Wir haben bereits einige Theorien zum Konfigurieren von Always ON-Verfügbarkeitsgruppen für Linux-basierte SQL Server behandelt. Der aktuelle Artikel konzentriert sich auf die Praxis.
Wir werden den schrittweisen Prozess zum Konfigurieren der SQL Server Always ON-Verfügbarkeitsgruppen zwischen zwei synchronen Replikaten vorstellen. Außerdem heben wir die Verwendung des Nur-Konfigurations-Replikats hervor, um ein automatisches Failover durchzuführen.
Bevor wir beginnen, würde ich Ihnen empfehlen, diesen vorherigen Artikel zu lesen und Ihr Wissen aufzufrischen.
Das folgende Designdiagramm zeigt die synchrone Zwei-Knoten-Replik und eine reine Konfigurationsreplik, die uns helfen, automatisches Failover und Datenschutz sicherzustellen.
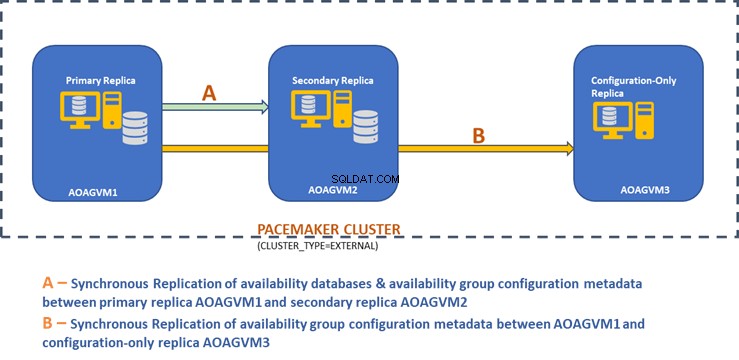
Wir haben dieses Design in dem zuvor erwähnten Artikel untersucht, also beziehen Sie sich bitte darauf, bevor wir mit praktischen Aufgaben fortfahren.
Installieren Sie SQL Server auf Ubuntu-Systemen
Das obige Designdiagramm erwähnt 3 Ubuntu-Systeme – aoagvm1 , aoagvm2 und aoagvm3 mit den installierten SQL Server-Instanzen. Siehe die Anleitung zur Installation von SQL Server auf Ubuntu – das Beispiel bezieht sich auf SQL Server 2019 auf einem Ubuntu 18.04-System. Sie können fortfahren und SQL Server 2019 auf allen 3 Knoten installieren (stellen Sie sicher, dass Sie dieselbe Build-Version installieren).
Um Lizenzkosten zu sparen, können Sie die SQL Server Express Edition für das dritte Knotenreplikat installieren. Dieser wird als reines Konfigurationsreplikat funktionieren, ohne Verfügbarkeitsdatenbanken zu hosten.
Sobald SQL Server auf allen 3 Knoten installiert ist, können wir die Verfügbarkeitsgruppe zwischen ihnen konfigurieren.
Verfügbarkeitsgruppen zwischen drei Knoten konfigurieren
Bevor Sie fortfahren, validieren Sie Ihre Umgebung:
- Stellen Sie sicher, dass zwischen allen 3 Knoten kommuniziert wird.
- Prüfen und aktualisieren Sie den Computernamen für jeden Host, indem Sie den Befehl sudo vi /etc/hostname ausführen
- Aktualisieren Sie die Hostdatei mit IP-Adresse und Knotennamen für jeden Knoten. Sie können den Befehl sudo vi /etc/hosts verwenden um dies zu erledigen
- Stellen Sie sicher, dass alle Instanzen über SQL Server 2017 CU1 hinaus ausgeführt werden, wenn Sie SQL Server 2019 nicht verwenden
Beginnen wir nun mit der Konfiguration der SQL Server Always ON-Verfügbarkeitsgruppe zwischen 3 Knoten. Wir müssen die Verfügbarkeitsgruppenfunktion auf allen 3 Knoten aktivieren.
Führen Sie den folgenden Befehl aus (beachten Sie, dass Sie den SQL Server-Dienst nach dieser Aktion neu starten müssen):
--Enable Availability Group feature
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
--Restart SQL Server service
sudo systemctl restart mssql-server
Ich habe den obigen Befehl auf dem primären Knoten ausgeführt. Dies sollte für die verbleibenden zwei Knoten wiederholt werden.
