Wenn wir eine gespeicherte Prozedur schreiben, möchten wir oft, dass sie sich je nach Benutzereingabe unterschiedlich verhält. Sehen wir uns das folgende Beispiel an:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Diese gespeicherte Prozedur, die ich in der AdventureWorks2017-Datenbank erstellt habe, hat zwei Parameter:@CustomerID und @SortOrder. Der erste Parameter, @CustomerID, wirkt sich auf die zurückzugebenden Zeilen aus. Wenn der gespeicherten Prozedur eine bestimmte Kunden-ID übergeben wird, gibt sie alle Bestellungen (Top 10) für diesen Kunden zurück. Andernfalls, wenn es NULL ist, gibt die gespeicherte Prozedur alle Bestellungen (Top 10) zurück, unabhängig vom Kunden. Der zweite Parameter, @SortOrder, bestimmt, wie die Daten sortiert werden – nach OrderDate oder nach SalesOrderID. Beachten Sie, dass nur die ersten 10 Zeilen gemäß der Sortierreihenfolge zurückgegeben werden.
Benutzer können das Verhalten der Abfrage also auf zwei Arten beeinflussen – welche Zeilen zurückgegeben werden und wie sie sortiert werden. Genauer gesagt gibt es 4 verschiedene Verhaltensweisen für diese Abfrage:
- Gibt die obersten 10 Zeilen für alle Kunden sortiert nach Bestelldatum zurück (Standardverhalten)
- Die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach Bestelldatum zurückgeben
- Die obersten 10 Zeilen für alle Kunden sortiert nach SalesOrderID zurückgeben
- Die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach SalesOrderID zurückgeben
Lassen Sie uns die gespeicherte Prozedur mit allen 4 Optionen testen und den Ausführungsplan und die Statistik-IO untersuchen.
Gib die obersten 10 Zeilen für alle Kunden sortiert nach Bestelldatum zurück
Das Folgende ist der Code zum Ausführen der gespeicherten Prozedur:
EXECUTE Sales.GetOrders; GO
Hier ist der Ausführungsplan:
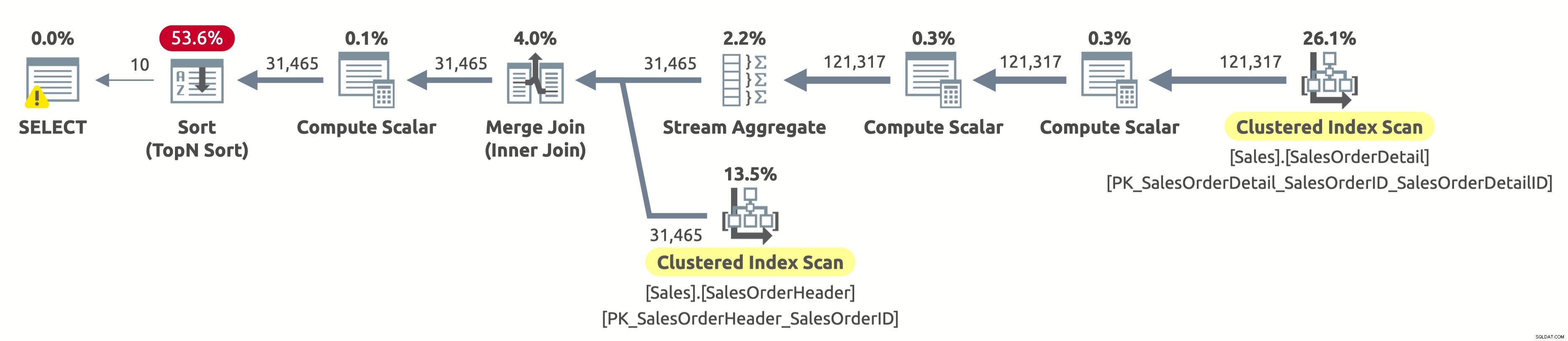
Da wir nicht nach Kunden gefiltert haben, müssen wir die gesamte Tabelle scannen. Der Optimierer entschied sich dafür, beide Tabellen unter Verwendung von Indizes auf SalesOrderID zu scannen, was eine effiziente Stream-Aggregation sowie einen effizienten Merge-Join ermöglichte.
Wenn Sie die Eigenschaften des Clustered Index Scan-Operators in der Sales.SalesOrderHeader-Tabelle überprüfen, finden Sie das folgende Prädikat:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @Kunden-ID] ODER [@Kunden-ID] IST NULL. Der Abfrageprozessor muss dieses Prädikat für jede Zeile in der Tabelle auswerten, was nicht sehr effizient ist, da es immer als wahr ausgewertet wird.
