Die SQL Server-Installation erstellt standardmäßig mehrere Systemdatenbanken pro Instanz, um diese Instanz zu warten und zu verwalten. In diesem Artikel werden wir diese Systemdatenbanken untersuchen und ihre Verantwortlichkeiten verstehen.
SQL Server-Systemdatenbanken
In SQL Server werden Systemdatenbanken während des Installationsvorgangs erstellt, um die instanzspezifischen Konfigurationsdetails von SQL Server zu speichern, damit sie normal funktionieren. Jede Installation von SQL Server erstellt mindestens 5 Systemdatenbanken und 1 replikationsbezogene Systemdatenbank mit dem Namen Verteilungsdatenbank die von Benutzern erstellt wird, wenn die Replikation in dieser Instanz konfiguriert ist. Jede Systemdatenbank hat ihren Zweck und wir werden dies später in diesem Artikel im Detail untersuchen.
Die Systemdatenbanken sind:
- Master – standardmäßig installiert
- Msdb – Standardmäßig installiert
- Modell – Standardmäßig installiert
- Tempdb – Standardmäßig installiert
- Ressource – Standardmäßig installiert . Eingeführt in SQL Server 2005 und verfügbar in späteren SQL Server-Versionen und daher nicht verfügbar in SQL Server 2000 und früheren Versionen.
- Verteilung – Erstellt durch Benutzeraktion . Benutzer können die Verteilungsdatenbank erstellen, um die Replikation zu konfigurieren.
Um die in SQL Server installierte Systemdatenbank anzuzeigen, können wir SSMS verwenden.
Stellen Sie eine Verbindung zu Ihrer SQL Server-Instanz her, erweitern Sie Datenbanken > Systemdatenbanken :
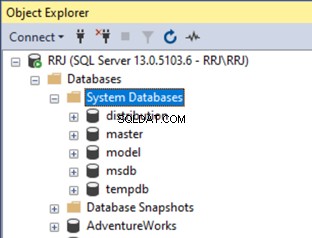
Haben Sie bemerkt, dass die Ressource Datenbank fehlt in der obigen Liste? Die Ressourcendatenbank ist nämlich eine spezielle Systemdatenbank, die nicht im SSMS-Objekt-Explorer aufgeführt ist. Wir können jedoch die Details der Ressourcendatenbank von einer System-DMV mit dem Namen sys.sysaltfiles abfragen und führen Sie die Abfrage aus:
SELECT dbid, db_name(dbid) database_name, fileid, name, filename
FROM sys.sysaltfiles
WHERE dbid NOT BETWEEN 5 AND 11
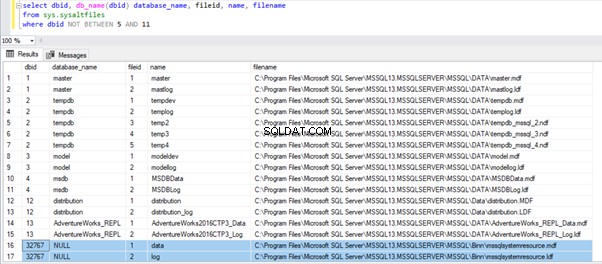
In den Ergebnissen sehen wir die Systemdatenbanken in folgender Reihenfolge:master, tempdb, model, msdb, distribution , und schließlich dbid 32767 das ist eine Ressourcendatenbank. Diese Ressourcendatenbank zeigt jedoch keinen Datenbanknamen an, da sie keinen Eintrag in sys.databases hat . Ich habe einige Benutzerdatenbanken zwischen dbid 5 und 11 ausgeschlossen und AdventureWorks_REPL eingeschlossen als Beispiel, um zu zeigen, dass DMV auch Benutzerdatenbanken anzeigen kann. Auf die Ressourcendatenbank und andere Systemdatenbanken gehen wir später noch genauer ein.