Die Ausgabe ist unten – geben Sie den Benutzernamen und das Passwort ein, wenn Sie dazu aufgefordert werden.
example@sqldat.com:~$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
SQL Server needs to be restarted to apply this setting. Please run
'systemctl restart mssql-server.service'.
example@sqldat.com:~$ systemctl restart mssql-server
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to restart 'mssql-server.service'.
Authenticating as: Ubuntu (aoagvm1)
Password:
Der nächste Schritt besteht darin, die erweiterten Always ON-Ereignisse zu aktivieren für jede SQL Server-Instanz. Obwohl dies ein optionaler Schritt ist, müssen Sie ihn aktivieren, um später auftretende Probleme zu beheben. Stellen Sie mit SQLCMD eine Verbindung zur SQL Server-Instanz her und führen Sie den folgenden Befehl aus:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
Go
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
Go
Die Ausgabe ist unten:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
2>GO
1>
Nachdem Sie diese Option auf dem primären Replikatknoten aktiviert haben, machen Sie dasselbe für die verbleibenden aoagvm2- und aoagvm3-Knoten.
Die unter Linux ausgeführten SQL Server-Instanzen verwenden Zertifikate, um die Kommunikation zwischen den Spiegelungsendpunkten zu authentifizieren. Die nächste Option besteht also darin, das Zertifikat auf dem primären Replikat aoagvm1 zu erstellen .
Zuerst erstellen wir einen Hauptschlüssel und ein Zertifikat. Dann sichern wir dieses Zertifikat in einer Datei und sichern die Datei mit einem privaten Schlüssel. Führen Sie das folgende T-SQL-Skript auf dem primären Replikatknoten aus:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Configure Certificates
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
Die Ausgabe:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
3>GO
1>BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
2>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
3>GO
1>
Der primäre Replikatknoten hat jetzt zwei neue Dateien. Eine davon ist die Zertifikatsdatei dbm_certificate.cer und die private Schlüsseldatei dbm_certificate.pvk unter /var/opt/mssql/data/ Ort.
Kopieren Sie die beiden obigen Dateien an denselben Speicherort auf den verbleibenden zwei Knoten (AOAGVM2 und AOAGVM3), die an der Konfiguration der Verfügbarkeitsgruppe teilnehmen werden. Sie können den SCP-Befehl oder ein Dienstprogramm eines Drittanbieters verwenden, um diese beiden Dateien auf den Zielserver zu kopieren.
Nachdem die Dateien auf die verbleibenden zwei Knoten kopiert wurden, weisen wir der mssql Berechtigungen zu Benutzer auf diese Dateien auf allen 3 Knoten zugreifen. Führen Sie dazu den folgenden Befehl aus und führen Sie ihn dann für den dritten Knoten aoagvm3 aus auch:
--Copy files to aoagvm2 node
cd /var/opt/mssql/data
scp dbm_certificate.* example@sqldat.com:var/opt/mssql/data/
--Grant permission to user mssql to access both newly created files
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Wir erstellen die Hauptschlüssel- und Zertifikatsdateien mit Hilfe der beiden oben genannten kopierten Dateien auf den verbleibenden zwei Knoten aoagvm2 und aoagvm3 . Führen Sie den folgenden Befehl auf diesen beiden Knoten aus, um den Hauptschlüssel zu erstellen :
--Create master key and certificate on remaining two nodes
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
Ich habe den obigen Befehl auf dem zweiten Knoten aoagvm2 ausgeführt um den Hauptschlüssel zu erstellen und Zertifikat . Sehen Sie sich die Ausführungsausgabe an. Stellen Sie sicher, dass Sie dieselben Passwörter wie beim Erstellen und Sichern des Zertifikats und des Hauptschlüssels verwenden.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate
3>FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
4>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
5>GO
1>
Führen Sie den obigen Befehl auf AOAGVM3 aus auch Knoten.