Wir müssen noch alle Daten nach OrderDate sortieren, um die ersten 10 Zeilen zurückzugeben. Wenn es einen Index für OrderDate gäbe, hätte der Optimierer ihn wahrscheinlich verwendet, um nur die ersten 10 Zeilen von Sales.SalesOrderHeader zu scannen, aber es gibt keinen solchen Index, also scheint der Plan in Anbetracht der verfügbaren Indizes in Ordnung zu sein.
Hier ist die Ausgabe von Statistik IO:
- Tabelle 'SalesOrderHeader'. Scananzahl 1, logische Lesevorgänge 689
- Tabelle 'SalesOrderDetail'. Scananzahl 1, logische Lesevorgänge 1248
Wenn Sie fragen, warum es eine Warnung für den SELECT-Operator gibt, dann ist es eine übermäßige Grant-Warnung. In diesem Fall liegt es nicht an einem Problem im Ausführungsplan, sondern daran, dass der Abfrageprozessor 1.024 KB angefordert hat (was standardmäßig das Minimum ist) und nur 16 KB verwendet hat.
Manchmal ist Plan-Caching keine so gute Idee
Als Nächstes möchten wir das Szenario testen, bei dem die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach OrderDate zurückgegeben werden. Unten ist der Code:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Der Ausführungsplan ist genau derselbe wie zuvor. Diesmal ist der Plan sehr ineffizient, da er beide Tabellen scannt, um nur 3 Bestellungen zurückzugeben. Es gibt viel bessere Möglichkeiten, diese Abfrage auszuführen.
Der Grund ist in diesem Fall das Plan-Caching. Der Ausführungsplan wurde bei der ersten Ausführung basierend auf den Parameterwerten in dieser bestimmten Ausführung generiert – eine Methode, die als Parameter-Sniffing bekannt ist. Dieser Plan wurde zur Wiederverwendung im Plan-Cache gespeichert, und von nun an wird jeder Aufruf dieser gespeicherten Prozedur denselben Plan wiederverwenden.
Dies ist ein Beispiel, bei dem Plan-Caching keine so gute Idee ist. Aufgrund der Art dieser gespeicherten Prozedur, die 4 verschiedene Verhaltensweisen aufweist, erwarten wir, dass wir für jedes Verhalten einen anderen Plan erhalten. Aber wir bleiben bei einem einzigen Plan hängen, der nur für eine der 4 Optionen geeignet ist, basierend auf der Option, die bei der ersten Ausführung verwendet wurde.