Einschränkungen für SQL-Systemdatenbanken
Da Systemdatenbanken kritische Systemkonfigurationsdetails enthalten, sollten geeignete Sicherheitsmaßnahmen vorhanden sein, um ein versehentliches Löschen von Daten zu vermeiden. Daher haben Systemdatenbanken im Vergleich zu Benutzerdatenbanken die folgenden Einschränkungen:
Systemdatenbanken können nicht offline genommen werden
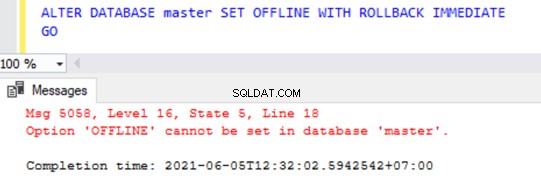
Wir können eine Benutzerdatenbank mit dem Befehl ALTER DATABASE offline schalten, wie unten gezeigt:
ALTER DATABASE AdventureWorks SET OFFLINE WITH ROLLBACK IMMEDIATE
GO
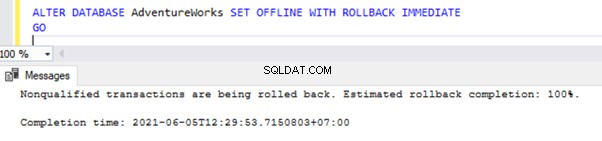
Wenn wir jedoch versuchen, eine der Systemdatenbanken mit dem obigen Befehl OFFLINE zu schalten, erhalten wir eine Fehlermeldung wie unten gezeigt:
Systemdatenbanken können nicht gelöscht werden
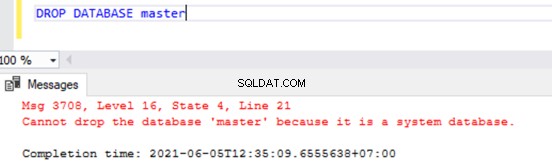
Während wir die Benutzerdatenbanken löschen können, indem wir den Befehl DROP DATABASE
ausführenDROP DATABASE AdventureWorksWenn wir versuchen, eine der Systemdatenbanken zu löschen, erhalten wir den unten gezeigten Fehler:
Eigentümer von Systemdatenbanken können nicht geändert werden
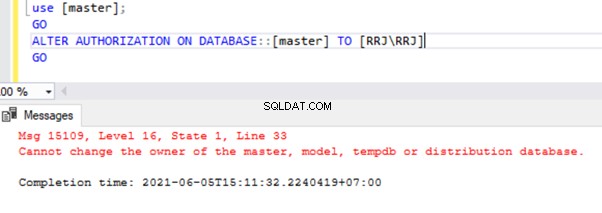
Der Eigentümer der Systemdatenbank ist sa standardmäßig. Es kann nicht geändert werden. Versuche, den Eigentümer der Systemdatenbank umzubenennen, führen zu Fehlern.
Es gibt jedoch eine Ausnahme. Es ist möglich, den Eigentümer der msdb zu ändern Datenbank.
use [master];
GO
ALTER AUTHORIZATION ON DATABASE::[master] TO [RRJ\RRJ]
GO
Datenbankname von Systemdatenbanken kann nicht geändert werden
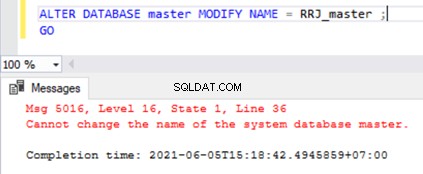
Wenn wir versuchen, die Systemdatenbanken umzubenennen, erhalten wir die unten gezeigte Fehlermeldung:
ALTER DATABASE master MODIFY NAME = RRJ_master;
GO
Die Sortierung von Systemdatenbanken kann nicht geändert werden
Systemdatenbanken werden mit dem Sortierungsnamen erstellt, der während der Installation von SQL Server ausgewählt wurde. Nach der Installation kann die Sortierung der Systemdatenbanken nicht mehr geändert werden. Die einzige Möglichkeit, die Sortierung der Systemdatenbanken zu ändern, besteht darin, die SQL Server-Instanz mit der richtigen Sortierung neu zu installieren.
Primäre Dateigruppe von Systemdatenbanken kann nicht in den READ_ONLY-Modus versetzt werden
Da die Systemdatenbank wichtige Informationen zu SQL Server-Instanzen erfasst, lässt SQL Server nicht zu, dass die primären Datendateien, die sich in der primären Dateigruppe befinden, als schreibgeschützt festgelegt werden .
Change Data Capture-Funktion kann auf Systemdatenbanken nicht aktiviert werden
Diese Funktion wird verwendet, um jede DML-Änderung zu verfolgen, die in einer Datenbank in den verfolgten Tabellen stattfindet. Wenn wir versuchen, die Change Data Capture-Funktion für Systemdatenbanken zu aktivieren, tritt der Fehler auf:
use master
GO
exec sys.sp_cdc_enable_db

Nachdem wir uns nun über den Unterschied zwischen Systemdatenbanken und Benutzerdatenbanken im Klaren sind, können wir den Zweck jeder Systemdatenbank genauer untersuchen.
Master-Datenbank in SQL Server
Die Datenbank des Master-Systems enthält wichtige Konfigurationsdetails in Bezug auf die SQL Server-Instanz . SQL Server verlässt sich darauf, wenn eine bestimmte Instanz gestartet wird. Wenn es aus irgendeinem Grund nicht möglich ist, die Master-Datenbank zu starten, kann die SQL Server-Instanz auch nicht gestartet werden.
Zu diesen in der Master-Datenbank gespeicherten Schlüsseldetails gehören Anmeldekonten, Verbindungsserverdetails, Endpunkte, Systemkonfigurationseinstellungen und Details zu allen Benutzerdatenbanken.
Jetzt kommt die Frage. Woher weiß der SQL Server-Dienst, wo die Daten und Protokolldateien der Master-Datenbank verfügbar sind? Die Antwort liegt in den Startkonfigurationsparametern des SQL Server-Dienstes.