Jetzt konfigurieren wir Endpunkte für die Datenbankspiegelung – zuvor haben wir Zertifikate für sie erstellt. Der Spiegelungsendpunkt namens hadr_endpoint sollte sich auf allen 3 Knoten gemäß ihrem jeweiligen Rollentyp befinden.
Da Verfügbarkeitsdatenbanken auf nur 2 Knoten aoagvm1 gehostet werden und aoagvm2, Wir werden die folgende Anweisung nur auf diesen Knoten ausführen. Der dritte Knoten wird wie ein Zeuge fungieren – also werden wir einfach die ROLLE ändern bezeugen im folgenden Skript und führen Sie dann T-SQL zum dritten Knoten aoagvm3 aus . Das Skript lautet:
--Configure database mirroring endpoint Hadr_endpoint on nodes aoagvm1 and aoagvm2
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Hier ist die Ausgabe des obigen Befehls auf dem primären Replikatknoten. Ich habe eine Verbindung zu sqlcmd hergestellt und es ausgeführt. Stellen Sie sicher, dass Sie dasselbe auf dem zweiten Replikatknoten aoagvm2 tun auch.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE ENDPOINT [Hadr_endpoint]
2>AS TCP (LISTENER_PORT = 5022)
3>FOR DATABASE_MIRRORING (ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
4>Go
1>ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
2>Go
1>
Nachdem Sie das obige T-SQL-Skript auf den ersten beiden Knoten ausgeführt haben, müssen wir es für den dritten Knoten ändern – ändern Sie die ROLE in WITNESS.
Führen Sie das folgende Skript aus, um den Endpunkt für die Datenbankspiegelung auf dem Zeugenknoten AOAGVM3 zu erstellen . Wenn Sie dort Verfügbarkeitsdatenbanken hosten möchten, führen Sie den obigen Befehl auch auf dem 3-Replikat-Knoten aus. Stellen Sie jedoch sicher, dass Sie die richtige Edition von SQL Server installiert haben, um diese Funktion nutzen zu können.
Wenn Sie die SQL Server Express Edition auf dem 3-Knoten installiert haben, um nur Konfiguration zu implementieren Replik , können Sie nur ROLE konfigurieren als Zeuge für diesen Knoten:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
----Configure database mirroring endpoint Hadr_endpoint on 3rd node aoagvm3
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = WITNESS, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint on aoagvm3
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Jetzt müssen wir die Verfügbarkeitsgruppe mit dem Namen ag1 erstellen .
Stellen Sie mithilfe von sqlcmd eine Verbindung zur SQL Server-Instanz her und führen Sie den folgenden Befehl auf dem primären Replikatknoten aoagvm1 aus :
--Connect to the local SQL Server instance using sqlcmd hosted on primary replica node aoagvm1
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Create availability group ag1
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'aoagvm1’ WITH (ENDPOINT_URL = N'tcp://aoagvm1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm2' WITH (ENDPOINT_URL = N'tcp://aoagvm2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm3' WITH (ENDPOINT_URL = N'tcp://aoagvm3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY);
--Assign required permission
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Das obige Skript konfiguriert Replikate von Verfügbarkeitsgruppen mit den folgenden Konfigurationsparametern (wir haben sie gerade im T-SQL-Skript verwendet):
- CLUSTER_TYPE =EXTERN weil wir Verfügbarkeitsgruppen auf Linux-basierten SQL Server-Installationen konfigurieren
- SEEDING_MODE =AUTOMATISCH bewirkt, dass SQL Server automatisch eine Datenbank auf jedem sekundären Replikat erstellt. Verfügbarkeitsdatenbanken werden nicht auf reinen Konfigurationsreplikaten erstellt
- FAILOVER_MODE =EXTERN sowohl für primäre als auch für sekundäre Replikate. Das bedeutet, dass das Replikat mit einem externen Cluster-Ressourcenmanager wie Pacemaker interagiert
- AVAILABILITY_MODE =SYNCHRONOUS_COMMIT für primäre und sekundäre Replikate für automatisches Failover
- AVAILABILITY_MODE =CONFIGURATION_ONLY für das dritte Replikat, das als reines Konfigurationsreplikat fungiert
Wir müssen auch eine Pacemaker-Anmeldung auf allen SQL Server-Instanzen erstellen. Diesem Benutzer muss der ALTER zugewiesen werden , STEUERUNG und ANSEHEN DEFINITION Berechtigungen für die Verfügbarkeitsgruppe auf allen Replikaten. Um Berechtigungen zu erteilen, führen Sie das folgende T-SQL-Skript sofort auf allen drei Replikatknoten aus. Zuerst erstellen wir ein Pacemaker-Login. Dann weisen wir diesem Login die oben genannten Berechtigungen zu.
