Die SQL Server Always ON-Verfügbarkeitsgruppe ist eine Lösung, mit der Hochverfügbarkeit und Notfallwiederherstellung für SQL Server-Datenbanken erreicht werden sollen. Wir können diese Funktionalität zwischen Windows-basierten SQL Server-Installationen, Linux-basierten SQL Server-Installationen und sogar zwischen Linux- und Windows-basierten SQL Server-Installationen zusammen konfigurieren.
Verfügbarkeitsgruppen sind in Form von automatischem Failover und Datenschutz eng in Clustertechnologien integriert, indem Daten auf ihre jeweiligen sekundären Replikate repliziert werden. Es ist jedoch nicht immer zwingend erforderlich, einen Cluster-Ressourcen-Manager zum Konfigurieren von Verfügbarkeitsgruppen zu haben.
Um SQL Server-Verfügbarkeitsgruppen zu konfigurieren, benötigen wir WSFC – Windows Server-Failover-Cluster Technologie für Windows -basierte SQL Server-Installationen und PACEMAKER für Linux -basierte SQL Server-Installationen.
HERZSCHRITTMACHER ist ein Open-Source-Cluster-Ressourcenmanager, mit dem wir Ressourcen verwalten und die Systemverfügbarkeit sicherstellen können, falls auf Linux-Systemen ein Fehler auftritt.
WSFC ist ein Microsoft-Produkt, das entwickelt wurde, um Windows-basierte Cluster-Anforderungen zu unterstützen.
Wenn Sie sich die konfigurierten Verfügbarkeitsgruppen in SQL Server für beide Arten von Betriebssystemen ansehen, scheint es in SQL Server Management Studio ähnlich zu sein.
In diesem Artikel werden jedoch Verfügbarkeitsgruppen zwischen dem auf Ubuntu Linux basierenden SQL Server erläutert Installationen mit dem PACEMAKER Cluster-Technologie, daher werde ich nur diese Konfiguration in Betracht ziehen.
Konfiguration des Clustertyps
Wie ich oben erwähnt habe, gibt es je nach Betriebssystem drei Varianten zum Konfigurieren von Verfügbarkeitsgruppen für SQL Server:
- zwischen Windows-basierten SQL Server-Installationen;
- zwischen Linux-basierten SQL Server-Installationen;
- zwischen dem gemischten Typ von Windows- und Linux-basierten SQL Server-Installationen.
Microsoft hat den Cluster_type eingeführt Konfigurationseinstellung zum Identifizieren und Konfigurieren einer geeigneten Clustertechnologie für Verfügbarkeitsgruppen. Es ist ein Konfigurationselement, das definiert, welche Art von Clustertechnologie wir für Verfügbarkeitsgruppen verwenden, unabhängig davon, auf welchem Betriebssystem die SQL Server-Instanz basiert.
Sie können die vorhandene Konfiguration des Cluster-Typs mithilfe von SQL Server Dynamic Management View (DMV) sys.availability_groups abrufen und validieren . Es gibt zwei Spalten namens cluster_type und cluster_type_desc . Wir können diese Spalten lesen, um die Cluster-Typ-Konfiguration der Einrichtung der Verfügbarkeitsgruppe zu definieren.
Diese Konfigurationseinstellung hat 3 Werte, um die Cluster-Technologieanforderungen für jede Variante zu erfüllen:
WSFC . Sie müssen die Option WSFC (Windows Server Failover Cluster) verwenden, wenn Sie über Windows-basierte SQL Server-Installationen verfügen. Es wird nicht für Linux-basierte SQL Server-Installationen unterstützt.
EXTERN . Wenn Sie Verfügbarkeitsgruppen zwischen Linux-basierten SQL Server-Installationen konfigurieren, müssen Sie den PACEMAKER-Cluster-Manager verwenden und EXTERN auswählen Cluster tippen . Der Failover-Modus muss auch EXTERNAL sein (in WSFC ist er Automatic).
KEINE . Wenn Sie keine Clustering-Technologie für Ihre Verfügbarkeitsgruppen verwenden möchten, wählen Sie NONE aus . Diese Option ist anwendbar, wenn Sie Verfügbarkeitsgruppen zwischen Linux- und Windows-basierten SQL Server-Instanzen konfigurieren möchten. Selbst wenn Sie Clustering für Ihr System konfiguriert haben, verwenden die Verfügbarkeitsgruppen die Clustertechnologie nicht, sobald Sie den Clustertypwert auf NONE festgelegt haben. Der Failover-Modus für den Clustertyp NONE ist immer Manuell .
Eine neue Einstellung:Erforderliche synchronisierte Secondaries zum Commit
Beginnend mit SQL Server 2017 hat Microsoft eine neue Einstellung namens required_synchronized_secondaries_to_commit eingeführt . Es aktiviert die automatische Failover-Option, wenn Sie den Cluster-Typ als EXTERN für die PACEMAKER-Cluster-Konfiguration konfiguriert haben.
Der Wert dieser Einstellung wird standardmäßig festgelegt, wenn Sie den SQL Server-Ressourcenagenten mssql-server-ha konfigurieren und erstellen Sie die Clusterkonfiguration.