Lassen Sie uns das Plan-Caching für diese gespeicherte Prozedur deaktivieren, damit wir den besten Plan sehen können, den der Optimierer für jedes der anderen drei Verhaltensweisen entwickeln kann. Dazu fügen wir WITH RECOMPILE zum EXECUTE-Befehl hinzu.
Die Top 10 Zeilen für einen bestimmten Kunden sortiert nach Bestelldatum zurückgeben
Der folgende Code gibt die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach OrderDate zurück:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Das Folgende ist der Ausführungsplan:
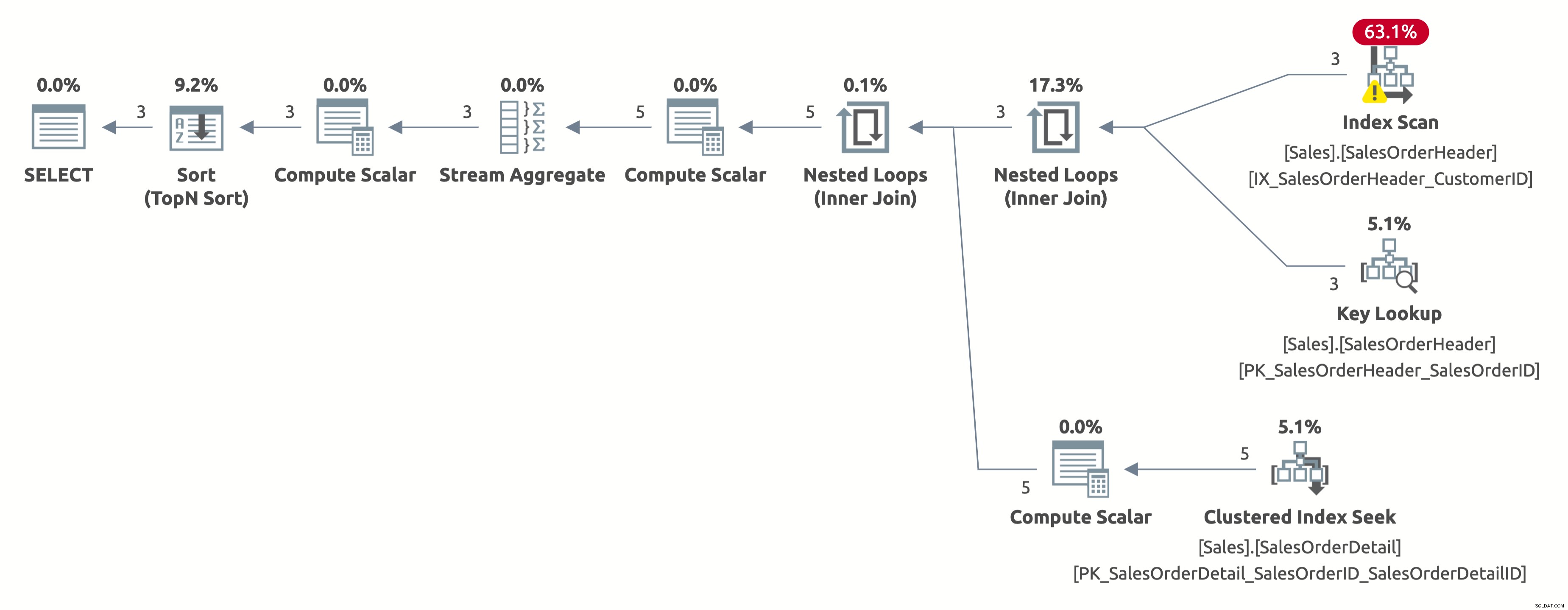
Dieses Mal erhalten wir einen besseren Plan, der einen Index für CustomerID verwendet. Der Optimierer schätzt korrekt 2,6 Zeilen für CustomerID =11006 (die tatsächliche Zahl ist 3). Beachten Sie jedoch, dass anstelle einer Indexsuche ein Indexscan durchgeführt wird. Es kann keine Indexsuche durchführen, da es das folgende Prädikat für jede Zeile in der Tabelle auswerten muss:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID ] ODER [@CustomerID] IST NULL.
Hier ist die Ausgabe von Statistik IO:
- Tabelle 'SalesOrderDetail'. Scananzahl 3, logische Lesevorgänge 9
- Tabelle 'SalesOrderHeader'. Scananzahl 1, logische Lesevorgänge 66
Gib die Top 10 Zeilen für alle Kunden sortiert nach SalesOrderID zurück
Der folgende Code gibt die obersten 10 Zeilen für alle Kunden sortiert nach SalesOrderID zurück:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Das Folgende ist der Ausführungsplan:
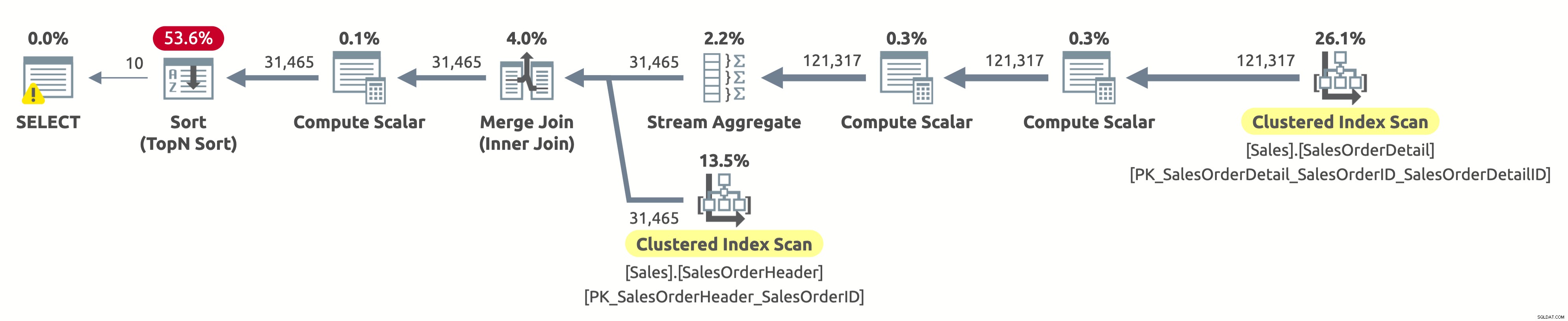
Hey, das ist der gleiche Ausführungsplan wie in der ersten Option. Doch dieses Mal stimmt etwas nicht. Wir wissen bereits, dass die Clustered-Indizes für beide Tabellen nach SalesOrderID sortiert sind. Wir wissen auch, dass der Plan beide in der logischen Reihenfolge scannt, um die Sortierreihenfolge beizubehalten (die Ordered-Eigenschaft ist auf True gesetzt). Der Merge Join-Operator behält auch die Sortierreihenfolge bei. Weil wir jetzt darum bitten, das Ergebnis nach SalesOrderID zu sortieren, und es ist bereits so sortiert, warum müssen wir dann für einen teuren Sort-Operator bezahlen?