--Create pacemaker login on each SQL Server instance. Run below commands on all 3 SQL Server instances
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
--Grant permission to pacemaker login on newly created availability group. Run it on all 3 SQL Server instances
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemaker
GRANT VIEW SERVER STATE TO pacemaker
Nachdem wir der Pacemaker-Anmeldung auf allen drei Replikaten die entsprechenden Berechtigungen zugewiesen haben, führen wir die folgenden T-SQL-Skripts aus, um den sekundären Replikaten aoagvm2 beizutreten und aoagvm3 in die neu erstellte Verfügbarkeitsgruppe ag1 . Führen Sie die folgenden Befehle auf den sekundären Replikaten aoagvm2 aus und aoagvm3 .
--Execute below commands on aoagvm2 and aoagvm3 to join availability group ag1
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Unten ist die Ausgabe der obigen Ausführungen auf dem Knoten aoagvm2 . Stellen Sie sicher, dass Sie es auf aoagvm3 ausführen auch Knoten.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
2>Go
1>ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
2>Go
1>
Daher haben wir die Verfügbarkeitsgruppe konfiguriert. Jetzt müssen wir dieser Verfügbarkeitsgruppe einen Benutzer oder eine Testdatenbank hinzufügen. Wenn Sie bereits eine Benutzerdatenbank auf dem Replikat des primären Knotens erstellt haben, führen Sie einfach eine vollständige Sicherung durch und lassen Sie sie dann vom automatischen Seeding auf dem sekundären Knoten wiederherstellen.
Führen Sie daher den folgenden Befehl aus:
--Run a full backup of test database or user database hosted on primary replica aoagvm1
BACKUP DATABASE [Test] TO DISK = N'/var/opt/mssql/data/Test_15June.bak';
Lassen Sie uns diese Datenbank Test hinzufügen an die Verfügbarkeitsgruppe ag1 . Führen Sie die folgende T-SQL-Anweisung auf dem primären Knoten aoagvm1 aus . Sie können den sqlcmd verwenden Dienstprogramm zum Ausführen von T-SQL-Anweisungen.
--Add user database or test database to the availability group ag1
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [Test];
Sie können die Benutzerdatenbank oder eine Testdatenbank überprüfen, die Sie der Verfügbarkeitsgruppe hinzugefügt haben, indem Sie sich die sekundäre SQL Server-Instanz ansehen, unabhängig davon, ob sie auf sekundären Replikaten erstellt wurde oder nicht. Sie können entweder SQL Server Management Studio verwenden oder eine einfache T-SQL-Anweisung ausführen, um die Details zu dieser Datenbank abzurufen.
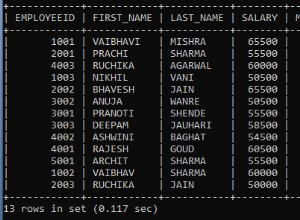
--Verify test database is created on a secondary replica or not. Run it on secondary replica aoagvm2.
SELECT * FROM sys.databases WHERE name = 'Test';
GO
Sie erhalten den Test Datenbank, die auf dem sekundären Replikat erstellt wurde.
Mit dem obigen Schritt wurde die AlwaysOn-Verfügbarkeitsgruppe zwischen allen drei Knoten konfiguriert. Diese Knoten sind jedoch noch nicht geclustert. Unser nächster Schritt ist die Installation des Pacemaker Cluster auf ihnen. Dann fügen wir die Verfügbarkeitsgruppe ag1 hinzu als Ressource für diesen Cluster.
PACEMAKER-Cluster-Konfiguration zwischen drei Knoten
Daher verwenden wir einen externen Cluster-Ressourcenmanager PACEMAKER zwischen allen 3 Knoten für Cluster-Unterstützung. Beginnen wir mit der Aktivierung der Firewall-Ports zwischen allen 3 Knoten.