Um die Startkonfigurationsparameter einer SQL Server-Instanz anzuzeigen, sollten wir uns zunächst mit dem integrierten Tool namens SQL Server Configuration Manager vertraut machen . Es hilft bei der Verwaltung aller SQL Server-bezogenen Dienste aller Instanzen, die auf dem jeweiligen Server verfügbar sind. Um diese Daten anzuzeigen, öffnen Sie den SQL Server Configuration Manager und es wird die unten gezeigte Liste angezeigt:
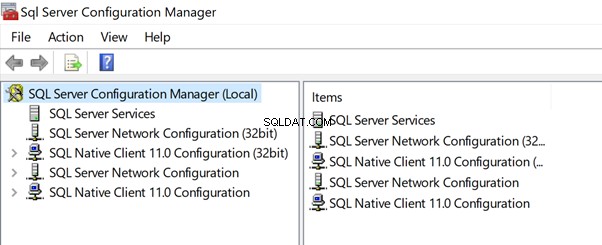
Klicken Sie auf SQL Server-Dienste um die Liste der auf diesem Server oder PC verfügbaren Dienste anzuzeigen:
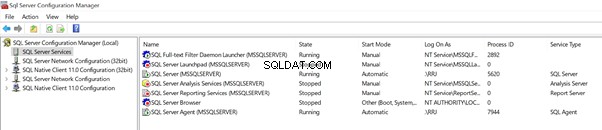
Warte mal eine Sekunde! Es kommt der services.msc bekannt vor listet alle auf dem Server verfügbaren Dienste auf, zeigt aber nur SQL Server-bezogene Dienste an.
Lassen Sie uns services.msc öffnen um zu sehen, wie es aussieht, und um die Unterschiede zwischen dem SQL Server-Konfigurations-Manager und services.msc zu überprüfen um zu vergleichen, welches besser ist.
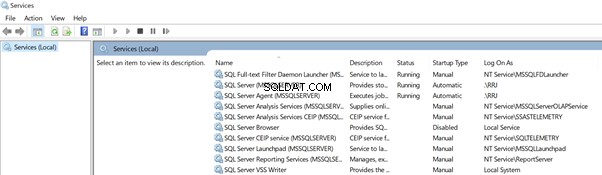
Der SQL Server-Konfigurations-Manager zeigt die Prozess-ID der derzeit ausgeführten Dienste an. Wir konnten das in services.msc nicht finden . Natürlich können wir diese Informationen aus dem Windows Task-Manager abrufen, aber der SQL Server-Konfigurationsmanager hat uns dabei geholfen, diese an einem einzigen Ort anzuzeigen.
Lassen Sie uns nun einen detaillierten Blick darauf werfen. Klicken Sie mit der rechten Maustaste auf den SQL Server-Dienst von services.msc . Sie werden die folgenden Menüs sehen:Allgemein , Anmelden , Wiederherstellung und Abhängigkeiten .
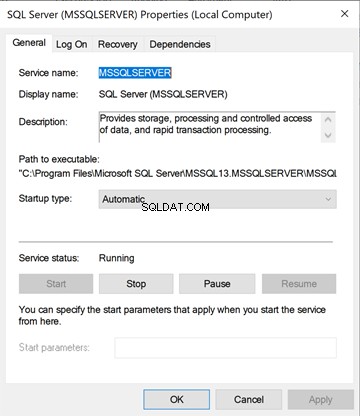
Klicken Sie im SQL Server Configuration Manager mit der rechten Maustaste auf SQL Server(MSSQLSERVER) service> Eigenschaften . Es listet die folgenden Menüs auf – Anmelden, Service. FileStream, Advanced, AlwaysonHigh Availability und Startparameter .
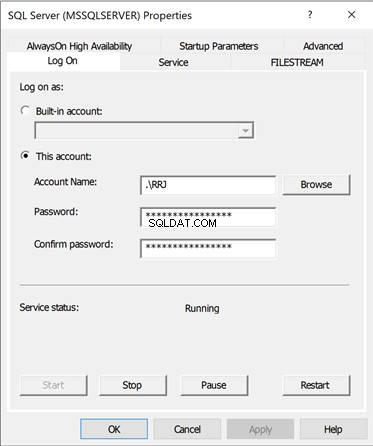
Die Startparameter des Dienstes, der den Speicherort der Master-Datenbankdaten und Protokolldateien speichert war nur im SQL Server Configuration Manager verfügbar .
Klicken Sie auf Startparameter um die Details anzuzeigen – für Vorhanden Parameter . Sie sehen die folgenden Informationen:
- Der physische Speicherort der Hauptdatenbank Datendatei
- Der physische Speicherort der Master-Datenbank Transaktionsprotokolldatei
- Der physische Speicherort des ErrorLog-Ordners wo sich Fehler im Zusammenhang mit dem SQL Server-Dienst befinden.
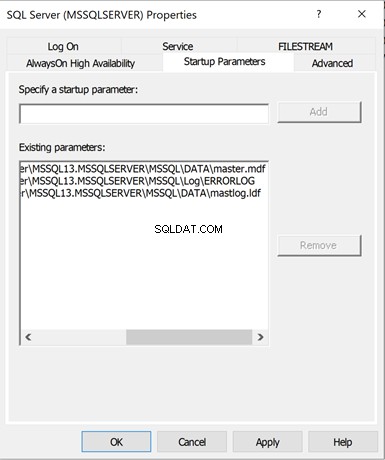
Wir können weitere Startparameter wie Einzelbenutzermodus (-m) hinzufügen usw. Dazu müssen wir die erforderlichen Werte in Startparameter angeben angeben und klicken Sie auf Hinzufügen .
Wir haben festgestellt, dass der SQL Server Configuration Manager nicht nur erweiterte Details anzeigt, sondern uns auch viele erweiterte Konfigurationen im Zusammenhang mit dem SQL Server-Dienst ermöglicht. Daher würde ich persönlich empfehlen, den SQL Server-Konfigurationsmanager zum Stoppen/Starten von SQL Server-bezogenen Diensten im Vergleich zur Standardoption Services.msc zu verwenden.