Nun, wenn Sie den Sort-Operator überprüfen, werden Sie feststellen, dass er die Daten gemäß Expr1004 sortiert. Und wenn Sie den Compute Scalar-Operator rechts neben dem Sort-Operator überprüfen, werden Sie feststellen, dass Expr1004 wie folgt lautet:

Kein schöner Anblick, ich weiß. Dies ist der Ausdruck, den wir in der ORDER BY-Klausel unserer Abfrage haben. Das Problem ist, dass der Optimierer diesen Ausdruck nicht zur Kompilierzeit auswerten kann, also muss er ihn zur Laufzeit für jede Zeile berechnen und dann den gesamten Datensatz basierend darauf sortieren.
Die Ausgabe von Statistik IO ist wie bei der ersten Ausführung:
- Tabelle 'SalesOrderHeader'. Scananzahl 1, logische Lesevorgänge 689
- Tabelle 'SalesOrderDetail'. Scananzahl 1, logische Lesevorgänge 1248
Gib die Top 10 Zeilen für einen bestimmten Kunden sortiert nach SalesOrderID zurück
Der folgende Code gibt die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach SalesOrderID zurück:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Der Ausführungsplan ist derselbe wie bei der zweiten Option (die obersten 10 Zeilen für einen bestimmten Kunden sortiert nach OrderDate zurückgeben). Der Plan hat die gleichen zwei Probleme, die wir bereits erwähnt haben. Das erste Problem besteht darin, aufgrund des Ausdrucks in der WHERE-Klausel einen Index-Scan anstelle einer Index-Suche durchzuführen. Das zweite Problem ist die Durchführung einer aufwendigen Sortierung aufgrund des Ausdrucks in der ORDER BY-Klausel.
Also, was sollen wir tun?
Erinnern wir uns zuerst daran, womit wir es zu tun haben. Wir haben Parameter, die die Struktur der Abfrage bestimmen. Für jede Kombination von Parameterwerten erhalten wir eine andere Abfragestruktur. Im Fall des @CustomerID-Parameters sind die beiden unterschiedlichen Verhalten NULL oder NOT NULL und wirken sich auf die WHERE-Klausel aus. Im Fall des @SortOrder-Parameters gibt es zwei mögliche Werte, die sich auf die ORDER BY-Klausel auswirken. Das Ergebnis sind 4 mögliche Abfragestrukturen, und wir möchten für jede einen anderen Plan erhalten.
Dann haben wir zwei unterschiedliche Probleme. Das erste ist das Plan-Caching. Es gibt nur einen einzigen Plan für die gespeicherte Prozedur, und dieser wird basierend auf den Parameterwerten bei der ersten Ausführung generiert. Das zweite Problem ist, dass selbst wenn ein neuer Plan generiert wird, dies nicht effizient ist, da der Optimierer die "dynamischen" Ausdrücke in der WHERE-Klausel und in der ORDER BY-Klausel zur Kompilierzeit nicht auswerten kann.
Wir können versuchen, diese Probleme auf verschiedene Weise zu lösen:
- Verwenden Sie eine Reihe von IF-ELSE-Anweisungen
- Unterteilen Sie die Prozedur in separate gespeicherte Prozeduren
- Verwenden Sie OPTION (RECOMPILE)
- Generieren Sie die Abfrage dynamisch
Verwenden Sie eine Reihe von IF-ELSE-Anweisungen
Die Idee ist einfach:Anstelle der „dynamischen“ Ausdrücke in der WHERE-Klausel und in der ORDER BY-Klausel können wir die Ausführung mithilfe von IF-ELSE-Anweisungen in 4 Zweige aufteilen – einen Zweig für jedes mögliche Verhalten.
Das Folgende ist beispielsweise der Code für die erste Verzweigung:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Dieser Ansatz kann helfen, bessere Pläne zu erstellen, hat aber einige Einschränkungen.
Erstens wird die gespeicherte Prozedur ziemlich lang und schwieriger zu schreiben, zu lesen und zu warten. Und das ist, wenn wir nur zwei Parameter haben. Wenn wir 3 Parameter hätten, hätten wir 8 Zweige. Stellen Sie sich vor, Sie müssen der SELECT-Klausel eine Spalte hinzufügen. Sie müssten die Spalte in 8 verschiedenen Abfragen hinzufügen. Es wird zu einem Wartungsalptraum mit einem hohen Risiko menschlicher Fehler.