Öffnen Sie Firewall-Ports mit dem folgenden Befehl:
--Run the below commands on all 3 nodes to open Firewall Ports
sudo ufw allow 2224/tcp
sudo ufw allow 3121/tcp
sudo ufw allow 21064/tcp
sudo ufw allow 5405/udp
sudo ufw allow 1433/tcp
sudo ufw allow 5022/tcp
sudo ufw reload
--If you don't want to open specific firewall ports then alternatively you can disable the firewall on all 3 nodes by running the below command (THIS IS ALTERNATE & OPTIONAL APPROACH)
sudo ufw disable
Sehen Sie sich die Ausgabe an – diese stammt vom primären Replikat AOAGVM1 . Sie müssen die obigen Befehle nacheinander auf allen drei Knoten ausführen. Die Ausgabe sollte ähnlich sein.
example@sqldat.com:~$ sudo ufw allow 2224/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 3121/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 21064/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5405/udp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 1433/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5022/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw reload
Firewall not enabled (skipping reload)
Installieren Sie Pacemaker und corosync Pakete auf allen 3 Knoten. Führen Sie den folgenden Befehl auf jedem Knoten aus – er konfiguriert Pacemaker , corosync , und Fechtagent .
--Install Pacemaker packages on all 3 nodes aoagvm1, aoagvm2 and aoagvm3 by running the below command
sudo apt-get install pacemaker pcs fence-agents resource-agents
Der Output ist riesig – knapp 20 Seiten. Ich habe die ersten und letzten Zeilen zur Veranschaulichung kopiert (Sie können alle installierten Pakete sehen):
example@sqldat.com:~$ sudo apt-get install pacemaker pcs fence-agents resource-agents
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
cluster-glue corosync fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4 libcpg4
libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker-cli-utils pacemaker-common pacemaker-resource-agents python-pexpect python-ptyprocess python-pycurl python3-bs4 python3-html5lib
python3-lxml python3-pycurl python3-webencodings rake ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean ruby-ethon ruby-ffi ruby-highline
ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4 ruby-power-assert ruby-rack
ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt ruby-tzinfo ruby2.5
rubygems-integration sg3-utils snmp unzip xsltproc zip
Suggested packages:
ipmitool python-requests python-suds apache2 | lighttpd | httpd lm-sensors snmp-mibs-downloader python-pexpect-doc libcurl4-gnutls-dev python-pycurl-dbg
python-pycurl-doc python3-genshi python3-lxml-dbg python-lxml-doc python3-pycurl-dbg ri ruby-dev bundler
The following NEW packages will be installed:
cluster-glue corosync fence-agents fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4
libcpg4 libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker pacemaker-cli-utils pacemaker-common pacemaker-resource-agents pcs python-pexpect python-ptyprocess python-pycurl python3-bs4
python3-html5lib python3-lxml python3-pycurl python3-webencodings rake resource-agents ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean
ruby-ethon ruby-ffi ruby-highline ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4
ruby-power-assert ruby-rack ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt
ruby-tzinfo ruby2.5 rubygems-integration sg3-utils snmp unzip xsltproc zip
0 upgraded, 103 newly installed, 0 to remove and 2 not upgraded.
Need to get 19.6 MB of archives.