Sie können den Wert auch manuell an Ihre Anforderungen anpassen, indem Sie den folgenden Befehl ausführen:
--Run below commands to change value for setting required_synchronized_secondaries_to_commit
--AGResourceName is the name of the resource configured for the Availability group
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
Hinweis:Wir können die obige Einstellung nur über Pacemaker unter Linux ändern. Es ist unmöglich, es mit der T-SQL-Anweisung für Linux-basierte Bereitstellungen zu ändern. Für Windows-basierte Bereitstellungen können wir diese Einstellung jedoch durch eine T-SQL-Anweisung ändern.
Unten sind die möglichen Werte für required_synchronized_secondaries_to_commit aufgeführt
0 – Dies bedeutet, dass sekundäre Replikate nicht mit dem jeweiligen primären Replikat synchronisiert werden müssen. Daher wird das automatische Failover nicht unterstützt. Sie müssen das Failover manuell initiieren, wenn das primäre Replikat ausfällt. Wichtig:Es besteht die Möglichkeit eines Datenverlusts, wenn Sie diesen Wert für die Konfiguration wählen.
1 – Dies bedeutet, dass sich mindestens ein sekundäres Replikat im synchronisierten Zustand befinden muss, um ein automatisches Failover zu erreichen.
2 – Dies bedeutet, dass beide sekundären Replikate mit dem primären Replikat synchronisiert werden müssen. Das automatische Failover wird unterstützt.
Replikate zur Teilnahme an einer Verfügbarkeitsgruppe
Die Anzahl der Replikate, die an einer Verfügbarkeitsgruppe teilnehmen können, hängt von der installierten SQL Server-Edition ab.
- Der Standard von SQL Server Edition unterstützt nur Zwei-Knoten-Replikat für eine Verfügbarkeitsgruppe zusammen mit dem zusätzlichen reinen Konfigurationsreplikat.
- Der SQL Server Enterprise Edition unterstützt bis zu neun Replikate – ein primäres und acht sekundäre Replikate.
Da die SQL Server Standard Edition nur zwei Replikate unterstützt (ein primäres Replikat und ein sekundäres Replikat), hat Microsoft ein neues Konzept eingeführt, das als Nur-Konfigurations-Replikat bezeichnet wird in SQL Server 2017 CU1, um ein automatisches Failover für SQL Server zu erreichen, die auf Linux-Systemen ausgeführt werden.
Es gibt zwei mögliche Gestaltungsmöglichkeiten:
- Drei synchrone Replikate. Diese Konfiguration kann nur mit der SQL Server Enterprise Edition bereitgestellt werden. Es gibt 3 Kopien Ihrer Verfügbarkeitsdatenbanken. Diese Architektur ermöglicht alle drei Funktionalitäten:Leseskalierung, Hochverfügbarkeit und Datenschutz.
- Zwei synchrone Replikate und ein reines Konfigurationsreplikat. Sie können dieses Design auch mithilfe der SQL Server Standard Edition konfigurieren, indem Sie zwei synchrone Replikate auf der SQL Server Standard Edition und das dritte Replikat auf der SQL Server Express Edition ausführen, das als reines Konfigurationsreplikat fungiert. Es ist ein kostengünstiges Design, das Hochverfügbarkeit mit automatischem Failover und Datenbankschutz unterstützt.
Zwei-Knoten-Replik
Die Replikatkonfigurationen mit zwei Knoten für Verfügbarkeitsgruppen ist eine sehr beliebte Bereitstellungsoption, um die Hochverfügbarkeit von SQL Server-Datenbanken sicherzustellen. Wir erreichen das automatische Failover mit Hilfe der Windows Server Failover Cluster-Technologie und einem Dateifreigabezeugen in Windows-basierten SQL Server-Bereitstellungen.
Die Dateifreigabe wird im Allgemeinen auf einem zusätzlichen Knoten in WSFC verwendet, um eine Quorumkonfiguration für Replikatkonfigurationen mit zwei Knoten bereitzustellen. WSFC synchronisiert alle Konfigurationsmetadaten mit beiden Replikaten und auf dem dritten Knoten oder Dateifreigabezeugen für ein reibungsloses Failover. Alle Failover-Vermittlungen für Windows-basierte SQL Server-Verfügbarkeitsgruppen finden auf WSFC-Ebene statt.
Wenn wir das automatische Failover für Bereitstellungen von Linux-basierten SQL Server-Verfügbarkeitsgruppen erreichen möchten, funktioniert die obige Konfiguration nicht. Dies liegt daran, dass WSFC nur für Windows-basierte SQL Server-Installationen verwendet werden kann.
Um diese Einschränkung zu beheben und automatisches Failover für Linux-basierte Bereitstellungen mit zwei Replikaten zu ermöglichen, hat Microsoft ein neues Konzept eingeführt.
Nur-Konfigurationsreplik
Ein reines Konfigurationsreplikat ist eine Option, bei der wir eine zusätzliche Instanz von SQL Server auf dem dritten Knoten installieren. Dieser Knoten fungiert als Zeugenserver für die Replikatkonfiguration mit zwei Knoten, um automatisches Failover zu unterstützen. Wir können ein reines Konfigurationsreplikat pro Verfügbarkeitsgruppe erstellen .