Zweitens haben wir bis zu einem gewissen Grad immer noch das Problem des Plan-Caching und des Parameter-Sniffing. Dies liegt daran, dass der Optimierer bei der ersten Ausführung einen Plan für alle 4 Abfragen basierend auf den Parameterwerten in dieser Ausführung generiert. Nehmen wir an, dass die erste Ausführung die Standardwerte für die Parameter verwenden wird. Insbesondere ist der Wert von @CustomerID NULL. Alle Abfragen werden basierend auf diesem Wert optimiert, einschließlich der Abfrage mit der WHERE-Klausel (SalesOrders.CustomerID =@CustomerID). Der Optimierer schätzt 0 Zeilen für diese Abfragen. Nehmen wir nun an, dass die zweite Ausführung einen Nicht-Null-Wert für @CustomerID verwenden wird. Der zwischengespeicherte Plan, der 0 Zeilen schätzt, wird verwendet, auch wenn der Kunde möglicherweise viele Bestellungen in der Tabelle hat.
Teilen Sie die Prozedur in separate gespeicherte Prozeduren auf
Anstelle von 4 Zweigen innerhalb derselben gespeicherten Prozedur können wir 4 separate gespeicherte Prozeduren erstellen, jede mit den relevanten Parametern und der entsprechenden Abfrage. Dann können wir entweder die Anwendung neu schreiben, um zu entscheiden, welche gespeicherte Prozedur gemäß dem gewünschten Verhalten ausgeführt werden soll. Oder, wenn wir möchten, dass es für die Anwendung transparent ist, können wir die ursprüngliche gespeicherte Prozedur neu schreiben, um zu entscheiden, welche Prozedur basierend auf den Parameterwerten ausgeführt werden soll. Wir werden dieselben IF-ELSE-Anweisungen verwenden, aber anstatt in jedem Zweig eine Abfrage auszuführen, führen wir eine separate gespeicherte Prozedur aus.
Der Vorteil besteht darin, dass wir das Plan-Caching-Problem lösen, da jede gespeicherte Prozedur jetzt ihren eigenen Plan hat und der Plan für jede gespeicherte Prozedur bei ihrer ersten Ausführung basierend auf Parameter-Sniffing generiert wird.
Aber wir haben immer noch das Wartungsproblem. Einige Leute werden vielleicht sagen, dass es jetzt noch schlimmer ist, weil wir mehrere gespeicherte Prozeduren verwalten müssen. Wenn wir die Anzahl der Parameter auf 3 erhöhen, würden wir wiederum 8 verschiedene gespeicherte Prozeduren erhalten.
Verwenden Sie OPTION (RECOMPILE)
OPTION (RECOMPILE) funktioniert wie Magie. Sie müssen nur die Wörter sagen (oder sie an die Abfrage anhängen), und es passiert Magie. Wirklich, es löst so viele Probleme, weil es die Abfrage zur Laufzeit kompiliert, und das bei jeder Ausführung.
Aber Sie müssen vorsichtig sein, denn Sie wissen, was sie sagen:"Mit großer Macht kommt große Verantwortung." Wenn Sie OPTION (RECOMPILE) in einer Abfrage verwenden, die sehr oft auf einem ausgelasteten OLTP-System ausgeführt wird, beenden Sie möglicherweise das System, da der Server bei jeder Ausführung einen neuen Plan kompilieren und generieren muss, was viele CPU-Ressourcen verbraucht. Das ist wirklich gefährlich. Wenn die Abfrage jedoch nur ab und zu ausgeführt wird, sagen wir einmal alle paar Minuten, dann ist sie wahrscheinlich sicher. Testen Sie die Auswirkungen jedoch immer in Ihrer spezifischen Umgebung.