After this operation, 86.0 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 fonts-lato all 2.0-2 [2698 kB]
Get:2 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 libdbus-glib-1-2 amd64 0.110-2 [58.3 kB]
…………
--------
Einmal der Herzschrittmacher Cluster-Installation ist abgeschlossen, der hacluster Benutzer wird automatisch ausgefüllt, während der folgende Befehl ausgeführt wird:
example@sqldat.com:~$ cat /etc/passwd|grep hacluster
hacluster:x:111:115::/var/lib/pacemaker:/usr/sbin/nologin
Jetzt können wir das Passwort für den Standardbenutzer festlegen, der während der Installation von Pacemaker erstellt wurde und Corosync Pakete. Stellen Sie sicher, dass Sie auf allen 3 Knoten dasselbe Passwort verwenden. Verwenden Sie den folgenden Befehl:
--Set default user password on all 3 nodes
sudo passwd hacluster
Geben Sie das Passwort ein, wenn Sie dazu aufgefordert werden:
example@sqldat.com:~$ sudo passwd hacluster
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Der nächste Schritt besteht darin, pcsd zu aktivieren und zu starten Service und Herzschrittmacher auf allen 3 Knoten. Es ermöglicht allen 3 Knoten, dem Cluster nach dem Neustart beizutreten. Führen Sie den folgenden Befehl auf allen 3 Knoten aus, um diesen Schritt zu erledigen:
--Enable and start pcsd service and pacemaker
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker
Sehen Sie sich die Ausführung auf dem primären Replikat aoagvm1 an . Stellen Sie sicher, dass es auch auf den verbleibenden zwei Knoten ausgeführt wird.
--Enable pcsd service
example@sqldat.com:~$ sudo systemctl enable pcsd
Synchronizing state of pcsd.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pcsd
--Start pcsd service
example@sqldat.com:~$ sudo systemctl start pcsd
--Enable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Wir haben den Pacemaker konfiguriert Pakete. Jetzt erstellen wir einen Cluster.
Stellen Sie zunächst sicher, dass auf diesen Systemen keine zuvor konfigurierten Cluster vorhanden sind. Sie können alle vorhandenen Clusterkonfigurationen von allen Knoten zerstören, indem Sie die folgenden Befehle ausführen. Beachten Sie, dass das Entfernen einer Cluster-Konfiguration alle Cluster-Dienste beendet und den Pacemaker deaktiviert Dienst – er muss erneut aktiviert werden.
--Destroy previously configured clusters to clean the systems
sudo pcs cluster destroy
--Reenable Pacemaker
sudo systemctl enable pacemaker
Unten sehen Sie die Ausgabe des primären Replikatknotens aoagvm1 .
--Destroy previously configured clusters to clean the systems
example@sqldat.com:~$ sudo pcs cluster destroy
Shutting down pacemaker/corosync services...
Killing any remaining services...
Removing all cluster configuration files...
--Reenable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Als Nächstes erstellen wir den 3-Knoten-Cluster zwischen allen 3 Knoten aus dem primären Replikat aoagvm1 . Wichtig :Führen Sie die folgenden Befehle nur von Ihrem primären Knoten aus aus !
--Create cluster. Modify below command with your node names, hacluster password and clustername
sudo pcs cluster auth <node1> <node2> <node3> -u hacluster -p <password for hacluster>
sudo pcs cluster setup --name <clusterName> <node1> <node2...> <node3>
sudo pcs cluster start --all
sudo pcs cluster enable --all
Sehen Sie sich die Ausgabe auf dem primären Replikatknoten an:
example@sqldat.com:~$ sudo pcs cluster auth aoagvm1 aoagvm2 aoagvm3 -u hacluster -p hacluster
aoagvm1: Authorized
aoagvm2: Authorized
aoagvm3: Authorized
example@sqldat.com:~$ sudo pcs cluster setup --name aoagvmcluster aoagvm1 aoagvm2 aoagvm3
Destroying cluster on nodes: aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Stopping Cluster (pacemaker)...
aoagvm2: Stopping Cluster (pacemaker)...
aoagvm3: Stopping Cluster (pacemaker)...
aoagvm1: Successfully destroyed cluster
aoagvm2: Successfully destroyed cluster
aoagvm3: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'aoagvm1', 'aoagvm2', 'aoagvm3'
aoagvm1: successful distribution of the file 'pacemaker_remote authkey'
aoagvm2: successful distribution of the file 'pacemaker_remote authkey'
aoagvm3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
aoagvm1: Succeeded
aoagvm2: Succeeded
aoagvm3: Succeeded
Synchronizing pcsd certificates on nodes aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
Restarting pcsd on the nodes to reload the certificates...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
example@sqldat.com:~$ sudo pcs cluster start --all
aoagvm1: Starting Cluster...
aoagvm2: Starting Cluster...
aoagvm3: Starting Cluster...
example@sqldat.com:~$ sudo pcs cluster enable --all
aoagvm1: Cluster Enabled
aoagvm2: Cluster Enabled
aoagvm3: Cluster Enabled
Fechten ist eine der wesentlichen Konfigurationen beim Einsatz des PACEMAKER-Clusters in der Produktion. Sie sollten Fencing für Ihren Cluster konfigurieren, um sicherzustellen, dass bei Ausfällen keine Daten beschädigt werden .