Empfohlene Vorgehensweisen für die Master-Datenbank
Da die Master-Datenbank wichtige Details über die SQL Server-Instanz speichert, wird empfohlen, beim Umgang mit dieser Datenbank die Best Practices zu befolgen.
- Jede Konfigurationsänderung auf einer Instanz von SQL Server wird in der Master-Datenbank gespeichert. Daher müssen Sie immer eine vollständige Sicherung der Master-Datenbank erstellen, um den neuesten Stand wiederherzustellen, falls wir die Master-Datenbank bei Bedarf aus der vollständigen Sicherung wiederherstellen.
- Obwohl SQL Server es Benutzern ermöglicht, Benutzertabellen oder andere Objekte in der Master-Datenbank zu erstellen, wird dies nicht empfohlen. Die Master-Datenbank sollte einfach und sauber bleiben. Wenn Sie Benutzerobjekte in der Master-Datenbank erstellen müssen, sollten Sie häufiger vollständige Sicherungen der Master-Datenbank erstellen.
- SQL Server unterstützt die Startprozeduroption zum Ausführen bestimmter gespeicherter Prozeduren beim Starten einer SQL Server-Instanz. Es verwendet die sp_procoption Verfahren. Seien Sie bei der Verwendung dieser Option vorsichtig, da sich ein nicht optimaler Code oder eine nicht optimale rekursive Logik auf die Startzeit der SQL Server-Instanz auswirken kann.
Wenn SQL Server aufgrund von Problemen mit der Master-Datenbank nicht gestartet werden konnte, müssen wir die Master-Datenbank aus der letzten als funktionierend bekannten Sicherung wiederherstellen.
Modelldatenbank in SQL Server
Wie der Name schon sagt, die Modellsystemdatenbank fungiert als Modell oder Vorlage für die Erstellung jeder Benutzerdatenbank in Bezug auf Dateipfad, Anfangsgröße, Einstellungen für automatisches Wachstum und das Wiederherstellungsmodell sowie andere Konfigurationsoptionen .
Alle Benutzerobjekte wie Tabellen, Prozeduren usw., die in den Modelldatenbanken erstellt werden, werden auch automatisch in allen neuen Benutzerdatenbanken in dieser SQL Server-Instanz erstellt.
Lassen Sie uns dies überprüfen, indem wir eine neue Tabelle in der Modelldatenbank erstellen:
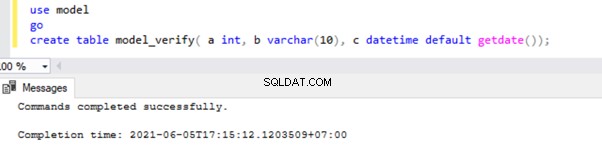
Lassen Sie uns prüfen, ob diese Tabelle in der Modelldatenbank vorhanden ist:
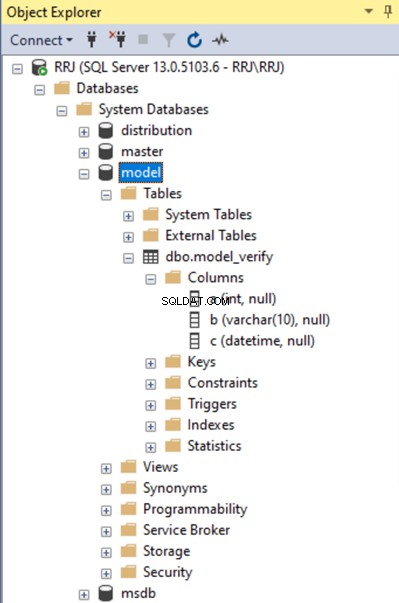
Die Modelldatenbank speichert auch den Standarddateipfad der Benutzerdatenbanken, wie unten in den Datenbankeigenschaften gezeigt der msdb Datenbank.
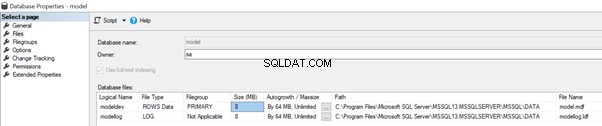
Gemäß der aktuellen Konfiguration ist die Anfängliche Dateigröße beider Daten und Protokolldateien ist auf 8 MB eingestellt, wobei die automatische Vergrößerung für beide auf 64 MB eingestellt ist.
Wenn Sie eine Benutzerdatenbank in einem anderen Dateipfad anstelle des Speicherorts der Modelldatenbankdatei erstellen müssen, können wir sie in den Servereigenschaften ändern dieser SQL Server-Instanz.