In unserem Fall, vorausgesetzt, wir können OPTION (RECOMPILE) sicher verwenden, müssen wir nur die magischen Wörter am Ende unserer Abfrage hinzufügen, wie unten gezeigt:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Lassen Sie uns nun die Magie in Aktion sehen. Der folgende Plan ist beispielsweise für das zweite Verhalten:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
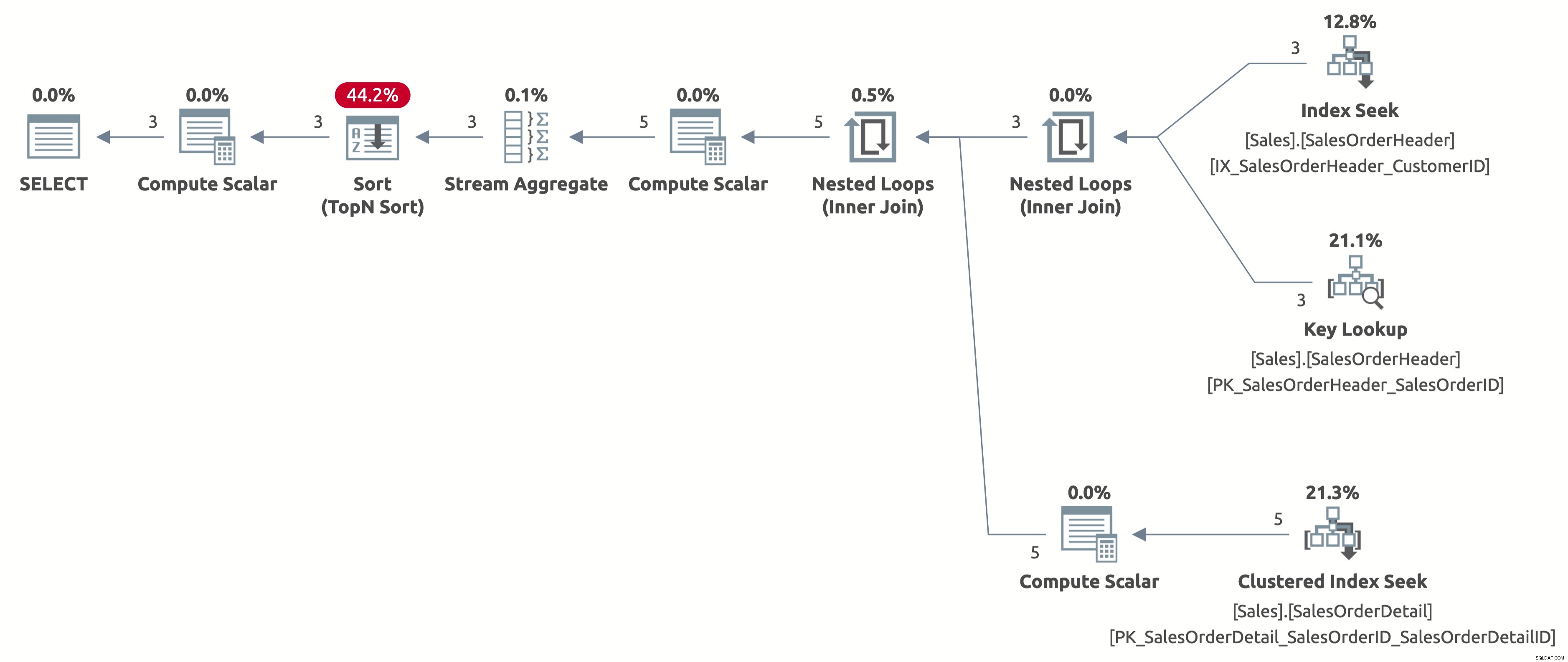
Jetzt erhalten wir eine effiziente Indexsuche mit einer korrekten Schätzung von 2,6 Zeilen. Wir müssen immer noch nach Bestelldatum sortieren, aber jetzt erfolgt die Sortierung direkt nach Bestelldatum, und wir müssen den CASE-Ausdruck in der ORDER BY-Klausel nicht mehr berechnen. Dies ist der bestmögliche Plan für dieses Abfrageverhalten basierend auf den verfügbaren Indizes.
Hier ist die Ausgabe von Statistik IO:
- Tabelle 'SalesOrderDetail'. Scananzahl 3, logische Lesevorgänge 9
- Tabelle 'SalesOrderHeader'. Scananzahl 1, logische Lesevorgänge 11
Der Grund, warum OPTION (RECOMPILE) in diesem Fall so effizient ist, liegt darin, dass es genau die beiden Probleme löst, die wir hier haben. Denken Sie daran, dass das erste Problem das Plan-Caching ist. OPTION (RECOMPILE) beseitigt dieses Problem vollständig, da es die Abfrage jedes Mal neu kompiliert. Das zweite Problem ist die Unfähigkeit des Optimierers, den komplexen Ausdruck in der WHERE-Klausel und in der ORDER BY-Klausel zur Kompilierzeit auszuwerten. Da OPTION (RECOMPILE) zur Laufzeit passiert, löst es das Problem. Denn zur Laufzeit verfügt der Optimierer im Vergleich zur Kompilierzeit über viel mehr Informationen, und das macht den Unterschied.