Es gibt zwei Arten der Fencing-Implementierung:
- Ressourcenebene – stellt sicher, dass ein Knoten eine oder mehrere Ressourcen nicht verwenden kann.
- Knotenebene – stellt sicher, dass ein Knoten überhaupt keine Ressourcen ausführt.
Wir verwenden im Allgemeinen STONITH als Fencing-Konfiguration – das Fencing auf Knotenebene für PACEMAKER .
Wenn HERZSCHRITTMACHER den Zustand eines Knotens oder einer Ressource auf einem Knoten nicht bestimmen kann, bringt Fencing den Cluster wieder in einen bekannten Zustand. Um dies zu erreichen, erfordert PACEMAKER, dass wir STONITH aktivieren , was für Shoot The Other Node In The Head steht .
Wir konzentrieren uns in diesem Artikel nicht auf die Fencing-Konfiguration, da die Fencing-Konfiguration auf Knotenebene stark von der individuellen Umgebung abhängt. Für unser Szenario deaktivieren wir es, indem wir den folgenden Befehl ausführen:
--Disable fencing (STONITH)
sudo pcs property set stonith-enabled=false
Wenn Sie jedoch vorhaben, Pacemaker zu verwenden In einer Produktionsumgebung sollten Sie die STONITH-Implementierung abhängig von Ihrer Umgebung planen und aktiviert lassen.
Als Nächstes werden wir einige wesentliche Cluster-Eigenschaften festlegen:cluster-recheck-interval, start-failure-is-fatal, und Fehler-Timeout .
Gemäß MSDN, wenn failure-timeout ist auf 60 Sekunden und cluster-recheck-interval eingestellt auf 120 Sekunden eingestellt ist, wird der Neustart in einem Intervall versucht, das größer als 60 Sekunden, aber kleiner als 120 Sekunden ist. Microsoft empfiehlt, einen Wert für cluster-recheck-interval festzulegen größer als der Wert von failure-timeout . Eine weitere Einstellung start-failure-is-fatal muss auf true gesetzt werden . Andernfalls leitet der Cluster bei dauerhaften Ausfällen kein Failover des primären Replikats auf das entsprechende sekundäre Replikat ein.
Führen Sie die folgenden Befehle aus, um alle drei wichtigen Clustereigenschaften zu konfigurieren:
--Set cluster property cluster-recheck-interval to 2 minutes
sudo pcs property set cluster-recheck-interval=2min
--Set start-failure-is-fatal to True
sudo pcs property set start-failure-is-fatal=true
--Set failure-timeout to 60 seconds. Ag1 is the name of the availability group. Change this name with your availability group name.
pcs resource update ag1 meta failure-timeout=60s
Verfügbarkeitsgruppe in Pacemaker-Clustergruppe integrieren
Hier ist unser Ziel, den Prozess der Integration der neu erstellten Verfügbarkeitsgruppe ag1 zu beschreiben zum neu erstellten Pacemaker Clustergruppe.
Zunächst installieren wir den SQL Server-Ressourcenagenten für die Integration mit Pacemaker auf allen 3 Knoten:
--Install SQL Server Resource Agent on all 3 nodes
sudo apt-get install mssql-server-ha
Ich habe den obigen Befehl auf allen 3 Knoten ausgeführt. Sehen Sie sich die Ausgabe unten an (entnommen aus aoagvm1 ):
--Install SQL Server resource agent for integration with Pacemaker
example@sqldat.com:~$ sudo apt-get install mssql-server-ha
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
mssql-server-ha
0 upgraded, 1 newly installed, 0 to remove, and 2 not upgraded.
Need to get 1486 kB of archives.
After this operation, 9151 kB of additional disk space will be used.