Klicken Sie in SSMS mit der rechten Maustaste auf Server > Eigenschaften > Datenbankeinstellungen . Zeigen Sie die Standardspeicherorte der Datenbank an:
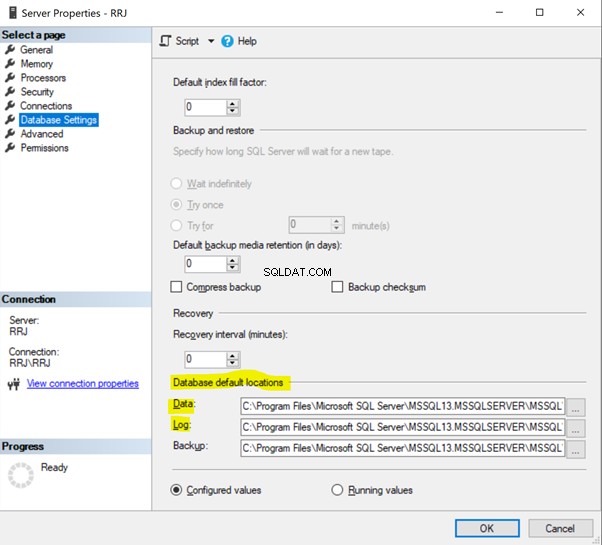
Ändern Sie den Dateipfad in den gewünschten Pfad und klicken Sie auf OK . Die Benutzerdatenbank Daten und Protokollieren Dateien werden in dem neuen Pfad erstellt, den Sie angegeben haben.
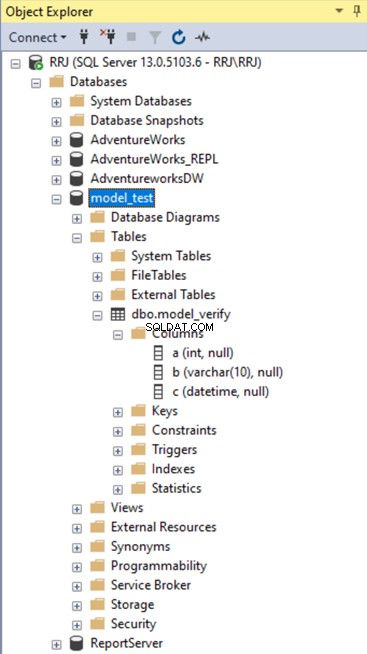
Lassen Sie uns eine neue Datenbank mit dem Namen model_test erstellen und überprüfen Sie die neuen Daten- und Protokolldateipfade der Datenbank zusammen mit den Eigenschaften der Datei "Initial" und "Autogrowth" und model_verify Tabelle in der neuen Datenbank.
Lassen Sie uns den model_test überprüfen Daten- und Protokolldateipfade. Klicken Sie mit der rechten Maustaste auf model_test Datenbank> Eigenschaften > Dateien :
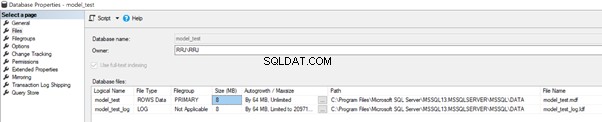
Wie wir sehen können, sind die Daten und Protokollieren Dateien des model_test Datenbank werden gemäß dem Pfad erstellt, der in der Modelldatenbank verfügbar ist. Der Wert für die anfängliche Dateigröße der Daten- und Protokolldateien beträgt 8 MB. Der Autogrowth-Wert beträgt 64 MB. Diese Werte entsprechen der Konfiguration der Modelldatenbank.
Jetzt prüfen wir, ob die model_verify Tabelle wird im model_test erstellt Datenbank. Wir können diese neue Datenbank sehen.
Neben Tabellen gilt dies für Ansichten, gespeicherte Prozeduren, Funktionen und alle in den Modelldatenbanken erstellten Objekte.
Empfohlene Vorgehensweisen für die Modelldatenbank
Da die Modelldatenbank als Vorlage für jede neue Erstellung einer Benutzerdatenbank dient, sollten wir die folgenden Verfahren anwenden, wenn wir damit umgehen:
- Wann immer Sie Änderungen an der Modelldatenbankkonfiguration implementieren möchten (z. B. anfängliche Dateigröße, Größe der automatischen Vergrößerung, Erstellen, Ändern oder Löschen von Benutzerobjekten), erstellen Sie sofort eine vollständige Sicherung der Modelldatenbank.
- Da alle in den Modelldatenbanken erstellten Benutzerobjekte in beliebigen Benutzerdatenbanken erstellt werden, achten Sie darauf, nur erforderliche Objekte hinzuzufügen. Andernfalls werden viele unnötige Objekte in allen Benutzerdatenbanken erstellt, und Sie verbringen viel Zeit damit, sie zu sortieren und Ihre Datenbanken zu bereinigen.
- Konfigurieren Sie die Parameter für die anfängliche Dateigröße und die automatische Vergrößerung für die Daten- und Protokolldateien. Es hilft, die Daten- und Protokolldateigrößen in den Benutzerdatenbanken besser zu verwalten und die Leistung zu verbessern.
MSDB-Datenbank
Die msdb-Systemdatenbank speichert die folgenden kritischen Informationen über die Systemtabellen hinweg:
- Elemente im Zusammenhang mit dem SQL Server-Agenten wie Jobs, Jobverläufe, Warnungen, Operatoren, Proxys usw.
- SQL Server-Funktionen wie Service Broker und Datenbank-E-Mail mit Konfigurations- und Verlaufsdetails.
- Details zur SQL Server-Sicherung und -Wiederherstellung werden in den msdb-Datenbanktabellen gespeichert.
- Protokollversandkonfigurationen, Replikations-Agent-Profile und Datenkollektorkonfigurationen.
