während des gesamten Tests ziemlich konstant und variierte am Ende leicht (aber nicht zu verrückt).
- Die Timings für INSERTs waren unter Linux größtenteils besser, außer ganz am Ende, als Windows „die Runde gewann“.
- Die Größe der Transaktionsprotokolldatei wurde unter Linux nach jeder Runde von INSERTs besser gehandhabt.
- Die Timings für DELETEs waren unter Linux größtenteils besser, außer ganz am Ende, wo Windows „die Runde gewann“ (ich finde es merkwürdig, dass Windows auch die letzte INSERT-Runde gewann).
- Die Größe der Transaktionsprotokolldateien nach jeder DELETE-Runde war in Bezug auf Höhen und Tiefen zwischen den beiden ziemlich gleich.
- Ich hätte gerne mit 100.000 Zeilen getestet, aber mir fehlte etwas Speicherplatz, also habe ich es auf 50.000 begrenzt.
Schlussfolgerung
Basierend auf den Ergebnissen dieses Tests würde ich sagen, dass es keinen triftigen Grund gibt zu behaupten, dass die Linux-Variante exponentiell besser abschneidet als ihr Windows-Pendant. Natürlich ist dies keineswegs ein formaler Test, auf den Sie sich stützen können, um eine solche Entscheidung zu treffen. Die Übung selbst war jedoch interessant genug für mich.
Ich würde vermuten, dass SQL Server 2019 für Windows aufgrund des GUI-Renderings im Hintergrund manchmal etwas (nicht viel) hinterherhinkt, was auf der Ubuntu-Server-Seite des Zauns nicht passiert.
Wenn Sie sich stark auf Funktionen und Fähigkeiten verlassen, die exklusiv für Windows sind (zumindest zum Zeitpunkt des Schreibens dieses Artikels), dann entscheiden Sie sich auf jeden Fall dafür. Andernfalls werden Sie kaum eine schlechte Wahl treffen, wenn Sie sich für eines entscheiden.