Bei Linux-basierten SQL Server-Instanzen, bei denen wir den Clustertyp EXTERNAL für PACEMAKER verwenden, funktioniert die Failover-Vermittlung nicht auf Clusterebene wie WSFC. Die gesamte Failover-Arbitrierung erfolgt auf SQL Server-Ebene, da alle Konfigurationsmetadaten der Verfügbarkeitsgruppe in den Master-Datenbanken jedes Replikats gespeichert werden.
Microsoft hat das reine Konfigurationsreplikatkonzept eingeführt, um das Quorum für Linux-basierte SQL Server-Verfügbarkeitsgruppen zu handhaben. Dieses Konzept hostet keine Benutzerdatenbanken zur Teilnahme an einer Verfügbarkeitsgruppe. Es speichert alle Konfigurationsinformationen der Verfügbarkeitsgruppe in der Master-Datenbank, um sicherzustellen, dass alle Failover-Vermittlungen reibungslos ablaufen.
Sie können jede Edition von SQL Server für das reine Konfigurationsreplikat verwenden. Sogar die SQL Server Express Edition eignet sich, um Ihre Lizenzkosten für das dritte Replikat zu sparen. Denken Sie daran, dass das reine Konfigurationsreplikat keine Datenbank innerhalb der Verfügbarkeitsgruppe hostet. Daher haben Sie nur zwei Kopien von Datenbanken in einer Verfügbarkeitsgruppe.
Standardmäßig required_synchronized_secondaries_to_commit auf 0 gesetzt ist wenn wir das Nur-Konfigurations-Replikat verwenden. Wir können diesen Wert bei Bedarf manuell auf 1 ändern.
Sehen Sie sich das Entwurfsdiagramm der synchronen Zwei-Knoten-Replikation und einer Nur-Konfigurations-Replikation an, um automatisches Failover und Datenschutz zu erreichen.
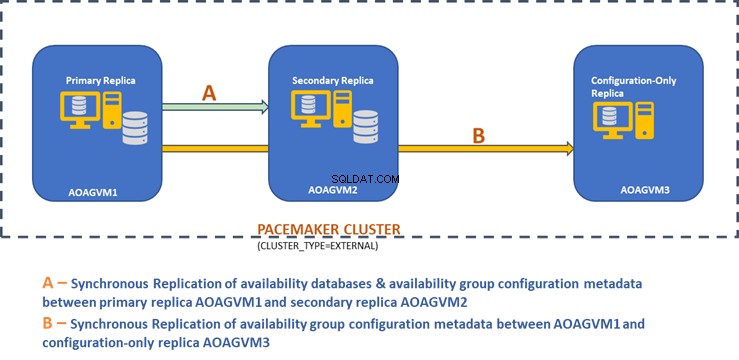
Wir können sehen, dass es 3 VMs mit den Namen AOAGVM1, AOAGVM2 und AOAGVM3 gibt. Sie alle laufen auf dem Ubuntu-Linux-System, und SQL Server ist auf allen drei Linux-Systemen konfiguriert. Die Verfügbarkeitsdatenbanken werden auf AOAGVM1 und AOAGVM2 gehostet.
AOAGVM1 fungiert als primäres Replikat, während AOAGVM2 ein sekundäres Replikat ist. AOAGVM3 dient als reines Konfigurationsreplikat, bei dem es sich um die SQL Server Express Edition handelt. Auf diesem dritten Replikat werden keine Benutzerdatenbanken gehostet.
Der Pacemaker-Cluster wurde zwischen allen drei Knoten konfiguriert, um die Clustertechnologie für die Konfiguration von Linux-basierten Verfügbarkeitsgruppen zu unterstützen.
Um das obige Design zu konfigurieren oder zu implementieren, müssen wir die folgenden Schritte ausführen:
- Installieren Sie SQL Server auf drei Ubuntu-Systemen (die SQL Server Express Edition eignet sich für Nur-Konfigurations-Replikate).
- Verfügbarkeitsgruppen zwischen drei Knoten konfigurieren.
- Konfigurieren Sie den PACEMAKER-Cluster zwischen drei Knoten.
- Verfügbarkeitsgruppe als Ressource in die Clustergruppe hinzufügen oder integrieren.
Sehen Sie sich den zugehörigen Artikel an, um Schritt 1 abzuschließen (Installieren von SQL Server-Instanzen auf drei Knoten).
Bleiben Sie dran für meinen nächsten Artikel, in dem ich den Schritt-für-Schritt-Prozess zur Implementierung des obigen Designs erkläre. Unser Ziel wird es sein, automatisches Failover und Datenschutz mithilfe des synchronen 2-Knoten-Replikats und eines Nur-Konfigurations-Replikats zu erreichen.
Wir freuen uns auf Ihre Gedanken und praktischen Tipps zu diesem Thema. Fühlen Sie sich frei, sie im Kommentarbereich zu teilen.