- Wartungspläne, SSIS-Pakete und einige andere Details.
Mit anderen Worten, die msdb-Systemdatenbank speichert alle kritischen Informationen zu SQL Server Agent Services und einigen anderen verwandten Diensten.
Empfohlene Vorgehensweisen für die msdb-Datenbank
Die msdb-Datenbank speichert viele wichtige Konfigurationsinformationen in Bezug auf SQL Server-Agenten, Jobs und Datenbank-E-Mail. Es speichert auch historische Details. Daher sollten wir beim Umgang mit der msdb-Datenbank die folgenden Praktiken implementieren:
- In einer SQL Server-Instanz mit vielen Datenbanken oder auskonfigurierten Jobs wird die Größe der msdb-Datenbank im Laufe der Zeit kontinuierlich zunehmen. Daher sollten für die msdb-Datenbanken zusammen mit anderen Benutzerdatenbanken täglich vollständige Sicherungen implementiert werden. Wenn msdb viele wichtige Informationen erhält, können wir das Wiederherstellungsmodell der msdb-Datenbank auf „Vollständig“ ändern und dann auch die Transaktionsprotokollsicherung implementieren.
- Obwohl SQL Server es Benutzern ermöglicht, Benutzerobjekte in der msdb-Datenbank zu erstellen, wird empfohlen, keine Benutzertabellen oder -objekte in der msdb-Datenbank zu erstellen und die Größe der msdb-Datenbank weiter zu erhöhen.
- Führen Sie eine regelmäßige Bereinigung der msdb-Systemtabellen durch, um die Größe der msdb-Datenbank unter Kontrolle zu halten und die Leistungseinbußen zu vermeiden, wenn große Datenmengen in mehreren Tabellen vorhanden sind.
Tempdb-Datenbank
Die tempdb-Systemdatenbank kann als globaler Arbeitsbereich betrachtet werden, der allen Benutzern zur Verfügung steht, die mit der SQL Server-Instanz verbunden sind, um ihre SELECT- oder andere Operationen auszuführen .
Die Tempdb-Datenbank enthält die folgenden Objekttypen, während Benutzer ihre Operationen ausführen:
- Temporäre Objekte, die explizit von Benutzern erstellt wurden, können entweder lokale oder globale temporäre Tabellen und Indizes, Tabellenvariablen, in Tabellenwertfunktionen verwendete Tabellen und Cursor sein.
- Interne Objekte, die von der Datenbank-Engine erstellt wurden, wie zum Beispiel:
- Arbeitstabellen, die für Zwischenergebnisse für Spools, Cursor, Sortierungen und temporäre große Objekte (LOB) verwendet werden
- Arbeitsdateien für Hash-Join- oder Hash-Aggregat-Operationen
- Zwischensortierergebnisse beim Erstellen oder Neuerstellen von Indizes, wenn SORT_IN_TEMPDB auf ON gesetzt ist, und andere Vorgänge wie GROUP BY-, ORDER BY- oder UNION-Abfragen
- Versionsspeicher, die die Zeilenversionsfunktion unterstützen, entweder allgemeiner Versionsspeicher oder Online-Versionsspeicher für die Indexerstellung.
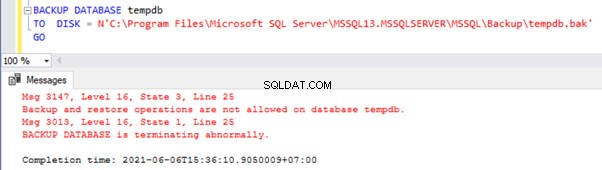
Bei jedem Start oder Neustart des SQL Server-Dienstes wird die tempdb-Datenbank mit Hilfe der model-Datenbank neu erstellt. Daher ist tempdb die einzige Systemdatenbank, die nicht gesichert werden kann .
Wenn wir versuchen, es zu sichern, erhalten wir Fehler:
Da wir tempdb in fast allen Benutzervorgängen verwenden, stellt diese Datenbank einen erheblichen Leistungsengpass für mehrere Versionen von SQL Server dar. Ab SQL Server 2016 wurden mehrere Optimierungstechniken von Microsoft implementiert – wir werden sie später besprechen.
Bevor wir auf die empfohlenen Vorgehensweisen für die tempdb-Datenbank eingehen, werfen wir einen kurzen Blick auf ihre Datendateien unter der Standardkonfiguration, wie unten gezeigt:
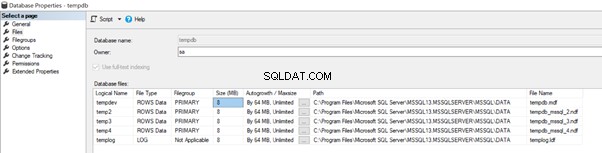
Für meine aktuelle SQL Server-Instanz haben wir 4 Datendateien und eine Protokolldatei für die tempdb-Datenbank.