Get:1 https://packages.microsoft.com/ubuntu/16.04/mssql-server-preview xenial/main amd64 mssql-server-ha amd64 15.0.1600.8-1 [1486 kB]
Fetched 1486 kB in 0s (4187 kB/s)
Selecting previously unselected package mssql-server-ha.
(Reading database ... 90430 files and directories currently installed.)
Preparing to unpack .../mssql-server-ha_15.0.1600.8-1_amd64.deb ...
Unpacking mssql-server-ha (15.0.1600.8-1) ...
Setting up mssql-server-ha (15.0.1600.8-1) ...
Wiederholen Sie die obigen Schritte für die verbleibenden 2 Knoten.
Wir haben bereits den Pacemaker erstellt Melden Sie sich bei allen SQL Server-Instanzen an, die auf 3 Knoten gehostet werden, wenn wir die Verfügbarkeitsgruppe ag1 konfiguriert haben . Jetzt weisen wir allen 3 SQL Server-Instanzen die Sysadmin-Rolle zu. Sie können eine Verbindung mit sqlcmd herstellen for running this T-SQL command. If you have not created the Pacemaker login, you can run the below command to do it.
--Create a pacemaker login if you missed creating it in the above section.
USE master
Go
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
Go
--Assign sysadmin role to pacemaker login on all 3 nodes. Run this T-SQL on all 3 SQL Server instances.
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemaker]
We must save the above SQL Server Pacemaker login and its credentials on all 3 nodes. Run the below command there:
--Save pacemaker login credentials on all 3 nodes by executing below commands on each node
echo 'pacemaker' >> ~/pacemaker-passwd
echo 'example@sqldat.com@12' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd
We will create the Availability Group Resource as master/subordinate .
We are using the pcs resource create command to create the Availability Group resource and set its properties. The following command will create the ocf:mssql:ag resource for the Availability Group ag1 .
The Pacemaker resource agent automatically sets the value of REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT on the Availability Group based on the Availability Group’s configuration during the creation of the Availability Group resource.
Execute the below command:
--Create availability group resource ocf:mssql:ag
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s --master meta notify=true
Next, we create a virtual IP resource in Pacemaker . Ensure you have the unused private IP address from your network . Replace the IP value with your virtual IP address. This IP will point to the primary replica and you can use it to make databases connections with active nodes.
The command is below:
--Configure virtual IP resource
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=10.50.0.7
We are adding the colocation constraint and ordering constraint to the Pacemaker cluster configuration . These constraints help the virtual IP resource to make decisions on resources, e.g., where they should run.
Constraints have some scores, and Pacemaker uses these scores to make decisions. Scores are calculated per resource. The cluster resource manager chooses the node with the highest score for a particular resource.
The colocation constraint has an implicit ordering constraint . We need to add an ordering constraint to prevent the IP address from temporarily pointing to the node with the pre-failover secondary . Ordering constraint ensures the cluster comes online in a particular sequential manner.
Run the below commands to add colocation constraint and ordering constraint to the cluster.
--Add colocation constraint
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
--Add ordering constraint
sudo pcs constraint order promote ag_cluster-master then start virtualip
Hence, Two-Node Synchronous Replicas (aoagvm1 &aoagvm2) and a Configuration-Only Replica (aoagvm3) on PACEMAKER Cluster between 3-Node Ubuntu Systems has been completed.
We can test the configuration to validate the automatic failover. Run the below command to check the status of the Pacemaker cluster. The command also initiates the Availability Group failover.
Remember, once you couple your Availability Group with the PACEMAKER cluster, you cannot use T-SQL statements to initiate the Availability Group failovers. You can also shut down the primary replica to initiate the automatic failover.
The command is the following:
--Validate the PACEMAKER cluster configuration
sudo pcs status
--Initiate availability group failover to verify AOAG configuration
sudo pcs resource move ag_cluster-master aoagvm2 –master
Schlussfolgerung
This article was meant to help you understand the configuration of the Two-Node Synchronous Replicas and a Configuration-Only Replica on PACEMAKER Cluster. We hope that you got useful information that will help you in your workflow.
Always plan all steps carefully and do proper testing in a lower life cycle before deploying to your production environment.
We’ll be glad to hear your thoughts about this topic. Feel free to leave your feedback in a comment section.