Sehen wir uns nun an, was passiert, wenn wir das dritte Verhalten ausprobieren:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
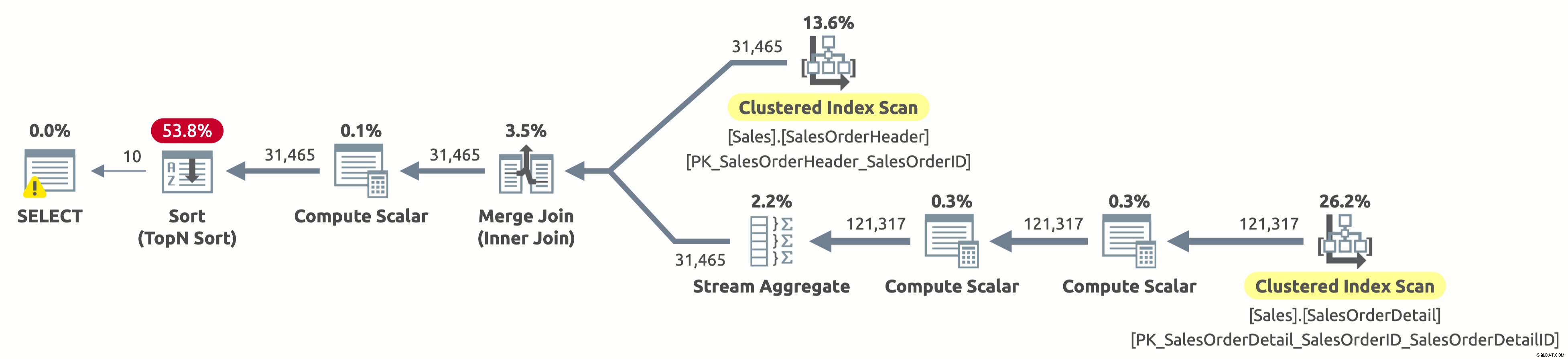
Houston, wir haben ein Problem. Der Plan scannt weiterhin beide Tabellen vollständig und sortiert dann alles, anstatt nur die ersten 10 Zeilen von Sales.SalesOrderHeader zu scannen und die Sortierung insgesamt zu vermeiden. Was ist passiert?
Dies ist ein interessanter »Fall« und hat mit dem CASE-Ausdruck in der ORDER BY-Klausel zu tun. Der CASE-Ausdruck wertet eine Liste von Bedingungen aus und gibt einen der Ergebnisausdrücke zurück. Die Ergebnisausdrücke können jedoch unterschiedliche Datentypen haben. Was wäre also der Datentyp des gesamten CASE-Ausdrucks? Nun, der CASE-Ausdruck gibt immer den Datentyp mit der höchsten Priorität zurück. In unserem Fall hat die Spalte OrderDate den Datentyp DATETIME, während die Spalte SalesOrderID den Datentyp INT hat. Der Datentyp DATETIME hat eine höhere Priorität, daher gibt der CASE-Ausdruck immer DATETIME zurück.
Wenn wir also nach SalesOrderID sortieren möchten, muss der CASE-Ausdruck zuerst den Wert von SalesOrderID für jede Zeile implizit in DATETIME konvertieren, bevor er sortiert wird. Sehen Sie den Compute Scalar-Operator rechts neben dem Sort-Operator im Plan oben? Genau das tut es.
Dies ist ein Problem für sich und zeigt, wie gefährlich es sein kann, verschiedene Datentypen in einem einzigen CASE-Ausdruck zu mischen.
Wir können dieses Problem umgehen, indem wir die ORDER BY-Klausel auf andere Weise umschreiben, aber das würde den Code noch hässlicher und schwieriger zu lesen und zu warten machen. Also werde ich nicht in diese Richtung gehen.
Versuchen wir stattdessen die nächste Methode …
Generieren Sie die Abfrage dynamisch
Da unser Ziel darin besteht, 4 verschiedene Abfragestrukturen innerhalb einer einzigen Abfrage zu generieren, kann dynamisches SQL in diesem Fall sehr praktisch sein. Die Idee besteht darin, die Abfrage dynamisch basierend auf den Parameterwerten zu erstellen. Auf diese Weise können wir die 4 verschiedenen Abfragestrukturen in einem einzigen Code erstellen, ohne 4 Kopien der Abfrage verwalten zu müssen. Jede Abfragestruktur wird einmal kompiliert, wenn sie zum ersten Mal ausgeführt wird, und sie erhält den besten Plan, da sie keine komplexen Ausdrücke enthält.
Diese Lösung ist der Lösung mit mehreren gespeicherten Prozeduren sehr ähnlich, aber anstatt 8 gespeicherte Prozeduren für 3 Parameter zu verwalten, verwalten wir nur einen einzigen Code, der die Abfrage dynamisch erstellt.
Ich weiß, dynamisches SQL ist auch hässlich und kann manchmal ziemlich schwierig zu warten sein, aber ich denke, es ist immer noch einfacher als das Verwalten mehrerer gespeicherter Prozeduren, und es skaliert nicht exponentiell, wenn die Anzahl der Parameter zunimmt.