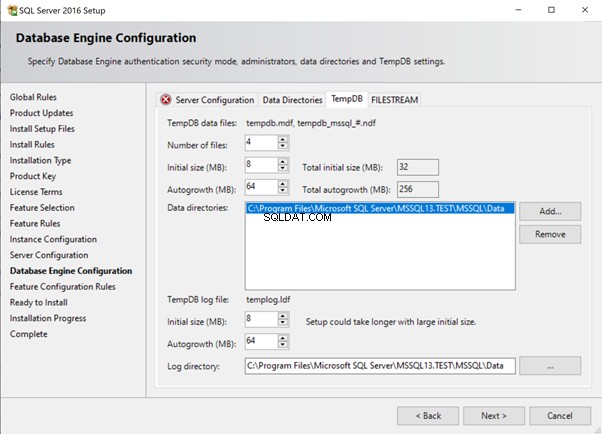
Ab SQL Server 2016 haben wir das SQL Server-Installationsprogramm, mit dem wir mehrere Dateien zu tempdb hinzufügen können. Die obigen 4 Dateien mit einer Anfangsgröße von 8 MB und einer Autogrowth-Größe von 64 MB wurden mit den unten gezeigten Standardoptionen erstellt.
Wenn wir eine einzelne Datendatei in der tempdb-Datenbank haben, versuchen alle im Server verfügbaren logischen Kerne, auf dieselbe Datendatei von tempdb zuzugreifen, was zu einem Leistungsengpass führt.
Wenn mehrere Datendateien vorhanden sind, werden bestimmte Kerne logisch einer einzelnen Datei zugeordnet. Daher haben wir weniger Konflikte bei tempdb-Datendateien. Dadurch wird die Leistungsauswirkung auf die tempdb-Datendateien verbessert.
Empfohlene Verfahren für die tempdb-Datenbank
Da die tempdb-Datenbank wie ein globaler Arbeitsbereich für alle Benutzeraktivitäten ist, erhöht sich die tempdb-Größe basierend auf den Benutzeraktivitäten. Dies kann ein Leistungsengpass für die gesamte SQL Server-Instanz sein.
Daher sollten wir die folgenden Praktiken implementieren:
- Platzieren Sie die tempdb-Daten- und Protokolldateien auf Hochleistungsspeicher, um höhere IOPS für eine bessere Leistung zu erzielen.
- Stellen Sie sicher, dass die tempdb-Datenbank in mehrere Datendateien aufgeteilt ist, um Konflikte zu reduzieren und Leistungsengpässe in der tempdb-Datenbank zu vermeiden.
- Wenn die Anzahl der logischen Kerne weniger als 8 beträgt, können wir eine tempdb-Datendatei pro logischem Kern haben. In unserer Testinstanz hatten wir 4 logische Kerne. Daher sollten 4 Datendateien auf tempdb ausreichen.
- Wenn die Anzahl der logischen Kerne mehr als 8 beträgt, beginnen Sie mit 8 Datendateien und erhöhen Sie um 4 Datendateien, wenn Konflikte und Leistungsprobleme in der tempdb-Datenbank beobachtet werden.
- Wenn die Anzahl der logischen Kerne in einem Server 32 oder 64 beträgt, können wir mit 8 Datendateien beginnen. Dies bedeutet, dass 4 Kerne oder 8 Kerne logisch für eine einzelne Datendatei verknüpft sind.
Für mehr Klarheit über mehrere tempdb-Datendateien empfehle ich Ihnen den ausgezeichneten Artikel von Paul Randal.
- Stellen Sie sicher, dass tempdb-Datendateien mit optimaler anfänglicher Dateigröße konfiguriert sind. Idealerweise sollte dies durch einen Trial-and-Error-Ansatz erreicht werden. Tempdb mit optimaler anfänglicher Dateigröße wächst tendenziell seltener als tempdb, das mit der geringeren anfänglichen Dateigröße konfiguriert ist, die dazu neigt, mehrmals zu wachsen, was zu Fragmentierung führt. In der aktuellen Konfiguration sind beispielsweise alle Dateien mit einer anfänglichen Dateigröße von 8 MB konfiguriert, was zu wenig ist, um SQL-Workloads zu verarbeiten. Wenden Sie daher den Trial-and-Error-Ansatz an und legen Sie die anfängliche Dateigröße auf 512 MB oder 1 GB oder einen anderen Wert fest.
- Stellen Sie sicher, dass alle tempdb-Datendateien auf die gleiche Dateigröße eingestellt sind. Autowachstumseigenschaften müssen gleichermaßen definiert werden. In unserem Szenario sind alle Dateien auf 64 MB automatisches Wachstum eingestellt. Das Festlegen der Größe für die automatische Vergrößerung auf 512 MB oder 1 GB oder einen anderen geeigneten Wert hilft, die häufige automatische Vergrößerung von tempdb-Datendateien zu reduzieren.
- Stellen Sie sicher, dass die Anfangsdateigröße und die automatische Vergrößerung für die tempdb-Protokolldatei auf einen optimalen Wert konfiguriert sind, ähnlich wie bei tempdb-Datendateien. Da das Wiederherstellungsmodell von tempdb standardmäßig auf Einfach eingestellt ist und nicht geändert werden kann, sollte es ausreichen, die anfängliche Dateigröße und die automatische Vergrößerungseigenschaft der tempdb-Protokolldatei zu konfigurieren.
Tempdb ist für die Leistung von SQL Server-Instanzen von entscheidender Bedeutung. In unseren nächsten Artikeln werfen wir einen detaillierten Blick auf die häufigen Probleme, mit denen tempdb konfrontiert ist, und wie man sie optimal verkleinert.