Das Folgende ist der Code:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Beachten Sie, dass ich immer noch einen internen Parameter für die Kunden-ID verwende und den dynamischen Code mit sys.sp_executesql ausführe um den Parameterwert zu übergeben. Dies ist aus zwei Gründen wichtig. Erstens, um mehrere Kompilierungen derselben Abfragestruktur für unterschiedliche Werte von @CustomerID zu vermeiden. Zweitens, um SQL-Injection zu vermeiden.
Wenn Sie versuchen, die gespeicherte Prozedur jetzt mit unterschiedlichen Parameterwerten auszuführen, werden Sie sehen, dass jedes Abfrageverhalten oder jede Abfragestruktur den besten Ausführungsplan erhält und jeder der 4 Pläne nur einmal kompiliert wird.
Als Beispiel ist das folgende der Plan für das dritte Verhalten:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
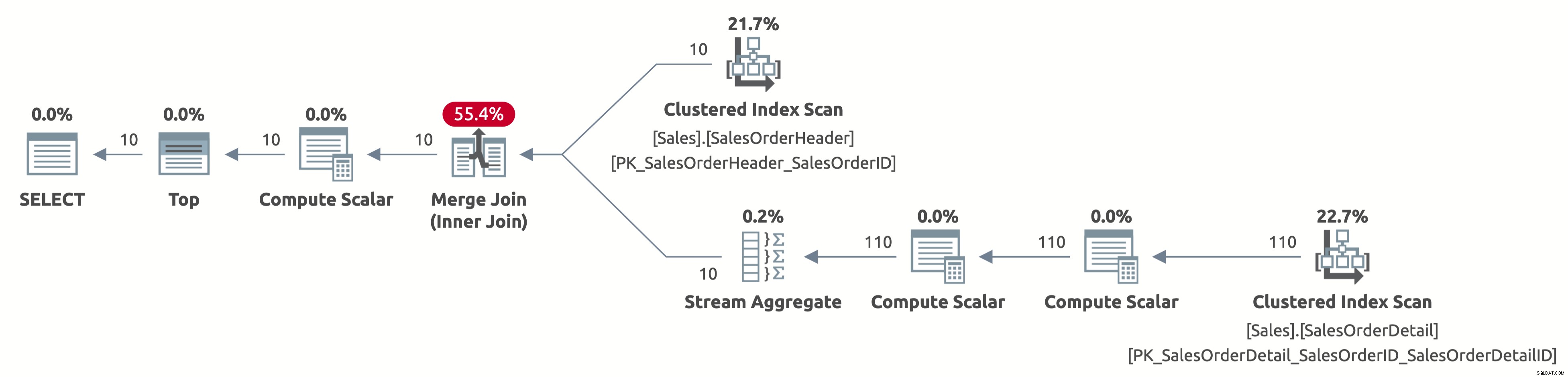
Jetzt scannen wir nur die ersten 10 Zeilen der Sales.SalesOrderHeader-Tabelle und wir scannen auch nur die ersten 110 Zeilen der Sales.SalesOrderDetail-Tabelle. Außerdem gibt es keinen Sort-Operator, da die Daten bereits nach SalesOrderID sortiert sind.
Hier ist die Ausgabe von Statistik IO:
- Tabelle 'SalesOrderDetail'. Scananzahl 1, logische Lesevorgänge 4
- Tabelle 'SalesOrderHeader'. Scananzahl 1, logische Lesevorgänge 3
Schlussfolgerung
Wenn Sie Parameter verwenden, um die Struktur Ihrer Abfrage zu ändern, verwenden Sie keine komplexen Ausdrücke innerhalb der Abfrage, um das erwartete Verhalten abzuleiten. In den meisten Fällen führt dies zu einer schlechten Leistung, und das aus guten Gründen. Der erste Grund ist, dass der Plan basierend auf der ersten Ausführung generiert wird und alle nachfolgenden Ausführungen denselben Plan wiederverwenden, der nur für eine Abfragestruktur geeignet ist. Der zweite Grund ist, dass der Optimierer in seiner Fähigkeit eingeschränkt ist, diese komplexen Ausdrücke zur Kompilierzeit auszuwerten.
Es gibt mehrere Möglichkeiten, diese Probleme zu überwinden, und wir haben sie in diesem Artikel untersucht. In den meisten Fällen wäre die beste Methode, die Abfrage dynamisch basierend auf den Parameterwerten zu erstellen. Auf diese Weise wird jede Abfragestruktur einmal mit dem bestmöglichen Plan kompiliert.
Wenn Sie die Abfrage mit dynamischem SQL erstellen, achten Sie darauf, an geeigneten Stellen Parameter zu verwenden, und vergewissern Sie sich, dass Ihr Code sicher ist.