Ressourcendatenbank in SQL Server
Die Resource System-Datenbank ist die einzige schreibgeschützte Systemdatenbank, die nicht unter den Systemdatenbanken in SSMS aufgeführt ist, wie zuvor gesehen.
Die Datenbank-ID (dbid) der Ressourcendatenbanken in allen Instanzen beträgt 32767, was auch die maximale Anzahl von Datenbanken ist, die in einer SQL Server-Instanz unterstützt werden. Sie kann aus den sys.sysaltfiles abgefragt werden System DMV. Ausführen der folgenden SELECT-Abfrage auf sys.sysaltfiles gibt die Ergebnismenge zurück zeigt, wo sich die Daten- und Protokolldateien der Ressourcendatenbank befinden:
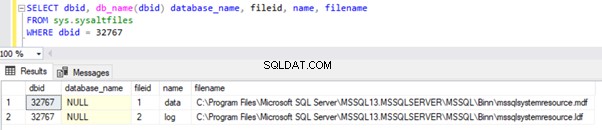
Wir können physische Dateien der Ressourcendatenbank sehen, die im oben genannten Pfad verfügbar sind. Das Änderungsdatum gibt den Zeitpunkt der Installation der SQL Server-Instanz oder das letzte Mal an, dass Service Packs (SP) oder kumulative Updates (CU) auf diese Instanz angewendet wurden.

Die Ressourcendatenbank enthält alle Systemobjekte, wie z. B. sys.objects , sys.databases , sys.sysaltfiles , etc. physisch darin. Diese Datenbank listet alle diese Objekte logisch unter dem sys-Schema über alle in der Instanz verfügbaren Datenbanken auf . Da die Ressourcendatenbank schreibgeschützt ist, können keine Benutzerobjekte oder Daten darauf erstellt werden.
Die Ressourcensystemdatenbank wurde ab SQL Server 2005 eingeführt, um das SQL Server-Upgrade entweder auf eine neue Version von SP oder CU zu beschleunigen. Vor der Einführung dieser Option bedeuteten alle derartigen Upgrades und Updates, dass Änderungen auf alle Datenbanken angewendet wurden, was den Upgrade-Prozess komplizierter und zeitaufwändiger machte. Jetzt aktualisiert oder ersetzt jede SQL Server-Versionsaktualisierung oder SP- oder CU-Aktualisierung nur die Ressourcendatenbank.
Da die Ressourcendatenbank schreibgeschützt und für Benutzer nicht sichtbar ist, ist kein Benutzereingriff erforderlich. Wenn Sie die Sicherung der Ressourcendatenbank in Ihre Hochverfügbarkeits- oder Notfallwiederherstellungsplanung einbeziehen möchten, erstellen Sie einfach eine Dateisicherung der Dateien mssqlsystemresource.mdf und mssqlsystemresource.ldf, nachdem Sie die SQL Server-Dienste beendet haben (der SQL Server-Dienst erlaubt nicht, die Dateien währenddessen zu kopieren SQL Server Service is up and running) und speichern Sie es an einem sicheren Ort. Achten Sie besonders darauf, es nicht auf einer Instanz von SQL Server zu aktualisieren, die mit einer anderen Version der SP- oder CU-Stufen ausgeführt wird, da dies zu unerwarteten Problemen führen kann.
Verteilungsdatenbank in SQL Server
Die Datenbank des Verteilungssystems ist das Herzstück der Replikation. Benutzer können die Verteilungsdatenbank als Teil der Replikationseinrichtung mit Hilfe des Assistenten zum Konfigurieren von Verteilungen oder des Assistenten zum Erstellen von Veröffentlichungen erstellen oder konfigurieren. Wir haben die Erstellungsschritte für die Verteilungsdatenbank im Detail als Teil meines vorherigen Artikels über SQL Server Transactional Replication Internals beschrieben.
Empfohlene Praktiken für die Verteilungsdatenbank
Da die Verteilungsdatenbank für die Replikationsfunktion wesentlich ist, sollten wir die folgenden Praktiken implementieren:
- Verschieben Sie die Daten- und Protokolldateien der Verteilungsdatenbank auf das Laufwerk mit guten IOPS, um Leistungsprobleme bei der Verteilung zu vermeiden.
- Konfigurieren Sie die Anfangsdateigröße und die Autogrowth-Eigenschaften der Verteilungsdatenbank auf einen besseren Wert, um Fragmentierungsprobleme zu vermeiden.
- Die Verteilungsdatenbank in die Wartungsjobs der vollständigen Datenbanksicherung einbeziehen.
- Beziehen Sie Verteilungsdatenbanken in die Indexwartungsjobs ein, um Fragmentierung und Leistungsprobleme zu vermeiden.
In meinem Artikel über die Interna der SQL Server-Transaktionsreplikation finden Sie auch Empfehlungen zu anderen effizienten Vorgehensweisen.
Schlussfolgerung
Vielen Dank, dass Sie sich einen weiteren leistungsstarken Artikel angesehen haben!
Ich hoffe, es hat Ihnen geholfen, das Wesen und die Zwecke der SQL Server-Systemdatenbanken zu verdeutlichen und die bewährten Verfahren zur Vermeidung von Leistungsproblemen bei diesen Datenbanken kennenzulernen.